基于多头注意力循环卷积神经网络的电力设备缺陷文本分类方法
2021-07-02陆世豪祝云周振茂
陆世豪,祝云,周振茂
(1.广西电力系统最优化与节能技术重点实验室 (广西大学),广西 南宁 530004;2.广西电网有限责任公司来宾供电局,广西 来宾 546100)
电力设备巡检是保障电力系统安全运行的重要举措。巡检发现的设备缺陷将被记录到缺陷管理系统,包括缺陷发现时间、缺陷描述、缺陷等级等。判断设备缺陷等级是消缺的前提,根据电网公司设备缺陷分类标准[1],将设备缺陷按严重程度分为紧急缺陷、重大缺陷和一般缺陷,不同等级的缺陷消除时限也不同,目前缺陷分类工作主要由人工完成。随着电力系统的规模越来越庞大,设备的数量成倍增长,极大地增加了巡检工作量。同时随着设备运行时间推移和操作频次增加,加大了设备缺陷的出现几率。如果巡检人员的知识和经验不足,很容易对设备缺陷等级产生误判,影响消缺的时间和效果。因此,快速、准确地将设备缺陷进行分类对电网安全运行具有重要意义。
电网缺陷管理系统中存在大量已经消缺的历史缺陷记录,其中的缺陷描述包含缺陷的具体信息,若使用历史缺陷描述将新缺陷自动分类,不仅能提高电力系统信息资源利用率,还可降低人工分类的工作量。
电力设备缺陷描述文本涉及电力专业领域,与许多日常的中文文本存在不同。首先,每个人的用语习惯不同,描述上存在差异,对同一装置或者缺陷会出现不同表达;其次,存在相同词在不同缺陷描述中表达严重程度不同的情况,例如表1中的加粗词语在不同缺陷情况描述中所表达的程度不同;最后,缺陷描述一般会记录缺陷现象、数据、故障推断等。这类描述的内容较多,语义较为复杂,需要结合上下文理解语义,关注文中重要信息才能正确判断。

表1 缺陷描述例句Tab.1 Example sentences of defect descriptions
随着自然语言处理技术的高速发展,文本挖掘技术从早期的贝叶斯、支持向量机等浅层学习算法转向卷积神经网络(convolutional neural network,CNN)、记忆网络等深度学习算法。文献[2]对大量的设备缺陷文本进行分析,通过机器学习实现电力设备故障预测以及系统风险评估。由于中文没有空格分词,也没有固定的句法结构,因此中文的理解难度远大于英文,这也加大了在工业应用的难度。目前,国内电力自然语言处理还属于探索阶段。文献[3]利用文本挖掘模型辅助电力操作票校验,提升操作票校验的效率和准确性。文献[4]采用CNN对电力设备缺陷描述短句文本分类,相比起传统机器学习分类方法能有效降低分类错误率,但是CNN是通过增强局部感知来获取文本特征,并不能学习上下文语义,从而影响分类准确度。文献[5]使用双向长短期记忆网络(bidirectional long short-term memory,Bi-LSTM)模型根据因果关系对电力设备缺陷句子进行分类,为故障文本下一步挖掘提供条件。文献[6]将循环卷积神经网络(recurrent convolutional neural networks,RCNN)分类模型用于电力变压器缺陷文本分类中。RCNN网络由RNN和CNN两种网络结合而成,RNN网络用于处理顺序敏感的序列问题,但存在选择性遗忘信息的不足,随着时间步长的更新会造成重要信息丢失,并且通过最大池化层提取特征的方法不具备选择关注重要单词的能力。
注意力机制(attention mechanism)最早起源于视觉领域研究。注意力机制按人类视觉机制理解就是,人类的视觉系统一般会倾向于关注图像的重要部分,并且忽略无关信息[7]。同样,人们在阅读一段文字时,也会根据经验捕捉重要信息。2017年Google将注意力机制应用到机器翻译当中,并将注意力机制进行完善,提出基于多头注意力(multi-head attention,MAT)机制的翻译模型Transformer[8],Transformer打破了传统翻译模型基于RNN端到端的框架,在编码过程和解码过程完全使用多头注意力机制,通过在不同子空间下进行自注意力(self-attention)计算挖掘词与词内部联系,使得机器能够学习到长距离依赖关系,并选择性的关注重要信息。
为探索深度学习文本分类模型在电力文本识别中应用,对电力设备缺陷描述文本进行研究。根据缺陷描述文本的特点,将多头注意力机制与RCNN结合,构建基于多头注意力循环卷积神经网络(MAT-RCNN)的电力设备缺陷描述文本分类模型,并通过实例显示本文所提模型较传统的浅层分类模型、深度学习分类模型在电力设备缺陷描述文本分类性能上表现更佳。
1 预训练语言模型
1.1 文本预处理
a)中文分词。中文文本和英文文本的不同在于中文每个词之间没有空格分隔,所以需要对文本分词处理。缺陷描述文本中有许多电气领域专有名词,为了提升分词的准确性,根据缺陷设备定级标准手册与缺陷描述文本实际,自行建立电力缺陷描述词典,见表2。

表2 电气缺陷描述部分词汇Tab.2 Vocabularies of electrical defect descriptions
采用基于汉字成词能力的隐马尔可夫模型(hidden Markov model,HMM)并结合Viterbi算法[9]动态求解最佳的分词序列,通过建立词典保证电力专有名词切分的正确性。
b)去停用词。为了避免将无用词作为特征,影响文本处理效率。对于无法体现设备缺陷严重程度的词,如人名、变电站名称、地名等,通过建立停用词表,在分词后利用二叉搜索树将缺陷描述中的停用词剔除。
1.2 分布式文本表示
预处理后的文本并不能直接被任何分类器所识别,必须将其转换成为一个简洁的、统一的、能够被学习算法和分类器所识别的形式,才能进一步分析和处理。传统分类模型采用句向量[10]表示文本,通过词频、布尔值等计算方法获得权重。但是这种基于词频计算的表达方式并不能很好地表达句子语义,例如“电机表面温度>120 ℃”和“120 ℃>电机表面温度”在句义上完全不同,但是传统表示方法会将其表示为相同的句向量。并且传统方法将每个单词独立化,这就无法体现词语的相关性,例如 “视窗镜 破裂”与“视窗镜 破损”等,会被表示为不同词组。
Word2vec[11-12]是Google提出来的一种文本分布式表示方法,通过运用层次Softmax[13]和负采样2种方式,可以无监督地深度学习语义信息,并生成表征语义的低维度稠密词向量。这种方法在近义词描述、语义表达以及词之间关联度方面要优于传统方法。
本文采用Word2vec中连续词袋(continuous bag-of-words,CBOW)模型,CBOW模型是通过上下文的词语预测中间的词,从而得到中间词的向量。以预处理后的电力缺陷描述作为语料,训练出每个词的向量表示,选取部分词向量通过t分布随机邻域嵌入(t-distributed stochastic neighbor embedding,T-SNE)降至二维空间展示,如图1所示。
图1每个点代表每个词所对应的词向量,语义相近的单词如“地刀”和“刀闸”、“主变”和“变压器”在二维空间图上距离较近。语义相差较大的单词如“硅胶”与“断路器”二者距离相差较远。由此可见,训练的词向量能在一定程度上刻画出词之间的语义距离。根据电力设备用语规范[14]将同义词向量进行合并,语义存在差别的近义词向量不合并。

图1 二维空间的词向量Fig.1 Word vector in two-dimensional space
2 MAT-RCNN网络分类模型
2.1 多头注意力机制
注意力机制本质上是一个查询(query)到一系列键-值对
(1)

与传统注意力机制不同,多头注意力机制进行了多次注意力计算,从而能在不同子空间表示中多维度学习序列的关键信息,其结构如图2所示。

h—多头注意力头数即注意力运算次数;X—输入文本矩阵。图2 多头注意力结构Fig.2 Multi-head attention structure
首先,对输入矩阵X进行线性变换;然后,输入到缩放点积注意力函数中,重复h次;最后将所有的注意力值进行拼接处理,并进行线性变换。
ti=fA(XWiQ,XWiK,XWiV),
(2)
T=[t1…th]WO.
(3)
2.2 GRU结构
门控循环单元(gated recurrent unit,GRU)是LSTM的一种变体,适用于分析时间序列数据[15-16],其结构如图3所示。GRU将LSTM中的输入门和遗忘门合并成更新门,相比LSTM的三门结构,GRU的两门结构参数更少;因此,在保证效果的同时简化内部结构,缩短训练时长。

图3 GRU结构Fig.3 GRU structure

rt=σ(Wr·[ht-1,xt]),
(4)
zt=σ(Wz·[ht-1,xt]),
(5)
(6)
(7)
式(4)—(7)中:Wz、Wr、W为权重矩阵;E为单位向量;[…,…]表示2个向量的拼接;“·”表示矩阵相乘。
2.3 MAT-RCNN网络模型
本文根据多头注意力机制和RCNN的特点,提出一种MAT-RCNN分类模型,模型由输入层、注意力层、RCNN层、输出层组成,模型架构如图4所示。
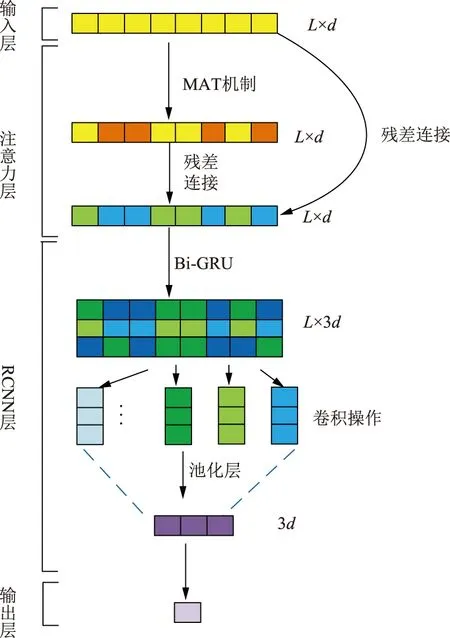
图4 MAT-RCNN模型架构Fig.4 MAT-RCNN model structure
a)输入层。将预训练的Word2vec词向量输送到文本词嵌入层,可将句子变换成可以被神经网络处理的文本矩阵。
以最长文本长度L作为模型输入大小,文本长度不足的使用零填充。句子中第i个词向量表示为ci(1≤i≤L),得到L×d的文本矩阵
(8)
b)注意力层。按照2.1节计算出多头注意力T,将输入矩阵D与T进行残差连接,归一化后输出文本矩阵:
D′1=fRC(D,T),
(9)
D1=fLN(D′1).
(10)
式(9)、(10)中:输出矩阵D1∈RL×d;fRC为残差连接操作[8];fLN为层归一化操作[8]。
c)RCNN层。注意力层输出的文本矩阵需要RCNN进一步提取特征。单向GRU网络对全文信息学习能力较弱,因此采用双向GRU网络(Bi-GRU)对文本序列学习,进一步提取特征,如图5所示。
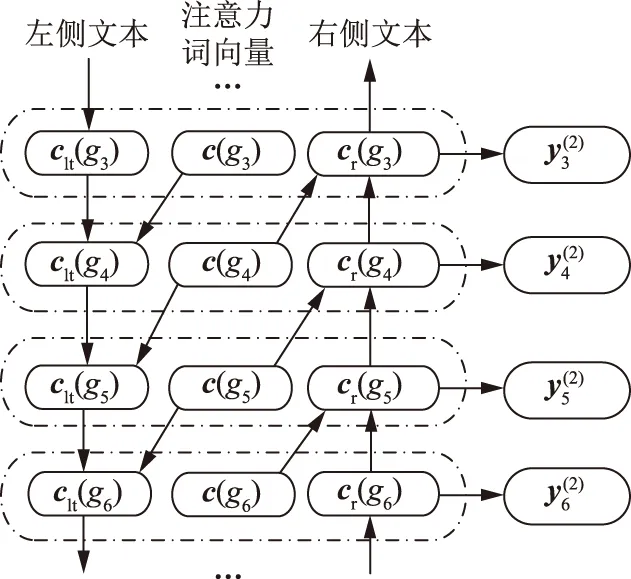
图5 Bi-GRU示意图Fig.5 Bi-GRU structure
Bi-GRU网络由2层GRU网络和注意力层输出组成,左右使用GRU网络分别学习当前词gi的左上下文表示clt(gi)和右上下文表示cr(gi),再与当前词的注意力词向量c(gi)∈D1连接,构成后续卷积层的输入xi:
(11)
(12)
xi=[clt(gi),c(gi),cr(gi)].
(13)
卷积部分使用列数与xi相同,行数为1的卷积核W(2)∈R1×3d,步长为1,激活函数为tanh,将Bi-GRU网络的输出通过卷积层进行卷积运算得到卷积结果
(14)

与文献[6]采用的池化层不同,本模型的池化层采用全局平均池化 (global average pooling,GAP)[17],卷积结果送入池化层进行特征采样。通过GAP采样得到特征信息y(3)∈R3d。
d)输出层。将最终提取的特征向量y(3)传递到输出层。采用Softmax函数计算每类概率Pi,根据概率最大值确定文本所属类别。训练时采用随机失活率(dropout)机制与L2正则化提高模型泛化能力[18]。
优化算法采用自适应矩估计法(adaptive moment estimation,ADAM)对随机目标函数执行一阶梯度优化。模型的目标函数为交叉熵损失函数
(15)
式中:N为类别个数;Pi为预测类别的概率分布;yi为样本类别真实分布。
3 算例分析
3.1 样本情况与分类评价指标
为研究本文模型对电力设备缺陷文本的分类效果,选取广西电网缺陷管理系统2016至2019年的2 150条一次设备缺陷描述文本进行研究,文本均已全部标注缺陷等级,并逐条核对。随机选取215条数据作为测试集,其余数据平均分为5份,每份387条数据,4份为训练数据,1份为验证数据,进行5次交叉验证,以测试集结果作为模型的最终评价。
在二分类问题中常采用评价指标为
(16)
式中:准确率为P=Tp/(Tp+Fp);TP为正例中预测正确的部分,FP为负例中预测正确的部分;召回率为R=Tp/(Tp+FN),FN为正例中预测错误的部分。
由于电力缺陷文本分类可分为3个缺陷等级,因此属于多分类问题,为了综合评价模型对每类的分类情况,采用宏平均综合指标[5-6]
(17)
式中宏准确率MP、宏召回率MR定义如下:
(18)
式中n为分类类别个数。
3.2 实验条件及参数设置
本文的实验环境:CPU为 Intel Core i7-8550U,具有4个处理核心;主频1.8 GHz;编程语言为Python;模型开发架构为Tensorflow。模型经过调参后,具体参数见表3。

表3 模型参数设置Tab.3 Model parameter setting
模型评价指标(MF1)如图6所示,损失值(fLoss)曲线如图7所示。由图6、图7可见,随着迭代次数增加,训练过程趋于平稳,模型的评价指标与损失值均趋于收敛。当迭代次数达到30时,训练集MF1=97.88%,验证集MF1=95.91%。

图6 训练评价指标曲线Fig.7 Training evaluation index curves

图7 训练损失值曲线Fig.7 Training loss value curves
3.3 实验结果及分析
3.3.1 多头注意力超参数取值研究
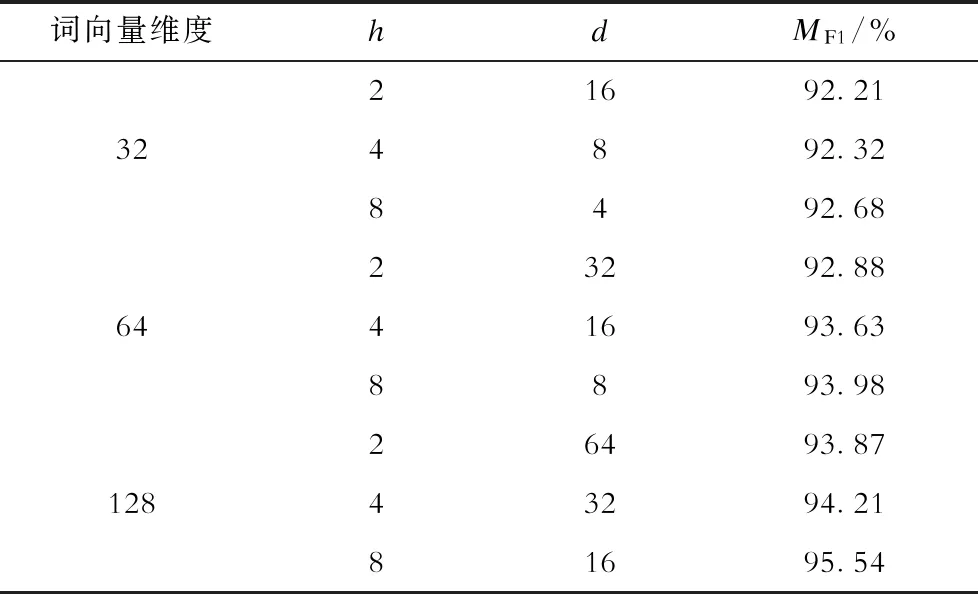
表4 不同参数实验结果Tab.4 Experimental results of different parameters
可见,当维度相同时,随着头数h增加,模型的分类效果越好,这也说明了多头注意力的优点,通过增加头数h数量,模型可从多个方面考虑文本序列内部信息,深度学习文本语义特征,从而提升模型性能。
3.3.2 注意力可视化
多头注意力机制可通过学习缺陷文本内所有词之间联系,以分配不同词语相应权重的方式自动捕获重要信息,将这些权重进行可视化操作来体现注意力机制的有效性[19-20]。以“遥控合闸时后台发控制回路断线信号现场检查发现合闸线圈烧坏”为例,输出某一子空间的注意力矩阵,其注意力分布如图8所示。

图8 注意力可视化结果Fig.8 Visualization result of attention mechanism
图8中纵坐标为方面词,横坐标为文本单词,色块的深浅代表两词之间的关联程度,关联性越强获得的权重也越大,同时注意力对这类信息的关注程度越高。
对缺陷分析可知,由于合闸线圈烧坏导致合闸回路断线,后台才发出控制回路断线信号。因此,合闸线圈烧坏与控制回路断线信号之间存在内在联系。图8中方面词“合闸线圈”向量中,“回路 断线 信号”以及“烧坏”所对应色块很深,说明注意力关注到了“回路 断线 信号”,并且捕捉到与“烧坏”这个状态词;同样,方面词“烧坏”向量中,“遥控”以及“控制 回路 断线 信号”对应的色块很深,说明这些信息和方面词之间有很强的关联度。在2个方面词中都同时关注到了“控制 回路 断线 信号”这个关联信息,但对应的其余部分颜色相对较浅,说明注意力对其余部分并未过多关注。
3.3.3 与传统模型分类效果对比实验
为对比本文模型与传统文本分类模型分类效果,分别选取词频与逆文档频率 (term frequency-inverse document frequency,TF-IDF)、潜在语义索引(latent semantic indexing,LSI)、隐含狄利克雷分布主题模型(latent Dirichlet allocation,LDA)3种特征提取方法。分类器选择朴素贝叶斯(naive Bayesian,NB)、支持向量机(support vector machine,SVM)、决策树(decision tree,DT)。实验结果如图9所示。

图9 传统文本分类模型实验结果Fig.9 Experimental results of traditional text classification models
从表4和图9分析可知本文模型在分类效果上优于传统分类模型。因为传统分类模型的特征提取方法假设每个词之间是相互独立,因此无法学习词之间的关联信息,所采用的分类器仅能浅层分析文本语义。而深度学习模型可以无监督地学习词之间的相关度,利用神经网络进一步提取语义信息,所以分类效果更佳。
3.3.4 与CNN、RNN、RCNN模型对比实验
对比提出的MAT-RCNN模型与CNN、RNN、RCNN在分类性能上的优劣,采用相同方法进行实验,其中CNN模型为文献[4]的模型,RNN模型分别采用Bi-GRU和Bi-LSTM[5],RCNN模型选用文献[6]中的模型。实验结果均在每个模型最优参数下获得,实验结果如图10所示。

图10 与CNN、RNN、RCNN模型对比结果Fig.10 Comparison results of CNN,RNN and RCNN models
如图10所示,本文所提出的模型在分类效果上要优于其他对比模型。CNN模型的MF1最低,这是由于CNN是通过卷积核逐块扫描的方法提取特征,因此无法关注到上下文的语义联系。Bi-GRU与Bi-LSTM分类效果相差不大,但Bi-GRU的分类效果要稍好于Bi-LSTM,这种双向的RNN循环结构在一定程度上能获取上下文信息。RCNN在双向循环结构的基础上加入最大池化层,在获取上下文信息的同时较大程度保留关键语义,在分类效果上优于双向RNN模型。本文所提出的模型利用多次注意力计算获取文本内部联系,从而突出文本重要特征,并通过RCNN进一步提取语义信息,因此在语义理解方面要优于对比模型。
对各个模型训练耗时与测试耗时进行研究,由于词向量维度大小会对耗时产生影响,词向量越大耗时越长,词向量维度在50~150之间变化时,模型的综合指标MF1变化幅度不超过0.6%。因此,为了客观地对每个模型训练耗时与测试耗时进行测试,将输入词向量维度设置为128,迭代次数为30次,分别对每个模型进行实验,结果见表5。
由表5可知,随着模型的复杂程度增加,模型的耗时也会增加。由于CNN模型采用不同卷积核并行运算,因此耗时最少。Bi-GRU模型训练耗时少于Bi-LSTM模型,因为GRU模型的两门设计相比起LSTM的三门设计,结构简单,训练耗时少,这也是本文模型的RCNN网络层采用Bi-GRU网络的原因。本文模型由于模型结构相比于对比模型复杂,因此训练耗时较长,但是测试耗时相对于对比模型相差不大,在实际应用中仅需加载训练好的模型对测试数据进行计算,所以实际中仅用考虑测试耗时,模型测试耗时为1.005 s,远低于人工分类耗时。

表5 深度学习模型分类性能对比Tab.5 Performance comparisons of deep learning models
4 结束语
采用多头注意力机制与RCNN对电力设备缺陷描述文本实现自动分类,通过实验证明多头注意力机制结合RCNN在语义学习和缺陷描述文本分类效果上优于CNN、RNN、RCNN等模型。所提方法可以通过语义学习有效地识别缺陷的严重程度,提升了巡检效率。
