湍流数据同化技术及应用
2021-07-05何创新邓志文刘应征
何创新,邓志文,刘应征,*
1. 上海交通大学 机械与动力工程学院 动力机械与工程教育部重点实验室,上海 200240 2.上海交通大学 燃气轮机研究院,上海 200240
湍流普遍存在于航空航天、能源动力和海洋工程等领域,通常伴随着传热、传质、振动、噪声等复杂的物理现象,因而相关研究对湍流流场的高精度实验测量与数值模拟提出了很高的要求。高频响的热线风速仪(Hot Wire anemometer, HW)、高空间分辨率的粒子图像测速技术(Particle Image Velocimetry, PIV)以及最新发展起来的层析PIV技术(Tomography Particle Image Velocimetry, Tomo-PIV)[1-3]为湍流流场分别提供了一维、二维和三维的测量手段。高精度大涡模拟(Large-Eddy Simulation, LES)和分离涡模拟(Detached-Eddy Simulation, DES)[4-6]方法为湍流多物理场的获取提供了全三维高时空分辨率的解决方案。然而,单纯实验测量和数值模拟仍然无法满足日益深入的研究需求。实验测量方面:① 测量的空间维度有限,即使先进的三维PIV测量技术,其测量空间和流速范围也受到硬件多方面的制约;② 测量区域受到几何结构的遮挡与阻碍,复杂内流场及全场测量难以实现;③ 实验测量误差问题,尤其是近壁区的PIV测量误差很大;④ 多物理场同步测量难度大。数值模拟方面:① 高精度LES和DES模拟技术是建立在高分辨率网格的基础上,尤其对于含有边界层转捩的外流场模拟,计算量非常大;② 雷诺时均(Reynolds-Averaged Navier-Stokes, RANS)方法基于半理论半经验的模型方程,对复杂流场模拟的准确度比较差;③ 数值计算需要给定准确的边界条件,而这在很多工程流场中难以确定。
数据同化(Data Assimilation, DA)[7]是一种融合实验测量与模型预测的数学方法,最早在气象预报中得到发展与应用[8],现阶段还被广泛应用于海洋、水文、地理等领域[9-11]。数据同化通过引入观测站获取的实时测量数据作为约束,植入流动与热动力学方程中,从而预测未来时刻的天气状况。实验观测(Observation)、预测模型(Predictive model)和同化算法是数据同化的三要素。实验观测通过同化算法对预测模型进行修正,使之获得更准确的预测结果。近年来,国外研究学者也开始将数据同化技术应用到湍流动力学研究领域[12-13]。数据同化方法可以很好地发挥实验测量与数值模拟的各自优势,在未来湍流研究中将具有很大的应用潜力。
在湍流数据同化研究中,实验观测可以是热线风速仪、PIV等常规测试方法获取的一维、二维乃至三维流场矢量分布,也可以是压力传感器、压敏漆(Pressure Sensitive Paint, PSP)等方法获取的壁面压力分布;预测模型一般包括Navier-Stokes (N-S)方程、连续性方程、湍流封闭方程等;同化算法种类则比较多,常用的算法包括四维变分(4DVar)[14]、集合卡尔曼滤波(EnKF)[15]、伴随(Adjoint formulation)[16]等。从广义上讲,最近兴起的基于物理信息的机器学习(Physics informed machine learning)[17]方法也可归纳到同化算法当中,而不同的是其对历史测量数据库的依赖:通过对大样本历史数据库的学习从而构建从实验观测到待测物理场的虚拟映射关系。从流场形式上来讲,数据同化可分为稳态数据同化和非稳态数据同化[7]。顾名思义,稳态数据同化针对的流场一般为湍流雷诺时均场。非稳态数据同化与稳态相对,如4DVar方法。顺序数据同化作为非稳态数据同化的一种,是指在预测模型的时间正向积分中,不断引入动态观测数据对模型进行约束,从而修正模型的运行轨迹。动态数据的约束可以在每个时间步进行,也可以在模型运行过程中的若干时刻进行,而后者对于观测数据之间时刻的流场信息,依赖于模型本身的准确性以及前一观测时刻同化结果带来的时间相关性约束。在稳态数据同化中,预测模型一般包含RANS湍流模型方程[18-19],通过数据同化算法对模型方程进行修正。而这种RANS模型修正方法在顺序数据同化中效果不佳,因为湍流涡黏模型的修正不足以使流场得到快速响应,而一般在N-S方程中直接添加雷诺应力项以加快流场的改变。
鉴于数据同化的原理及优势,单纯的实验测量或数值模拟方法的缺陷有望得到弥补,从而发展实验测量与数值模拟的深度融合技术。本文结合国内外数据同化技术在湍流领域的研究成果,围绕其基本数学原理、实现方法、发展现状及应用进行综述。
1 湍流测量与数值模拟的挑战
湍流问题是困扰人类的世纪难题,其时间与空间上的多尺度特性决定了它与其他力学问题有着本质的区别。常规的湍流研究方法包含实验测量和数值模拟两大类,以获取流场速度矢量和其他衍生物理信息的时空分布为主要目标。
1.1 实验测量技术
湍流测量已由单点或者阵列式的传感器测量发展到了多维度的激光无侵入式测量技术。虽然高频响低噪声的点式测量技术在现阶段仍发挥着重要作用,但是高时空分辨率的多维和多场测量技术具有更重要的实际意义。PIV技术通过在流场中播撒示踪粒子,使用相机捕捉激光平面上粒子位移图像从而计算得到高分辨率二维速度矢量分布,已经在众多的工程领域得到应用[20-22],而后发展起来的二维三分量(2D3C)的Stereo-PIV和三维三分量(3D3C)的Tomo-PIV也越来越受到关注[23-24]。然而,这些测量技术也面临着诸多挑战,包括测量误差的影响、测量范围的限制以及多场同步测量的困难。以Tomo-PIV为例,由于相机景深的限制,测量区域在深度方向上尺寸不能太大,而激光光强限制了其能够测量的最大流速,相机的数量限制也导致了三维重构中会产生很多幽灵粒子图像[25],从而引起较大的测量误差。
流场中的标量(温度、浓度、压力等)分布也是湍流的重要特性,常用的测量手段有温敏漆(Temperature Sensitive Paint, TSP)[26]、热敏液晶[27]等壁面温度场测量,以及激光诱导荧光(Laser Induced Fluorescence, LIF)[28]等流域中温度或浓度场测量。LIF虽然能够实现三维标量测量[29],但同样受到硬件条件的限制。目前除了壁面的PSP测量技术[30]之外,对于流域内部的高分辨率压力场还没有直接测量的方法,而是间接地通过PIV测得的流场和控制方程逆向求解[31],受到PIV测量区域大小和误差的严重影响[32]。在众多研究当中,同步获取全三维的多物理场分布是分析掺混、传热、振动、噪声及化学反应的重要前提,比如发动机燃烧室中燃料的掺混和燃烧,这对测量技术带来了重大挑战。目前的成熟方法能够做到二维两物理场的同步测量[33-35],而对于三维或者更多物理场的同步测量还难以实现。
1.2 数值模拟技术
实验能够测量的湍流信息是有限的,而更全面的流场信息获取一般通过数值模拟的方式。由于湍流的多尺度特性,其数值模拟相对于其他物理过程的模拟难度更大。直接数值模拟(Direction Numerical Simulation, DNS)必须解析所有的湍流尺度,而无法应用于工程计算,常用的数值模拟方式为雷诺时均模拟RANS、大涡模拟LES和两者混合的分离涡模拟DES。
RANS计算量小而被广泛应用于工程计算,通过使用半理论半经验的封闭方程(RANS湍流模型),模化所有湍流尺度,仅求解雷诺时均场,因此,模拟结果的正确性很大程度上取决于RANS模型的表现。RANS模型的不确定度主要来自4个层面[36]:① 雷诺时均过程中湍流信息的丢失,导致湍流对时均场的影响只能通过时均场的相关函数来表示;② 雷诺应力的模化形式,比如线性的Boussinesq涡黏假设将雷诺应力张量模化成涡黏标量场;③ RANS模型方程的选取,也会对湍流模拟造成一系列适用性问题,不同的RANS模型最佳适应场合不一样,并且也无法准确复现复杂的湍流时均场;④ RANS模型常数都是根据简单典型的流场进行标定的,无法满足普适性要求。因此,除了用于模型标定的湍流附面边界层等流动之外,RANS方法对于复杂湍流场(甚至很多简单流场)的模拟,都会产生很大的偏差[37]。
RANS的误差来源于对全部湍流尺度的数学模化,而通过计算网格和N-S方程直接解析部分湍流尺度是提高数值模拟预测准确性的有效手段,因而发展了LES和DES方法。LES直接解析湍流中大尺度旋涡结构,而使用亚格子应力模型模化小尺度旋涡对大尺度结构的影响。在远壁区网格尺度满足LES要求[38]的前提下,因为绝大部分湍动能已经通过解析方法直接求得,小尺度结构的影响并不是特别明显,因此流场分布对亚格子模型并不敏感。而近壁边界层中湍流尺度非常小,这就大大提高了LES对网格的要求。在边界层网格分辨率不够时,LES结果会出现明显偏差,并影响远壁区的流场分布[6]。针对此问题,混合DES方法应运而生[5-6],通过使用RANS方法准确模化附面边界层流动,而使用LES解析分离和远壁区的大尺度湍流结构。尽管如此,DES方法仍然存在以下问题而制约其工程应用,包括RANS/LES耦合位置产生灰色区域、耦合之后原来的RANS和LES模型性能都发生了很大的变化、RANS往LES模式转换延迟、进口边界难以给定等问题,同时边界层转捩也是一个棘手的问题,通过补丁来修正模型方程,而不具备流场模拟的普适性[39-41]。
1.3 前景与挑战
单纯的实验测量和数值模拟存在各自的问题与缺陷,这2种方法的融合技术备受关注。数据同化使用到的实验观测数据和数值预测模型多种多样,比如在三维流场测量中,通过质量守恒约束来修正速度场的散度[42]也可以看成是数据同化的简单应用。而在工程应用领域,数据同化技术具有广阔的应用前景,同时也具有很多技术挑战。例如,通过二维PIV测量旋转机械若干截面上的局部流场分布而重建全三维流场和压力场,对其性能分析及优化设计具有非常重要的意义;通过快响应PSP测得飞行器壁面非稳态压力分布并融合数值模型,重构空间三维瞬态流场和压力场,从而获取声源信息分析远场噪声传播特性;在高超声速边界层模拟中,融合敏感位置壁面压力传感器数据和DES模型,使用观测数据驱动RANS与LES的动态耦合以及实时调整模型参数,显著提升DES模型对边界层转捩的预测精度等等。而针对不同的测量方法,使用怎样的算法来融合实验测量与数值模型使实测数据对数值模型产生最有效的控制与约束并降低计算量,以及如何考虑实测数据与数值模型各自的误差,则是数据同化方法的主要挑战。
2 基于雷诺时均的湍流稳态数据同化
鉴于RANS方法的工程应用优势,针对RANS模型进行数据同化研究具有广阔的应用前景。结合1.2节陈述的RANS模型4个层面的不确定度,数据同化工作主要从以下几个方面展开。
2.1 模型常数修正
在RANS模型提出初期,一般通过几种典型的流场来标定模型中的常数,而对于复杂的流场,通过修正模型常数可以获得模型性能明显的提升。Li等[43]提出了一种数据驱动的D-DARK(Data-Driven Adaptive RANSk-ω)方法来获取最优的模型常数。定义RANS模型的常数矩阵为θ,实验观测为φo,相对应的模型预测结果为φp,D-DARK的目的为将以下目标函数最小化:
(1)
式中:N为数据点个数;Wi为权函数矩阵。计算J对θ的导数Γ便可迭代求得最优系数矩阵。由于实际中无法获得φp(θ)函数的显示表达式,导数的获取通过单独扰动每个常数来获得。对每个模型常数相对于默认参数施加微小扰动,可得导数为
(2)
其中:lθ为模型常数的个数。模型常数便可通过式(3)来更新:
θ(n+1)=θ(n)-ξnΓ(θ)
(3)
其中:ξn为自适应迭代步长。通过多次迭代,模型常数θ便可收敛到J(θ)的极小值点θ*。值得注意的是,此方法并不能使J(θ)收敛到最小值,因此最终预测结果可能与观测值还存在较大偏差。
D-DARK方法实现起来不太方便,而另一种常用的方法是基于贝叶斯推断(Bayesian inference)或集合卡尔曼滤波(Ensemble Karman Filter, EnKF)的最优常数估计[13,44-46]。事实上,EnKF可认为是贝叶斯推断的一个特例,其基本的实现流程如图1[46]所示。首先对需要优化的常数围绕某参考值进行扰动并采样,再使用每组样本常数进行RANS计算获得预测空间的样本分布并与实验观测进行对比。EnKF的目的就是确定预测数据与实验观测吻合时对应的模型常数。下面以EnKF为例介绍其数据同化原理。

图1 基于贝叶斯推断模型常数优化流程图[46]Fig.1 Flow chart of model constant optimization based on Bayesian inference[46]
在EnKF数据同化中,使用xf表示模型预测的状态变量,可以理解为更新以后的流场信息;x0为初始状态变量,即初始流场信息;φ为流场时间演化的非线性函数;v为系统误差;w为实验观测误差;yexp为实验观测;H为状态变量空间向观测空间的映射函数。存在以下关系:
xf=φ(x0,v)
(4)
yexp=Hxf+w
(5)
EnKF的算法流程分为预测、分析和确认3个步骤。确认步骤有时可以省略,但对于N-S方程这样的强非线性预测模型而言,一般建议保留。在预测步骤中,对扰动之后的所有样本常数有
(6)
(7)

(8)
K=PHT(HPHT+R)-1
(9)

(10)
(11)
式中:R为扰动样本的协方差矩阵,其定义可见文献为分析步骤之后的状态变量样本;H为状态空间向观测空间的映射矩阵。确认步骤与式(10)和式(11)类似,只是对卡尔曼增益增加了一个松弛因子γ以增强计算的稳定性,即
(12)
(13)
其中:j为确认步骤中的迭代次数。经过EnKF同化之后的模型常数样本会分布在一个非常窄的范围内,进行样本平均之后即可得到最优化的模型系数矩阵。
通过不同RANS模型和EnKF数据同化常数优化获得的圆管射流结果如图2和图3所示[47]。射流的雷诺数为Re=6 000, PIV实验在水槽中进行,入口条件为充分长的圆管流动。图2展示了通过不同的RANS模型得到的截然不同的射流时均场,图中U为射流时均流向速度,U0为喷口流速,D为喷嘴直径,r/D为径向位置。k-ω模型预测的射流时均场与PIV测量结果的偏差最明显,但是其他的RANS模型结果偏差也比较大。图3显示,通过EnKF数据同化之后,所有RANS的预测结果均得到了很大的改善,尤其是k-ω模型。这说明,对于特定流场下标定的RANS模型常数,并不一定适用于非标定的流场情形,但是对于多种流场,可以通过重新标定模型系数来降低模型的不确定度。基于EnKF的数据同化方法提供了一种方便可行的常数标定方法,当然其他的一些方法[43, 48]也能达到类似的目的。

图2 不同RANS模型预测的射流时均场与PIV测量结果的对比[47]Fig.2 Mean flows of circular jet predicted using different RANS models and comparison with PIV results [47]

图3 基于不同RANS模型的常数数据同化结果及与PIV结果的对比[47]Fig.3 Data assimilation results based on constant optimization of different RANS models and comparison with PIV results[47]
2.2 模型形式误差修正
对于特定的RANS模型,其误差来源除了模型中的调节常数以外,另一个重要方面是模型固有的方程形式。对于湍动能k的计算,其确切的控制方程为
(14)
式中:U为速度矢量场;T′、P和ε分别为方程的传输项、生成项及耗散项,且T′和ε均与湍流的脉动统计特性有关,使得方程无法封闭。在k-ε方程中,使用梯度-扩散假设来对T′进行模化
(15)
其中:νt为湍流涡黏;σk为需要标定的模型常数。而对ε模化的整个方程则被完全经验式地认为与k形式相似。这种模化的表达形式给RANS模型带来了很大的方程形式误差[49]。在这方面工作中,Oliver等[50-51]基于贝叶斯估计在Boussinesq涡黏假设中增加了一个修正项,用来弥补RANS模型预测的误差,但这一修正项的选取及对观测数据的依赖关系,是该方法的关键。
另一种常用的方法是针对涡黏模型,在湍流生成项中增加空间(用x表示空间位置)分布的修正系数β(x),以修正模型的形式误差,而最优的β(x)分布可通过贝叶斯反演算法来获得[52]。以Spalart-Allmaras (SA)模型[53]为例, 有
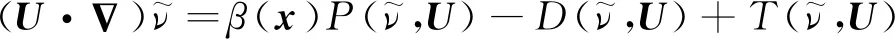
(16)

对于最优修正系数β的获取,更常用的一种方法是采用伴随方程的反演算法[54]。定义目标函数
(17)
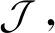
(18)
(19)
通过式(18)可计算得到全导数,从而使用梯度下降法逐步逼近获得最优的β分布。Singh等[54]使用此方法对光滑壁面流动分离做了数据同化研究,选用壁面压力系数为实验观测进行数据同化,在反演修正系数β之后,结果相对于默认的SA模型有了非常明显的提升。值得注意的是,此伴随方程完全通过离散的矩阵计算得到,需要很大的计算量且不方便实现,因而到目前为止,这种方法仅在二维流场计算中得到了应用。
为解决离散伴随计算量大、实施困难等问题,作者团队[16]提出了连续伴随数据同化(ABDA)模型。连续伴随方法早期被应用于拓扑优化研究,相比离散伴随方法表现出更高的工程应用价值[55]。为获取最优的修正系数β分布,定义拉格朗日函数

(20)

(21)
选择合适的伴随变量,使得式(21)的后3项为0,即
(22)
可求得伴随方程组为
(23)
(24)
(25)
对应的变量含义及边界条件见文献[16]。ABDA模型建立了方程驱动的连续伴随系统,联立主方程组(N-S方程、连续性方程和SA模型方程)和伴随方程组(式(23)~式(25))迭代求解即可获得最优β分布。相对于离散伴随方法,连续伴随方法避免了大型矩阵计算,更能适用于复杂三维流场的数据同化,如图4和图5所示的三维方柱分离与再附流动[16],其中使用了热线测得的若干位置流向速度Uexp为观测量,图中U0为来流速度。

图4 三维方柱计算域和实验观测数据的植入[16]Fig.4 Computational domain of 3D cube flow and implantation of experimental data[16]

图5 三维方柱流动反演得到的流场和β分布[16]Fig.5 Inversed flow and β distribution of 3D cube using data assimilation[16]
2.3 雷诺应力项修正
上述的模型修正方法均建立在Boussinesq涡黏假设的框架之内,尽管使用空间分布的β修正系数可以显著减小模型方程的形式误差,而其适用性仍受到标量涡黏νt的制约。为解决此问题,需抛开涡黏假设,发展对雷诺应力项修正的数据同化方法。Foures[56]和Symon[57-58]等使用连续伴随直接对雷诺应力项F进行同化,
(26)

(27)
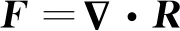
对雷诺应力的数据同化方法虽然可以不受涡黏假设的约束而获得非常好的结果,但是最明显的缺点是计算不稳定,以致对高雷诺数的流场同化几乎无法实现。作者团队对此方法进行了改进,提出了基于各项异性的湍流数据同化方法。
(28)
式中:νeff为流体分子黏度ν与湍流涡黏中各项同性部分νt0之和;与式(26)不同的是,这里F仅表示各向异性涡黏部分νta的贡献:

(29)
其中: “.*”为向量对应元素相乘符号。F通过使用连续伴随方程进行同化,而νeff则直接通过常规的RANS涡黏模型进行模化。F的分布会根据RANS模型的选取而有所变化,但是对于任何流场,均能同化获得最优F分布来复现真实湍流中雷诺应力的贡献,即
(30)
此方法相对于式(26)最明显的优势为,在稍微增加常规RANS方程计算量的前提下,利用各向同性涡黏明显提高了计算收敛的稳定性,而方法的适用性与式(26)一致。


图6 圆管的各向异性数据同化结果Fig.6 Results of anisotropic data assimilation of a circular jet
与DA-SA时均流场进行对比,其速度等值线几乎重叠。而如图6(b)~图6(c)所示,该数据同化方案中,雷诺应力项的还原非常准确,这相比于常规的SA模拟和各项同性ABDA模型(式(23)~式(25))有非常明显的改善。值得注意的是,式(16)所示模型方程形式的修正方案虽然能够显著提升流场的还原准确度,但是并不是建立在对雷诺应力项的准确还原之上,因此即使流场有显著改善,但是雷诺应力项可能与真实值(LES)间的偏差依然很大。
3 湍流的非稳态数据同化
3.1 4DVar变分数据同化
4DVar是一种基于伴随的非稳态数据同化方法,它的目的是根据一套初始状态值和实验观测来改善模型的预测轨迹,并通过当前和过去的观测数据准确预测未来状态。其基本的方程为[59]

(31)
(32)
Yt=H(Xt(x))+t
(33)
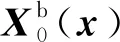
J(η,qt)=J0+Jt
(34)
(35)

(36)
其中:B为背景误差协方差矩阵;R为观测误差协方差矩阵。最小化目标函数J(η,qt)通过伴随系统计算J沿δn=(δqt,δη)方向的导数来实现,而最小化的评估区间为[t0,tf]时间段。对控制方程进行时间积分并引入伴随变量λt:


(37)
其中:∂XM为对应于非线性算子M的切线线性算子,引入伴随算子(∂XM)*和(∂XH)*满足:
(38)
(39)
并对式(37)进行部分积分可得
(40)
由于伴随变量满足

(41)
λtf=0
(42)
将伴随方程式(41)代入式(40)并使用dXt0=δη及dXt=(∂Xt/∂n)δn可得目标函数的导数为
(43)
(44)
式中:Q为预测模型误差的协方差矩阵,一般认为误差为中心高斯随机分布。
通过式(43)~式(44)求得的目标函数导数可以迭代确定最优的η和qt分布。具体的求解可采用差分-离散或者离散-差分的方法。前者为连续伴随方法,需要推导完整的伴随方程组和边界条件,而且使用到一些假设条件;而后者避免了方程的推导,直接通过数据驱动来进行系统求解,精度更高,但是如前所述,其计算量更大。由于伴随变量的λt的初始值未知,而只知道其终值λtf=0,这就意味着求解式(40)所示的伴随方程需要进行时间逆向积分,而对于主控制方程式(31)进行时间正向积分。由此,求解整个方程系统需要保存所有计算时间步下的结果以完成正向和逆向时间积分,并以此为一个迭代步数,整个系统经过若干个迭代步直至方程组完全收敛。4DVar变分同化是使用最广泛的数据同化方法之一,国内在数值天气预报、地理、核电等领域都有广泛的研究及应用[60-63],但尚未涉及到湍流流场的深入研究,国外近几年开始了对湍流流场的4DVar数据同化研究[64-67]。Mons等[64]对非稳态来流情况下圆柱绕流进行了4DVar同化,取圆柱壁面的压力系数为实验观测,使用4DVar数据同化获取最优的初始场及非稳态入流条件参数。结果显示,经过同化之后的流场和压力分布准确反映了周期性非稳态来流的影响。
3.2 顺序数据同化
4DVar数据同化实现了在整个时间段内的参数最优化分布,而最大的问题是需要进行时间正向和逆向积分,需事先获取整个时间段内的观测数据及保存每时间步的计算结果,存储量大且计算复杂。顺序数据同化(Sequential DA)实现了时间上的正向顺序推进,使用实时动态数据修正模型预测轨迹,其计算过程与常规的数值模拟类似,计算量相对4DVar显著降低。图7所示为顺序数据同化的原理示意图,通过在整个时间段内的正向和逆向积分迭代,4DVar数据同化获得了连续的时间序列并逼近观测数据。为降低计算量和存储量,顺序数据同化通过时间正向积分,同样使同化结果逼近实验观测,但是在有观测数据约束的时刻,通过对模型预测轨迹进行修正,使得结果出现不连续现象。这种不连续现象随着观测数据时间间隔的减小而减弱,当观测时间间隔等于计算时间步长时,同化结果理论上与4DVar一致。

图7 顺序数据同化原理图Fig.7 Schematic diagram of sequential data assimilation
Meldi和Poux[68]使用卡尔曼滤波构建了顺序数据同化方法,其在计算流体力学底层PISO (Pressure Implicit with Splitting of Operators) 算法中,将半离散形式的动量方程作为预测模型。
(45)

(46)

此方法的关键在于卡尔曼增益K的确定,如式(9)所示,K与实验测量误差、模型预测误差的协方差矩阵直接相关,这些协方差矩阵一般可以通过解析或者统计的方法来确定。统计的方法需要计算大量样本[69-70],这给顺序数据同化方法带来了很大的困难,而解析的方法需要计算预测模型误差传递特性,这对于N-S方程来说难以实现。
上述方法基于强烈假设来构建卡尔曼降阶模型,从而确定卡尔曼增益,其适用性和同化的准确性还有待提升。作者团队[32]基于4DVar方法进行改进,提出了基于连续伴随的顺序数据同化方法,避免了时间正向和逆向积分,较4DVar方法节省约90%的存储量。其基本原理与式(28)类似,在N-S方程中加入同化控制变量F
(47)
(48)
式中:流体黏度ν也可以用等效黏度νeff替代,从而引入亚格子尺度湍流模型。湍流涡黏可以使用LES或DES模型来获得。此问题的拉格朗日函数为

(49)
其中:与4DVar相同,[t0,T]为数据同化的时间窗口;为控制方程式(47)和式为在时间窗口[t0,T]中评估的目标函数,即
(50)

(51)

(52)
V(T)=0
(53)
其中:ρ为流体密度。
连续伴随方法通过推导确切的偏微分方程组及边界条件(见参考文献[32])降低了数据计算量。为了避免时间的逆向积分,将时间窗口缩短为一个计算时间步长,即[t0,t1],并使用欧拉格式对式(51)中的时间偏导进行差分,从而得到
(54)
式中:Δt为计算时间步长。变换之后的伴随方程式(54)消除了时间非稳态项,避免了时间逆向积分,在存在观测数据的时刻,可随主控制方程组同步求解,从而实现流场的顺序数据同化,其计算流程如图8[32]所示。图9[32]展示了射流流场的数据同化结果,观测区域选为0.2 图8 连续伴随顺序数据同化计算迭代流程[32]Fig.8 Iteration procedure of adjoint-based sequential DA[32] 图9 射流流场的伴随顺序数据同化[32]Fig.9 Adjoint-based sequential DA of jet flow[32] 机器学习方法在湍流研究中快速发展,推动了湍流的预测往人工智能领域迈进。数据驱动的机器学习模型直接通过流场数据本身进行学习训练,可以很好地构建相关物理量之间的映射关系,得到了广泛的研究与应用。此类模型算法在湍流特征提取[71-72],流场预测与重构[73-76],边界层分类[77],湍流模型优化[78],流场的模态识别[79]与时空分辨率增强[80-82]等诸多领域取得了很好的应用效果。但此类模型本身缺乏相应物理方程的约束,模型内部的权重与偏置系数的获取需要进行大量的数据训练拟合,同时模型的泛化能力有待提升。 近年来,基于物理信息的机器学习模型备受研究学者关注。Raissi等[83-84]提出基于物理信息的机器学习模型率先将传统的N-S方程与人工神经网络相结合并应用于涡激振动的圆柱绕流中,成功地从流场的某单一物理量信息(如速度场或浓度场)中提取出与之对应的其他物理量信息(如压力场)。其设计的基本网络结构如图10[84]所示, 其中,左边灰色区域部分为传统的全连接神经网络,网络输入为流场的时间与空间信息,输出为相对应的物理量信息,如速度(u,v),压力p和圆柱振动位移η。白色圆圈代表偏微分算子,用于求解计算相应物理量的时间与空间偏微分。右边区域为N-S方程的物理损失项约束,用于约束模型训练,使得模型预测结果满足物理方程的规律。 图10神经网络中的u、v、p、η这些物理量信息可以通过求解损失函数Jloss(式(55))的极小值获得。其中Jloss的前2项分别为实测的流场和圆柱位移与模型预测的流场和圆柱位移的误差,Jloss的最后一项为物理误差损失;当e1、e2、e3的值在模型训练中逼近于0时,则意味着相关物理量u、v、p、η满足了特定物理方程的约束。 |v(tn,xn,yn)-vn|2)+ (55) 现阶段,基于物理信息的机器学习方法还多局限于层流的预测,但是其基本的数学原理和约束方程同样适用于湍流问题。从基本数学思维上讲,基于物理信息的机器学习方法同样是为了最小化目标函数,且图10中物理约束方程与连续伴随方程(式(49))中的控制方程具有异曲同工之处。随着技术的发展,基于物理信息的机器学习方法也将在湍流问题预测和重构中发挥重要作用。 图10 N-S方程驱动的神经网络模型[84]Fig.10 N-S equation informed neural networks[84] 数据同化技术作为一种实验测量与数值模拟的耦合方法,在湍流研究领域发挥着越来越重要的作用。数据同化的主要应用之一可以概括为基于物理约束的辅助测量。在控制方程的物理约束下,数据同化辅助完成实验测量,获得更全面的流场数据。通过PIV数据来同化获得全场的流场信息是比较常见的应用,比如Dovetta等[85]通过部分区域PIV测量的时均流场获取翼型周围全场的流场分布,其还通过变分数据同化方法并以PIV为观测,获取了管内的全场流动信息,并进一步准确计算了剪切应力分布[86]。作者团队[87]展示了数据同化能够修正PIV测量的误差,获得更加准确的近壁方柱绕流全局流动分布。如图11[87](图中d为方柱截面的尺寸)所示,由于分辨率的原因,方柱下方的近壁射流区域无法被PIV准确测得,因而产生了很大的测量误差,而这被数据同化准确地还原了。除此以外,数值同化也可以用来预测流场中无法测量的衍生物理信息,比如温度场、浓度场、压力场等。 基于PIV流场测量的压力场计算是数据同化的重要应用[32, 66]。常规的方法是通过N-S方程求得压力梯度之后,再对压力梯度积分求得压力分布[31],但一方面要求获得三维的流场,另一方面受PIV测量误差影响,压力重构精度并不高。图12[32]为射流的压力场重构,以LES模拟的三维湍流流场为实验观测,数据同化获得的流场在图9中给出,可以看到非稳态压力场也被准确还原。而常规的压力梯度积分重构并没有得到比较好的结果,原因是在积分中容易导致误差积累,即使此案例中使用到的观测为LES纯净流场,图12(c)显示数值误差的积累也是一个非常严重的问题。 鉴于梯度积分法中需要对流场求时间导数,这就需要先获得时间解析的非稳态流场。而当流场的采样频率较低时,计算得到的压力脉动通常会偏大[88]。在数据同化中,不需要每一时间步都进行流场观测数据的植入,这就使得实验测量中流场的采样时间间隔可以100倍(甚至更高)于求解时间导数所需要的流场采样间隔。最近,作者团队[89]结合线性随机估计(Linear Stochastic Estimation, LSE),实现了从1 Hz的PIV测量数据同化获取1 kHz的非稳态压力分布。其首先使用1 Hz的PIV测量和1 kHz的动态压力传感器同步测量,获得了粗糙的1 kHz流场数据,再通过数据同化进行误差过滤,准确重构了1 kHz的流场和非稳态压力场。 常规的数值模拟结果与实验结果一般存在比较大的误差,结合数据同化技术,使用少量实验结果作为观测,可以有效提高模型预测的准确性。Meldi和Poux[68]在平板分离再附流场模拟中,使用基于卡尔曼滤波的数据同化方法在平板上方截面植入若干时刻的观测数据。图13[68](图中Hp为平板高度)中由于观测数据非常有限,数值模拟提升的幅度不大,这可以增加观测数据植入的时间频率来进一步改善模型预测。作者团队[16]提出的ABDA模型根据热线测得的若干位置速度分布降低湍流模型的不确定度。Singh等[54]使用类似的方法,通过数据同化反演获得翼型不同工况下的模型修正系数之后,结合机器学习预测任意翼型工况下的修正系数分布,从而建立了离线的数据驱动数值模拟方法(如图14[54]所示,图中C为翼型弦长)。 图13 平板绕流数据驱动模拟中不同下游位置的时均流向速度和横向速度分布[68]Fig.13 Time-averaged distributions of streamwise velocity at different downstream locations in data-driving simulation of flow over bluff plate[68] 图14 翼型表面压力系数Cp的数据同化反演与机器学习预测[54]Fig.14 Data-assimilation inversing and machine-learning simulation of pressure coefficient distribution Cp on a aerofoil[54] 使用数据同化技术也可以为DNS或LES数值模拟提供进口边界条件,从而显著缩小模拟区域,简化几何模型。Gronskis等[65]对圆柱绕流做了DNS模拟,其计算域为不包含圆柱在内的尾迹区域,同时使用4DVar技术,结合PIV测量结果,对DNS的入口速度分布进行数据同化。从其结果看出,在获取进口速度条件之后,DNS对下游尾迹区域流场的模拟与PIV测量结果非常吻合,同时相比PIV结果具有更高的分辨率和更低的噪声水平。 随着数据同化技术的发展,流场数据的精度和广度不断增加,而历史数据库的积累,为湍流的智能化铺平了道路。未来的世界是大数据的世界,数字孪生[90]也成为了湍流研究的发展方向,而更高效更准确地使用这些数据来预测未来的状态,是这项研究中的关键问题。Renganathan等[91]尝试了面向数字孪生范式的空气动力学数据融合,基于贝叶斯推断,结合数值模拟数据库和实测数据,重建机身表面高分辨率压力分布。其重建方案如图15所示,具体的变量定义和算法策略见参考文献[91],这里不做详细展开。类似的研究还包括众多基于机器学习的流场预测[92-94],而这些仅仅是迈出了大数据时代的一小步。纯数据驱动的人工智能使湍流丧失了物理本质,而物理信息的机器学习和数据同化技术在这一点上本质相同。 图15 基于传感器数据和贝叶斯推断的 飞行器气动力学预测[91]Fig.15 Aerodynamics prediction of aircrafts based on probe data and Bayesian inference[91] 本文综述了现阶段湍流的主要数据同化技术及应用。数据同化作为实验测量和数值计算的耦合方法,弥补了单纯实验测量和数值计算中的缺点和不足,提高了实验测量的精度和广度,改善了数值模拟的预测性能。 稳态数据同化一般结合RANS模型方程,从重新标定模型常数、修正涡黏模型方程形式误差、修正雷诺应力项等方面着手。基于EnKF的模型常数标定方法是一种显著提升模型预测精度的方便高效的稳态数据同化方法,而其方程的形式决定了其有限的适用性。基于伴随的数据同化能够对模型方程的形式进行修正,确定最优的修正系数空间分布,但是其仍处于涡黏假设的框架之内,对于某些复杂流场并不适用。而对雷诺应力项进行修正的数据同化适用性更广,理论上没有特定流场的局限。 非稳态的数据同化一般包括4DVar等时间连续的数据同化方式以及顺序数据同化。4DVar通过时间正向和逆向积分迭代,在整个时间段内对预测模型进行修正,但其缺点是存储量和计算量都非常大。顺序数据同化不需要时间逆向积分,可以在若干时刻对实验观测进行间断性地植入,不断地修正模型运行轨迹,其计算量和存储量与常规数值模拟相似。 数据同化在促进湍流研究发展方面具有非常重要的意义,成为融合实验测量和数值计算的重要手段,开拓了物性约束的辅助测量及数据驱动的数值模拟两条研究道路。随着机器学习、人工智能的飞速发展,湍流研究也向智能化迈进。基于物理信息的机器学习虽然现阶段还主要应用于层流预测,但是鉴于其基本的数学原理,也将在湍流领域获得广泛的应用前景。

3.3 基于物理信息的机器学习

4 湍流数据同化的应用
4.1 物理约束的辅助测量
4.2 数据驱动的数值模拟


4.3 基于大数据的流场预测

5 结 语
