基于轻量级网络的钢铁表面缺陷分类
2021-07-02史杨潇
史杨潇,章 军,陈 鹏,王 兵
(1.安徽大学电气工程与自动化学院,合肥 230601;2.安徽工业大学电气信息学院,安徽马鞍山 243002)
(∗通信作者电子邮箱1142752120@qq.com)
0 引言
钢铁表面缺陷分类是工业缺陷检测的关键环节。然而,在传统工业中,这个环节往往是手动执行的。为了取代手工操作,人们希望机器能够利用计算机视觉技术自动检测钢铁表面缺陷[1]。
由于钢铁表面缺陷图像受到光照和材质变化的影响,并且钢铁表面类内缺陷在外观上存在较大差异,类间缺陷又有相似的方面[2],利用计算机视觉技术进行缺陷分类,仍然是一个巨大的挑战。目前的图像分类方法主要为两类:传统机器学习图像分类算法和基于卷积神经网络(Convolutional Neural Network,CNN)[3]的深度学习方法。传统图像分类算法主要采用特征提取和分类器设计两大步骤来实现,如K近邻(K-Nearest Neighbor,KNN)算 法[4]、支持向量机(Support Vector Machine,SVM)[5]以及神经网络[6]等。在实际缺陷分类应用中会面临各种复杂的情况,使用传统的图像处理方法在准确率上很难达到要求。
近年来,基于深度学习的图像分类方法取得了很好的效果,例如VGGNet(Visual Geometry Group Network)[7]、ResNet(Residual Network)[8]等。然而,最先进的CNN 需要数十亿次浮点运算,这使得它们无法用于移动或嵌入式设备。例如,ResNet-101 的复杂度为7.8×109FLOPs(FLoating-point Operations Per second),即使使用强大的GPU 也无法实现实时检测。考虑到现代CNN 的巨大计算成本,轻量级神经网络被提出部署在移动或嵌入式设备上。例如:MobileNetV1[9]和MobileNetV2[10]采用深度可分离卷积来构建轻量级网络;ShuffleNet[11]采用分组卷积和深度可分离卷积来构建轻量级网络;SqueezeNet[12]利用核心模块Fire 压缩模型参数,减小网络的深度,降低模型的大小;SENet(Squeeze-and-Excitation Network)[13]提出的SE 模块是一种轻量级注意力机制,通过学习通道重要性的方式自适应校准特征图,然而SE模块只关注了特征图通道方面的影响而忽略了空间维度的重要性。同时,目前已有研究者进行轻量级网络应用在缺陷和分类方面的研究,如:姚海明等[14]提出了一种用于实时检测瓷片表面缺陷的MagnetNet;张琪等[15]提出了一种改进的用于对肝部病理组织进行分类的MobileNet。
轻量级网络可以在有限的计算预算下获得相对较高的精度。然而现有轻量级网络倾向于使用“稀疏连接”卷积,例如深度卷积和群卷积,而不是标准的“完全连接”卷积。这种“稀疏连接”卷积在降低参数量的同时,一定程度上会阻碍组间信息的交换,导致网络性能下降。而实用的钢铁缺陷分类算法需要部署在CPU 甚至嵌入式系统上,因此需要采用一种可以避免组间信息丢失的具有较低计算复杂度,同时具有较高分类准确率的算法。
本文提出了一种新颖的Mix-Fusion 网络模型,以ShuffleNet 的通道洗牌单元和MENet(Merging-Evolution Network)的融合编码模块为核心,构建出具有三个分支的MF(Mix-Fusion)模块。该模块通过标准分支保留原有特征;通过降参分支降低计算成本的同时优化了模型精度;通过融合分支避免组间信息的丢失。同时,将该轻量级网络与混合卷积模块融合,提高了网络对于不同分辨率模式的捕获能力,获得了更好的模型精度及效率。在NEU-CLS 数据集上进行实验验证,通过和其他方法的比较结果可以得出,Mix-Fusion 网络模型避免了组间信息的丢失,进一步降低了参数量和计算量,显著提升了分类精度。
1 Mix-Fusion网络的构建
由于深层神经网络计算量大、模型容量大,神经网络的压缩和加速问题已成为深度学习领域的研究热点。在嵌入式设备上运行高质量深层神经网络的需求不断增加,更是鼓励了对轻量级网络模型设计的研究。这些网络倾向于利用“稀疏连接”卷积,在减小计算成本的同时也会阻碍组间的信息交换。本文借鉴了ShuffleNet 和MENet[16]的思想,并加入 了MixConv[17]卷积模块,提出了一种Mix-Fusion 网络。该网络在分类精度提高的同时,计算成本也有所下降。
1.1 通道洗牌网络单元
通道洗牌网络单元(Channel-shuffle)是ShuffleNet 网络的核心,目的在于解决组卷积阻碍组间信息交换、导致性能下降的问题。如图1 所示,将3 组原始通道每组再次平均分为3组,用①~⑨表示,通道洗牌操作将9组通道打乱重置,使得第二卷积层中的每个组包含来自第一卷积层中每个组的通道,在一定程度上实现了组间信息的交换。

图1 通道洗牌网络单元示意图Fig.1 Schematic diagram of channel shuffle network unit
然而,当每组通道数为3 时,通道洗牌无法完全避免组间信息的丢失,第二卷积层中的每个组仅从第一卷积层的每个组接收一个通道,导致每个组中其他两个信道被忽略。因此,大部分组间信息无法利用。这个问题在更多的信道组中会更加严重。随着组数的增加,每组通道数增加,然而第二卷积层接收的通道数仍然保持为1 个,同时每组忽略的通道数量也增加,造成组间信息丢失严重,网络性能大幅下降。
1.2 融合编码模块
为了解决组间信息丢失的问题,本文借鉴了MENet 中合并和进化的思想。如图2 所示,利用一个狭窄的特征映射对组间通道信息进行融合编码,并对其进行匹配变换后与原始网络相结合以获得更具区分性的特征。操作如下:

图2 融合编码模块示意图Fig.2 Schematic diagram of fusion coding module
1)通道融合。通道融合的目的是将所有通道特征聚合,并对组间信息编码,形成一个狭窄的特征映射。在组卷积生成的原始特征图F∈RC×H×W基础之上,网络对其进行融合编码变换TF:RC×H×W→,达到对所有通道的特征进行聚合的目的。其中:C为原始特征图的通道数;H和W为原始特征图的宽和高;CM为融合特征图的通道数。由于C比较大,在不影响计算成本的前提下,很难对空间信息进行集成。因此本文首先利用1×1 单点卷积完成融合编码变换,将同一空间位置上所有通道的特征聚合起来,同时降低通道数量并进行批处理规范化[18]和ReLU(Rectified Linear Unit)激活。
2)空间变换。由于计算成本的限制,通道融合操作未对空间信息进行集成,因此引入一个标准的3×3 卷积核进行空间变换TS:。空间变换操作能够在不改变通道数的情况下提取更多的空间信息,之后进行批处理规范化和ReLU激活。
3)匹配变换。为了将处理后的特征图与原始网络相结合以获得更具区分性的特征,网络对空间特征图进行匹配变换TM:,之后进行批处理规范化和Sigmoid激活,得到与原始特征图一样维度的匹配特征图。最终,将匹配特征图作为神经元尺度因子,与原始网络以元素乘积的方式相结合,进一步提高特征在网络中的表达能力。在通道融合过程中,1×1 单点卷积操作对于每一个通道的信息都进行了编码,因此在最终的匹配特征图中,变换后的通道都包含了来自原始特征图每一个通道的信息,这避免了卷积过程中组间信息的丢失。
1.3 混合卷积模块
深度卷积(DepthWise Convolution,DWConv)在现代轻量级网络中越来越流行,常用的深度卷积将每个通道单独分为一组进行组卷积,从而极大降低了参数量和计算成本。然而传统做法都是简单地使用3×3 卷积核[19],忽视了卷积核的大小。本文借鉴MixConv 多核结合的思想,使用不同大小组合的卷积核替代深度卷积,大卷积核能够在一定范围内提高模型精度,多卷积核则能提高模型在不同分辨率下的适应度。
如图3 所示,不同于将单个内核应用于所有通道的深度卷积,混合卷积将通道平均划分为若干组,并对每个组应用不同大小的内核。网络既需要大卷积核来捕捉高分辨率模式,也需要小卷积核来捕捉低分辨率模式,以获得更好的模型精度和效率。相较于多分支网络集中改变神经网络的宏观结构以利用不同的卷积运算,如Inception[20]和NASNet[21],混合卷积在不改变网络结构的情况下,能够替换不同大小组合的卷积核以测试模型性能。

图3 深度卷积和混合卷积原理Fig.3 Principles of deep convolution and mixed convolution
1.4 Mix-Fusion模块
基于上述单元,本文提出了MF 模块。MF 模块由图4(a)从左至右三个分支组成:标准分支、降参分支和融合分支。标准分支是对原始特征图的直接映射。降参分支采用“稀疏连接”卷积,它由三层组成:第一层单点群卷积降低了计算成本,之后执行通道洗牌操作以减少组间信息丢失。第二层混合卷积添加在通道洗牌操作之后,利用混合卷积核在不同分辨率下的高适应度获得更加稳定的特征图,通过混合卷积中的大卷积核保留更多的特征信息;之后与融合分支处理后的特征图结合,成为连接降参分支和融合分支的桥梁。第三层单点群卷积是为了恢复通道维数以匹配标准分支。融合分支对网络进行融合编码,并在第三层单点群卷积前与降参分支以元素乘积的方式相结合,这种设计有助于降低第三层卷积过程中组间信息的丢失。
图4(b)为MF 模块的下采样版本,做了以下修改:1)降参分支的混合卷积和融合分支中的3×3标准卷积的步长变为2。2)在标准分支中应用了步长为2的3×3平均池化,并用元素拼接(Concat)的方式代替了元素加法,将标准分支和降参分支结合起来。经过下采样MF 模块后,特征图的空间维数被减半,而通道维数则增加了1倍。
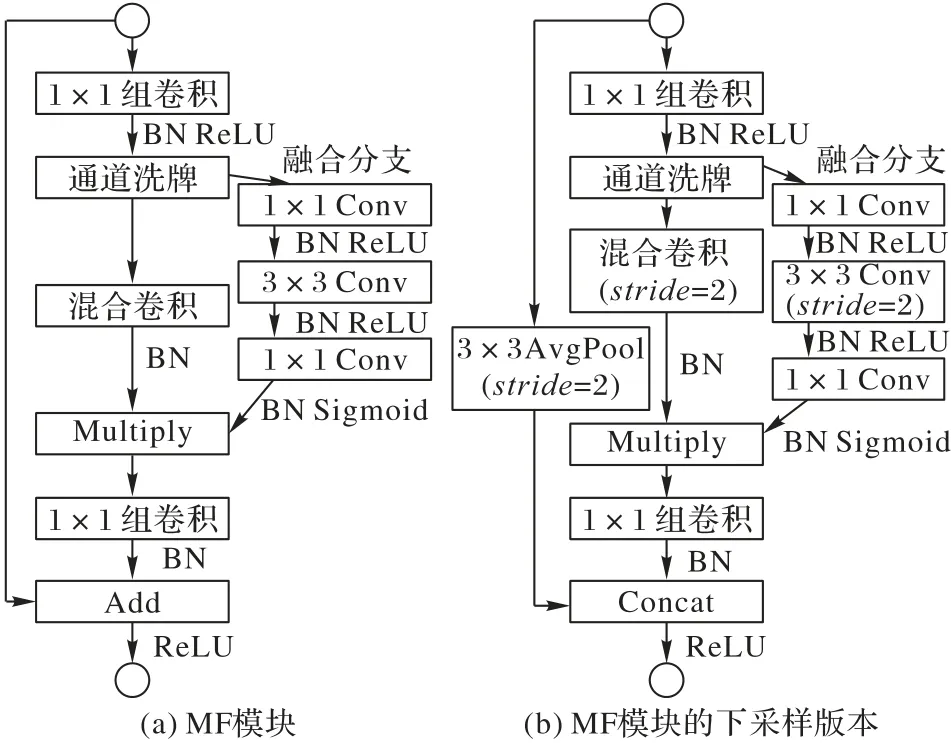
图4 Mix-Fusion 模块示意图Fig.4 Schematic diagram of Mix-Fusion module
1.5 Mix-Fusion网络
基于MF 模块,本文提出了一种新颖的网络结构Mix-Fusion,总体结构如表1 所示。网络结构分为4 个阶段:阶段一包括步长为2的一个3×3卷积层和max pooling层,这两层对输入图像执行4倍的下采样以降低计算成本;之后3个阶段都是由一个下采样MF 模块和若干标准MF 模块组成。模块类型后面的数字代表输出通道的数量。“×3”和“×7”分别表示MF模块重复3 次或7 次,“/2”表示步长为2,带有“/2”的MF 模块执行下采样功能。表1 中的“分类层”为采用核大小为7 的全局平均池化层,通过全连接层输出6 类缺陷的概率,生成预测分类。

表1 Mix-Fusion网络结构Tab.1 Network structure of Mix-Fusion
输出通道的数量在同一阶段中保持不变,在下一阶段中增加1倍。此外,降参分支中的通道数被设置为同一MF 模块中输出信道的1/4以节省计算成本。最后,本文将降参分支中组卷积的组数设置为3,进而增加降参分支的连接稀疏度。
2 实验设计及结果分析
2.1 实验数据集
本文采用东北大学收集的热轧带钢表面缺陷数据集NEU-CLS[22]。该数据集收集了六种典型热轧带钢表面缺陷,包括裂纹(Cr)、夹杂(In)、裂斑(Pa)、麻点(PS)、轧屑(RS)和划痕(SC)。每一类缺陷有300 个样本,每幅图像的原始分辨率为200 像素×200 像素。该数据集主要面临两个挑战:1)类内缺陷在外观上存在较大差异;2)类间缺陷有相似的方面,由于缺陷图像受到光照和材料变化的影响,类间缺陷图像的灰度也会发生变化。部分缺陷图像示例样本如图5所示。

图5 示例缺陷图像及对应标签Fig.5 Sample defect images and corresponding labels
2.2 基准实验
本文在NEU-CLS 数据集上提取了一种常用的传统纹理特征并进行基准测试,即灰度共生矩阵(Gray-Level Co-occurrence Matrix,GLCM)[23]。GLCM 描述了具有某种空间位置关系的两个像素灰度的联合分布,它可以反映像素的分布特征以及图片的纹理特征。本文选取对比度、差异性、同质性、熵、相关性、能量六种灰度共生矩阵统计量的组合作为需要提取的特征,并选取支持向量机(SVM)作为分类器,svm.SVC 作为SVM 类,linear 作为核函数,惩罚因子C设置为0.5,最终分类结果达到了90.81%。
这种由特征提取算法加分类器设计的传统方法是目前工业界主流的一种表面缺陷分类方法,将此SVM+GLCM 作为基准实验并与Mix-Fusion网络比较可以保证实验的可靠性。
2.3 环境与训练
本文的算法是在PyTorch 框架上进行的,实验环境配置为:Inter Core i7-6700 CPU@ 3.40 GHz 处理器,16 GB 内存,NVIDIAGeForce GTX 1080显卡,操作系统为Windows 10。
实验从数据集中随机选取1 440张图像作为训练集,剩余360 张图像作为测试集。网络在训练阶段采用Adam 优化算法基于训练数据迭代地更新神经网络的权重,每一个批次(batch)包含32 张图像,权值的初始学习率0.02,每隔10 个epoch 学习率衰减一次,衰减系数设置为0.9。在训练前将数据图像边缘调整为256像素,之后中心裁剪为224×224像素进行实验。
2.4 结果分析
为测试网络模型在钢铁表面缺陷分类任务中的综合性能,本文引入了四种评价指标:计算力,即每秒所执行的浮点运算次数(FLoating-point Operations Per second,FLOPs)、参数量、精度以及平均运行时间,并使用PyTorch-OpCounter 工具测试出网络的FLOPs 以及参数量。其中,FLOPs 表示浮点运算数,用来衡量模型的复杂度,复杂度越低,模型越轻便,一般轻量级网络的FLOPs 可以降到150×106以下。精度反映了模型在缺陷分类任务中的准确率,运行平均时间为单张图像连续运行12次,去掉一个最大值和一个最小值后取10次运行的平均结果,衡量了模型的运行速度。表2 展示了在NEU-CLS数据集上Mix-Fusion 和一些最先进的网络结构以及基准实验关于四种评价指标的比较情况。表2 中的MFLOPs(Million FLOPs)用来衡量FLOPs,指每秒浮点运算次数为106。

表2 不同网络综合性能对比Tab.2 Comparison of comprehensive performance of different networks
为验证提出的不同模块对于网络性能的影响,本文设计了一个只使用传统深度卷积的Mix-Fusion(Base)网络。基础网络结构与图4 保持一致,仅仅将模块示意图中的混合卷积替换为卷积核尺度一致的3×3 深度卷积,结果表明该网络测试效果明显优于基准实验,分类精度达96.67%。之后将Mix-Fusion(Base)网络与三种 经典的流行网络(GooGleNet[24]、ResNet-50以及AlexNet[25])作比较。其中AlexNet及ResNet-50分别取得了95.00%和95.56%的分类精度,而GooGleNet 取得了稍好的精度96.38%。相比较之下,Mix-Fusion(Base)相较AlexNet 精度提高了1.67 个百分点的同时FLOPs 数量减少为原来的1/17.2,相较ResNet-50 精度提高了1.11 个百分点的同时FLOPs数量减少为原来的1/99.7,相较GooGleNet精度提高了0.29 个百分点的同时FLOPs 数量减少为原来的1/36.5。上述结果充分说明了组卷积和通道洗牌操作具有降低网络参数量的作用,且融合编码操作打通了组间信息交流,具有降低性能损失的有效性。
之后,本文实验了不同大小混合卷积核对于Mix-Fusion网络性能的影响。如表2 所示,网络名称的数字后缀代表了混合卷积核的组合大小,如Mix-Fusion(3-5)代表将通道平均划分为两组,分别应用{(3×3),(5×5)}的混合卷积核。实验结果显示,随着混合卷积模块的加入,模型精度有所提高,其中Mix-Fusion(3-5-7)取得了最好的精度98.61%,表明混合卷积可以有效降低网络对大卷积核的敏感度,提高网络稳定性,优化模型性能。
为做出全面的比较实验,本文引入带有通道注意力机制的SENet 进行比较。如表2 所示,尽管SE-ResNet-50 和SEResNet-101 的分类精度高出Mix-Fusion(3-5)和Mix-Fusion(3-5-7-9),但是Mix-Fusion(3-5-7)的分类精度依然略微胜出,同时Mix-Fusion 网络的运行速度要远快于SE-ResNet 网络,SE-ResNet网络的参数量和复杂度远大于Mix-Fusion网络。
表3展示了Mix-Fusion网络对于数据的依赖性分析,训练数据占比代表新的训练集在原始训练集中所占百分比。当训练数据占比为50%和25%时网络精度略微下降,当训练数据占比为10%及以下时网络性能会极大下降,并出现轻微的过拟合现象,表明本文网络对数据量有一定的依赖性。

表3 不同训练数据占比的网络精度对比Tab.3 Comparison of network accuracy with different training data ratios
为分析网络的收敛性及稳定性,图6 展示了Mix-Fusion、ShuffleNetV2以及MobileNetV2三种网络的训练损失曲线和验证准确率曲线。
如图6(a)所示,Mix-Fusion 网络收敛最快,loss 稳定在0.004;ShuffleNetV2 收敛速 度次之,loss 稳定在0.005;MobileNetV2 收敛最慢,loss 稳定在0.009。图6(b)中,Mix-Fusion 的验证准确率明显高于另外两个网络,同时准确率曲线趋势显示Mix-Fusion 和ShuffleNetV2 的稳定性较高,MobileNetV2次之。

图6 不同模型性能比较Fig.6 Performance comparison of different models
为了验证模型的有效性,本文进一步比较了Mix-Fusion与三种先进的轻量级网络ShuffleNet、ShuffleNetV2 以及MobileNetV2 的综合性能,如表4 所示。由表4 可以看出,Mix-Fusion 的性能优于ShuffleNet。考虑到在Mix-Fusion 中降参分支的通道比在ShuffleNet中要少,将这种改进归因于所提出的融合编码操作。尽管ShuffleNet拥有更多的通道,但它依然遭受着组间信息丢失的困扰,而Mix-Fusion 有效地利用了组间信息。因此,Mix-Fusion 比ShuffleNet 产生了更具有区分性的特征,克服了性能下降的缺陷。同时与ShuffleNetV2、MobileNetV2 相比,Mix-Fusion 的分类精度在最小计算成本的基础上取得了分别高于前两者1.36 个百分点以及1.67 个百分点的好成绩。

表4 不同轻量级网络综合性能对比Tab.4 Comparison of comprehensive performance of different lightweight networks
综上所述,Mix-Fusion 无论是在与传统纹理特征提取方法(GLCM),还是其他几种经典网络或是先进的轻量级网络的对比中都能够在更小的计算成本代价下取得更高的分类精度和更快的运行速度。一方面是因为MF 模块的融合分支有效地解决了“稀疏连接”卷积阻碍组间信息交换的问题,降参分支极大降低了网络的计算量;另一方面是因为混合卷积相较于传统的深度卷积,降低了网络对大卷积核的敏感性,提高了网络的稳定性。
3 结语
针对卷积神经网络参数量、计算成本日益增长以及现有轻量级网络难以完全避免组间信息丢失的问题,本文借鉴了ShuffleNet 和MENet 的思想,提出了一种新颖的轻量级网络Mix-Fusion。实验结果表明,该网络避免了组间信息丢失,提高了分类精度,降低了计算成本和参数量,相较其他网络综合性能有明显提升,为钢铁表面缺陷分类任务在移动端的部署提供了有力支持。我们接下来的工作是进一步验证模型的泛化性能,并开展优化算法、适配设备等方面的工作以满足产品化的需求。
