机器学习在流动控制领域的应用及发展趋势
2021-07-05任峰高传强唐辉
任峰,高传强, 2,唐辉, 3,*
1. 香港理工大学 机械工程学系 流固耦合研究中心,香港 2.西北工业大学 航空学院,西安 710072 3.香港理工大学 深圳研究院,深圳 518057
流动控制常常按照是否有外部能量的输入分为主动流动控制和被动流动控制两类。其中,被动流动控制主要通过采用修改目标物体的几何形状来实现,比如在泳衣上采用类似鲨鱼表面的沟槽结构以实现减阻[1]。主动流动控制需要引入激励器(如吹吸射流[2]、合成射流[3]、等离子体激励器[4]等)以改变局部流动,进而实现全局的控制目标。如果激励器输出值根据流场中传感器的反馈信号得到,则称为闭环控制,否则为开环控制。流动的时空演化由非线性的Navier-Stokes方程主导,往往包含了高维、多频、多模态、多尺度等复杂特征,因此为控制带来了许多挑战。
作为实现人工智能最重要的途径,机器学习在近些年吸引了来自各个学科领域的大量关注,包括自然语言处理、计算机视觉、机器人等。机器学习致力于研究如何通过计算的手段,利用以数据为存在形式的“经验”来改善系统自身的性能[5]。因此,对于常常涉及海量数据的流体力学研究来说,机器学习亦已广泛引入[6],包括粒子图像测速(PIV)、图像处理[7]、湍流模型[8-9]、气动外形优化[10]等。
作为流体力学中的重要领域,对流动控制的研究也在不断引入机器学习的概念[6,11-12]。在这个背景下,为了展示目前机器学习在流动控制中的应用现状,本文将从3类方法出发,重点回顾目前基于机器学习方法的流动控制研究工作,包括面向流动控制基于机器学习的系统辨识与降阶模型、基于遗传规划的主动流动控制、基于人工神经网络与深度强化学习的主动流动控制。此外,本文将涉及到较为广泛的具体问题,包括气动弹性主动控制、钝体减阻、流致振动、射流掺混、热对流等。
1 面向流动控制的流动降阶模型
1.1 基于降阶模型的主动流动控制
在复杂流动的主动控制问题中,基于CFD仿真的主动控制律设计难度较大,并且由于对非定常流动和控制系统交互耦合的高保真求解往往耗费巨大,因此常建立非定常气动力降阶模型来处理。目前常采用的非定常气动力降阶建模方法可以分成两大类,即流场特征提取类模型和系统辨识类模型。流场特征提取类模型本质上是一种灰箱模型,包括线化稳定性分析法、本征正交分解法(POD)和动模态分解法(DMD)。为了向气动伺服主动控制系统提供高效高精度的状态空间模型,陈刚等[13]采用POD建模方法建立了气动伺服弹性降阶方程,并将其应用到主动控制律的设计中。Ahuja和Rowley[14]基于平衡截断思想,在POD基础上发展了BPOD方法,开展了平板大攻角分离流动的降阶建模和闭环反馈控制研究。
系统辨识类方法主要包括ERA模型和ARX模型。这类模型主要是通过辨识方法构建系统的有限输入和输出之间的传递函数关系,本质上是一种 “黑箱模型”。这类黑箱模型不仅计算效率高,还方便开展系统特性随参数的变化分析,因此在以流动控制为代表的多学科耦合研究方面具有无可比拟的优势。基于辨识类模型的流动反馈控制过程及其与CFD仿真的关系如图1所示,其中降阶模型通过CFD仿真数据构建,具备与CFD仿真相当的流场预测精度。ERA模型是基于特征系统实现算法,Flinois和Morgans[15]采用ERA方法开展了绕钝体涡街流动的低阶模型构建及闭环反馈控制。

图1 基于系统辨识类降阶模型的流动闭环控制示意图Fig.1 Schematics of flow closed-loop control based on reduced order modeling via system identification
针对跨声速气动弹性与流动控制的分析需求,Gao和Zhang等[16]采用自回归(ARX)方法构建了适用于不稳定跨声速抖振流动的线性降阶模型。该模型能准确地刻画流动稳定性随来流攻角和马赫数的变化,捕捉的抖振始发边界与数值模拟和实验结果吻合较好。进一步,针对跨声速复杂气动弹性问题的控制问题,张伟伟等[17]还开展了基于低阶模型的控制律设计。其中,闭环控制以升力和力矩系数为反馈信号,以机翼尾缘舵面转动的角度和角速度为控制输出,控制律设计分别通过极点配置和线性二次型调节器(LQR)方法实现。控制结果采用CFD求解器加以验证,发现二者均能有效抑制抖振,甚至能在非线性扰动和非设计条件下工作,证实其具有较优的鲁棒性。对控制律的进一步分析发现,最优控制参数在开环系统的反共振处得到,进而实现了反相控制。
1.2 机器学习与系统辨识和降阶模型的结合
在建立流动系统降阶模型的过程中,对气动力的辨识往往局限于线性层面,为完善对非线性气动力的系统辨识,许多研究者转向了机器学习和非线性系统辨识方法。机器学习方法将非线性动力学系统视为黑箱,通过模型训练进行参数学习,得到流场和气动力的降阶模型。基于机器学习和非线性系统辨识方法的典型非线性、非定常气动力模型包括Kriging模型、神经网络模型、模块式模型等。Kriging模型是一种非线性的插值方法,将未知函数视为低阶多项式与随机过程的叠加,其中低阶多项式考虑了函数的全局特性,而随机多项式考虑了局部特性。Glaz等[18]通过Kriging模型建立了非线性、非定常的气动力模型,并预测了NACA0012翼型的非定常气动力。胡海岩等[19]进一步将该模型扩展到变马赫数的非定常气动力预测。
神经网络模型是一种模拟人脑神经元处理信息的数学模型,具有很强的非线性函数拟合能力。张伟伟等[20]提出一种递归的RBF神经网络模型,通过神经网络的非线性建模能力近似大幅运动下的气动力变化,结合递归结构模型反映气动力的非定常效应。Mannarino和Mantegazza[21]采用类似思路,通过递归神经网络建立非定常非线性气动力模型,并进行气动弹性仿真。Winter和Breitsamter[22]通过模糊神经网络模型,建立了变参数的气动力模型用于不同马赫数下的颤振边界。
模块式模型是一种对线性与非线性动力学系统进行串联建模的模型框架。Wiener模型是一种动态线性模型和静态非线性模型串联的模型框架。胡海岩等[23]基于Wiener模型提出一种多输入多输出的非线性气动力降阶模型,该模型将通过线性状态方程与单层神经网络串联建立Wiener模型,通过逐个建立Wiener模型逐步降低建模误差。张伟伟等[24]为了考虑更强的气动力非定常、非线性效应,将标准Wiener模型中的非线性部分从静态非线性拓展为准动态的非线性模块,其中线性模块基于ARX模型,非线性模块基于RBF神经网络。结果表明这种新的Wiener模型架构在描述大幅运动的气动力响应上具有很高精度,且通过线性与非线性部分的两级训练保证模型对小幅运动下动态线性特征的预测精度。
模块式模型在结构小幅运动时,往往难以完全退化成线性模型,而采用并联结构模型则可以更好地兼顾系统的线性和非线性特征。Mannarino和Dowell[25]利用非线性状态空间模型建立了并联结构的气动力降阶模型。Kou和Zhang等[26]提出了分层降阶模型(图2(a)),其中线性的气动力采用了基于ARX模型的系统辨识方法,非线性部分则利用径向基函数神经网络(RBFNN)实现。线性模型和非线性模型输出的结果叠加而产生最终的气动力系数。通过在两种模型之间引入延迟,使得整体模型既适用于准定常问题也适用于非定常问题。
在该项工作的基础上,Kou和Zhang等[27]继续改进设计了基于机器学习的混合降阶模型架构(图2(b)),其中线性的气动力依然采用了基于ARX模型的系统辨识方法,而非线性部分利用多核神经网络实现。考虑到前述研究中[26]对线性和非线性气动力的建模彼此独立,非线性模型引入的偏差对线性模型并不产生影响,因而在改进模型中引入耦合机制和混合模型架构,使得建模的偏差能够反馈到输入数据中,从而使模型本身具备一定的自我修正能力。验证算例也证实模型在处理多种复杂气动力预测问题时均具有较高的精度。

图2 分层降阶模型框架和混合降阶模型框架[26-27]Fig.2 Layered model framework and mixed model framework[26-27]
经典神经网络模型采用比较简单的模型架构,对于复杂非线性和大样本的处理上存在泛化能力不足的问题。近年来随着深度学习方法的发展,深度神经网络在流体力学建模中逐渐受到关注。张伟伟等[28]提出一种基于长短时记忆网络模型(LSTM)的非定常非线性气动力降阶模型,该模型能够用于预测一定马赫数范围内的非定常气动力响应。结果表明这种模型比经典神经网络具有更高的泛化能力,在流动控制方面具有较大潜力。
Han等[29]发展了一套混合深度神经网络方法,用于从高维非定常流动数据中提取有用的时间和空间分布特征。该混合网络包含了卷积神经网络(CNN)、长短时记忆网络(LSTM)和逆卷积神经网络(DeCNN)。其中卷积神经网络从高维流场数据中提取空间特征以低维形式表达出来;长短时记忆网络从低维数据中获取时域特征以预测未来时刻的流场变化;逆卷积网络是卷积网络的逆过程,从低维数据中恢复出高维流场信息。该混合网络利用不同雷诺数下均匀来流分别流经圆柱和翼型的流场进行训练,在训练完成后预测未来时刻内的流场信息。经对比发现,基于该混合网络预测的流场与计算得到的真实流场吻合良好。
刘学军等[30]利用最新的生成对抗网络(GAN)结合卷积神经网络,建立了一类可参数化描述的超临界翼型与对应跨声速流场之间的对应关系,用以预测流场并进一步计算出翼型的气动力系数。该方法由于在模型内部引入了由生成器和评判器构成的竞争机制,因而在模型泛化能力上具有独特优势。尽管作者仅展示将其用于对翼型外形的优化,但该方法在系统辨识以及预测不同来流和攻角条件下的气动力方面亦具有一定的潜在优势。
须指出,上述机器学习与系统辨识和降解模型结合方面的研究工作目前还主要集中在对非线性气动力的辨识,即模型的建立层面。利用数据驱动的方式,完善不同控制条件对气动力乃至流场的影响,为后续流动控制尤其是闭环控制律的设计奠定模型基础。考虑到流动问题的复杂性,比如涉及高维强非线性的湍流问题,上述研究仍有相当长的路要走。
2 基于遗传规划的主动流动控制
2.1 遗传规划方法
遗传规划(GP,也译作“遗传编程”)是从遗传算法(GA)中衍生出来的方法[31]。在主体思想上,遗传规划和遗传算法都是受“物竞天择,适者生存”的生物进化思想启发,即一定规模的种群在接受自然的选择后,只有具有优势的个体才能够生存并有机会将自己的优势基因遗传下去,而未能通过自然选择的个体将会被淘汰并失去繁衍后代的机会。如此一来,在经历一定世代的进化之后,整个种群适应自然的能力将大大提高。为了增加种群的多样性,在进化过程中还引入了变异机制。与遗传算法不同的是,在遗传规划中,个体的表达并非简单的将一组数字进行二进制基因编码,而是利用LISP语言将之表达成显式的数学表达式。如此衍生的模型使得遗传规划在保留遗传算法优势的同时,具备了更加广阔的应用场景:包括具有回归、分类等特征的通用数学问题。表1比较了遗传算法和遗传规划的差异,其中,在遗传规划的结构形式举例中,sub、mul、cos分别表示减、乘、余弦函数。须指出,遗传规划中除了常规的四则运算外,并不限定数学运算的种类,实际应用中可根据研究者对具体问题的理解而添加。

表1 遗传算法与遗传规划的比较
遗传算法通过二进制编码,将可能的参数组合表达成染色体的形式,染色体的位数决定了参数组合有多少可能性。因而,遗传算法仅能输出离散而非连续过渡的参数组合,其在主动控制中的应用也主要限于对控制参数组合的优化。比如,Noack等[32]利用遗传算法对等离子激励器的电压、猝发频率、工作周期等参数进行了优化。Minelli等[33]利用遗传算法研究了高雷诺数钝体绕流开环控制的最优参数条件。此外,在常规的线性PID控制中,也可在确定3个控制参数的上下限后利用遗传算法筛选出最优的参数组合[34]。
对于闭环控制来说,由于显式控制律可视为以反馈信号为自变量、以激励强度为因变量的函数表达,恰恰与遗传规划的思想相契合。如此一来,由遗传规划生成一系列控制律,代入目标系统中分别评估其性能优劣(以特定的损失函数量化),并执行个体直接复制、交叉配对、变异等进化过程,在一定世代后便可收敛得到一定性能水平的控制律。
2.2 实 验
遗传规划在主动流动控制中的应用最早由Gautier等[35]在对后台阶分离流动的控制实验中引入。该项研究旨在减小后台阶分离区面积,其中,控制系统以PIV实验获取的二维流场数据为反馈信息,从台阶前缘附近壁面处的狭缝射流单元输出可调速度以改变流场。作者利用包含500个个体的种群,在经过12个演化世代后,即获得了收敛的控制律。基于最优控制律,分离区面积相比未控制时减小约80%。相比优化后的开环控制,该控制所包含的低频分量使得流动更易发生失稳,有利于流动在分离后再附。此外,该控制律在更高雷诺数下测试得到的性能亦优于开环控制,证实基于遗传规划的流动控制方法能够有效探索较优的控制方案。
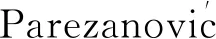

图3 剪切混合流动实验中基于遗传规划的流动控制框架[37]Fig.3 Flow control framework in GP-based mixing layer flow experiments[37]
Li等[38]开展了针对汽车模型减阻的闭环控制研究,其中以脉冲射流为激励手段,从模型后方布置的压力传感器获取反馈信号,并采用线性化的遗传规划模型,获得了22%的减阻效果。
周裕等[39-40]将线性化的遗传规划应用到了增强射流掺混的研究中。整个控制系统包含两个热线探针用以提供反馈信号,以及多个微射流激励器,控制性能以射流中心线上平均速度的衰减率进行量化。在使用多组微射流激励器协同工作[39]时,利用遗传规划得到的最优控制在控制性能大幅提升的基础上,还发现了一种新的复合流动结构,该复合结构兼具蘑菇状结构、螺旋运动、波动形式的射流柱等特征。而经过深入分析发现,这3类特征均有助于射流掺混的增强。该项研究有力证实了机器学习应用于流体力学研究时具有发现新知识的潜力。
在上述研究中,研究者在实验室条件下成功搭建了闭环流动控制系统,并实现了一定的控制目标,是近年来比较典型的遗传规划在流动控制中的应用范例,为后续工程化应用提供了重要参考。
2.3 数值模拟
遗传规划在执行过程中需要让一定规模的种群经过多代演化,而其中对每个个体的评价均需要在一次完整的实验或仿真中进行。在实验研究中,对个体的评价可以在较短时间内自动完成。但在CFD框架下同样的效率难以实现,因此目前鲜见基于遗传规划的主动流动控制在CFD框架下实现。利用GPU加速的格子Boltzmann求解器,唐辉等[41]首次将遗传规划应用到对圆柱涡激振动的主动抑制中,图4展示了求解器与遗传规划的交互框架。在该问题中,CFD求解器用于获取圆柱在施加不同吹/吸控制时的流场信息及其受到的流体作用力,并通过求解展向结构运动方程以获得实时的结构动力学响应。遗传规划中使用50个个体的种群规模并执行了25个世代的演化。在演化过程中,仅在3个世代后即收敛至最优的控制律,并且发现最终性能前10位的控制律均表现为吸入模式。此时,圆柱的振动幅度受抑制达94.2%。在权衡了能量消耗的性能指标中,遗传规划相较最好的开环控制实现了21.4%的性能提高。从图5可看出控制后圆柱的尾涡在强度和形态等方面均发生了较大的变化。此外,遗传规划控制在雷诺数100~400范围内均获得了较一致的控制效果,而传统的比例控制却显示出较差的鲁棒性。

图4 基于遗传规划的涡激振动主动控制系统数值模拟框架[41]Fig.4 Numerical simulation framework of active flow control loop for suppressing vortex-induced vibrations using GP[41]

图5 处于涡激振动中的圆柱尾涡形态Fig.5 Wake pattern of a cylinder undergoing vortex-induced vibrations
上述研究基于高保真数值模拟手段,避免了实验条件下可能存在的一些不确定性因素,如测量误差、外界干扰、硬件的时间滞后等,为开展基于机器学习的流动控制提供了重要参考。但囿于机器学习过程中的大量硬件、时间成本,在不牺牲计算精度的前提下如何拓展到高雷诺数下的控制问题,仍是目前面临的一个重要挑战。
3 基于人工神经网络与深度强化学习的主动流动控制
3.1 人工神经网络
人工神经网络(ANN)受生物神经系统作用机制启发而来。以常见的多层感知机(MLP)为例(图6),该网络结构包括输入层、隐藏层和输出层,其中隐藏层可以是单层或多层。每一层包含一定数目的神经元,而每一个神经元可以接收上一层所有神经元传递的信息,在经过加权求和处理后施加激活函数,最终结果作为该神经元当前的数值。该过程数学表达式为yi=f(Σwijxj+bi),其中wij为该神经元yi接收上一层神经元xj的权系数,f为指定的激活函数,bi为偏置因子。常用的激活函数包括relu(y=max(0,x))、tanh(y=tanh(x))、sigmoid(y=(1+e-x)-1)、softplus(y=ln(1+ex))等,对应函数图像如图7所示。在学习过程中,利用网络的后向传播,通过梯度下降等优化方法,可以对网络中权系数和偏置因子的取值进行更新。最终的策略便是由这些权系数和偏置因子决定。

图6 多层感知机示意图Fig.6 Schematics of multi-layer perceptron

图7 常见的4种激活函数Fig.7 Four typical types of activation functions
ANN的诞生是人工智能发展进程中最重要的里程碑之一。在此基础上,研究者还发展出卷积神经网络(CNN)、递归神经网络(RNN)、长短时记忆(LSTM)、门控循环单元(GRU)、生成对抗网络(GAN)等更加复杂的网络结构[42],以应对科学研究或现实应用中的一些复杂场景。
3.2 深度强化学习
强化学习是机器学习中侧重于同环境进行交互,并在此过程中获得最大累积奖励的一类方法。在围棋比赛中领先人类顶级棋手的AlphaGo[43]、AlphaGo Zero[44]等使得强化学习这一概念为世人所熟知。值得指出的是,AlphaGo除采用强化学习外,还依赖于现存的棋局比赛数据以进行监督式学习。而比赛表现更为出色的AlphaGo Zero则仅仅使用了改进的强化学习方法,在游戏规则下通过自我对局来不断地提升自身策略水平,除棋局本身的规则和对棋局的特征设计外并不需要任何人类指导。由于强化学习常常借助于深度网络结构,来构建模型中复杂的状态输入和输出之间的关系,因此这类方法常被称为深度强化学习(DRL)[45]。2015年发表于《Nature》上的工作——基于深度强化学习获得与人类水平相接近的控制[46]也使得DRL这一概念成为学术研究的热点。
在包含DRL的控制系统中,智能体(Agent)从环境中获取必要的状态信息,决定输出动作的大小以对环境进行干预,然后通过特定的函数计算出动作对环境的影响大小。如图8所示,该回路与闭环控制系统思路大体一致,其中状态信息(States)由传感器获取,动作(Actions)输出由激励器执行,控制效果评估与动作奖励(Reward)同义。因此,基于DRL的许多具体应用也是针对控制相关的问题展开的,如机械臂控制[47]、自动驾驶[48]等。由于深度学习本身在提取复杂系统(如混沌系统)的非线性特征方面已展现出优秀的能力[49],而且从原理的角度来看,大多数强化学习方法本身亦不受系统的非线性特性限制,因此可以预期,DRL在流动控制中具有极大的应用潜力和优势。

图8 深度强化学习与环境之间的交互回路Fig.8 Interactive loop between DRL agent and environment
3.3 壁湍流控制
湍流是流体力学的核心问题,对湍流的主动控制也是流体力学界关注的焦点[50]。利用神经网络对壁湍流进行主动流动控制可追溯到Lee等[51]的一项采用壁面吹/吸激励器旨在减小槽道湍流壁面阻力的研究。该问题提出的背景源于Choi等[52]提出的设想,即通过从壁面施加与距离壁面y+=10位置处的法向速度相反的吹/吸速度来改变湍流的上扬与下扫运动,进而减小壁面的阻力。Lee等提出,上述y+=10位置的法向速度传感器可以由壁面上测得的展向切应力代替,而二者的关系可以在控制前预先由ANN建立(见图9[51])。基于这一设想,作者在Reτ=100的流动工况下,在流向和展向适当位置处提取展向切应力,使用100个神经元进行训练即获得了稳定的目标速度与壁面切应力之间的关系。利用该关系即可施加与Choi等所提出设想类似的闭环主动控制,换言之,该方法可视为与文献[52]中直接主动控制方式相对应的间接方式。通过对比,这两种方式产生的激励作用相当。结果表明,基于ANN的闭环控制最终获得了高达20%的减阻效果。

图9 基于神经网络的槽道湍流减阻网络结构[51]Fig.9 Network architecture for drag reduction of turbulent channel flow[51]
许春晓针对湍流相干结构和壁湍流的减阻问题展开了大量研究[53]。采用与Lee等[51]相似的思想,杨歌[54]利用主动变形壁面对槽道流动施加了主动控制,并重点对比了神经网络、次优控制等方法在减小壁面阻力方面的性能。发现神经网络可视为次优控制在仅考虑物理空间内控制点展向流动信息的特例,其最终性能也略逊于次优控制。
侯宏和杨建华[55]将神经网络应用于边界层转捩的主动控制中,其中利用抽吸控制转捩的实验数据训练神经网络参数,从而构建了抽吸速度和边界层转捩位置之间的函数关系,据此通过反推,实现了以最小的抽吸能量代价保持转捩在特定位置发生的效果。
可以看出,上述早期基于神经网络的主动流动控制研究大多偏向于在已探明一定的控制策略或物理规律的基础上,使用神经网络对未知关系进行数据回归操作,因而在探索有别于已有策略之外的控制策略方面具有一定的局限性。比如,在槽道湍流减阻研究中,Choi等[52]提出的线性反馈控制思路尚未被证实为最优或在考察其他几何外形的壁湍流及大雷诺数范围时具有普遍意义,新的控制策略尚待发掘。
3.4 钝体绕流控制
对钝体绕流的主动控制一直是学术界和工程界研究的重点,包括钝体减阻、减小升力波动、抑制振动等。Rabault等[56]利用最新的DRL方法,即近端策略优化(PPO),实现了圆柱减阻的闭环控制。在该问题中,作者在圆柱周围和尾流中布置了151个速度传感器,使用一对吹/吸射流器对流动施加控制作用。其中,吹/吸射流器对称布置在圆柱上下表面,以一个射流器吸入另一个射流器吹出的模式工作。基于PPO方法,根据传感器观测到的流动信息便能实时作出控制决策。基于DRL的学习过程见图10[56],其中横坐标表示训练集数(Episode),纵坐标为阻力系数CD,每次训练可视为一次单独的数值模拟算例,所获得的奖励函数采用多种方法进行了平均化处理。经过约300次训练集数的训练后,即可获得收敛的控制策略。基于该策,可使得圆柱的绕流阻力减小约8%,此时,圆柱的回流区大幅延长,涡脱落的强度也被大大弱化。
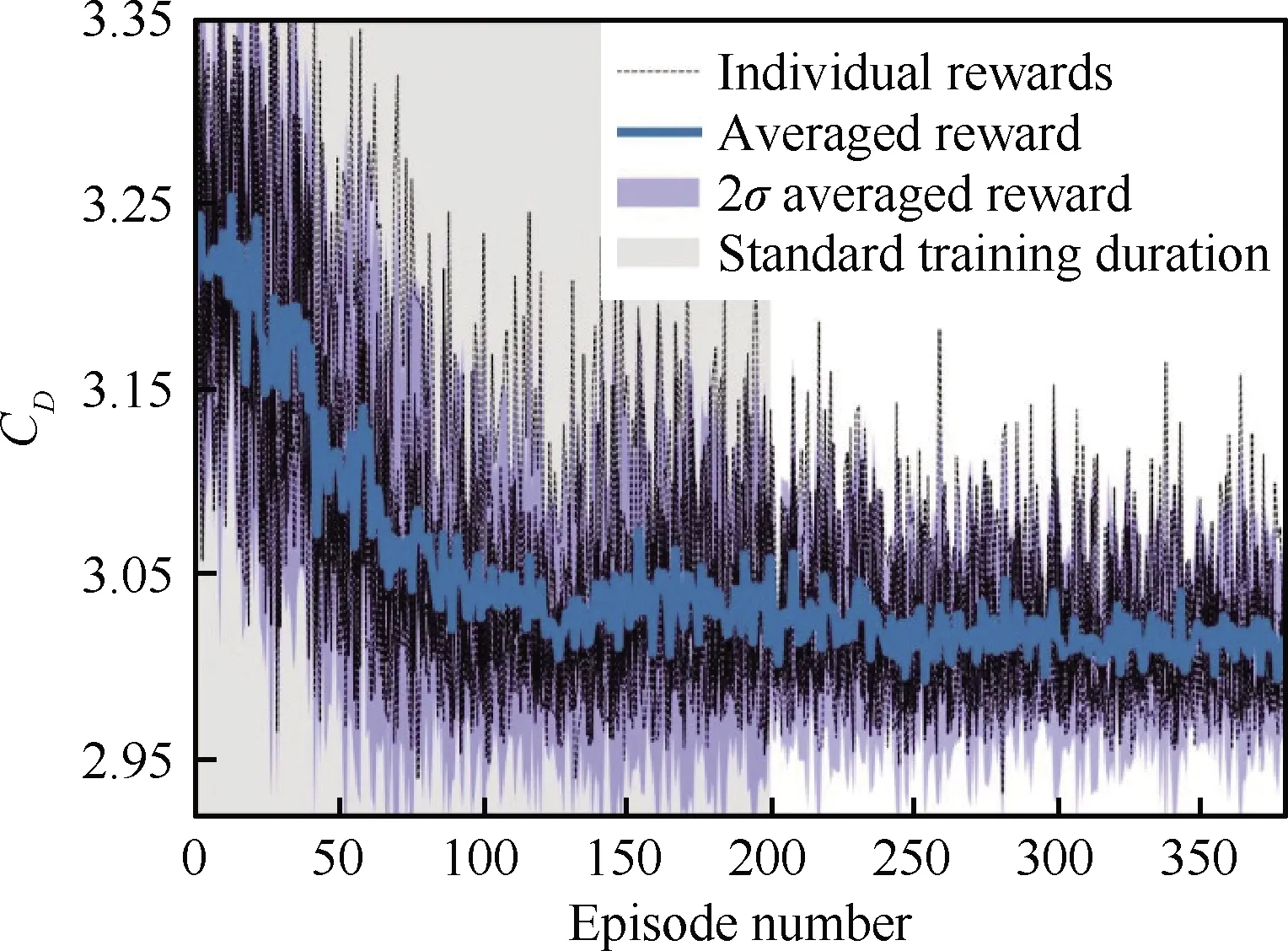
图10 基于DRL的圆柱绕流主动控制学习曲线[56]Fig.10 Learning curves for DRL-based active control of flow past a cylinder[56]
为了提升学习效率,Rabault和Kuhnle[57]还提出了多环境分布式同步学习的算法。该算法中,智能体同时收集来自多个环境中的状态信息,以相同的策略给出动作概率分布,控制得到的奖励值也同样被收集到智能体中。其中,多环境的模拟可以在多个设备中同步完成,相当于构建了环境之间互不干扰的并行计算环境。如此一来,原先需要在一个环境中执行交互的任务分散到多个环境中完成,在几乎不影响学习进程的基础上,大大减小了学习过程所消耗的时间。
基于相同的流动求解器和DRL框架,文献[58]将上述研究拓展到雷诺数100~400的范围。
在此范围内,采用4个射流激励器获得了最高可达38.7%的减阻率。此外,通过与采用对称边界的算例相比,发现DRL获得的减阻效果与其十分接近,侧面说明了DRL习得的策略能够有效抑制涡的产生和脱落。
采用格子Boltzmann方法求解器,唐辉等[59]首先复现了Rabault等在层流条件下的控制结果(见图11),随后针对湍流条件下(雷诺数1 000)圆柱绕流减阻开展了详实的研究。在该工况下,流动呈现出更加复杂的非线性特征,这大大增加了DRL习得较优控制策略的难度。针对该问题,作者除采用常规的随机初始策略外,还采用层流工况下已习得的策略作为初始条件,此时DRL智能体在已掌握层流条件下控制策略的基础上随即开始探索更加复杂的流动环境。结果发现,两种初始化策略尽管寻找最优控制策略的路径不同,却获得了相一致的最终策略,说明DRL本身具有较优的鲁棒性。在雷诺数1 000的工况下,所有独立的学习过程在2 000次的学习集数内最终均获得了约30%的一致减阻效果,此时从时均流场来看,圆柱尾流中的回流区相比未控制时大幅度延长,且尾流内的速度波动和雷诺应力均得到了大幅抑制。
图11 层流条件下的圆柱尾流形态Fig.11 Wake pattern of a cylinder in laminar flow regime
Ren和Tang等[60]还提出采用闭环控制系统实现钝体水动力隐身的设想,并借助DRL加以实现。在该闭环控制系统中,激励器采用了一组前吸后吹射流器,反馈信号由在钝体尾流中布置的一组速度传感器阵列提供。实施实时控制时,由DRL智能体根据反馈信号给出当前的动作输出。利用这套系统,钝体尾流的速度亏损可以在开启控制后短时间内消除,同时该钝体受到的流向和展向作用力均趋近于零。此时在距离圆柱2~3倍直径以外的位置上仅凭借对流场的观测已经难以感知结构体本身的存在,即实现了水动力意义上的隐身。
须指出,上述利用DRL实施的闭环流动控制虽然都基于CFD工具实现,但在设计系统架构时往往也考虑到了实验的可行性,包括激励器的选取、传感器信号的获取等。作为较新颖的概念,可以预期,将DRL应用到实验研究中并进而推广到工程问题中,应当是目前许多研究者的共识。不过,计算与实验之间存在大的差异,包括传感器获取数据的实时性,传感器、激励器和处理器之间的延迟,以及测量的不确定度等。为解决上述问题,不仅需要采用先进的硬件设备,在数据预处理等算法层面也亟待深入探索。
3.5 对流控制
对流在自然界中十分普遍,在大的空间尺度上包括大气中的环流、城市的热岛效应等,小尺度上包括换热器设计、反应釜内的对流流动等[61-62]。基于深度强化学习PPO方法,Beintema等[63]以Rayleigh-Bénard对流为物理模型开展了以抑制对流、使流动趋稳为目标的闭环控制。在整个宽高比为1的封闭对流腔体内布置了8×8个 监控点,每个监控点提供当前和此前3个时间步的温度及速度信息,以此作为控制系统的状态空间。在满足下壁面温度平均值不变的前提下,通过在下壁面布置10个温度可调的激励单元,每个单元仅能输出两种离散的温度值,以此作为控制系统的动作空间。控制过程以降低Nusselt数为目标,选取了Prandtl数为0.71(对应常温下的空气)和Rayleigh数为103~107区间段的工况。在该Rayleigh数范围内,未施加控制的对流流动尚未达到湍流发生条件。将基于DRL的主动控制与参数优化后的PID控制进行了对比,表明DRL在选取的整个参数范围内均获得了较优的控制效果,而PID控制在Rayleigh数达到3×106后即失效,且在所有Rayleigh数下DRL控制的性能均优于PID控制。通过对瞬时温度和速度场的分析也发现,DRL控制在部分Rayleigh数条件下能够破坏大尺度环流,并诱导产生一对涡流,该流动有利于抑制传热过程。
上述研究探索了多个激励输出条件下,将深度强化学习用于典型对流流动问题的控制,并通过一定Rayleigh数范围下与常规线性控制算法进行比较,证实了算法的有效性。相信后续围绕更高Rayleigh数条件下的闭环控制,会吸引学术界更多的兴趣。
3.6 生物体运动行为操控
自古至今,自然界中的鸟飞鱼游都是为人类探索流动现象带来启发的重要源泉。在人工智能飞速发展的今天,科学家们也自然思考能否为人造生物体赋予自主思考、决策的智慧,使其在同环境进行交互的过程中逐渐习得一定的技能,从而为相关研究带来更广阔的想象力空间[64]。事实上,强化学习的思想也较完美地契合了这一想法。
在晴朗的天气中,迁徙的鸟类可以利用上升的对流气流所产生的升力助力其飞向更高的天空。为了理解其中的物理机制,并探索如何将这一自然界现象应用到滑翔机中以延长其航行距离,Sejnowski等[65]借助强化学习方法实现了这一构想。他们首先对鸟类滑翔的动力学模型进行了简化,并假设滑翔过程中对背景流场无影响。上升气流流场建立在边长1 km的计算域中,利用CFD求解器预先计算经典的Rayleigh-Bénard对流得到。飞鸟在滑翔过程中能够感知其上升加速度、上升速度、翼展向力矩和当地温度等信息,通过基于SARSA模型的强化学习智能体作出决策,以此调整自身的攻角和倾斜角,最终以获得尽可能大的爬升速度以及爬升到尽可能高的海拔位置为目标。通过学习,发现感知上升加速度和展向力矩对于决策最为有利。强化学习习得的策略表明,在遇到单个上升羽流时,控制倾斜角最为有效;而遇到多个上升羽流时,对攻角的控制发挥着更加重要的作用。此外,该习得策略可以有效过滤小的湍流脉动的干扰,利用大尺度上升羽流。
Verma等[66]利用强化学习研究了鱼类在群游过程中,位于后方的鱼如何从前面鱼的尾涡中提取机械能以助力其游动。该研究基于CFD求解器进行,其中流动通过直接求解Navier-Stokes方程得到,鱼的身体摆动通过给定的基准曲率方程与3个参数可调的方程叠加得到。身体形状对应的可调参数利用基于深度Q网络(DQN)的强化学习获得。为了赋予鱼记忆过往行为的能力,在DQN模型中还使用了LSTM网络。结果表明,DQN训练后的鱼能够将自身置于前面鱼产生的涡环的适当位置来更好地利用涡流中的机械能。利用二维环境中习得的策略还成功拓展到三维的环境中(见图12[66]),证实了算法的可拓展性和习得策略的鲁棒性。

图12 三维鱼游[66]Fig.12 3D fish swimming[66]
Colabrese等[67]利用强化学习探索了具有趋地性的粒子如何运动到最大的高度位置,同时避免在该过程中受到背景流动的影响而陷入涡流中。作者引入经典的二维Taylor-Green流动作为背景流动,并假设这些粒子的行为不会对流动产生影响。运动的粒子能够感知背景流动中的涡量和自身的运动方向,借助基于Q学习的强化学习(学习过程见图13[67])所赋予的自主决策能力,判断出下一步的优先运动方向(见图13子图),进而调整其运动轨迹。通过学习,粒子能够以较大概率有效利用背景流动的速度趋向高海拔位置运动,而避免陷于涡流中。此外,作者还发现在对背景流动施加一定程度干扰时,获得智能的粒子仍能够较好地完成任务,证实已习得策略具有较好的抗干扰性。

图13 10个不同学习过程获得的回报曲线(子图表示习得策略,即不同状态对应的优先动作)[67]Fig.13 Learning gain for 10 different learning processes, where the subfigures represent the learnt policy, i.e., preferred action for each state[67]
4 总结与展望
本文回顾了近年来国内外研究者在探索将机器学习应用到流动控制研究的过程中所取得的进展。可以看出,在特定的研究中,机器学习用于主动流动控制,在性能方面较常规方法能带来更优表现,并且能在性能、效率、鲁棒性等方面取得较好的平衡。
从应用的角度出发,利用机器学习可以为流动的闭环实时控制提供关键的控制律设计指导。其中,利用遗传规划可直接获得显式的控制律数学表达式,而对于深度强化学习则以神经网络(动作器)的形式给出了控制律。可以预期,机器学习能够为流动控制的工程化应用带来极大助力,智能化流动控制的概念也将逐渐获得研究者的青睐。
此外,基于机器学习的流动控制方法在改善相应问题控制效能的同时,伴随着新颖、复杂的物理现象,这也为学术研究开拓了更为广阔的空间,有助于探索新的现象,从中提取概括出新的知识,并形成新的理念。
应当指出,机器学习在主动流动控制中的应用尚处于起步阶段,在解决一些复杂流动问题时仍存在诸多挑战。此外,基于机器学习的流动控制作为一种相对新颖的概念,在许多问题的认识上学界尚未形成统一的观点。大体而言,这当中的共性困难包括:
1) 湍流、流致振动等问题中,由于流动系统本身存在强非线性,演化/学习过程存在强随机性,因而基于同样的初始设置所产生的结果往往存在一定的差异,这种差异会影响到结果的可重复性。
2) 多输入多输出(MIMO)问题中寻找最优控制律/控制策略的难度显著增大。事实上,该问题在不同领域中具有普遍意义,在深度学习中,该问题常被称为“维数灾难”[68]。
针对主动流动控制,机器学习与降阶模型的结合是一种相对低成本的方法,同时也是极有潜力的解决方案。但在对复杂非线性问题建模时也存在保真度、易拓展性等诸多需要考量的难题。对于本文提到的遗传规划和深度强化学习方法,在展示自身出色能力的同时,也为研究手段提出了较高的挑战:
1) 在数值模拟研究方面,高效、高精度的计算始终是CFD研究者追求的目标,但常常也是一对相互矛盾的指标。显然,机器学习的引入对上述两项指标提出了更高的要求。在不影响最终机器学习结果的前提下,如何在二者之间取得较好的平衡,是摆在研究者面前的重要问题。使用并行计算算法和设备[41]、采用分布式算法[57]等方案是目前较为可行的方法。
2) 在实验研究方面,机器学习要求控制系统具有较低的不确定度和较低的时间延迟,因此也对传感器、激励器的硬件性能和算法处理的时效性提出了高要求。
未来在机器学习推广到实际的工程应用问题中还伴随着更具挑战的课题:比如,对于钝体减阻问题,实际的工况可能涉及到十分复杂的情形,如来流具有高湍流度、强扰动、横流等特征,这些复合因素往往难以通过数值模拟或实验全部复现。因而,在这些情况下,闭环的流动控制系统如何从受干扰的流动环境中提取有效状态信息并作出反应,既难以预测也难以干预。面向未来和实际应用,在研究过程中还存在多种复杂因素,需要加以关注并探索解决方案。
