基于改进粒子群-禁忌搜索算法的FMS布局优化*
2021-07-02彭正超胡晓兵周韶武李彦儒
彭正超,胡晓兵,周韶武,殷 鸣,李彦儒
(1.四川大学机械工程学院,成都 610065;2.中国核动力研究设计院,成都 610213)
0 引言
柔性制造系统(Flexible Manufacturing System, FMS)是典型机电液组成的复杂大系统,其中设备的布局是FMS设计过程中最重要的设计决策环节,设备布局的优良直接决定了FMS机床利用率的高低和投资回收周期的长短。设备的布局通常考虑待加工零件(族)加工过程的物流成本。传统柔性制造系统的设计过程往往依赖于经验,存在设计周期长、无法保证方案最优等问题,因此这类复杂系统的快速、高效设计是数字化设计领域的技术难点与发展方向。
对于FMS布局优化设计的研究,Yang T等[1]研究了单回路定向物流模式FMS的开放场地式布局设计;Qudeiri J A等[2]利用遗传算法和神经网络实现了动态环境下FMS的布局优化设计;对于一般的生产线布局问题,以总物流量最小为优化目标,李建荣等[3]使用粒子群算法(PSO)求解单行布局;王明超等[4]和Hu B等[5]使用改进的遗传算法(GA)和粒子群算法求解多行布局问题。邓兵等[6]和黄淇等[7]将遗传算法与系统布置设计法(SLP)结合求解布局问题。文献[8-10]分别采用吸收了遗传算法中交叉操作算子的改进粒子群算法、模拟退火算法(SA)改进的粒子群算法、动态改变惯性因子和粒子飞行情况的粒子群算法求解布局问题。房殿军等[11]将设施规划与生产调度并行进行,对多行设施布局和混流生产线分别建模,利用路径系数对物料流向进行优化,物流距离与物流量数据相互传递与迭代。Benderbal H H等[12]求解机器布局时采用多目标模拟退火(AMOSA),将机器平均使用量的最大化也作为优化目标。以上研究对于多行生产线与FMS布局研究较少,且采用的启发式算法的性能有待改进。
针对待加工零件(族)的工艺特性已知,且加工设备型号与数量选定的FMS的多行布局优化问题,本文提出了一种改进的粒子群-禁忌搜索算法算法,引入自适应变异算子对粒子的位置进行随机变异,并将得到的优化结果进行禁忌搜索,提高算法的局部搜索能力和寻优质量。
1 FMS布局优化问题描述和数学建模
1.1 问题描述
FMS的设计过程中,确定各制造单元的位置布局,以保证在加工过程中物料的运输物流成本最低很关键。常见的FMS的设备布局有4种方式:单行直线布局、环形布局、阶梯形布局(多行直线布局)、开放场地布局[1]。为考虑布局问题的一般性,拟以多行直线布局为主要研究对象。作出如下假定:
①用长和宽已知的矩形来抽象化制造单元的具体形状;
②同一行的制造单元的中心位于同一条直线上,行与行间距固定;
③各制造单元的长边与水平方向平行,短边与竖直方向平行;
④各制造单元间保持固定间隔,位于布局场地四周的制造单元与场地外围的水平方向和竖直方向保持固定间隔。
FMS多行直线布局的拓扑模型如图1所示。以FMS设备间物流成本最小为优化目标,优化各制造单元的布局,是典型的NP hard问题。
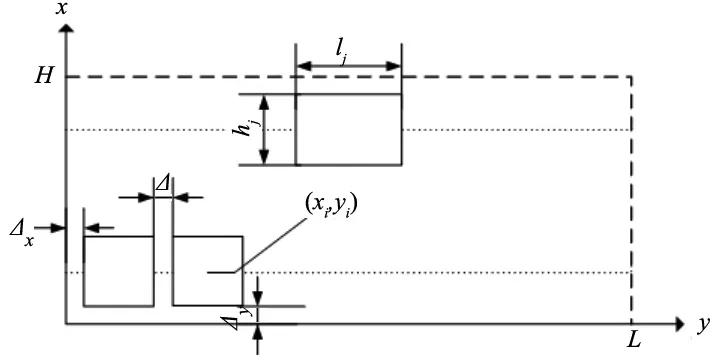
图1 FMS多行直线布局的拓扑模型
1.2 数学模型
定义布局场地的长和宽分别为L和H,m个待加工零件构成待加工零件集合p={p1,p2, …,pm},其中n个制造单元构成制造单元集合M={M1,M2, …,Mn}。制造单元长度和宽度集合分别为l={l1,l2, …,ln}和h={h1,h2, …,hn},制造单元i中心坐标为(xmi,ymi)。
设多行直线布局的行数为r,每个单元所在的行数为α(α=1, 2, …,r),每行允许排列最大单元数为K,第一行的竖直坐标为y1,行与行间的距离为d0,制造单元间的最小距离为Δ,制造单元在水平方向和竖直方向与布局场地外围的最小距离分别为Δx和Δy。排列在第α行第i个位置的制造单元对应的长度和宽度为lmi∈l、hmi∈h,其中心坐标计算公式为:
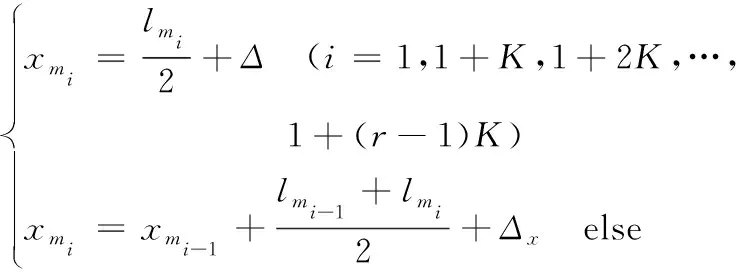
(1)
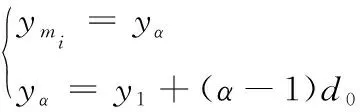
(2)
任意两个制造单元i与j间的物流距离可以表达为:
dij=|xmi-xmj|+|ymi-ymj|
(3)
单位距离制造单元i到j间总物流系数可以表达为:
(4)

为了最小化制造单元间物料搬运的总成本,布局问题的目标函数如下:
(5)
约束条件:
(1)制造单元位置不超过布局场地外围
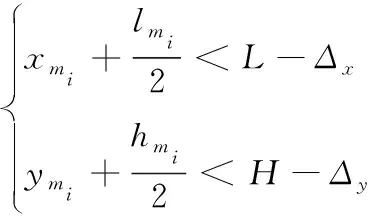
(6)
由于各制造单元在竖直方向的坐标yi在确定每行的位置时已经确定,可不再考虑,故约束条件式(6)可简化为:
(7)
(2)制造单元间不干涉

(8)
其中,zij用于表征制造单元i和j是否布局在同一行,当yi=yj时取1,否则取0。
2 改进粒子群-禁忌搜索算法
2.1 标准粒子群算法
由于粒子群算法具有较快的计算速度和较好的全局搜索能力,与进化算法相比避免了复杂的遗传操作,因此作为FMS布局优化的基本算法。
n维目标搜索空间中,N个粒子组成一个群,第i个粒子的位置记为Xi=(xi1,xi2, …,xin),速度记为Vi=(vi1,vi2, …,vin),迄今搜索到的个体极值记为pbest=(pi1,pi2, …,pin),整个粒子群迄今搜索到的全局极值记为gbest=(g1,g2, …,gN)。粒子通过迭代寻优,每一次迭代中跟踪个体极值pbest和全局极值gbest来更新空间位置和飞行速度:
vij(t+1)=wvij(t)+c1rand1( )[pij(t)-xij(t)]+
c2rand2( )[gj(t)-xij(t)]
(9)
xij(t+1)=xij(t)+vij(t+1)
(10)
(11)
式中,c1和c2为学习因子;rand1( )和rand2( )是[0,1]内的均匀随机数;w为惯性权重,在搜索过程中根据式(11)动态调整;t为当前迭代次数;T为最大迭代次数。
2.2 改进算法设计
由于粒子群算法具有早熟收敛、局部搜索能力弱容易陷入局部最优等缺点,对粒子群算法进行改进,提出一种新的基于自适应变异的改进粒子群-禁忌搜索算法(AMPSO-TS)。改进如下:一是借鉴其他启发式算法[13]引入变异操作,在粒子群算法进化过程中对得到的每个粒子的位置以一定概率进行变异操作,提高粒子种群的多样性;二是引入禁忌搜索算法,将粒子群算法得到的收敛的全局极值gbest使用禁忌搜索进行邻域解搜索,提高算法跳出局部最优解的能力。
改进算法流程图如图2所示,步骤如下:
步骤1:初始化算法参数,随机生成粒子的初始位置和速度;
步骤2:计算每个粒子的适应度值fit[i];
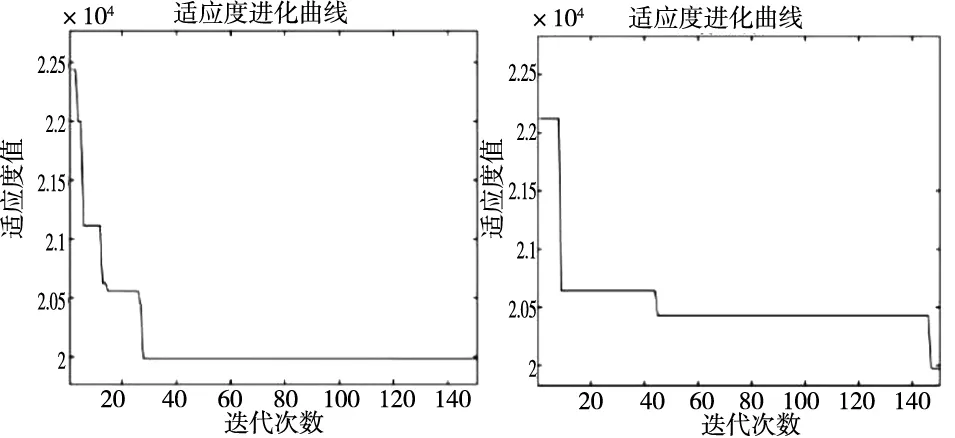
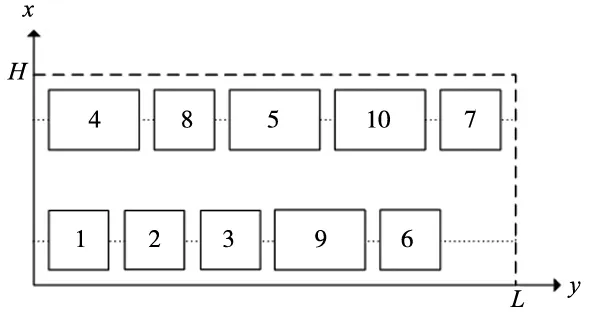
步骤3:对每个粒子,比较fit[i]和个体极值pbest(i)。如果fit[i] 步骤4:对每个粒子,判断是否符合变异条件,如果符合进入步骤5; 步骤5:对pbest(i)进行变异操作,如果变异后的粒子适应度值更优则保留变异,否则取消当前变异; 步骤6:将所有粒子的最优值中最优的个体存储在全局最优gbest中; 步骤7:更新每个粒子的位置和速度; 步骤8:进行边界条件处理; 步骤9:判断是否满足粒子群迭代终止条件:若是,则结束粒子群算法迭代进入下一步;否则返回步骤2; 步骤10:将得到的最佳微粒解码,进行禁忌搜索; 步骤11:禁忌搜索操作结束,输出结果。 图2 改进粒子群禁忌搜索算法(AMPSO-TS)流程图 针对FMS布局优化问题,在粒子群编码时将离散的布局问题进行连续化处理。制造单元数量为D,粒子的搜索空间为D维,粒子的位置Xi=(xi1,xi2, …,xiD)初始化时随机生成在某个范围内的实数。用随机生成的实数的排序后其原来的位置映射制造单元的序号。采用自动换行原则[8],当某一行制造单元排满后,自动换行排列到下一行。如某粒子的位置为(6.2295、5.9421、5.1011、8.5432、7.4442、9.5082、5.3451、5.5942、0.4734、7.3808),按数值从小到大排序后的元素在原编码中的位置 (9, 3, 7, 8, 2, 1, 10, 5, 4, 6)作为解码,每个数字对应加工单元的编号。当所需排列的单元数小于行数×每行最大制造单元数时,在解码后随机填充空位数个0表示该位置空缺,计算中心坐标和适应度值时跳过空位。 引入变异操作来提高粒子种群的多样性,避免算法早熟和陷入局部收敛[14]。为了提高算法效率,保证变异操作尽可能发生在收敛前,引入自适应变异因子来约束变异的发生。自适应变异因子为: (12) 式中,t为当前迭代次数,T为总迭代次数;λ为调节系数常量,用于调节δ的取值位于[0, 1]间,可取λ=1/e。变异发生在前若干次迭代且以一定的概率变异的条件可以归纳为: (13) 式中,δ0为允许变异因子常量,只有当变异因子δ<δ0时才允许变异;pm为变异概率。变异操作采用柯西变异(Cauchy mutation),柯西变异是基于柯西密度函数的,关于原点对称的一维柯西密度函数为: (14) 变异操作采用对粒子个体的位置进行变异,避免对个体极值变异使算法得到小于真实最小值的解,变异按如下式进行[15]: x'ij(i)=xij(i)+scCi (15) (16) 式中,Ci是柯西随机变量;sc为变异步长;rand(+,-)表示随机取正负号;ωc是[0,fcauchy(0)]中均匀产生的随机数。 禁忌搜索操作流程如图3所示。将粒子群迭代得到的最优解微粒的解码后的序列作为禁忌搜索的初始解。定义邻域映射为2-opt (2-Optimization) 形式,即初始解中两个单元排列位置进行对换。产生Ca个候选解,并保留前Ca/2个最好候选解。每一次迭代都会进行2-opt操作,某次搜索的其迭代过程中2-opt操作如图4所示。 图3 禁忌搜索流程图 图4 禁忌搜索2-opt操作产生候选解过程 (17) 将算法运行10次,得到10组最优的布局方案如表1所示,对应记录算法进行禁忌搜索前得到的最优解如表2所示。表中的1-1表示第一行第1个位置,以此类推。 表1 AMPSO-TS得到的最优布局方案 表2 禁忌搜索前得到的最优解 表1中除实验(1)外其余9次均收敛到了适应度最小值19 972。对比分析表1和表2中对应适应度值:实验(1)粒子群阶段(前120次迭代)收敛并进行禁忌搜索得到了更小的适应度值,但最终的收敛值大于适应度的最小值,其适应度进化曲线如图5a所示;实验(2)、(3)、(5)、(8)在进行禁忌搜索前(前120次迭代)算法已收敛到适应度最小值,其中实验(5)的适应度进化曲线如图5b所示。实验(4)、(6)、(7)、(9)、(10)在进行禁忌搜索前(前120次迭代)虽然已收敛但未收敛到适应度最小值,在进行禁忌搜索后得到了适应度最小值,其中实验(9)、(10)的适应度进化曲线如图5c、图5d所示。结果表明, 60%的情况下禁忌搜索对算法得到更优的适应度值起到积极作用。 进入禁忌搜索前(前120次迭代),图5a和图5c中,粒子群阶段很快收敛,图5b和图5d中适应度值随着迭代保持短暂稳定后突变,是由于变异操作带来的,避免了算法进入局部收敛,得到了更优的适应度值。 (a) 实验(1) (b) 实验(5) (c) 实验(9)(d) 实验(10)图5 适应度进化曲线 为了验证AMPSO-TS算法的性能提升,将本文算法与标准PSO进行对比,适应度进化曲线如图6所示。算法的收敛速度的差异较小,标准PSO得到的最优解适应度为20 114,AMPSO-TS得到的最优解适应度值为19 972,得到了更优的适应度值。 图6 AMPSO-TS与标准PSO对比 对表1中的最优布局进行修正,选取出现概率最大的设备为该位置的设备。当出现概率相同时,跳过该位置选定其它位置后再确定该位置;若出现两个位置两种设备出现的概率相同时则随机选取。修正后的布局方案序列为(1、2、3、9、6、4、8、5、10、7),记为最终布局方案,如图7所示。 图7 最终布局方案 (1)改进粒子群-禁忌搜索算法,引入了自适应变异操作和禁忌搜索策略,提高了粒子的多样性,避免了粒子“早熟”快速收敛陷入局部最优,同时增加邻域搜索策略来提高粒子群算法的局部搜索能力,使得算法精度和寻优质量有所提高。 (2)以某机床箱体类零件FMS为计算实例,使用改进粒子群-禁忌算法求解FMS布局优化问题,解决了在待加工零件(族)及其工艺路线已知且FMS中制造单元数量和种类选定后,对FMS布局优化的实际工程问题,快速准确得到可靠的多行优化布局方案,降低了FMS总物流成本。
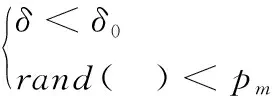


3 实例验证


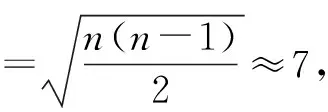




4 结论
