基于融合门网络的图像理解算法设计与应用
2021-07-03周自维王朝阳
周自维,王朝阳,徐 亮
(辽宁科技大学 电子信息工程学院,辽宁 鞍山114000)
1 引言
图像理解(Image Captioning)问题是计算机视觉领域研究中的核心和热点问题,其目的是通过一幅图像来生成描述该幅图像内容的一句话,即图像转换语言的问题。人在看到一幅图像后,可以很好地用语言描述出该图像中表达出的含义,但是让计算机达到类似的效果却面临诸多问题。因为图像理解需要考虑多方面的因素,包括如何利用图像的特征信息、如何将理解的知识转换成一段文字描述以及如何将这些过程转换成逻辑代码,对于传统的计算机算法而言,实现这项工作的难度巨大。
早期的图像理解方法例如文献[1]、文献[2]等是先通过图像处理和SVM分类结合的方式提取图像中存在的目标信息,然后再推断出前一阶段提取出的目标物信息和属性,并利用CRF或其他自定义的规则生成关于图像的一段描述。上述方式生成句子描述时过于依赖规则,因此文献[3]和文献[4]提出先用卷积神经网络作为编码端提取图像特征,再用循环神经网络作为解码端,结合图像特征生成图像描述。随着深度神经网络的应用,该问题的解决效果越来越好,因此目前普遍使用深度神经网络算法解决该问题。
文献[3]中采用的算法是典型的编码器-解码器[5]结构,该结构首先使用性能良好的CNN作为编码器获取图像的特征信息,然后使用循环神经网络作为解码器最终生成该图像的一段描述。但是在该论文的网络结构中,图像信息的利用不够充分,因为它只是在解码阶段的最初始时刻传递了图像的特征,随着解码步骤时间序列的不断增长,图像特征会逐渐丢失,最终导致生成的图像描述语句不够准确。受文献[6]中提及的注意力机制的启发,国内外学者提出了各种包含注意力机制的图像理解算法,其中包括软/硬注意力机制结合的图像理解方法、自适应注意力机制方法[7]等,虽然这些方法使图像描述的质量有了一定程度的提高,但是神经网络的方法也存在网络参数过多,算法过于复杂以及运行算法所需要的算力消耗过大等问题,这给研究成果的实际应用和推广带来了一定的经济困难。
基于上述问题,本文重新设计出一种新的网络模型,即“融合门”网络结构模型,该网络模型以编码器-解码器作为整体结构框架,并将注意力机制嵌入到模型之中。与以往注意力机制不同的是,该模型将注意力机制从区域图像特征转移到全局图像特征上来,实现花费更少算力而达到更好利用图像信息的效果。该“融合门”是图像的空间信息与时间信息的融合,为了使读者充分理解我们的网络结构,我们已经将该论文的代码开源,通过下载对应代码,可以更深入地理解我们的做法和思想,代码地址为:https://github.com/xuliang-a/fusion-attention.git
2 图像理解的相关研究
图像理解与图像的语义分析、图像标注[8-10,18]技术紧密相关,研究成果对于图像搜索[19-20]、信息降维[21]以及人机交互领域的应用起到根本性的支持作用。
目前解决图像理解问题普遍采用的算法是编码器-解码器结构的神经网络算法。其中编码器结构以卷积神经网络为基础,而解码器结构以长短时记忆网络(Long Short Term Memory,LSTM)为基础,而注意力机制可以充分利用图像的特征,该模型更加符合人的思维习惯,因此注意力机制越来越受到研究人员的重视。
文献[6]最早提出注意力机制并将其应用到图像分类之中。由于传统的机器翻译每次按照同样的比例提取源语言的特征信息,未能做到具体情况具体分析,文献[11]利用注意力机制的原理,将其引入到机器翻译之中,使翻译模型在对给定的一段序列进行翻译时,做到对不同词给予不同的关注,由此得到的目标语言也更加合理。文献[12]将注意力机制与LSTM相结合,将其应用到机器阅读中;文献[13]将注意力机制应用到图像的特征提取和语句的情感分析中;文献[14]将注意力机制应用到语言的理解中。随着对注意力机制的深入研究,研究人员也将注意力机制应用到图像理解中。文献[15]提出软注意力机制和硬注意力机制,在不同类型的区域,使用不同的注意力机制。文献[16-17]都提出了基于注意力机制对图像进行描述的算法,文献[7]提出自适应的注意力机制算法,该算法根据当前情况自行判断图像特征的重要程度,既可以很好地利用图像信息,又可以做到更好地模拟人的思想来生成图像的描述。随着研究的深入,文献[22-23]提出了新型循环神经网络结构,这种新的网络结构全面使用注意力机制,尝试取代LSTM网络以取得更好的描述效果,但是该网络结构在图像理解中尚未使用。
上述神经网络模型的演化都在向着一个方向发展,即网络模型设计得越来越复杂,网络参数越来越庞大,这使得运行神经网络所需要的算力(CPU+GPU)大大增加。因算力增加而造成的服务器和能耗的上升使得算法的部署成本也越来越高。
本文提出了精简、新颖的“融合门”网络结构,该结构是对图像空间信息与语句时序信息的融合,以编码器-解码器框架结构为基础,重新设计了一个“融合门”机制。该融合门结构将卷积神经网络的输出向量与标注语句的向量进行结合,再进入改进的LSTM网络,最后将输出结果形成一个统一矩阵,并作为网络的隐藏层输出,因此,该网络图像理解的输出既兼顾到图像整体的图像特征,又受到标注语句的影响,其输出的描述语句准确率更高。
本设计思想的实现也受到“注意力机制”[7]的启发,但是相比注意力机制的用法,本文采用的“融合门”网络结构更简单,网络参数更少,描述效果更理想。对实际的训练和测试结果进行评估,评估结果表明,在采用同样的卷积网络VGG⁃Net-16情况下,本文的融合门算法得到的评价指标CIDEr值比注意力机制[7]数值高出36.91%,通过程序计算,本文的网络参数个数为13,747,553,注意力机制网络参数个数为17,684,320,网络参数减少21.1%,本文模型的网络结构优势非常明显。
本文设计的新的“融合门”循环网络结构不但预测指标高,而且网络结构简单,占用计算资源少,对图像理解的推广起到积极作用。
3 基于融合门结构的图像理解模型设计与实现
“融合门”网络结构是时间信息与空间信息的融合,该网络结构基于编码器-解码器结构设计,在此基础上进行模型和算法的改进优化。模型的编码端采用卷积神经网络VGGNet-16,是为了获取图像的全局信息,模型的解码端采用改进LSTM模型,模型的详细描述如下所述。
3.1 基于融合门结构的网络模型
目前实现图像理解的网络模型几乎都使用“编码器-解码器”模型,其中最有代表性的是Li Fei-Fei设计的Neural Talk模型,如图1所示,其模型结构实现简洁,实际效果良好。
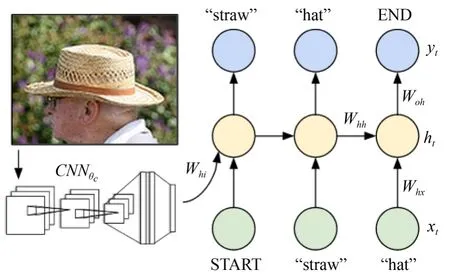
图1 Li Fei-Fei采用的网络结构[3]Fig.1 Neural Network of Li Fei-Fei[3]
自适应注意力机制模型[7]针对Li Fei-Fei的效果做了较大改进。
该网络利用卷积神经网络的中间层对后续输入输出做出调整,并且调整方式有较好的自适应能力,其网络结构如图2所示。上述结构的编码端与解码端实现方式如下。
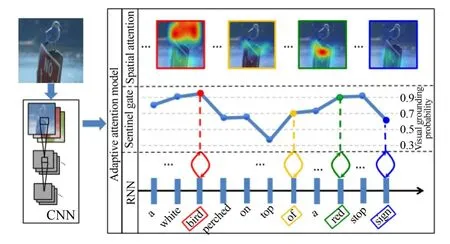
图2 注意力机制网络模型[7]Fig.2 Network of“Attention model”[7]
3.1.1 编码端算法
编码模型采用VGGNet-16对输入图像进行编码处理,由于解码端不需要使用图像的分类结果,所以去除掉VGGNet-16的分类层,从而使图像输入后获取到一个4096维的全局特征信息Ib,并利用文献[3]的方式对全局特征信息进行转换:
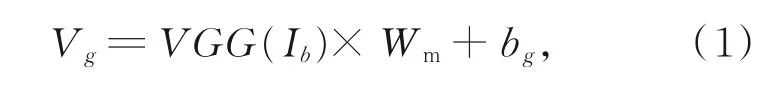
其中:VGG(Ib)用于将图像全局特征转换成词向量维度,若设定模型中词向量的维度为L,则W m的维度为4096×L,bg的维度为L,V g是编码端最终得到的全局图像输出向量。
3.1.2 解码端算法
解码端采用LSTM网络实现。文献[24]中的LSTM网络模型共有三个门,用于实现长期的语义信息及短期的语义信息的获取,使用该模型可以很好地避免梯度衰减或梯度爆炸现象的发生。
在t时刻下各个门的表达式如下:
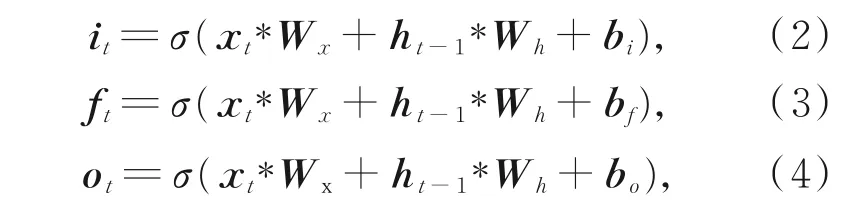
其中:σ代表激活函数,它是一种S型函数,阈值为(0,1),使用该函数更易于反向传播求导;∗代表矩阵相乘;it,f t和ot分别代表输入门、遗忘门和输出门;x t代表t时刻输入词的词向量;h t-1代表t-1时刻的获得的隐藏状态;W x和W h均是可学习的权重系数;其余均为可学习的偏置系数。该模型在t时刻的隐藏状态公式如下:
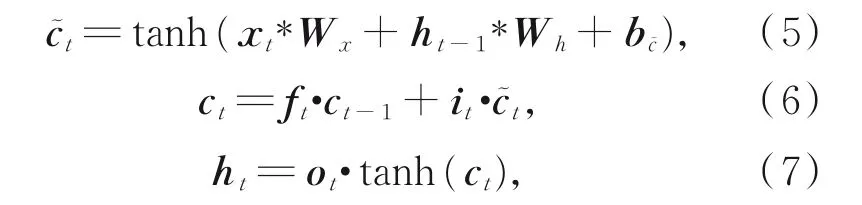
其中:·代表按元素相乘;c͂t表示候选的记忆细胞信息;ct表示记忆细胞信息;h t代表t时刻的获得的隐藏状态;bc͂代表可学习的偏置系数。
上述编码端和解码端的算法结构是本文设计新网络模型的基础。
3.1.3 “融合门”结构的网络模型框架
图像理解的核心问题是图像转语言,这种转换既包含了图像的空间信息,又包含了语言模型的时间信息,因此如果将空间信息与时间信息进行有效结合,图像理解的效果将得到有效改善,这是我们设计该算法的核心出发点。在实际的设计过程中,使用卷积神经网络处理空间信息-即图像信息,使用循环神经网络处理时间序列-即标定语句信息,进而将两者进行有机结合,达到更好的理解效果。
以此为基础设计该融合门网络结构,融合门网络结构的框架如图3所示。
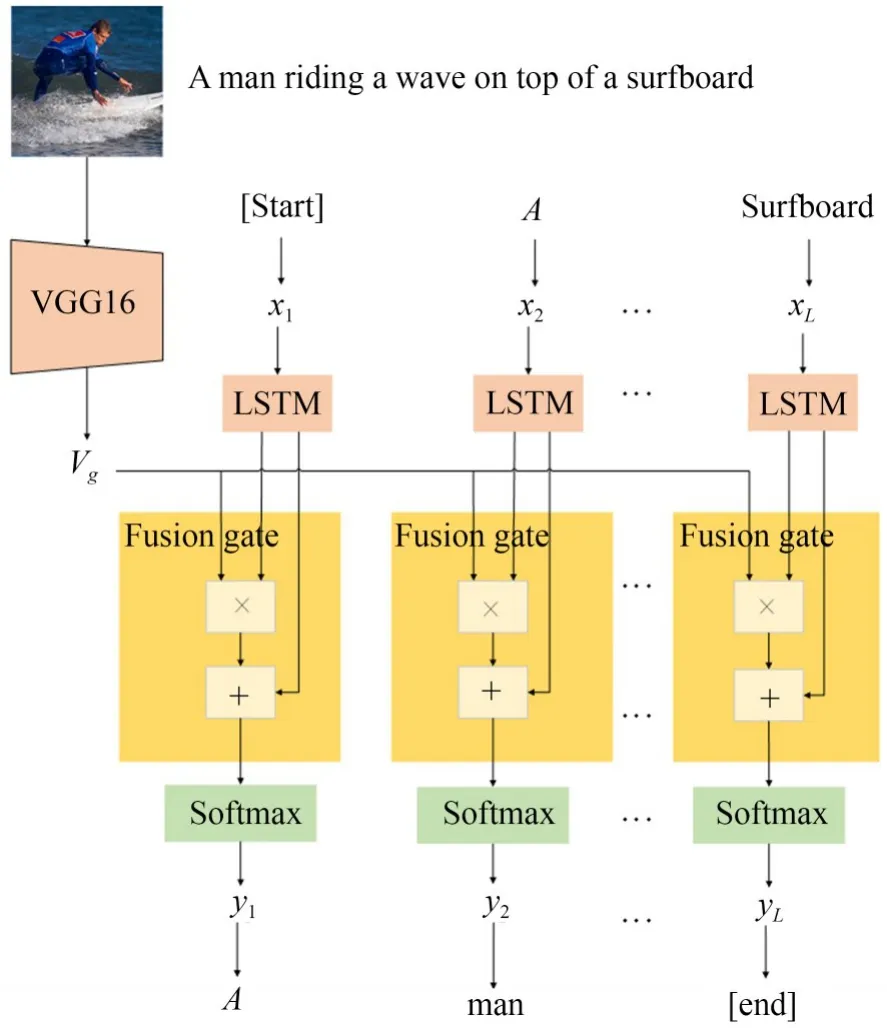
图3 “融合门”网络结构框架Fig.3 Architecture of“fusion gate”network
在网络结构的实现过程中,首先将输入图像通过VGGNet-16网络进行卷积,得到对应的4096维输出向量,然后将输出向量与标注语句结合作为LSTM网络的输入,经过LSTM的t0时间步产生隐藏层输出,将该输出再与卷积网络的全连接层一起,在后续的时间步重新进入LSTM网络,并进入下一次循环,即t1时间步,如此循环直至迭代结束,上述步骤的描述如图3所示。
3.2 网络结构内部设计
对于一段真实的句子,在预测不同物体的词语或者动词时使用图像信息可以使预测的结果更准确;而在预测“a”,“of”和“at”等介词则不需要使用图像信息,这类词的预测只需要利用上文的语义信息即可完成,这样就需要模型既可以充分利用图像特征信息,又可以对不同属性的词加以区分。为使模型可以更智能的使用图像特征信息,参考了文献[7]的思想,本文重新设计的“融合门”网络结构内部组成如图4所示。
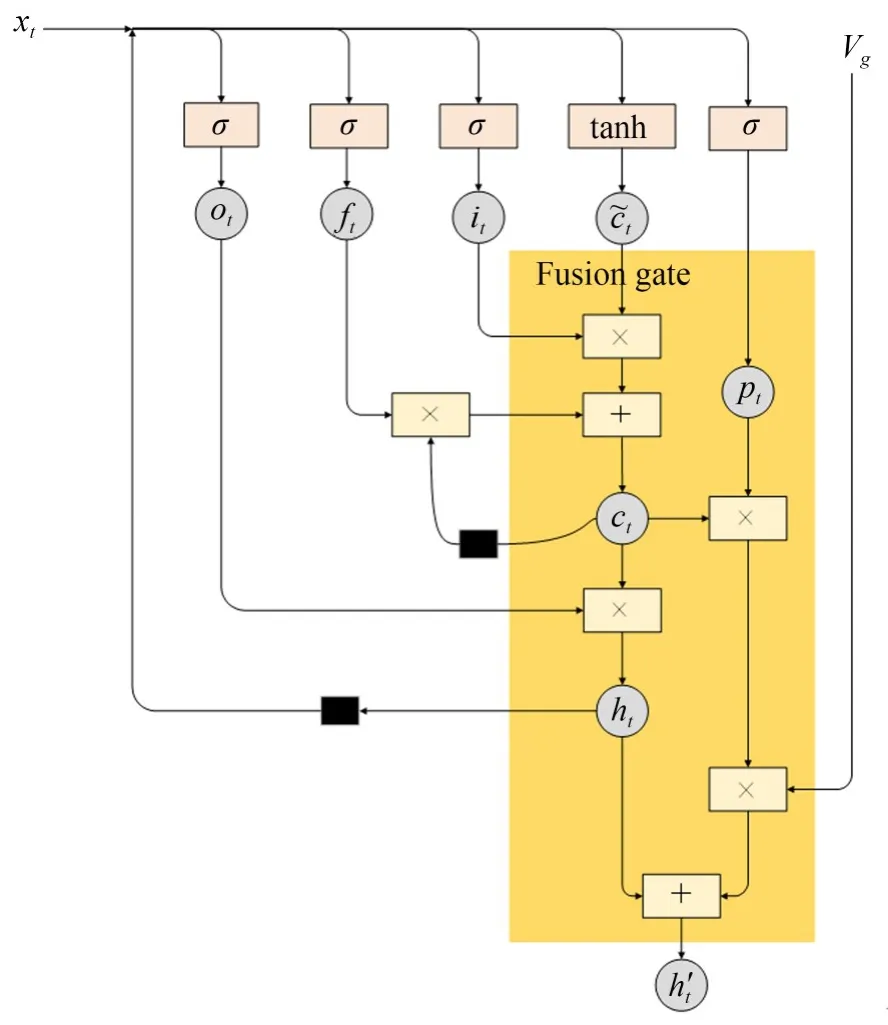
图4 “融合门“网络内部设计Fig.4 Internal parameters of“fusion gate”
图4中,黑方块表示单个时间步的延迟,利用这种方式得到的自适应的上下文向量,能够更好的组织推导关系,并且推断获取当前预测词后最需要的信息还有哪些。同时本文的模型仅使用图像的全局特征信息,这样可以大大减少网络的参数,使模型的复杂度降低,减少计算开销。
针对图像理解任务,该模型增加了用于控制如何使用全局图像信息的监听门p t。若p t的参数值为1,则表示需要根据当前的情况自行判断对图像全局特征信息的使用比例,p t的表达式如式(8)所示:
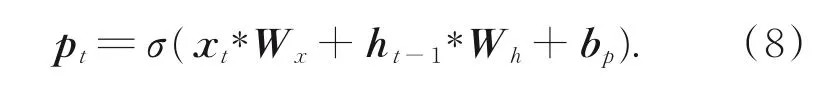
该模型利用文献[7]中的思想,使用当前时刻的隐藏状态信息,将其分别与全局的图像向量和受监听门控制的语义向量进行结合,为得到两者各自占的比例α̂t,使用softmax函数,将比例限定在[0,1]范围。α̂t的表达式如下:
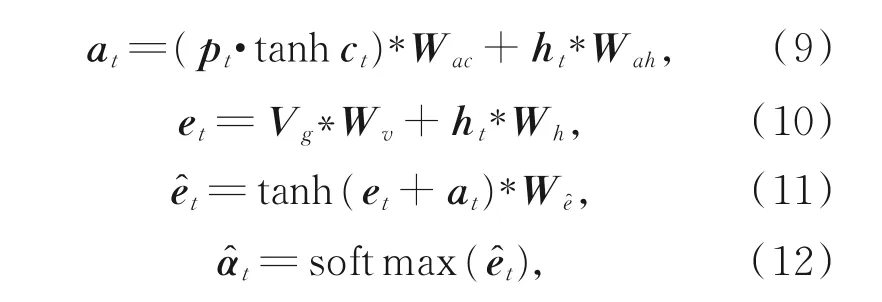
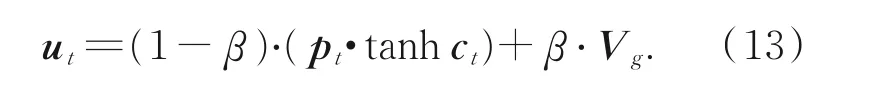
该模型在预测当前时刻的词的概率时最终使用的上下文向量h′t的计算公式如下:
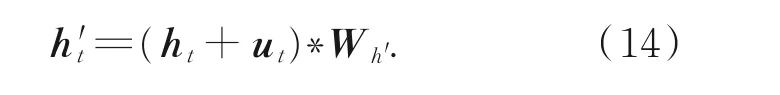
上述公式作为当前时刻t的隐藏层输出,作为下一时刻的隐藏层输入,利用上述算法特点,达到空间图像信息与句子的时间信息相互结合的特点,将二者信息融合,因此该结构以“融合门”命名。
4 实验与结果
MSCOCO 2014数据集[25]是目标检测和图像理解算法使用的通用数据集,该数据集包含80000多张训练数据集和40000多张验证/测试数据集。其中,数据集的每一幅图像大多是尺寸为256×256的彩色图像,并且每一幅图像都对应5句长短不一的英文图像描述。在对算法模型效果的验证与评估中,本文主要使用coco-caption代码[28]计算5种不同的评价指标,他们分别是BLEU 1-4指标[29],ROUGE指标[30],METEOR指标[31],SPICE指标[32]和CIDEr评价指标[33]。
4.1 样本数据的预处理
本文算法对输入的数据集有格式上的统一需求,因此在模型训练之前,需要根据情况对数据进行预处理,预处理主要分为三部分。
第一部分是对数据集顺序的预处理。采用随机分割的方式,将MSCOCO 2014的训练和验证数据集打乱,从中随机选取5000张图像用于验证,5000张图像用于测试,其余图像用于训练模型。
第二部分是对输入图像尺寸的预处理。由于选择了VGGNet-16[26]网络作为模型的编码端,所以需要将输入的图像尺寸调整为VGGNet-16网络所规定输入的尺寸,即224×224。
第三部分是对图像理解描述数据的预处理。首先获取所有图像理解数据中最长序列的长度,然后使用填充符将不足该长度的其余序列填充至最长序列的长度,最后保留在训练集中出现5次及以上的单词,并将训练集中出现5次以下的单词统一置为“未知词”,说明这些词使用太少,不具有参考价值。
4.2 模型训练与结果的评估方法
在实验中,采用了不同配置的服务器验证不同阶段的算法效果。在图像理解的验证/测试阶段,使用配置最低的NVIDIA Quadro P620 GPU服务器测试不同算法的预测效果,其目的是确定网络实际运行所需的最小计算机配置;而在数据集的训练和评估阶段,使用性能更好的NVIDIA Titan X GPU服务器。实验中我们尝试了多种网络的改进方法,尽管多数方案的评估效果不理想,但是在多次尝试中我们逐渐找到更好的方向,对图像理解的网络结构和算法有了更深入的理解。
网络训练中,针对该“融合门”网络模型,设置了10万次迭代,总训练时间约87个小时。设置每次迭代读取图像的批量大小为64,使用学习率为4e-4的Adam[26]优化算法来对模型进行训练,同时在模型中适当的添加丢弃层(Dropout Layer)来避免模型出现过拟合的现象。为避免卷积神经网络对模型的影响,在所有实验中未对其网络参数进行微调。在模型训练的过程中,每迭代200次时记录一次训练损失,每迭代10000次时使用3200张验证图像对模型进行一次验证与评估,获得平均结果,在迭代10万次后停止训练该模型,模型训练过程中的损失曲线如图5所示。
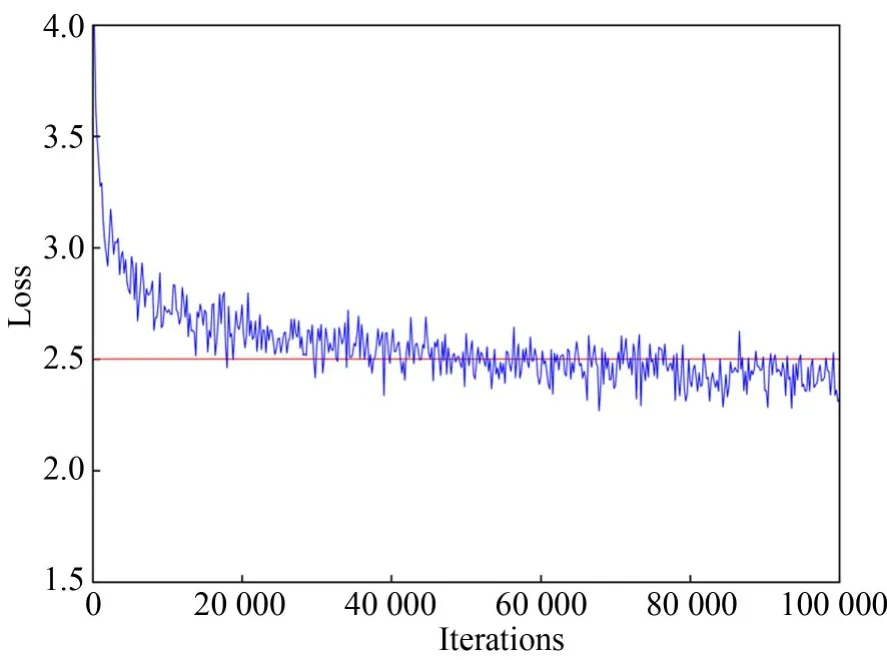
图5 模型训练损失曲线Fig.5 Loss curve of model training
在各个评估指标中,BLEU关注精确率,它是一种通过对比预测序列中的n元组在真实标签中出现的次数来分析文本相似性的一种评价指标;ROUGE关注召回率,它是一种通过对比真实标签中的n元组未出现在预测序列中的次数来分析文本相似性的一种评价指标;METEOR是综合考虑召回率和精确率的一种评价指标;SPICE使用Probabilistic Con⁃text-Free Grammar(PCFG)将预测的序列和真实的标签编码成一种语义依赖树,并通过一定的规则将其进行映射,利用这种方式来获取评价分数。
CIDEr采用TF-IDF和余弦相似度结合的方式来预测描述与参考句子的相似性,该指标最适宜于评价句子描述的好坏,因此对该指标的结果最关注。模型训练时各项评价指标的变化曲线如图6~图7所示。
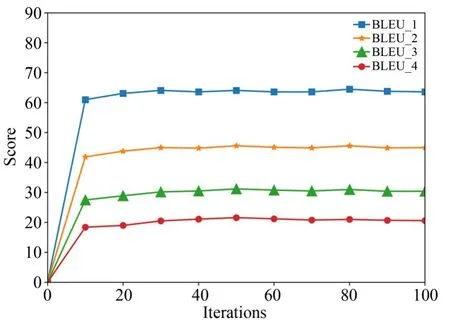
图6 融合门网络前四项评价指标变化曲线Fig.6 Curve of the first 4 indexes of“fusion gate”

图7 融合门网络后四项评价指标变化曲线Fig.7 Curve of the last 4 indexes of“fusion gate”
4.3 实验对比结果与分析
在网络训练过程中,使用了配置为NVIDIA Titan X GPU的服务器,对设计的“融合门”网络进行训练,训练耗时约87 h,网络迭代10万次。在训练结束后,通过观察和比较发现9万次迭代时生成的权重模型相较于10万次而言更好一些。从参考文献[3],[7]提供的程序和我们自己程序的运行结果上看,训练次数超过10万次以后,网络评价指标改善的幅度极其有限,10万次的训练次数已经足够体现不同算法的差异水平,因此以10万次训练作为本次实验结束条件。
本文选用的损失函数为交叉熵损失函数,优化算法使用的是Adam算法,该算法在图像理解中广泛使用[25],但是该优化算法不是全局最优算法,该算法经过迭代后只会获取区间最优解,本文采用该算法在10万次迭代范围内进行评估,根据损失和评价指标选出最理想的一组值,该组值在9万次附近得到,故而选用9万次迭代生成的权重来对实验结果进行评估报告。
在模型结果的测试和评估中,选择了目前比较典型的三个网络模型进行对比,分别是Google NIC网络[4],Neural Talk网络[3],和注意力机 制 模 型Attention model[7],选 用 上 述 网 络 的 原因还因为上述论文都提供了相应的运行代码,通过他们自带的代码运行更能保证评估结果的真实性,并且在编码器端都采用VGGNet-16卷积神经网络,在此条件下对比解码部分的效果,评价更加准确。
测试过程中使用3200张测试集中的图像作为输入,并设置每次迭代读取一幅图像,以此获得的评估结果,结果的指标如表1和表2所示。
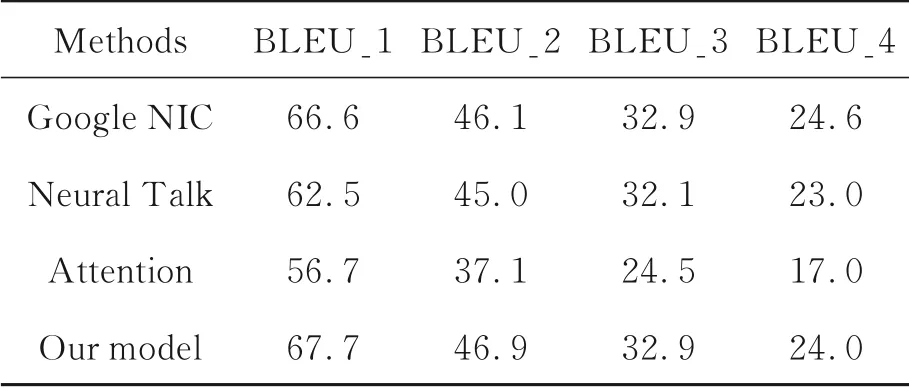
表1 实验的前四项数据Tab.1 The first 4 index results of experiment
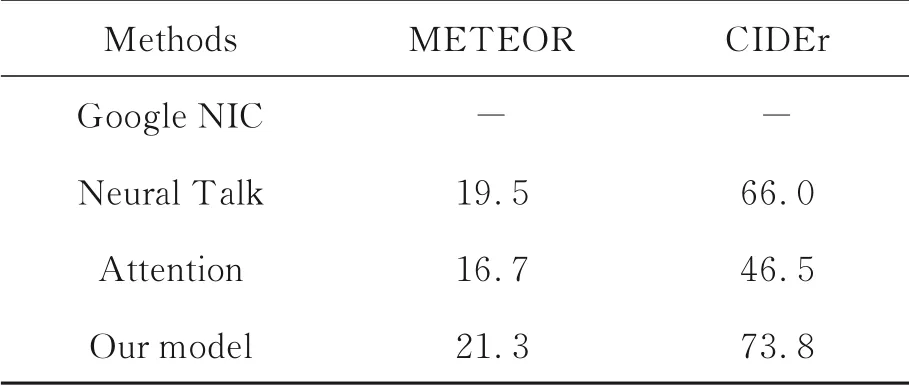
表2 实验的后两项数据Tab.2 The last 2 index results of experiment
从上述结果中可以看到,设计的模型CIDEr值为73.8,Neural Talk[3]的CIDEr值为66.0,提高幅度达到10.56%,即(73.8-66.0)/73.8×100%=10.56%,而Attention model模型CIDEr值为46.5,指标提高幅度为36.91%,即(73.8-46.50)/73.8×100%=36.91%,根 据 上 述结 果可以得出,本文设计的模型预测效果有明显提高。最后实验选取了4张COCO数据集中的图像和2张非COCO数据集中的图像进行预测。预测效果图分别为图8~图13,从获得的标注结果看,标注语句的描述和图像内容契合度较好。

图8 预测结果ⅠFig.8 prediction results I

图13 预测结果ⅥFig.13 prediction resultsⅥ
本文设计的网络模型,其网络参数个数为13,747,553,注意力机制网络模型参数个数为17,684,320,相对于注意力机制网络,我们的“融合门”网络的网络参数数量减少幅度为21.1%,即(17,684,320-13,747,553)/17,684,320×100%=22.1%。

图9 预测结果ⅡFig.9 prediction results II

图10 预测结果ⅢFig.10 prediction resultsⅢ

图11 预测结果ⅣFig.11 prediction resultsⅣ

图12 预测结果ⅤFig.12 prediction resultsⅤ
上述实验结果表明,所设计的“融合门”网络模型使用更简单的网络结构取得了更好的预测效果。
5 结论
为了获取得更好的图像理解效果并将图像理解的研究成果应用于实际需求,设计了基于“融合门”结构的深度神经网络算法模型。该模型以编码器-解码器结构为框架,编码部分以VGGNet-16网络为基础进行卷积,解码部分采用重新设计的循环神经网络模型进行推导,两者结合构成“融合门”网络结构。该“融合门”是图像空间信息和语句的时间信息的融合,设计思想符合图像、语言一体化的结构特点。
在配置NVIDIA Titan X GPU的服务器上,使用MSCOCO 2014数据集中的80000多张训练数据集和40000多张验证数据集上进行验证,运行约87 h完成10万次迭代训练,最终获得实验结果。
结果表明,设计的“融合门”网络结构不但预测指标高,而且网络结构简单,硬件实现需求低。在采用同样的前端卷积网络VGGNet-16情况下,网络比注意力机制[7]网络的CIDEr评价指标数值高出21.2%,网络参数减少22.1%,所有图像预测的推导时间都在0.5 s以内,实时性良好。实验结果证明,该模型使图像理解的预测质量得到了提升,并且有效降低了硬件需求,该结果对于图像理解研究成果在边缘计算领域应用和实际的推广起到重要作用。
