基于数据挖掘的飞行器气动布局设计知识提取
2021-07-05刘深深陈江涛桂业伟唐伟王安龄韩青华
刘深深,陈江涛,*,桂业伟,唐伟,王安龄,韩青华
1. 空气动力学国家重点实验室, 绵阳 621000 2.中国空气动力研究与发展中心 计算空气动力研究所, 绵阳 621000 3.西南科技大学 环境友好能源材料国家重点实验室, 绵阳 621000
气动布局设计是将飞行器的梦想变成现实的第一步,气动布局方案设计特别是早期的概念设计极其重要,决定着飞行器的设计质量、设计效率和设计成本,是飞行器气动性能、飞行性能等的决定性因素,也是飞行器研制成功的基础和关键[1]。为获得满足设计总体要求且整体性能达到最优的飞行器布局方案,气动布局设计通常需要在充分考虑尺寸/规模/操稳/防热等多种约束下,在不同学科的设计目标间进行反复多次迭代、折衷平衡和优化组合,因此其本质上是多学科相互交叉耦合作用下的多目标优化过程[2-6]。
当前气动布局多学科多目标优化设计仍面临诸多挑战:一是在早期布局概念设计阶段,设计人员对不同学科优化目标之间的内在关系及设计变量对优化目标的影响规律通常缺乏直观深入的认识,可能导致所构建的优化模型不够高效合理,带来优化耗时过长或者不能获取满意的优化结果的问题;二是多目标优化通常包含多个互相冲突和矛盾的目标,最终得到的优化结果是一系列非劣解集,需要设计人员根据某种偏好进行选择,这种选择将影响飞行器后续一系列的设计过程,如何刻画和获取气动布局设计所关心的目标之间的权衡关系,为最终布局方案的选取提供科学的决策支撑也是一个需要解决的问题;三是飞行器的布局设计强烈地依赖于设计者的设计知识和经验,基于先验设计知识的指导可以有效缩短设计选型周期,而现有的设计优化过程对设计人员而言更像是黑盒子,该过程只给出最终的优化结果,忽略掉了大量的中间设计状态所蕴含的设计规律及知识,如何获取其中的隐含信息并积累形成针对同类飞行器的设计指导知识,也是一个需要解决的问题。
数据挖掘技术是基于统计理论、机器学习、人工智能等算法从大量的数据集合中获取有用隐含信息,并通过规则和可视化等方式予以展现,形成知识发现的过程[7]。由于它可以有效地对大量数据进行分析,并方便直观地洞见复杂参数间的关联关系及影响规律从而解决上述问题,因而在多学科优化设计领域逐渐受到关注。Simpson等认为数据挖掘技术可以帮助分析设计变量对目标性能的影响关系,为同类设计提供设计信息,提高设计过程的效率和可靠性[8-9];Jeong等[10-11]基于总变差分析(Analysis of Variance,ANOVA)、自组织映射(Self-Organizing Map,SOM)、决策树及关联分析等方法开展了机翼翼型设计的知识挖掘研究,得到了翼型设计的敏感变量;Chiba等[12-13]基于ANOVA、SOM及粗糙集方法对机翼的设计空间开展了数据挖掘研究,总结并分析了不同方法的使用特点;邱亚松[14]基于等度量映射(Isometric Mapping,ISOMAP)等方法开展了二维翼型气动设计中满足几何约束的特征空间降维提取研究,以提升优化效率;汪伟等[7]基于K-means聚类及决策树方法,郭振东等[9]基于显著变量识别、ANOVA及SOM 3种方法对叶轮机叶片的设计开展了数据挖掘研究,获取了有益的叶片设计知识。总结来看,目前的数据挖掘技术在翼型、叶片等设计中已经得到了初步应用,但将数据挖掘技术用于飞行器整体布局选型设计知识提取的研究还较少。
本文为了解决当前飞行器气动布局多目标多约束设计优化过程中存在的问题,对数据挖掘技术在飞行器气动布局优化问题隐含设计知识提取中的应用开展了探索研究。以高升阻比滑翔飞行器布局设计优化问题为例,基于当前比较有代表性的ANOVA、SOM、决策树、ISOMAP 4类算法对气动布局设计中产生的中间数据进行了挖掘,并对不同方法得到的升阻比、横/侧向稳定及容积率4种目标性能间的权衡关系,目标性能与设计变量间的敏感性关系及产生较优布局外形的设计变量取值空间及设计规则进行了对比分析,凝练形成了适用于该类飞行器的设计知识,对4种方法的特点及适用性进行了总结分析。
1 高升阻比滑翔飞行器气动布局优化问题
无动力助推滑翔高超声速飞行器是当前高超声速飞行器的一个重要研究热点。升阻比是该类飞行器最为关键的设计指标[15],但高升阻比通常意味着更尖锐的前缘和更扁平的机身,这给防热和装填容积等都带来了严峻的挑战。美国HTV-2飞行试验的失败表明,该类飞行器扁平式设计的横侧向稳定问题也应当成为设计关注的重点[16]。因此典型的扁平对称式高升阻比滑翔飞行器的设计需要考虑升阻比、防热、容积率、横侧向稳定性等性能的综合寻优。
1.1 设计目标及约束
如图1所示,笔者在前期工作[17]中为改进HTV-2存在的横侧向稳定性问题,提出了一种带两侧小翼的扁平对称升力体构型滑翔飞行器,飞行器的横侧向稳定性与小翼的尺寸密切相关。围绕其升阻比/防热/操纵与稳定性3大核心问题开展了气动布局多目标优化设计研究,具体选取典型飞行状态点高度Η=50 km,马赫数Ma=15,迎角α=6°条件下的4个优化目标及约束:

图1 带小翼的扁平升力体构型[17]Fig.1 Flatted lifting-body configuration with winglets[17]

4) 飞行器容积率尽可能大,即目标函数F4=V2/3/S取极大值,V代表机身体积,S为飞行器的俯视投影面积。
同时考虑防热需求及当前的防热材料限制,要求飞行器布局典型飞行弹道状态下驻点热流满足约束:qs≤4 500 kW/m2。
1.2 设计变量及定义
利用二次曲线及基于类型和形状函数的CST方法,生成了如图1所示的类HX升力体飞行器气动外形[17]。
上下表面控制线采用二次曲线生成,以保证飞行器不同部位曲线斜率一致从而足够光滑,横截面形状主要通过CST函数生成[18],其中从头部至尾部由圆光滑地过渡至底部截面形状。选取如图2所示的12个变量作为设计变量,包括机身上半部分高度h1、头部半径Rh、机身第一部分长度L1、机身第一锥角θ1、机身第二锥角θ2、机身体襟翼宽度Lf、两侧小翼的翼根Xr、翼梢Xt、翼高Xs及安装角度θ4,底部截面型线的上下表面控制参数Nu1、Nu2。表1给出了设计变量的变化范围。

图2 设计变量示意图Fig.2 Schematic of design variables

表1 设计变量及搜索空间Table 1 Design variables and search region
1.3 气动性能分析方法及优化算法
在气动布局的概念选型设计中需要对大量外形开展气动特性评估,本文在多目标优化中高超声速气动力采用基于面元法的工程预测方法,气动热特性评估采用基于流线法的工程气动热方法。上述方法已同试验数据和数值模拟结果进行了大量对比验证[1,19-21],并在高超声速飞行器计算中得到了广泛应用[19],其精度基本满足方案论证和设计阶段的精度要求。对于本文外形,基于上述气动特性预测方法开展了和CFD数值模拟的对比,结果表明典型状态下二者升阻比偏差在5%以内,且针对不同构型的升阻比评估本文方法与数值计算具有一致性。而对于驻点热流的计算,本文方法和数值解结果相差12%左右,且在不同构型上热流规律与数值解具有一致性,因此本文方法能够保证优化方向的正确性和数据集的可信性。
优化算法方面采用自研MDO平台中基于遗传算法的多目标优化方法[22],算法充分考虑了Pareto排序,并利用小生境技术保证了种群的多样性。优化中种群数目为30,优化代数为40,本文的挖掘应用主要利用这些中间状态数据开展。该优化过程共产生了1 230个中间状态和135个非劣解集。图3给出了135个非劣解集4个目标函数的三维视图,从图中可以看出,对于分属不同学科的升阻比、方向稳定性、滚转稳定性及容积率4个目标函数之间的关系是难以直观理解的。为了更好地理解上述设计空间,本文将采用ANOVA、决策树、等度量映射及自组织映射4种算法对优化中产生的数据开展数据挖掘分析。

图3 非支配解集在三维目标函数空间投影Fig.3 Non-dominated solutions projected onto three-dimensional objective function space
2 数据挖掘方法
2.1 总变差分析
总变差分析是一种基于方差的后处理数据挖掘技术。基于方差的敏感性分析方法假定输入变量在取值空间内变化,通过输出变量的方差分析来识别输入变量对输出变量的贡献大小[9-12]。Sobol指标分析是一种应用广泛的基于方差的敏感性分析方法[23]。该方法的核心是通过Sobol分解,构建输出变量与输入变量之间的响应函数f(x),将函数f(x)分解为2n项的累积,即
f1,2,…,n(x1,x2,…,xn)
(1)
式中:x=[x1,x2,…,xn]为n维输入变量;f0为常数项;fi(xi)只包含第i个输入变量;fij(xi,xj)只包含第i个和第j个输入变量,以此类推。
当输入变量在取值空间内变化时,可以得到输出变量的方差,为
(2)
根据各项的正交性质,方差可以分解为以下2n-1项的贡献:
(3)
其中各子项分别定义为
(4)
由此可以定义各子项的Sobol指标,用以衡量其对总方差的贡献大小:
Si1,…,is=Di1,…,is/D
(5)
在实际应用中,更关心的是每个输入变量的总体敏感性指标,定义为
(6)
式中:Γi为包含第i个输入变量的所有子项的集合。
从上述分析中可以看到,Sobol指标分析的关键是得到函数f(x)的解析表达形式。这点在工程问题中很难得到。Toshimitsu和Andrea提出了使用蒙特卡洛方法估计输入变量Sobol指标的方法[24]:
STi=1-D~i/D
(7)
式中:D~i表示所有不包含第i个输入变量的子项引起的方差,可以通过蒙特卡洛方法估计:
(8)
其中:N为样本点数目;xm=[x1 m,x2 m,…,xnm]为第m个样本点的输入变量;x(~i)m=[x1 m,x2 m,…,x(i-1)m,x(i+1)m,…,xnm]表示第m个样本点去掉第i个输入变量之后的输入变量。该方法使用了两套样本数量都是N的样本点,分别用上标(1)和(2)区分;均值f0也是通过蒙特卡洛方法得到,即
(9)
为了得到n个输入变量的Sobol指标,该方法需要调用(n+1)N次计算程序得到样本点的关注输出量,计算量巨大。因此为了提高计算效率,本文使用代理模型来估计样本点的输出,取代耗时的直接计算。需要注意的是,代理模型的精度对敏感性分析十分关键。为了得到泛化误差满足要求的代理模型,本文使用交叉验证的方法进行了代理模型的选择和参数优化。备选模型包括多项式响应面(Response Surface Method, RSM)、支持向量机(Support Vector Machine, SVM)和Kriging模型等。
2.2 决策树算法
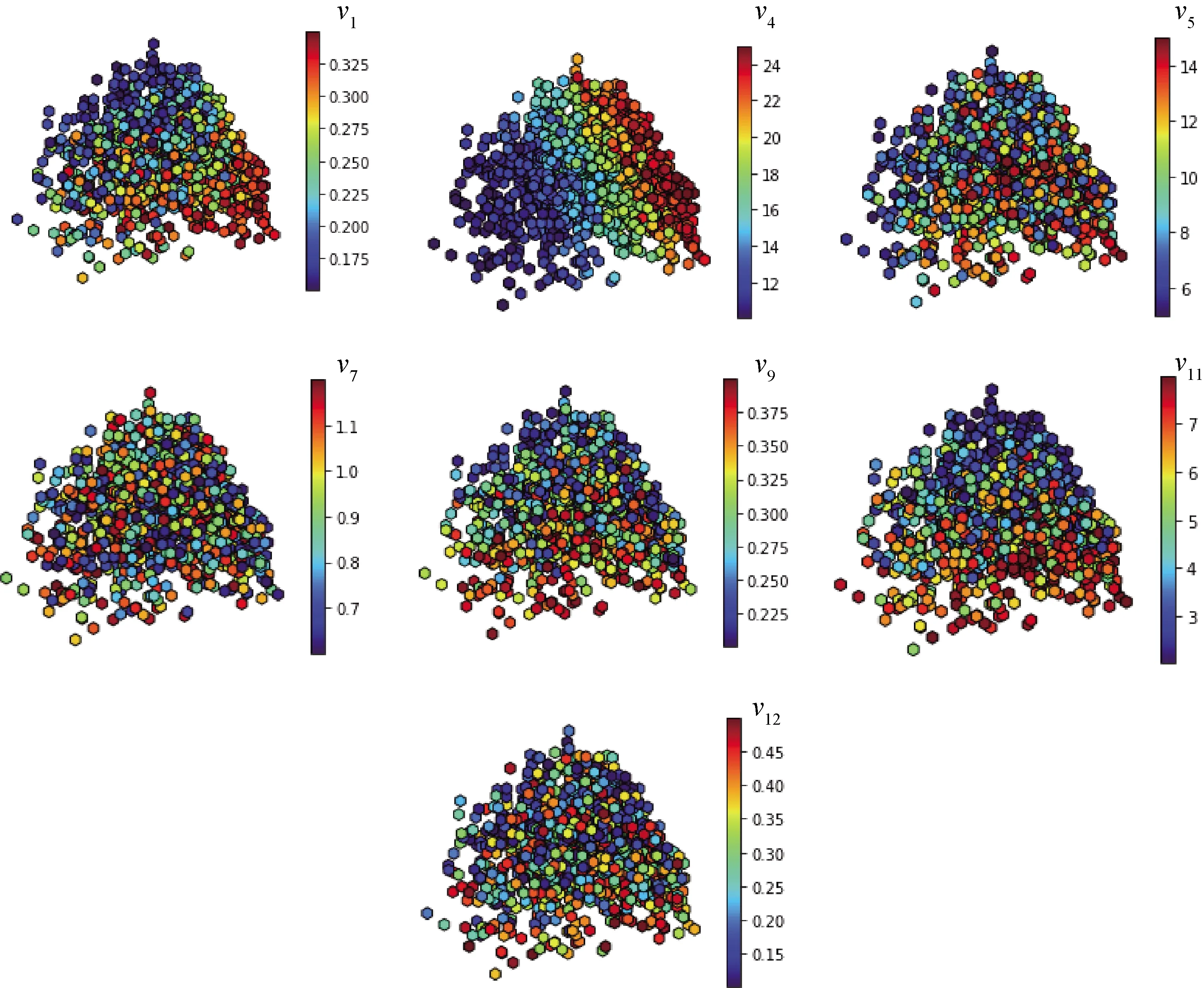
决策树算法是数据挖掘中一种非常重要的算法,通常用于对数据的分类、预测等,它具有直观且易于解释的优点,同时可以直观地得到分类和预测的规则,因而得到了非常广泛的应用[7,10,25]。如图4所示[9],一般而言,决策树通常包含根节点、若干内部节点和叶节点。根节点包含所有的数据,内部节点包含对属性的测试,叶节点则对应决策的结果。从根节点到叶节点的每一条路径都表明了一种判断序列,即对应于不同设计变量的取值规则及相应的目标函数决策。每一棵决策树都有若干的判断序列if(dv1>a1)and(dv2 图4 决策树示意图[9]Fig.4 Decision tree diagram[9] 其中最关键的步骤是选择最优的划分属性来构造决策树。最优属性的选择使得决策树的分支节点尽可能属于同一类别,即结点的纯度越高越好。经典的决策树算法ID3采用信息增益来进行特征选择,C4.5算法采用信息增益率来进行分割属性选择,CART算法通过基尼指数来进行分割属性的选择[25]。由于基尼指数不需要进行对数计算,本文选用scikit-Learn中基于基尼指数的CART算法来完成数据挖掘[26]。 等度量映射是流形学习的一种,流形学习的本质是发现高维观测数据集的内在低维流形结构和嵌入映射关系。流形学习的主要目的是找寻高维数据的低维本真结构,当数据被降低到二维或三维时,可以实现数据的可视化分析,如图5所示,三维空间的‘S’型分布数据通过流形学习可以得到二维的映射结构[25]。 ISOMAP是一种非线性的降维方法,它是MDS(Multidimensional Scaling,MDS)方法[24]的延伸,MDS降维方法主要用于线性降维,而ISOMAP方法选用图5(a)中黑色测地线距离来替代MDS的红色欧式距离从而实现对高维非线性结构的捕捉和描述。其具体的步骤包括[25]: 图5 三维空间数据结构与对应的二维流形结构Fig.5 2D embedding of 3D data structure 1) 确定高维空间中数据集D={x1,x2,…,xm}中每一个数据xi(i=1,2,…,m)的邻接关系,邻接关系定义采用k最近邻,k近邻之间的距离计算采用欧式距离计算,k近邻以外的数据点之间的距离设置为无穷大。 2) 利用Dijkstra算法计算邻接图上任意两点间的最短路径dist(i,j),得到近似测地线距离矩阵;对测地线矩阵运行MDS算法,获得d维内在空间上的低维坐标Z={z1,z2,…,zm}。 本文研究中所用的ISOMAP算法基于scikit-Learn开源代码包实现[27]。 SOM是人工神经网络中的一种无监督学习算法,它可以将高维的输入数据映射到低维空间中,与ISOMAP类似,它也是一种非线性降维技术[10-13]。如图6所示,典型的SOM模型包含输入层和输出层,输入层由n个神经单元组成,代表了需要处理的数据维度,输出层一般由m×m=M个神经单元组成,在输出层实现对数据的分类和整合。输入层到输出层的映射由连接输入向量和输出神经单元的权重矩阵Wi={wi1,wi2,…,wiN}(i=1,2,…,M)决定。在原始的高维空间中两个数据相似度越高,则他们对应的输出层神经单元相距也越近,可以较为容易地实现高维数据的可视化及信息提取。 图6 自组织映射的结构模型Fig.6 Self-organizing map structure model 在SOM算法中最重要的是找到与输入数据匹配的最佳神经单元c,最佳神经单元c定义为对于输入向量x∈Rn: (10) 其中输入和输出层之间的权重矩阵初始值为随机的小量,一旦找到最佳神经单元后,最佳神经单元的权重系数及其邻近单元的权重系数会被更新,更新的原则是其邻近单元与输入数据的欧式距离向着变小的方向发展,而最佳单元的权重系数与输入数据最相似。对于数据集中的每一个输入数据不断地重复上述过程,就可以得到最终的权重系数矩阵,以及每一个输入数据所对应的获胜单元[28-29]。 经过训练之后,神经元的位置和权向量都具备了一定的实际意义,每个神经元与映射到该神经元上的数据的值具有一定的关系,它代表了聚类数据取值的平均水平,同时不同神经元的位置也代表了不同的聚类类别,因此可以对高维数据的信息在低维空间上进行分析提取。本文采用github上的minisom开源代码包完成了数据挖掘分析[30]。 总变差分析方法及决策树构建过程中得到feature_importance参数均可给出每一设计变量对目标函数的定量影响结果。本文首先基于两种方法开展了数据挖掘以进行设计变量敏感性分析。在分析Sobol指标之前,使用交叉验证方法进行了代理模型的选择和参数优化。对于设计变量F1和F4,最终选定Kriging模型;对于设计变量F2和F3,选定RSM模型。每个模型的决定系数R2均大于0.98。此时认为对代理模型通过重采样进行敏感性分析是可靠的。同时在构建决策树的过程中对连续型的目标函数取值进行了离散化处理:对于1 230个数据点,将结果最优的10%的数据标记为‘high’,反之标记为‘low’。 图7和图8分别给出了总变差方法和决策树方法得到的每一个设计变量对目标函数变化的影响分析结果。从图7和图8中可以看出,对于F1目标而言,最重要的设计变量是v1,其次分别是v9、v7。即对升阻比而言,比较重要的设计变量为机身上半部分高度h1、两侧小翼的翼根Xr、翼高Xs。而对于F2偏航稳定性而言,最重要的设计变量是v4、v9、v5、v11,即机身第一锥角θ1、机身第二锥角θ2、两侧小翼翼高Xs及安装角度θ4,底部截面型线的上表面控制参数Nu1是较为重要的设计变量。同样对F3滚转稳定性而言,v11、v1和v12是非常重要的设计变量,即底部截面型线的上下表面控制参数Nu1、Nu2、机身上半部分高度h1大体决定了滚转稳定性的性能。而对于目标函数F4容积率而言,在总长及高度固定的情况,v4(机身第一锥角)和v5(机身第二锥角)决定了其容积率。 图7 总变差分析结果Fig.7 ANOVA results 图8 决策树得到的设计变量重要程度排序Fig.8 Feature importance ranking obtained by decision tree 综合两种方法来看,虽然总变差分析和决策树两种方法从不同的原理出发对设计变量对目标函数的影响程度进行了分析,但得到了较为一致的结论:即对4个设计目标而言,v1、v4、v5、v7、v9、v11、v12是相对重要的设计变量,在后续建模中如果希望进一步提高设计效率可重点关注这些设计变量。 图9给出了等度量映射方法得到的代表优化目标高维数据特征的二维流形结构,将该流形结构上的每一个数据点分别用目标函数的取值进行了染色分析,为保证较深的颜色表示较好的设计目标,将目标F3取负值处理。图10给出了采用自组织映射方法得到的神经网络单元用不同目标函数权重染色得到的结果,同样对F3进行了取负值的处理。 从图9和图10中可以看出该优化问题的目标函数之间存在比较复杂的关系:最明显的结论是F2(偏航稳定性)和F4(容积率)一致性较好,二者的较优解区域存在较大的重合,两种方法均捕捉到了完全一致的特征;其次对F2(偏航稳定性)和F3(滚转稳定性)而言两种方法给出的结果均表示二者之间存在较为强烈的冲突权衡关系,同理F2和F4之间也有较强的冲突权衡关系;对F1(升阻比)和F2(偏航稳定性)而言,从等度量映射结果来看二者除在左下角区域有较优解的重合,在大部分区域较优解的分布呈负相关,而从自组织映射结果来看,F1和F2除右上角部分较优值区域有重合外,大部分区域二者分布也呈负相关,虽然两种方法染色细节特征有差异,但均得到了相似的结论;同理可以得到F1(升阻比)与F3(滚转稳定性)的较优值除去左下角区域有部分重合外大部分区域存在权衡关系;此外目标函数F1与目标函数F4除在部分区域存在较优值的重叠外,在其他部分也存在冲突权衡关系。 因此对于该飞行器而言,不存在4种目标函数均取到最优值的解,必须进行妥协权衡。考虑到飞行器的设计必须保证偏航及滚转的静稳定性,同时要尽可能具备较大的容积率与升阻比,可以直观地得到图9黑圈所示区域以及图10中+号所示区域是综合4个设计目标时较优的决策数据点区域。具体分析两种方法可以看出二者在刻画目标函数大尺度关系上具有一致性。由于自组织映射在降维的同时对数据进行了聚类,因而所表达的目标关系更简洁,相应的缺点是对最优区域选择时得到的是一系列包含多个数据的神经单元集合,在最终决策中还需对单元中的数据集进行进一步分析,而等度量映射得到的最优解区域是单个数据点,可减少进一步决策过程中的额外工作量。 图9 ISOMAP目标函数染色结果Fig.9 ISOMAP colored by objective function values 图10 自组织映射网络目标函数染色结果Fig.10 SOM colored by objective function values 图11和图12分别给出了两种方法用设计变量值染色的结果,通过对比目标函数和设计变量的分布特征,可以得到每一个设计变量对目标函数的影响规律。限于篇幅这里仅给出对目标影响较大的设计变量的结果。 分别对比图9和图11及图10和图12的色块分布特征可以看出升阻比F1的取值分布与v1和v9的取值分布特征具有很强的负相关性,这与总变差分析及决策树结论一致。从数值来看,飞行器上半部分高度和两侧小翼翼高越大,飞行器升阻比越低。同时注意到等度量映射对于设计变量v7的特征分布识别不够明显,而自组织映射则能够给出较为简洁的F1和v7之间的关系,这说明自组织映射由于隐含的聚类特性在次显著变量复杂影响规律的捕捉方面更具优势。 图11 ISOMAP设计变量染色结果Fig.11 ISOMAP colored by design variables 图12 自组织映射网络的设计变量染色结果Fig.12 SOM colored by design variables 同时可以看出F2与设计变量v4之间呈较强的负相关关系。即机身第一锥角越大,飞行器展向越宽,飞行器越扁平,从而偏航稳定性越差;同时从自组织映射结果来看F2与v11正相关度也较高,即飞行器底部曲面中心线位置曲率变化越大(飞行器更不扁平)所获得的偏航稳定性越好,而等度量映射针对该变量得到的特征不够直观,这进一步说明自组织映射方法对次重要变量影响规律捕捉方面较为占优。 对于设计目标F3而言,两种方法均显示其色块特征与v11具有更好的一致性、与v1具有明显的负相关关系。同时在目标函数F3取较大值区域内,v12的取值也比较大。而对设计目标容积率F4而言,两种方法均显示其与机身第一锥角大小v4呈强烈的负相关,这与总变差分析和决策树结果高度一致。同时容积率与v5也呈现出较强的负相关性。因此对于该类飞行器而言,适当减小第一锥角和第二锥角的角度,减小飞行器的扁平化有利于提升容积率。 综合来看通过等度量映射和自组织映射两种方法不仅能直观地获取目标函数之间的权衡关系,相较于总变差分析和决策树还可以得到敏感变量变大变小对于目标函数值的好坏影响规律。同时自组织映射方法因为隐含了聚类分析特征,相较于等度量映射,除了可以实现对显著变量的影响规律捕捉外,还可对次显著变量的影响规律进行较为直观的展示。 决策树除了可用于分析设计变量的重要程度外还可以用于提取设计规则,对于设计而言,更关心什么样的取值空间可以得到较优的设计结果,进而可以优化设计空间取值,提升设计效率。文献[12]指出,采用所有设计空间的数据与采用非劣解集进行数据挖掘的结论具备一致性,因此本文采用非劣解集数据进行设计知识的提取以生成更简洁的决策树。图13以目标F1为例给出了决策树的生成结果,从图中可以提取出产生较高升阻比外形的比较重要的设计知识,如表2所示。 图13 针对目标F1升阻比的设计知识决策树Fig.13 Design knowledge decision tree for objective function F1 从表2看出,规则3是比较重要的设计规则,在设计变量v1<0.273,设计变量v7>0.99的情况下,如果设计变量v4>10.169,设计变量v5<13.903,极大概率可以得到较高的升阻比。同时考虑规则4,比较小的v9以及v3也是较优结果的保证。这两种规则代表了两种思路,前者通过减小机身上半部分高度来减少阻力,同时通过增加小翼翼根长度在实现增升,后者通过减小翼高高度减小阻力来实现升阻比的提升。这与等度量映射和自组织映射得到的结论一致。同理可以得到针对设计目标F2、F3、F4的较为重要的设计规则,如表3~表5所示。 表2 F1升阻比目标得到的设计规则 同样从表3~表5中可以得到,针对偏航稳定性、滚转稳定性和容积率的量化设计知识,上述设计知识除可以用来减小精细优化设计阶段的设计变量搜索空间以提升设计效率外,还可以用来指导未来相似飞行器的设计。 表3 F2偏航稳定性目标设计规则 表4 F3滚转稳定性目标设计规则Table 4 Design rules for objective function F3 of rolling stability 表5 F4容积率目标设计规则 本文以高升阻比滑翔飞行器布局设计优化问题为例,基于当前比较有代表性的总变差分析、决策树、等度量映射、自组织映射4类数据挖掘算法对气动布局设计中产生的中间数据进行了数据挖掘研究,得到如下结论: 1) 对于该滑翔飞行器,机身上下部分高度分配、机身第一锥角、第二锥角、两侧小翼高度以及机身上下部分截面形状对于升阻比、横/侧向稳定性及容积率而言是最重要的设计变量,在后续优化建模工作中可以进一步集中针对敏感量开展寻优设计。 2) 对于该滑翔飞行器,升阻比与容积率存在一定权衡关系,横向稳定性和侧向稳定性无法同时取到最优解,同时升阻比与横/侧向稳定性极大值区域也存在权衡关系。较优的解只能在较好的横侧向稳定性区域,牺牲最优升阻比和最大容积率的中间区域取得。 3) 4种方法得到了高度一致的结论,相互印证了方法的可靠性,因此均适用于对大量的优化数据开展挖掘分析研究。总变差分析方法可以揭示每一设计变量对目标函数的影响,定量提取出重要的敏感设计变量;等距离映射和自组织映射不仅可以揭示目标函数之间的折中平衡关系,同时也可以精准的抓取和揭示敏感度较高的单个设计变量变化对目标函数的主要影响特征;决策树不仅可以给出各设计变量对设计目标的重要程度,还可以给出产生较优布局的具体设计知识。 4) 在分析目标函数关系方面,自组织映射可以给出更为简洁的目标特征描述,而等度量映射则可以更直观地给出综合较优的决策解集;在分析设计变量对目标函数影响方面,二者均能对显著变量的影响规律进行捕捉,但对次显著变量的规律抓取方面,自组织映射方法表现更优。 综上,4种方法各有特点,在设计知识提取中各有侧重,能从不同的角度对布局优化过程中产生的数据进行挖掘分析,获取有利的设计知识。在实际应用中可以将4种方法综合使用,以实现气动布局隐含设计知识的挖掘与再利用。
2.3 等度量映射算法(ISOMAP)

2.4 自组织映射算法(SOM)

3 优化设计知识挖掘
3.1 优化目标的敏感设计变量分析


3.2 目标权衡关系及设计变量/目标性能影响规律



3.3 设计规则提取分析





4 结 论
