智能煤矿数据中台架构及关键技术研究
2021-07-02疏礼春
疏礼春
(应急管理部信息研究院, 北京 100029)
0 引言
目前,我国煤矿智能化发展处于初级阶段[1-3]。为促进煤矿智能化建设,国家发展改革委、国家能源局等八部委联合发布了《关于加快煤矿智能化发展的指导意见》,其中提出需实现煤矿智能化和大数据的深度融合与应用等。如何实现煤矿异构系统数据汇聚、分级分类存储、治理、建模和服务,是煤矿应用大数据的关键[4]。为此,需要建设煤矿大数据平台。文献[5-11]针对煤矿存在的信息化标准缺失、信息孤岛等问题,提出了基于云计算和大数据技术建设智能煤矿统一大数据平台的思路。但总的来说,我国煤矿大数据平台建设还处于起步阶段,对在互联网、智慧城市等领域应用较广泛的数据中台建设还未提及。
数据中台是智能煤矿建设的数据底座,是煤矿大数据应用的基础。本文提出智能煤矿数据中台架构,实现了数据汇聚、数据开发,以及各类感知数据、基础数据、管理数据的分级分类存储、数据资产管理、数据建模、模型训练和数据服务等,解决了信息孤岛、海量数据实时计算能力差、数据失真、查询速度慢、共享难等问题,将数据资源转变为数据资产,支撑业务应用的快速构建。
1 智能煤矿数据中台建设思路
智能煤矿数据中台建设涉及各类数据接入、管理规范的制定,汇聚数据资源量、硬件计算资源量、存储资源需求量估算,根据数据资源量和数据采集频率及实时性要求等进行大数据基础支撑组件的选型等,包括数据汇聚、数据开发、数据存储、数据资产管理和数据服务等步骤。
经数据汇聚采集的数据没有经过处理,基本是按照数据的原始状态堆砌在一起的,业务难以使用,需要通过数据开发存入数据资源池。数据开发主要面向开发和分析人员,提供离线或实时的算法开发工具,以及任务管理、监控等一系列集成工具。数据存储是数据中台的核心,要充分考虑数据的一致性和复用性,按照原始库、资源库、主题库等存储方式进行数据资源池建设,并形成数据资产和相关模型。数据服务使数据资产和相关模型服务于煤矿风险监测预警、设备健康诊断等,通过运维体系保障数据中台长期健康、持续运转。
2 智能煤矿数据中台架构
智能煤矿数据中台的主要功能是沉淀数据资产和构建分析模型,通过数据汇聚、数据治理、One ID、One Model、One Service来实现整体的数据加工、沉淀及服务,提供指标数据、标签数据、算法服务。智能煤矿数据中台主要包括数据标准规范、大数据基础支撑、数据汇聚、数据开发、数据资源池、数据资产管理、数据服务和运维保障等功能模块,通过统一的平台打通数据源层各系统之间的数据流,汇聚数据至统一的数据资源池进行存储、治理、分析,并通过数据服务为应用层提供数据,如图1所示。
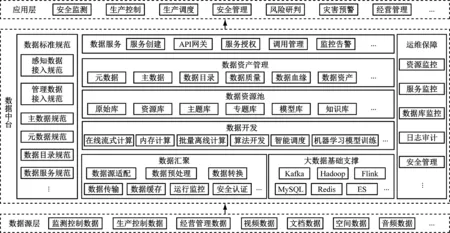
图1 智能煤矿数据中台技术架构Fig.1 Technical architecture of intelligent coal mine data middle platform
(1) 数据标准规范。包括数据接入规范和相关数据治理规范。数据接入规范是智能煤矿数据中台数据汇聚及质量管理的依据,包括煤矿安全监控、人员定位、工业视频监控、冲击地压监测、水害防治和矿用重大设备运维等感知数据接入规范,以及双重预防、地质测量等管理数据接入规范。数据治理规范包括主数据规范、元数据规范、数据目录规范、数据服务规范等,依据相关国家标准和行业标准制定。
(2) 大数据基础支撑。主要包括数据汇聚时所需的Kafka消息队列(用于缓存实时数据),Hadoop的Yarn,ZooKeeper资源调度管理组件,Flink实时流式计算处理组件,以及数据资源池建设中所需的MySQL,Redis,ES等数据存储组件。
(3) 数据汇聚。主要实现结构化、半结构化、非结构化数据采集,包括数据源适配、数据预处理、数据转换、数据传输、数据缓存、运行监控、安全认证等功能。
数据源适配支持Kafka消息队列、FTP文件、API(Application Programming Interface,应用程序接口)和前置交换库等。Kafka消息队列适用于时效性要求高的流式数据采集,如安全监控、人员定位、矿压和冲击地压、水文地质等数据。FTP文件适用于数据量大、时效性要求不高的数据采集。API和前置交换库适用于交换频率较低的管理数据采集。
数据预处理依据数据接入规范,通过开关方式开启数据项内容的格式检查。
数据转换是针对不同系统的数据源,按照数据接入规范转换为标准统一格式。标准转换程序内置在数据汇聚模块中。
数据传输方式因数据不同而不同。针对流式数据,将其写入Kafka消息队列中;针对离线数据,以文件形式或交换库方式进行数据传输。
数据采集过程具备数据缓存功能,满足数据断点续传需要。采集数据被保存到文件和数据库,作为缓存数据。若数据传输过程中出现故障,自动记录故障发生时间,缓存故障期间的数据,待故障恢复后自动从缓存中查询故障期间数据并重新传输。数据缓存功能可自定义缓存数据的保存时间。
运行监控是指对数据采集处理过程进行实时监控,发现异常信息及时告警提示。监控内容包括前置采集设备的CPU、内存、磁盘使用率,数据源适配接口、数据转换、数据传输状态。
安全认证在数据源适配时进行,数据可加密传输。
(4) 数据开发。根据汇聚数据的资源类型和数据采集频率不同,实时数据采用Flink进行在线流式计算,数据仓库各分层之间的离线数据采用Spark进行计算;针对热、温、冷数据,分别采用内存数据库、分析型数据库和时序数据库进行存储。
(5) 数据资源池。采集的原始数据经计算后先存入原始库,与源端保持一致,用于数据来源追溯和质量分析。原始库中数据经抽取、清洗和转换后存入资源库,供应用层调用。根据数据统计分析需要,从资源库抽取数据后存入主题库。从资源库、主题库等抽取数据,构建面向瓦斯、冲击地压、水害等煤矿高危灾害分析的专题库。模型库主要存储瓦斯、冲击地压、水害等煤矿高危灾害风险研判模型。知识库主要存储相关规范、规程和法律法规、预案等,为风险监测预警提供依据。
(6) 数据资产管理。通过梳理元数据、主数据,形成数据目录,通过数据血缘管理,追溯数据之间的血缘关系。数据质量主要包括质量规则、质量明细、质量统计、质量分析报告等,对从源端采集的数据进行完整性、一致性、冗余性、正确性校验。数据资产主要是对治理完成的数据资源进行可视化展示。
(7) 数据服务。服务创建即构建数据资源池中的服务程序。应用层通过数据服务的API网关访问数据资源池中数据,实现应用与数据分离。用户通过目录服务查看数据服务提供的服务条目。通过服务授权,确保只有经过授权的外部用户才可访问数据资源池数据。调用管理实现对外部程序访问的授权管理。监控告警模块对所有用户访问的服务进行监控,实时监控服务内容的访问成功或失败次数,同时具有服务超时自动熔断功能,避免服务死锁。
(8) 运维保障。实现整个数据接入、数据开发和数据服务过程的运行监控和管理等,主要包括资源监控、服务监控、数据库监控、日志审计、安全管理等。
3 智能煤矿数据中台关键技术
(1) 高并发低时延数据处理技术。针对煤矿端监测监控、生产自动化等系统产生的大量低时延实时监测、控制等感知数据,采用流式大数据处理技术,通过Kafka消息队列方式接收实时数据,存储在不同的消息队列分区。在数据消费时,开发基于Flink的流式数据处理系统,部署多任务处理节点。利用Hadoop的Yarn统一资源调度管理能力动态调度计算资源,采用多并发处理进程进行实时数据质量检查、逻辑计算等。经实时计算处理的数据存入二级业务Kafka,实现数据处理与数据库的解耦,提高实时数据处理效率。业务系统可根据需要直接从二级业务Kafka消费数据,进行实时数据的动态监测和预警提示。对于时效性不高的历史数据,通过时序数据库、分析型数据库自带的采集功能从二级业务Kafka消费数据。
(2) 数据分级分类存储技术。针对煤矿监测监控、生产自动化等系统产生数据类型多、实时性强等特点,按照数据仓库建设理论,设计贴源层、明细层、聚合层、应用层等分级存储层,按照数据热、温、冷特性和数据类别(基础数据、实时数据、异常告警数据、历史明细数据、统计数据,以及文档、视频等非结构化数据)分别存入不同类型的数据库,支撑数据应用层实时监测、统计分析等需求。设计包括原始库、资源库、主题库和专题库的数据仓库架构和表结构,实现热数据存入Redis内存数据库、温数据存入Clickhouse分析型数据库和MySQL关系数据库、冷数据存入Opentsdb时序数据库等。各种类型的数据库根据采集的数据资源量,采用多台机器分布式部署方式,确保数据高可用性存储。数据分类存储及支撑应用架构如图2所示。
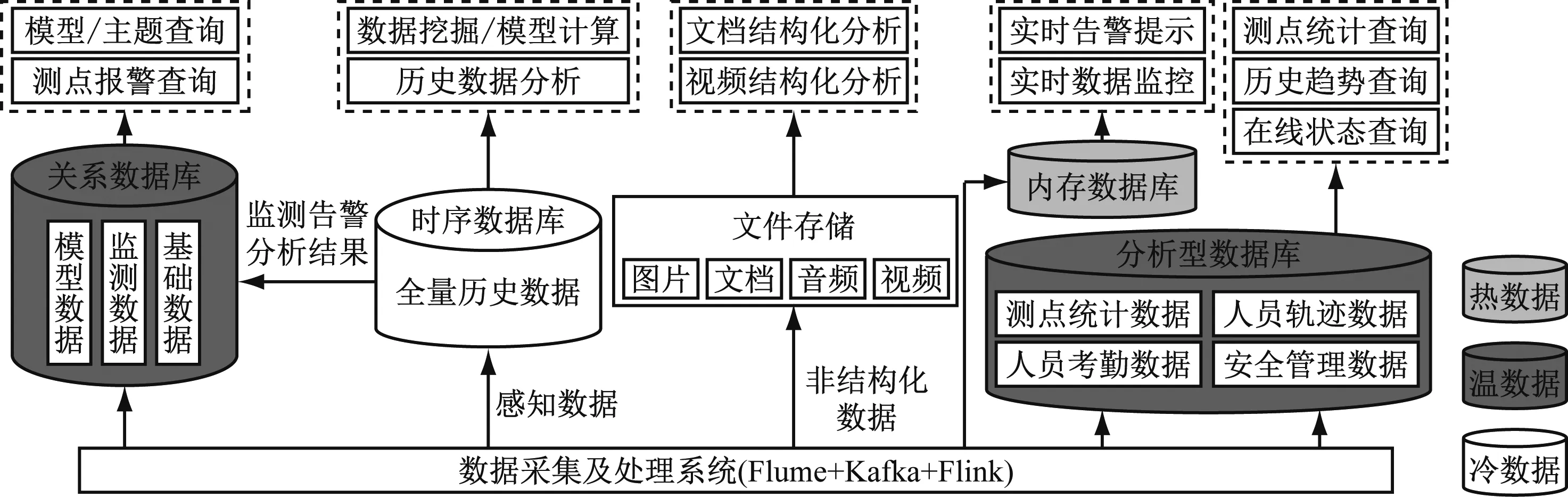
图2 数据分类存储及支撑应用架构Fig.2 Data classification storage and supporting application architecture
(3) 数据治理技术。针对异构系统融合的数据资源,根据业务类别、系统类型和数据接入规范,梳理元数据、主数据,设计不同类型业务系统的数据质量校验规则,包括正则表达式、SQL逻辑等,实现数据的一致性、完整性、及时性和准确性等校验,并按照元数据、主数据进行数据编目。对治理后存储在数据仓库中的明细层、聚合层、应用层数据,开发数据服务API网关和数据资产管理系统,对外提供数据服务,使数据资源变成数据资产,实现数据资产的共享和服务。通过数据治理,提高数据质量,确保数据真实可信,持续释放和挖掘数据价值。
(4) 基于大数据的煤矿灾害风险模型构建技术。基于煤矿井下人员信息、设备及环境感知数据、安全管理数据等,结合专家经验,基于人、机、环、管等因素构建瓦斯、冲击地压、水害等风险指标体系,应用机器学习算法和统计方法构建灾害风险模型。通过数据特征工程进行数据预处理,包括数据降噪、数据标准化、数据异常值处理、变量选择和变量生成。利用数据资源池的样本数据进行灾害模型训练,包括模型选择、模型超参数优化、模型参数训练和模型效果评价,进而形成灾害风险模型库,进行实际应用,并根据应用效果修正指标体系和灾害风险模型,形成闭环管理,如图3所示。
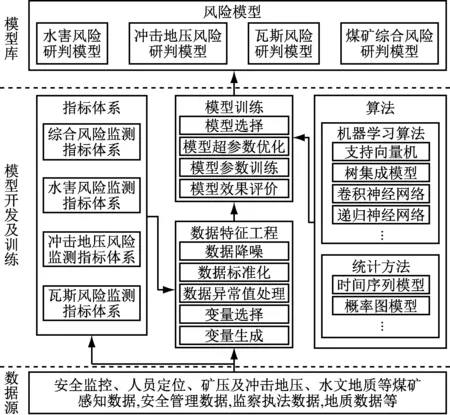
图3 煤矿灾害风险模型构建Fig.3 Construction of coal mine disaster-risk model
4 应用实例
提出的智能煤矿数据中台建设思路及相关关键技术在大同煤矿集团轩岗煤电有限责任公司进行实际应用。制定了数据接入规范,通过OPC接口方式采集自动化类系统数据,通过Kafka消息队列接口方式采集监测监控类系统实时数据,通过前置交换库方式采集安全管理数据。建立了Redis内存数据库、Clickhouse分析型数据库、Opentsdb时序数据库,针对热、温、冷数据分别存储,形成了统一的数据资源池。对采集数据进行治理,形成数据资产目录、元数据、主数据等。通过数据服务程序,供智能煤矿一体化管控平台的Web应用程序和APP程序调用,实现了通过统一数据底座支撑灾害风险模型开发训练和“一张图”、“一张表”等可视化应用。
5 结论
(1) 根据智能煤矿建设需求,提出了智能煤矿数据中台建设思路及架构,探讨了与数据中台建设相关的数据处理、分级分类存储、治理、模型构建等关键技术,形成了一套适合煤矿实际应用的数据中台解决方案。
(2) 应用结果表明,通过建设智能煤矿数据中台,可有效解决煤矿信息化过程中信息孤岛严重、信息化基础不牢、数据难集成、智能化分析水平低、应用效果不佳等问题,对充分发挥大数据在煤矿安全生产和管理中的作用有重要的现实意义。通过建设数据中台,可形成煤矿“数据大脑”,使煤矿多源异构数据从数据资源变成数据资产,提供基于大数据的调度决策、灾害风险分析、设备健康诊断和预防性维护等应用,赋能智能化煤矿建设。
