遮挡图像数据生成系统
2021-07-02梅若恒马惠敏
梅若恒,马惠敏
(北京科技大学计算机与通信工程学院,北京100083)
1 引 言
遮挡问题在计算机视觉领域一直是一个极具挑战的问题,当遮挡发生时,图像目标的特征会出现不同程度的缺失,造成目标检测算法精度的迅速下降。为了应对遮挡问题带来的挑战,国内外学者做了很多工作,如在跟踪领域,分块mean shift,HCF 等算法被提出以提升遮挡下的跟踪性能[1-2],在自动驾驶领域,关于行人检测、车辆检测和跟踪的一系列算法被提出以解决自动驾驶环境下的遮挡检测问题[3]。
虽然现在就遮挡问题在许多应用场景已经诞生了很多优秀的算法,但如何评估遮挡问题对算法的影响仍是当前亟需解决的任务。图像数据集在计算机视觉研究中具有非常重要的作用,ImageNet[4]涵盖20 000 多个类别,并为每张图像标注了颜色、纹理等属性。PASCAL VOC[5]拥有较高质量的图片数据,并针对不同的任务对物体的分割和检测提供了完备的标注。这些数据集为挖掘深度学习算法的潜能做出了巨大的贡献,但是它们缺乏对遮挡的标注来评估遮挡问题。KITTI 数据集[6]是一个自动驾驶场景下的大型数据集,包含城镇、乡村、高速公路等场景,并对行人、汽车等对象进行了0~3 级的遮挡标注。Caltech[7]是一个行人检测数据集,使用完整包围盒和可见包围盒对行人进行了标注,并将遮挡程度简单地划分为无遮挡、部分遮挡和严重遮挡。但是这些数据集对于遮挡问题仅仅提供了粗略的标注,仍缺乏合适的数据集来对遮挡问题进行系统地评价。
对于数据集的搭建,我们希望能够快速大量地生成标注准确的数据,而使用传统的方式构建大型数据集则需要在数据的采集和标注上花费大量的人力物力。近几年来,随着图形渲染质量的不断提升,已经有学者开始通过仿真的方式来构建数据集。Mayer 和Ilg 等人使用Blender 搭建了仿真数据集FlyingThings3D dataset[8],用于训练CNN 在视差和光流上的性能。Richter 和Vineet 等人通过访问图形接口解析游戏GTA-V的数据,使用捕获到的缓冲快速生成分割标注,搭建了GTA dataset[9],同时证明了仿真数据能够为算法带来准确率的提升,但是该方法仅实现了类级别的语义分割,且这种方式依赖于第三方的仿真平台,无法自由地在场景中改变或是添加新的物体,在数据生成上具有一定的局限性。
通过搭建仿真系统进行数据仿真,能够完全按照自己的想法生成数据,高效地生成大量数据样本及其对应标注,自由调整输出图像的分辨率以及布景、布光等影响识别率的因素。这种带有极高自由度的数据生成方式还能提供更多具有挑战的样本。Barbu 和Mayo 等人也提出目标摆放的角度和场所都会对目标识别算法的识别性能产生巨大的影响,并制作了数据集Object-Net[10],通过特殊视角和放置来挑战现有算法,指出现有目标识别算法仍然有很大的进步空间。
综上,在遮挡数据集的构建上,当前还存在以下问题:基于传统拍摄真实图像的方法在数据的采集和标注上仍然需要巨大的成本;基于解析图形接口的方法无法取得对场景物体的完全控制权,严重限制了数据获取的自由性;当前数据集的遮挡标注过于简单且没有高动态半透明物体如烟雾的标注,无法满足对于遮挡问题评估的需求。
为了解决以上问题,并就遮挡问题建立一个有效的算法评估机制,本文基于Unreal Engine 4提出遮挡图像数据生成系统,用于生成遮挡图像数据集MOCOD(More than Common Object Dataset)。系统以构建数据集为需求导向,选择场景并布景,控制智能体自动采集场景中的图像信号以及相关的辅助信息来生成数据集所需要的数据。MOCOD 数据集以遮挡为任务目标,设立了人、车、船、飞机四大类识别对象。在遮挡物的设计上,除了传统的实体遮挡,还实现了烟雾类型的半透明遮挡来扩充遮挡类型。此外,通过程序对遮挡物和遮挡对象做了精确的实例分割标注,并对场景物体的遮挡率和场景遮挡难度进行了评估和难度分级。通过使用遮挡图像生成系统,建立了包含8 200 张像素级语义分割图像的数据集,在布置完场景,且场景中包含两个目标和一个烟雾的前提下,标注并生成6 张1 280×720 的图像及标注文件在i7 8750H 2.2 GHz 和GTX 1060 的配置下仅使用1.455 s,极大地提高了数据采集的效率。
2 系统构建
遮挡图像数据生成系统旨在实现从虚拟场景中获取数据到数据生成、处理的自动化,使得能够快速地按照同一标准搭建和扩充数据集。本文提出的遮挡图像数据生成系统框架如图1 所示,其中紫色部分表示场景以及存在于场景中的物体,紫色部分底部的语义标注图像由更改后处理材质得到;绿色部分表示控制对象以及其子模块,用于采集处理信号并生成数据;棕色部分为控制对象的控制器,用于对象控制;黄色部分是python 端,用于处理仿真系统生成的数据;蓝色部分是其他说明(彩图见期刊电子版)。
整个系统主要由3 个模块构成:场景及全局管理模块(图中紫色和紫框上面无色部分)、控制模块(图中绿色和棕色部分)及数据处理模块(图中黄色部分)。
2.1 场景与全局管理
本文建立的MOCOD 数据集以人、车、船和飞机四大类为识别目标,在场景的搭建上,本文选择了城镇、工厂和海滨小镇作为场景,涵盖了城市和非城市道路、海洋以及天空。此外将识别目标和遮挡物按常理和不按常理的放置以构成接下来要进行数据采集的场景。
在场景的管理上,预先创建了一个颜色映射表来保证数据生成的自动化,并在场景初始化时遍历场景中的物体,查询识别目标和潜在的遮挡物,为它们分配模板ID 和对应的颜色,将不同类别的对象保存到不同的列表,存储在全局数据中供其他类调用。
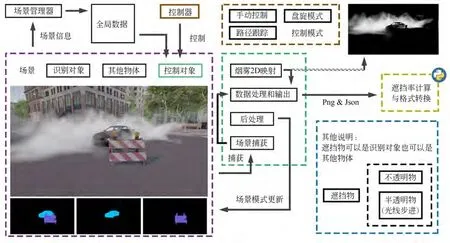
图1 遮挡图像数据生成系统框架图Fig .1 Frame diagram of occlusion image data generation system
2.2 控制模块设计
控制模块包括控制器和控制对象,其中控制对象是实际操控的智能体,通过控制器,使用手动或是预先设置的行为模式控制其行为。控制对象具有三个子模块,分别是:场景捕获模块,根据设定的相机参数在当前相机视角渲染帧图像并将图像二进制数据流保存到缓存;后处理模块,通过查询和使用延迟渲染缓冲区中的数据来处理屏幕像素,配合场景全局数据提取场景中更多的隐藏信息,用于生成场景深度图和图像标注等数据;烟雾2D 映射模块,生成当前相机视角下场景中半透明物体映射到相机光栅成像的透明度分布,用于计算半透明物体的遮挡率。
控制器用于实现对控制对象的控制,本文为控制器设计了手动和自动两种控制模式:使用自动模式能够令控制对象沿着指定路径批量采集数据实现采集效率最大化;采用手动控制的模式则可以用于更精确的数据采集。
2.3 遮挡率计算
在遮挡率的计算上,为了解决遮挡率分级和半透明烟雾遮挡的问题,分析系统生成的像素级标注,分别计算常规不透明物体贡献的遮挡率和烟雾半透明物体贡献的遮挡率并求和。对于烟雾透明度标注的生成,采用光线步进[11]的方法绘制烟雾体,通过计算光线在烟雾体内的积分来求解对应像素烟雾的透光比。对于遮挡率的评级,根据生成的精确遮挡率将难度按遮挡率划分为10 个等级,用于评估算法在不同遮挡难度下的性能。
3 数据生成
3.1 常规物体像素级标注生成方法
在KITTI 数据集下,可以看到当前的前沿算法如F-PointNet[12],SINet_VGG[13],UberATGMMF[14]等的性能仍会因为遮挡强度的增加而迅速下降[15]。然而KITTI 数据集采用的是包围盒的标注类型,且只有0~3 级的遮挡评级,无法为遮挡问题提供一个精确的评估。为了更好地评估遮挡问题,为场景物体生成了实例分割级的标注以提供更为精细的遮挡评级。
对于不透明物体的像素级标注,建立一个颜色映射表实现ID-颜色的映射,并将ID 作为模板值写入G-Buffer,作为图像后处理采用的目标填充标识,确保每个对象色彩的唯一性。如图2 所示,上图表示的是场景中的原始图像,下图是原始图像对应的标注图像,最下面一行是用于查询的颜色映射表的一部分,每一个颜色对应着唯一ID(彩图见期刊电子版)。在生成标注时,系统查找像素所属的对象,并根据ID 填充对应的颜色。但是事实上,在遮挡图像标注数据的生成过程中,更关心的是遮挡目标和遮挡物,为了在保留必要信息的前提下提高数据捕获效率,仅保留了遮挡目标和遮挡物的mask 信息,如图3 所示。

图2 全场景实例分割标注Fig.2 Full-scene instance segmentation mask

图3 仅留下遮挡物和被遮挡对象的标注Fig.3 Pixel level mask with target and occluder
然而仅仅拥有全局的标注仍然无法计算物体的遮挡率,物体遮挡率的计算还需要每个对象的完整标注。为此在全局数据中记录了遮挡物和被遮挡物的实例序列,通过控制实例在场景中是否被绘制来获取完整标注图像中每个对象的像素级标注,如图4 所示。

图4 单个实例的像素级标注Fig.4 Pixel level mask with single instance
对于生成的图像,添加了标注文件来记录一些必要的信息和指定图像实例的像素级标注路径,确保数据处理时能够跟踪到所有的相关数据。
L=(P,θ,I),i=(ID,T,C,Path,D),其中:L表示标签数据,P表示图像分辨率,θ表示相机俯仰角,I表示实例集,i表示实例集中的一个实例,ID为实例标识,T为实例类型,C为实例对应颜色,Path为实例单独标注的路径,D表示实例对象到相机的距离。
3.2 半透明烟雾及其标注生成方法
半透明类型的遮挡如燃烧产生的烟雾,水蒸气遇冷产生的水汽雾以及自然形成的大雾也是生活场景中常见的物体遮挡源。在仿真系统的渲染中,为了保证绘制的正确性,半透明物体的渲染在常规不透明片面绘制之后进行,难以通过常规的方式获取它的mask 信息。为了正确获取烟雾为像素点贡献的透明度,本文采用光线步进[11]的方式,依赖辐射传输方程[16],以Beer-Lambert[17]为衰减准则,沿着光线路径计算路径采样数据的积分,其中密度积分的结果作为烟雾的透明度输出,辐射亮度积分的结果作为烟雾的亮度输出。
现实中的烟雾动态是十分复杂的,为了获得实时的物理可信的烟雾,对烟雾模型作了简化,假设烟雾粒子在统计学上是独立的,且不发生非弹性碰撞,光线在体积中的散射均为均匀散射。
然而想要对三维空间中的体积进行采样,还需要一个三维的采样空间。为了创建出这个空间,如图5 所示,在时序上生成噪声作为烟雾在空间切片上的密度分布,并将序列作为空间上的第三维,从而获得一个伪3D 纹理来构建距离场,通过对伪3D 纹理插值采样就能够得到光线在采样点的密度值。
烟雾生成分为光线求交和光线步进采样两部分。如图6 所示,绿线表示当前相机射线采样积分的路径,橙线表示积分路径上采样点沿着光源方向的自阴影积分路径,灰色的点表示相机发出的光线在前进时没有采样到有效信息,蓝色的点表示介质内的有效采样点,红色的点表示自阴影积分路径上的采样点,光线在求出体积盒入点后按固定步长前进和采样(彩图见期刊电子版)。

图5 伪3D 纹理生成示意图Fig.5 Pseudo 3D texture generation schema
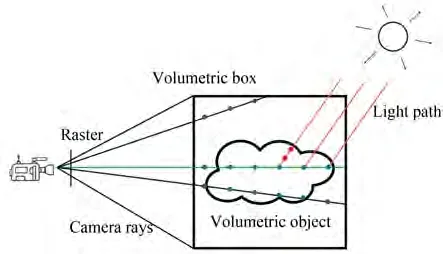
图6 光线步进示意图Fig.6 Ray marching schema
光线求交:
(1)沿着相机到光栅像素的方向发射射线;
几年前,父亲带着李离入蜀,去看青衣江上的佛像。川人集合了数千工匠,花掉了四十余年的时间,将一座山峰雕成慈眉善目的如来立像,秋风秋雨中,释迦牟尼的眉眼音容依稀已经出现,工人们搭着梯子,腰上缠着麻绳,举锤布凿,敲打他厚实的耳垂,慢慢将佛祖由山岭间唤醒。
(2)射线与体包围盒求交,计算光线在包围盒上的入射点p0和出射点p1;
(3)检测该射线对应像素的场景深度d,比较场景深度和出射点离相机的距离,若比场景深度大,更新出射点为场景深度对应的点,并计算入射点到出射点的距离;
(4)输出入射点和包围盒内光线传输的距离。
光线采样:
(1)计算光线步进采样点的采样值

(2)加入环境光照
由于光线在体积中被吸收和内散射而衰减,使得当烟雾极为浓厚时,背光且厚重的部分会出现浓重的黑色阴影,考虑到大气散射带来的能量,在采样点附近做了多次随机采样来模拟环境光照来获得柔和的自阴影,如图7 所示(上图为未加入环境光照的烟雾效果,下图为加入环境光照的烟雾效果)。
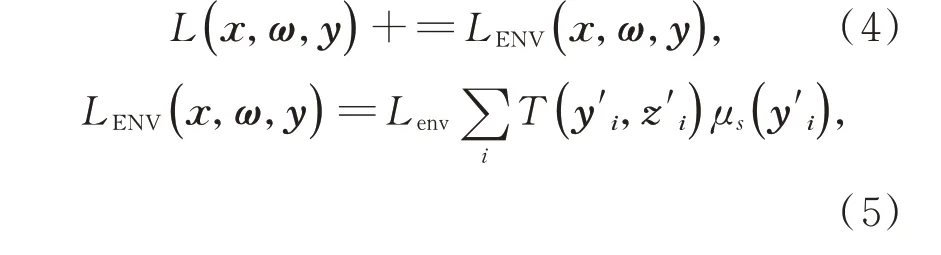
其中:LENV(x,ω,y)表示环境贡献的辐射亮度,Lenv是环境光强度,y′i表示采样点附近的随机点,z′i表示从该随机点出发沿着自阴影方向的出射点。
(3)路径积分
在获得了光线路径每一点的辐射亮度采样值后,沿着光线路径进行积分就能得到从光栅发射出去的光线最终采集到的辐射亮度:

通过光线步进的方式积分计算消光项,可以很容易得到光线对应像素的烟雾透光度。
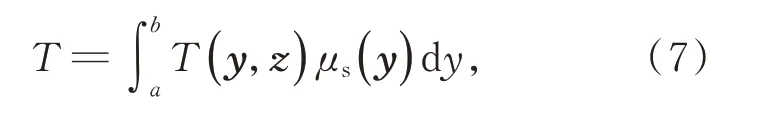
为了将计算得到的透明度的标注输出到本地,系统从场景中获取相机和烟雾的相关参数建立虚拟光栅模拟相机在场景中渲染烟雾的流程,从而将烟雾在三维空间中的成像映射到二维空间,最终得到烟雾在相机视角下透明度标注的输出结果。如图8 所示,上图为场景中的体积烟,下图为体积烟对应的不透明度mask 信息,纯黑表示无遮挡,纯白表示完全遮挡。

图8 烟雾透明度标注Fig.8 Smoke translucent mask
3.3 遮挡率计算方法
仿真系统生成的图像数据以及对应标注信息如图9 所示,包含人车船飞机四类数据。Occlusion 表示只有单物体遮挡时的遮挡率,Opaque、Translucent 和Total 分别表示多物体遮挡时的不透明遮挡率、半透明遮挡率和总遮挡率。其中辅助遮挡率计算的信息有完整标注图像、物体标注图像以及烟雾的标注图像。为了计算图像目标对应的遮挡率,本文提出了如下遮挡率计算规则:

其中:C(Label)表示计算对象在标注图像中所占的像素数量,C(Mask)表示计算对象在自身物质标注中所占的像素数量,∑L Alpha表示计算对象在自身标注图像中未被不透明物体遮挡部分的像素贡献的烟雾透明度,该规则的设立,实现了混合遮挡下的目标遮挡率计算。本文根据该规则划分出10 个遮挡难度等级,为遮挡率难度的评估提供了依据。

图9 MOCOD 数据集及标注Fig.9 MOCOD dataset with annotation
3.4 数据集分析
本文通过遮挡图像数据生成系统生成了包含人、车、船、飞机四大类对象共8 200 组图像,每一组图像包含(3+a)张图像,其中3 表示原始图像、视场内完整的mask 标注和烟雾的mask 标注,a 表示视场内被标记物体的数量,每个标记物体会生成一张自己的mask 标注,每张图像的分辨率均为1 280×720,数据集的标注比较如表1 所示。本文提出的数据集将标注精确到了实例分割级别,相较其他数据集划分了更多的遮挡等级,同时大大提升了标注的速度,能够更快地扩充数据集,提供更精确的遮挡评估。

表1 数据集标注情况比较Tab.1 Comparison of dataset annotation
对于MOCOD 引入的烟雾遮挡,目前主要面对生活中的大面积烟雾,如图10 所示,其中上图为现实中存在的烟雾,下图为仿真得到的烟雾。相比于其他数据集,烟雾类型遮挡和对应标注的引入进一步增强了数据集对于遮挡问题评估的完备性。

图10 现实和仿真烟雾对比Fig.10 Comparison between real and simulated smoke
4 结 论
本文创建了一个遮挡图像数据生成系统来高效构建遮挡图像数据库MOCOD。在遮挡图像库的构建中,引入了烟雾类型的半透明遮挡,扩充了场景中的遮挡类型。在系统中,提供了城镇、工厂和海滨小镇三个场景和数百个可以自由放置的物体,以及360°自由的拍摄角度,并提供了手动和自动追踪路径的控制模式来高效的捕获场景数据并得到实例分割结果,能够根据需求快速生成不同难易程度的样本。同时建立的图像库MOCOD 相较于当前其他公开的图像库拥有更详细的遮挡标注和评级,能够更好的评估检测和分割算法在遮挡下的图像识别性能。
本文的系统还具有很好的可扩展性。第一,在遮挡物的方面,现实生活中还存在着更丰富的遮挡类型,如被高温加热后的空气、含有杂质的液态流体等,都可以被引入从而进一步丰富我们的遮挡图像;第二,当前的半透明烟雾遮挡物仅使用随机噪声模拟,未来还可以在烟雾运动上加入物理约束得到更加合理的烟雾形态;第三,系统还能够继续扩展,根据需求生成光流、亮度分布等更多类型的数据。我们相信随着图形渲染技术的进步,利用仿真系统扩充样本将会越来越广泛的应用在计算机视觉领域,推动图像算法的进一步发展。
