联合训练生成对抗网络的半监督分类方法
2021-07-02曾庆捷
徐 哲,耿 杰,蒋 雯,张 卓,曾庆捷
(西北工业大学电子信息学院,西安710072)
1 引 言
图像分类作为计算机视觉领域最基础的任务之一,主要通过提取原始图像的特征并根据特征学习进行分类[1]。传统的特征提取方法主要是对图像的颜色、纹理、局部特征等图像表层特征进行处理实现的,例如尺度不变特征变换法[2],方向梯度法[3]以及局部二值法[4]等。但是这些特征都是人工设计的特征,很大程度上靠人类对识别目标的先验知识进行设计,具有一定的局限性。随着大数据时代的到来,基于深度学习的图像分类方法具有对大量复杂数据进行处理和表征的能力,能够有效学习目标的特征信息,从而提高图像分类的精度[5-8]。
深度学习以大数据驱动的方式进行训练,对标签数据依赖性较强,而在现实应用中往往难以获取大量的标签数据。当样本数量不足时,深度卷积网络模型容易过拟合,导致分类性能较差。生成对抗网络(Generative Adversarial Networks,GAN)[9]具有强大的数据生成能力,采用博弈对抗的方式,既训练正常的样本,也能对抗学习达到纳什均衡,从而完成网络的训练。这样GAN 在训练时既能够生成样本,又能够提高特征提取能力,可以用来解决小样本条件下网络过拟合的问题。但GAN 网络还存在稳定性差和依赖标签数据的问题,不能直接应用于分类任务中。
针对GAN 存在的问题,有不少学者从网络框架和理论模型两个角度对GAN 进行了改进。从网络框架角度,Radford 等[10]提出了深度卷积生成对抗网络(Deep Convolutional GAN,DCGAN),将卷积神经网络应用到生成对抗网络中,提高了GAN 训练的稳定性;Shaham 等[11]提出了单图像生成对抗网络(SinGAN),运用一个多尺度金字塔结构的全卷积网络,能够学习到不同尺度的图像块分布;Karnewar 等[12]提出了多尺度梯度生成对抗网络(Multi-Scale Gradients GAN,MSG-GAN),通过从判别器到生成器的梯度流向多个尺度来解决训练不稳定的问题。从理论模型角度,Arjovsky 等[13]提出Wasserstein 生成对抗网络(Wasserstein GAN,WGAN),使用Earth-Mover 距离代替JS(Jensen-Shannon)散度来计算生成样本分布与真实样本分布之间的距离,缓解了GAN 训练不稳定和梯度消失的问题;Goodfellow 等[14]提出了自注意力生成对抗网络(Self-Attention Generative Adversarial Networks,SAGAN),通过引入自注意力机制来增大深度卷积网络的感受野,从而更好地获取图像的全局信息。
为进一步提高图像分类的准确率,解决GAN 训练稳定性差的问题,本文提出一种联合训练生成对抗网络(Co-Training Generative Adversarial Networks,CT-GAN)的半监督分类方法,设计两个判别器进行联合训练,以消除单个判别器存在的分布误差问题,同时利用大量无标签数据和少量标签数据进行半监督学习,设计新的监督损失和无监督损失以优化网络模型,能够学习到泛化能力较强、性能更好的模型,在一定程度上减小网络对标签数据的依赖,提高网络的分类准确率。
2 生成对抗网络
2.1 生成对抗网络
生成对抗网络是由Goodfellow 等[9]在2014年提出的无监督生成模型,由一个生成器(Generator)和一个判别器(Discriminator)构成。生成器依据样本的数据分布来生成尽可能逼真的伪数据,判别器用于判别输入数据是真实数据还是生成器生成的伪数据,生成器和判别器经过博弈对抗达到纳什均衡,此时生成的数据能够拟合真实样本的数据分布。GAN 的网络结构如图1所示。
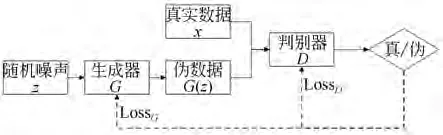
图1 GAN 的网络结构Fig.1 Structure of GAN
生成器G和判别器D通常可以由卷积神经网络或者函数表示,G输入随机噪声z用于生成伪数据G(z),D对输入的真实数据x和伪数据G(z)判别真伪,输出其属于真实样本的概率。生成器G和判别器D通过损失函数相互博弈对抗进行训练,其优化过程是极大极小博弈的过程,目标函数为:
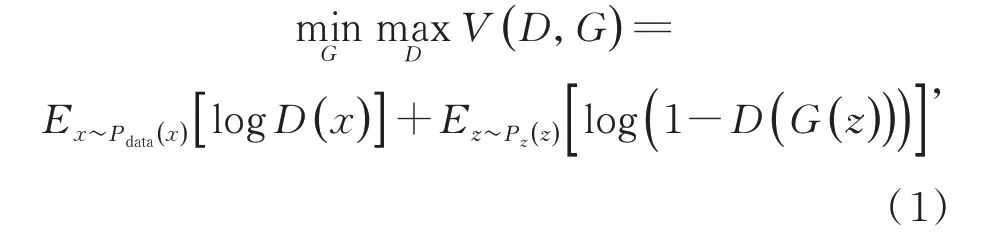
其中:x表示真实数据,Pdata为x的数据分布,z表示服从标准正态分布的随机噪声,Pz为z的数据分布,G(z)表示生成器生成的伪数据,D(·)表示判别器判别输入样本来自真实样本的概率。对于判别器D而言,其希望判别的准确率越高,即希望D(x) 越接近1,D(G(z)) 越接近0,此时V(D,G)取极大值。对于生成器G而言,生成的能力越强,生成的数据分布越接近真实的数据分布,即希望D(G(z))越接近1 越好,此时V(D,G)取极小值。
当V(D,G)取到极大极小值时,生成对抗网络达到纳什均衡,此时生成的数据能够拟合真实数据分布。
2.2 半监督生成对抗网络
半监督生成对抗网络(Semi-Supervised Learning with Generative Adversarial Networks,SGAN)[15]是由Odena 提出的半监督生成模型,其对原始GAN 网络进行改进,引入半监督学习,将标签数据和无标签数据共同输入到判别器中进行训练,并输出K+1 维带有类别信息的分类结果。SGAN 的网络结构如图2 所示。
在SGAN 中,随机噪声z通过生成器生成的伪数据G(z)与K类标签数据xl和无标签数据xu共同输入到判别器中进行训练,在判别器的最后一层使用softmax 非线性分类器,最终输出K+1维分类结果{l1,l2,…,lK+1},其中前K维输出代表对应类的置信度,第K+1 维代表判定为“伪”的置信度。
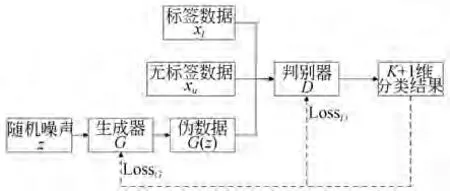
图2 SGAN 的网络结构Fig.2 Structure of SGAN
SGAN 采用了半监督训练方式,利用少量标签数据和大量无标签数据同时进行网络训练,从而提高半监督分类的准确率。但有研究表明,SGAN 仍存在训练不稳定的问题[16],主要表现在训练过程中可能出现梯度消失,导致网络不收敛的问题。这一问题的原因是SGAN 在训练过程中,单个判别器可能存在较大的分布误差,从而造成梯度消失,判别器网络不收敛。其中,分布误差是指判别器对样本类别预测时的概率分布误差。一般情况下,判别器预测样本类别的分布误差都可以通过训练迭代,逐渐消除其对网络训练的影响。但当出现较大的分布误差时,判别器网络会对样本产生较大的误判,造成梯度消失,使得判别器网络不收敛,影响其分类性能。
3 基于联合训练生成对抗网络的半监督分类
3.1 网络模型
为进一步提高图像分类的准确率,解决SGAN 训练不稳定的问题,本文提出一种联合训练生成对抗网络(Co-training GAN,CT-GAN)的半监督分类方法,CT-GAN 的网络结构如图3所示。
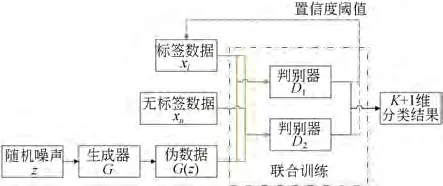
图3 CT-GAN 的网络结构Fig.3 Structure of CT-GAN
在CT-GAN 中,采用了两个判别器D1,D2进行联合训练,能够有效提升网络训练稳定性的同时提高图像分类的准确率。判别器D1,D2共享同一个生成器G,同时两个判别器的网络结构和初始参数设为相同。不同的是,将标签数据和无标签数据的顺序打乱后分别输入到判别器D1,D2中,即保证在训练过程中两个判别器是动态变化的。CT-GAN 采用两个判别器进行联合训练,在训练过程计算损失函数时,取两个判别器损失的平均值,以消除单个判别器存在的分布误差。同时在训练过程中,两个判别器不仅仅输出K+1维分类结果,还设置了一个置信度阈值,如果生成数据的置信度高于该阈值,则赋予其伪标签并加入到初始标签数据集中,在训练过程中就能够扩充数据集,加快网络收敛。
对于CT-GAN 的生成器G而言,G的能力越强,生成的图像越接近真实图像,即希望D(G(z))越接近1 越好,此时V(D,G)取极小值。由此可得到生成器的损失为:
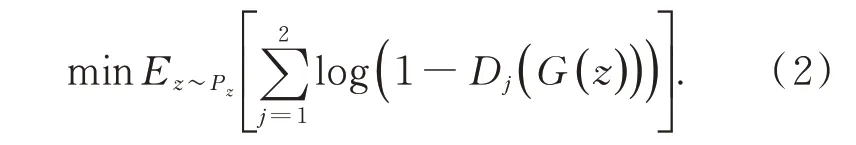
同时为了让生成器生成的数据分布更接近真实数据的统计分布,采用特征匹配[17]的方法对生成器的损失进行约束,定义特征匹配损失为:

其中:fj(·)表示判别器Dj在全连接层前的最后一层输出的特征值。这样,CT-GAN 生成器的总损失为:
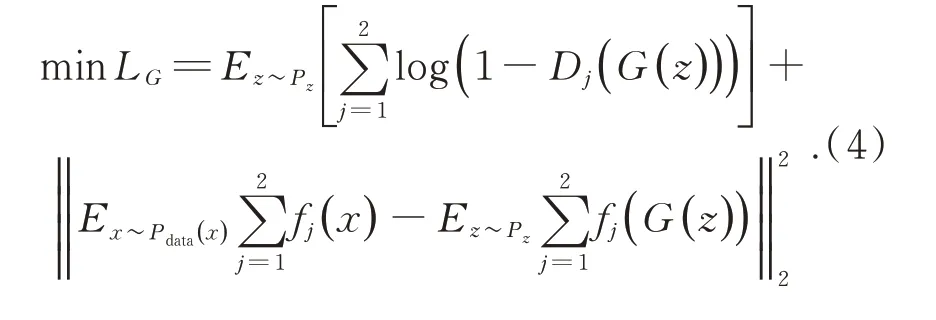
对于CT-GAN 的判别器损失函数,采取监督损失和无监督损失相结合的方式给出。对于判别器的监督损失,需要加入标签信息,因此以交叉熵的形式定义如下:
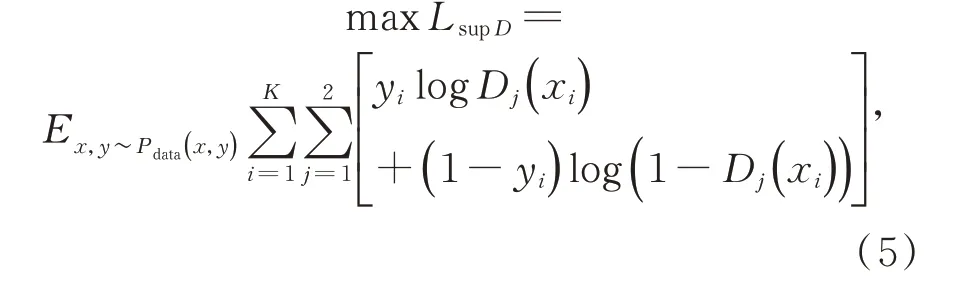
其中:yi表示第i维标签,Dj(xi)表示判别器Dj判别标签数据的标签结果为第i维的概率。
对于无监督损失,CT-GAN 需要判别无标签数据的类别标签。考虑到两个判别器联合训练的情况,CT-GAN 判别器的无监督损失定义如下:
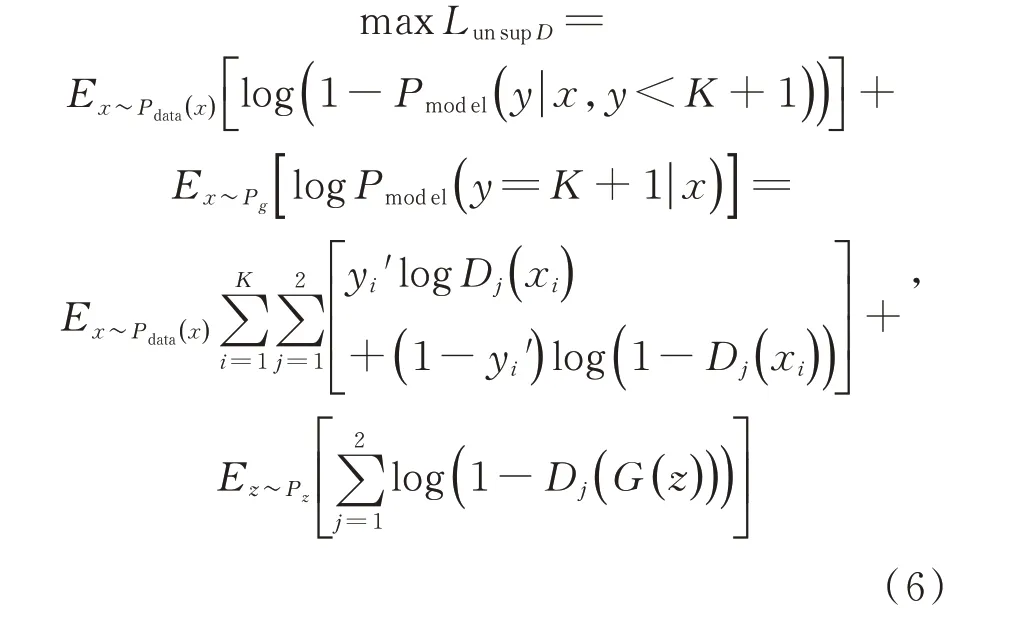
其中:yi′表示判别器前一次迭代时判别无标签数据的类别为第i维,Dj(xi)表示判别器Dj判别标签数据的标签结果为第i维的概率。
由式(5)和式(6)可得CT-GAN 判别器的总损失函数为:
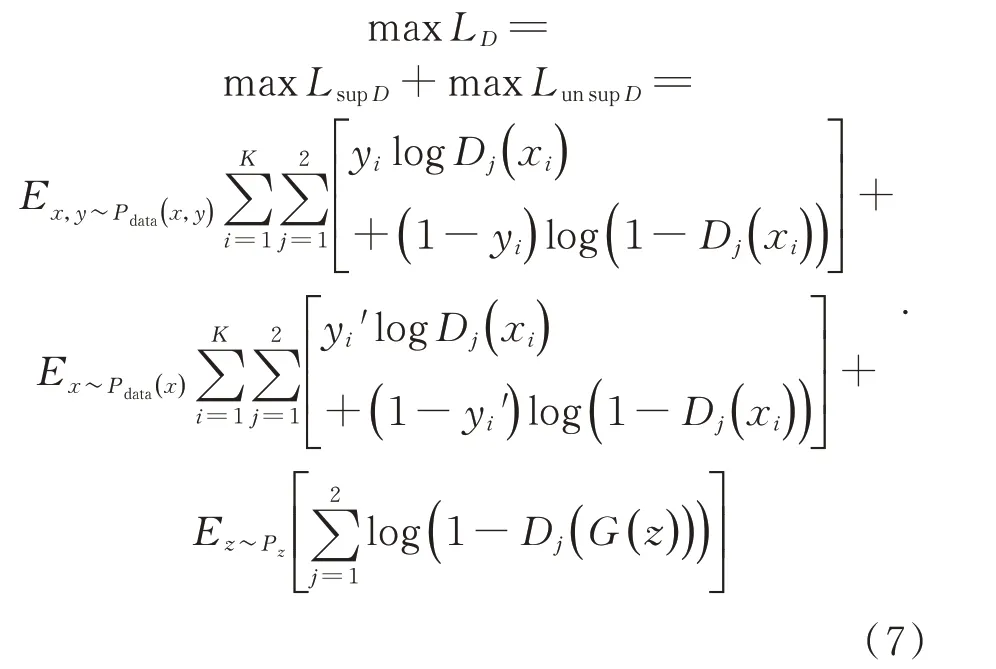
由CT-GAN 生成器总损失函数和判别器总损失函数相加,可以得到CT-GAN 整体的损失函数如下:
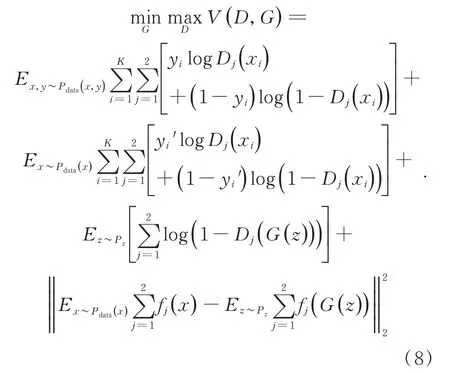
3.2 网络模型
CT-GAN 网络的联合训练示意如图4 所示。对于生成器生成的伪数据而言,判别器只需判断其真伪,不判别其类别,所以在此联合训练中暂不考虑伪数据的输入,只考虑标签数据和无标签数据的输入。
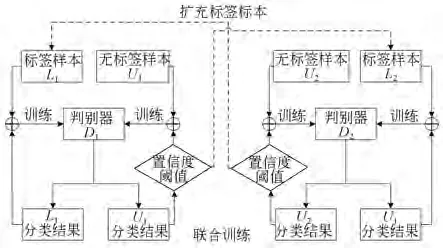
图4 网络联合训练示意图Fig.4 Schematic of co-training method
在CT-GAN 中,为保证判别器D1,D2训练时是动态变化的,首先将标签数据和无标签数据的顺序打乱得到标签样本L1,L2和无标签样本U1,U2,分别输入到判别器D1,D2中进行联合训练。以判别器D1为例,训练过程按照以下步骤进行训练:
(1)利用标签样本L1训练判别器D1。标签样本L1输入到判别器D1中,输出L1分类结果,计算判别器的监督损失以训练判别器D1;
(2)利用判别器D1来预测无标签样本U1的标签。判别器D1将前一次迭代得到的U1分类结果转化为独热向量并认为是当前无标签样本U1的标签,与当前得到的U1分类结果共同计算判别器的无监督损失,从而不断优化预测无标签样本U1的标签;
(3)利用无标签样本U1扩充标签样本L2。设置一个置信度阈值,对每次迭代得到的无标签样本U1的分类结果进行置信度判断,如果大于该置信度阈值,则赋予其伪标签并加入到对应的标签样本L2中继续训练,这样在训练过程中就可以扩充数据集,加快网络收敛。
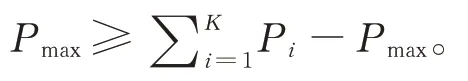
CT-GAN 模型通过判别器D1,D2的联合训练,一方面可以消除单个判别器存在的分布误差,提高判别器训练的稳定性;另一方面,利用无标签数据在训练时扩充标签数据集,能够加快网络收敛。因此,CT-GAN 模型能够充分利用少量标签数据的标签信息和大量无标签数据的分布信息来获取整个样本的特征分布,从而进一步提高网络识别的精度。
4 实验结果与分析
4.1 实验数据集及预处理
本文实验所使用的数据集为CIFAR-10 和SVHN 数据集,其中CIFAR10 数据集是一个包含10 个类别32×32 的彩色图像数据集,共计60 000 张图像,其中40 000 张作为训练集,20 000张作为测试集,即每个类别有4 000 张训练样本和2 000 张测试样本。SVHN 数据集是一个真实街景数字数据集,包含10 个类别32×32 的彩色图像,共计99 289 张图片,其中73 257 张作为训练集,26 032 张作为测试集。
数据集中的每张图像均包含一个类别信息,即均为标签数据。为满足本文实验要求,对训练集中图像进行预处理,按一定的比例随机去除部分标签数据的类别信息,得到无标签数据,CIFAR-10 数据集和SVHN 数据集的预处理方案如表1 所示。其中CIFAR-10 数据集在各类别标签数量分别为10,100,250,500,1 000 和2 000 时分别进行实验,SVHN 数据集在各类别标签数量分别为100 和1 000 时分别进行实验,以研究不同数量标签数据对网络的影响。

表1 CIFAR10数据集各类别标签数据的数量及所占比例Tab.1 Amount and proportion of labeled data in each category of the CIFAR10 data
4.2 实验环境
本实验采用一个RTX 2080Ti 的GPU 进行训练,共训练200 个epochs,且设置batch size 为128,即每个epoch 迭代313 次。设置初始学习率为0.000 2,并在迭代50 000 次和90 000 次时分别衰减为原来的1/10。采用Adam 优化算法对网络进行优化,其中一阶动量设为0.5,二阶动量设为0.999。模型采用基于PyTorch 的深度学习框架实现。
4.3 实验模型框架
在CIFAR-10 数据集上,CT-GAN 模型的生成器框架和判别器框架分别如图5(a)和(b)所示。生成器的输入为(128,100)的随机噪声,首先通过(100,8 192)的全连接层得到(128,8 192)的张量,经过维度转换得到维度为(128,128,8,8)的图像,经过两次上采样操作和三次步长为1的3×3 卷积核的卷积操作后得到维度为(128,3,32,32)的图像,其中每次完成卷积操作后都使用批归一化(Batch Normalization)操作并加入ReLU 激活函数。最后一层通过Tanh 激活函数输出生成数据G(z)。
判别器的输入为128 张大小为32×32 的3通道RGB 彩色图像,其维度为(128,3,32,32),经过四次步长为2 的3×3 卷积核的卷积操作,最终输出图像维度为(128,128,2,2),其中每次完成卷积操作后都加入LeakyReLU 激活函数和Dropout 操作以防止过拟合,而除了首次卷积不使用批归一化外,其余卷积操作后都使用批归一化。将卷积输出图像进行维度转换得到维度为(128,512)的张量,通过(512,10)的全连接层和softmax 分类器得到分类结果,同时通过(512,1)的全连接层和Sigmoid 分类器判别真伪。
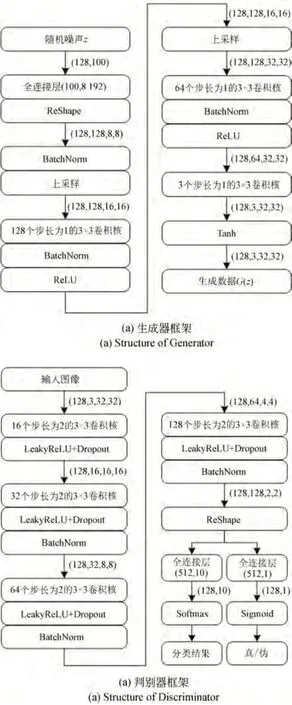
图5 CT-GAN 模型的生成器和判别器框架Fig.5 Structure of generator and discriminator in CTGAN
4.4 CIFAR-10 数据集上的实验结果及分析
在CIFAR-10 数据集上的实验首先按照4.1节中的数据集预处理方案,对数据集中的图像按一定的比例去除部分标签数据的标签信息,构成无标签数据。在各类别标签数量分别为10,100,250,500,1 000 和2 000 时分别进行实验,以研究不同数量的标签数据下CT-GAN 模型的性能。如图6 和图7 给出了在各类标签数据数量分别为10,100,250,500,1 000 和2 000 时的CT-GAN 判别器和生成器损失变化曲线。
分析图6 可知,在不同数量的标签数据下,CT-GAN 的判别器损失在一定迭代次数后都达到了稳定,标签数据越少,损失趋于稳定需要迭代的次数也越少。这是因为当标签数量越少时,整个数据所含的类别信息也就越少,判别器可以学习的信息也相应减少,导致损失收敛速度加快。虽然不同标签数量下损失收敛所需的迭代次数不同,但是其损失收敛值大致相同。这说明标签数量对CT-GAN 的判别器的训练影响很小,在一定程度上CT-GAN 模型能够减小对标签数据的依赖。分析图7 可知,在不同数量的标签数据下,CT-GAN 的生成器损失值逐渐减小并收敛到较低水平。
为了验证本文方法的有效性,利用CIFAR-10 数据集对比了不同数量标签数据下CT-GAN模型与相关的深度网络模型的分类效果,其分类准确率如表2 所示。实验在不同条件下分别进行了20 次重复实验,计算平均精度和方差。
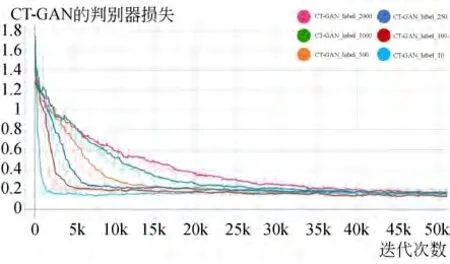
图6 CT-GAN 判别器损失变化曲线Fig.6 Discriminator loss of CT-GAN

图7 CT-GAN 生成器损失变化曲线Fig.7 Generator loss of CT-GAN
分析表2 的分类准确率可知,本文提出的CT-GAN 模型在CIFAR-10 数据集上的分类精度更高,在不同数量的标签数据下的分类精度都有不同程度的提升,在标签数据数量仅为10 时,就可以达到47.6%的分类精度,相比SGAN 模型提高了6.5%,这说明CT-GAN 模型能够有效提升在标签数据极少情况下的分类准确率,在一定程度上解决了GAN 网络在小样本条件下的过拟合问题。
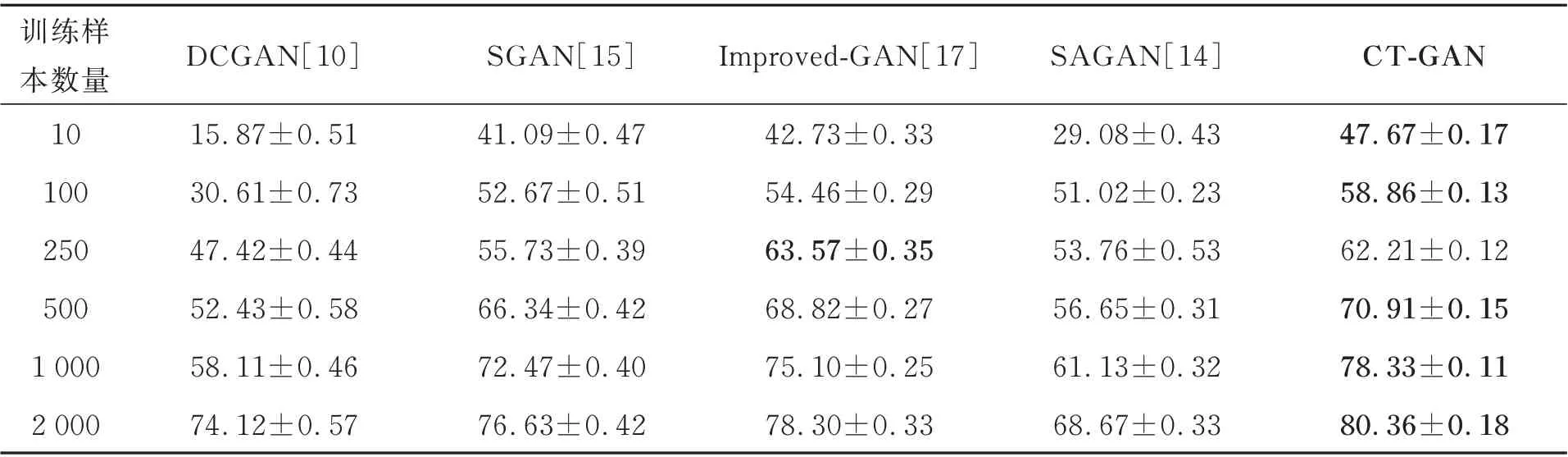
表2 CIFAR-10 数据集上不同数量标签样本的半监督分类精度Tab.2 Using different number of labeled data when semi-supervised training on CIFAR-10(%)
4.5 SVHN 数据集上的实验结果及分析
为更好地说明本文所提算法的有效性,在SVHN 数据集上进行实验。按照4.1 节中的数据集预处理方案,在各类别标签数量分别为100和1 000 时分别进行实验,以研究不同数量的标签数据下CT-GAN 模型的性能。表3 为SVHN数据集上不同数量标签样本的半监督分类精度。实验在不同条件下分别进行了20 次重复实验,计算平均精度和方差。
分析表3 可知,本文所提方法CT-GAN 模型在SVHN 数据集上的分类性能优异,在不同数量的标签数据下的分类精度都达到了较高水平,特别是当标签样本数量仅为100 时,即少量标签样本的情况下,达到了77.7%,相较于其他算法分别高38.33%,21.40%,6.34%和13.85%,进一步说明CT-GAN 模型能够在少量标签样本条件下有效提升网络的分类精度。同时,CT-GAN 在不同标签样本数量下的分类精度误差都在0.1%左右,相较于其他对比方法,本文所提模型训练更加稳定。

表3 SVHN 数据集上不同数量标签样本的半监督分类精度Tab.3 Classification accuracy of different number of labeled data on SVHN(%)
5 结 论
本文提出了一种基于联合训练生成对抗网络(CT-GAN)的半监督分类方法,通过两个判别器的联合训练来消除单个判别器存在的分布误差,同时利用无标签数据来扩充标签数据集,可以有效提升半监督分类的精度。实验结果表明,在少量标签样本条件下,CT-GAN 模型能够有效提升图像分类精度,在一定程度上降低了GAN 网络对标签数据的依赖。此外,在不同数量的标签数据下,CT-GAN 模型都取得了较好的分类效果,多种情况下的分类准确率相比其他方法都有一定程度提升,说明了本文模型的有效性。
