基于联邦学习的在线短视频内容分发策略
2021-07-02董文涛
董文涛,李 卓*,陈 昕
(1.网络文化与数字传播北京市重点实验室(北京信息科技大学),北京 100101;2.北京信息科技大学计算机学院,北京 100101)
(∗通信作者电子邮箱lizhuo@bistu.edu.cn)
0 引言
根据Cisco 年度互联网报告[1]预测,到2023 年,5G[2]速度将达到现有平均移动连接速度的13 倍,加之多媒体技术的高速发展,短视频应用(如:抖音、快手、火山短视频等)已成为当今互联网上的主流应用和占用网络带宽最多的应用[3]。据抖音官方发布的《2019抖音数据报告》[4]显示,截至2020年1月5日,抖音的日活跃用户已经超过了4 亿,因此通过可移动设备观看视频产生的网络流量将成为互联网流量的主要来源。随着网络基础设施的不断升级,一些具有缓存功能的网络架构[5]被提出。通过将未来流行度较高的视频内容缓存在移动边缘计算(Mobile Edge Computing,MEC)服务器的缓存中,可以有效地减少视频内容访问时延和从原始内容服务器检索视频的次数[6]。目前主要有两种内容分发策略[7]:基于拉(Pull)的分发策略和基于推(Push)的分发策略。其中基于拉的分发策略是一种基于用户需求的、被动的内容分发策略[8]。基于推的分发策略是在用户对视频内容发起请求之前,视频内容提供商把用户群即将请求或者最希望观看的一部分视频内容提前缓存在MEC 服务器的缓存中[9]。然而,随着智能终端的快速普及和短视频业务的飞速发展,在像抖音、快手等基于主动推荐方式的短视频应用中,基于拉的分发策略很难满足不同用户对短视频内容的个性化需求。在现有的基于推的缓存策略研究中,如何精准地预测出用户群即将请求或者最希望观看到的一部分短视频内容也是一大难点,有待进一步研究。如何将用户群感兴趣的短视频内容提前分发到MEC 服务器中,将会影响到用户群对该类短视频软件的使用体验。
本文主要研究了在边缘计算的环境下如何设计有效的分发策略将用户群感兴趣的短视频内容提前从源服务器分发到MEC 服务器中。首先,利用联邦学习的训练方式得到一个兴趣预测模型,提出用户群兴趣向量预测算法,进而由该算法得到用户群的兴趣向量表示;然后,以用户群的兴趣向量作为输入,提出基于联邦学习的组合置信上界(Federated Learning Combinatorial Upper Confidence Bound,FLCUCB)算法,进而使视频内容提供商获取的长期利润最大化。实验结果表明,本文所提策略获得的平均利润相对稳定且明显优于单纯基于组合置信上界(Combinatorial Upper Confidence Bound,CUCB)算法的短视频分发策略。在视频内容提供商获得的总利润方面,本文所提策略与置信上界(Upper Confidence Bound,UCB)策略和随机策略相比,分别提高了12%和30%。
1 相关工作
随着边缘计算的逐渐成熟,文献[10-11]考虑了MEC 服务器的计算能力,因此可以在MEC 服务器上处理视频或者执行其他相关计算。近年来深度学习在图像识别、语音识别、自然语言处理等领域取得了巨大的成就,它能够达到较高的预测精度,点亮了连续数据处理,如文本和语音处理的发展道路[12]。文献[13-17]研究了如何基于深度学习进行视频内容的流行度预测。Li等[14]以中国领先的在线视频服务提供商优酷的数据为基础,对如何了解网络视频的人气特征、预测单个视频的未来人气等问题进行了解决。Liu 等[15]基于软件定义网络(Software-Defined Networking,SDN),提出基于深度学习的内容流行度预测(Deep-Learning-based Content Popularity Prediction,DLCPP)来实现流行度预测。大量的实验结果表明,DLCPP 具有更高的预测精度。但是以上研究都没有将其应用到短视频内容的预缓存中。由于在移动端缺乏计算资源和训练数据,文献[18]设计了一个基于学习的系统结构,将训练数据集中到云端后,利用云端的计算资源进行深度学习模型的训练,在MEC 服务器上基于该模型预测的视频内容流行度得分进行视频内容的预缓存。但将本地数据上传到云端,会带来隐私数据泄露的风险,加之需要上传的数据量巨大,还会造成大量的通信开销。
文献[19]利用联邦学习,在一个分散的大数据集上通过分布式的方式进行模型训练,基于TensorFlow 在移动设备领域构建了一个可扩展的联邦学习生产系统。文献[20]考虑了从一个分布在多个边缘节点的数据中学习模型参数的问题,提出一种在给定资源预算下,通过控制本地更新和全局参数聚合的最优折中来最小化损失函数的控制算法。联邦学习可以有效地减少模型训练过程中的开销和避免隐私数据泄露的风险,但目前很少有研究将联邦学习应用到短视频内容的分发策略中。文献[21]充分利用MEC 服务器的缓存和计算能力,考虑了视频内容多比特率的特性,将问题建模为0-1 优化问题,设计了视频缓存和处理模型,为视频内容提供商提供最大利润。由于社交网络发展迅速,导致新的访问热点频现,基于主动推荐方式的短视频应用中的视频内容生命周期越来越短,文献[21]中设计的视频缓存和处理模型并不适用于该应用场景。
2 系统模型
本章中将介绍如何将更符合用户群兴趣的一部分短视频内容提前分发到MEC 服务器上。如图1 所示,在本文介绍的系统中,假设有三个角色,分别是视频内容提供商、MEC 服务器和代表用户群的多个移动设备。移动设备通过无线网络连接到MEC 服务器,MEC 服务器将其缓存中的视频内容主动推送到移动设备。假设视频内容提供商主要从广告费用中获取利润,如果视频内容提供商将广告植入到某些将被点赞、收藏或转发更多次的视频内容中,它将会获得更高的利润。也就是说,视频内容提供商希望他预缓存在MEC 服务器中的视频内容将会获得更多的点赞次数、收藏次数或者转发次数。因此视频内容提供商需要决定将哪些短视频内容提前缓存在MEC服务器上来使他获得的利润最大化。
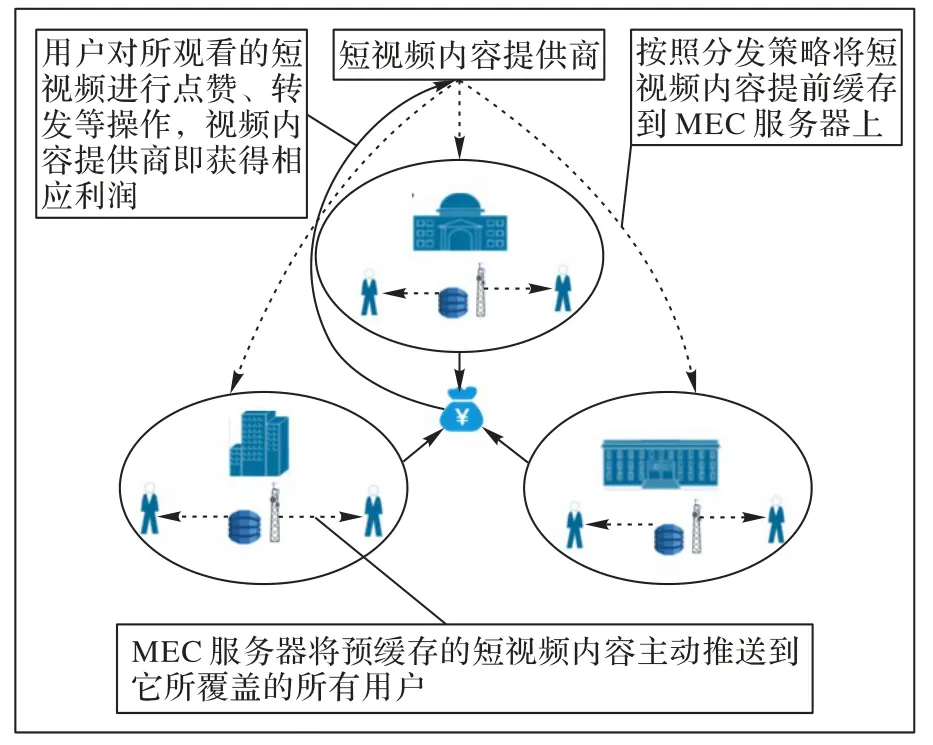
图1 视频缓存和获利示意图Fig.1 Schematic diagram of video caching and profit gain
2.1 预缓存视频内容的动机
预缓存视频内容到MEC 服务器后,当用户访问这些内容时,这些内容将会被在离用户较近的MEC 服务器中获得,减少骨干网络中的网络流量,有效降低源服务器的负载,极大降低用户的访问时延,改善用户的体验质量。在本文中,假设用户访问的短视频内容全部由其所在区域的MEC 服务器主动推送,所以不考虑用户的时延问题。但视频内容提供商获取的利润和其推送的内容被点赞、收藏或者转发的次数成正相关关系,因此需要在学习用户群兴趣方向的基础上,制定合理的分发决策,使视频内容提供商获取尽可能多的利润。
2.2 系统模型设备和视频内容
本文假设该系统中有Z个可移动设备,即Z个用户,J种类型的视频内容。定义Zagg={1,2,…,z,…,Z}表示Z个可移动设备的集合,Jagg={1,2,…,j,…,J}代表有J种类型的视频类型集合,Kagg={1,2,…,k,…,K}表示所有的视频内容集合。实际运用中,MEC 服务器的缓存大小是有限的,定义其容量为C,每个短视频内容的大小为κ。以下所有操作都在离散化的时间t=1,2,…,T内完成。
2.3 视频缓存和约束
对于某一个属于类型j的短视频内容k,本文用缓存决策变量∈{0,1}表示它在时间t是否被缓存在MEC服务器上。如果=1表示缓存该类型为j的短视频内容k到MEC服务器,=0表示该短视频内容不会被缓存在MEC服务器上,即:

因为在每一个MEC 服务器中其缓存大小有限的,所以MEC服务器上缓存的视频总容量不能超过C,即:

2.4 视频提供商盈利模型
本文的优化目标是使视频内容提供商获得的利益最大化。对于视频内容提供商来说,本文假设它的盈利主要来自广告费用。它所拥有的用户越多,获得的利润相对也就越多。定义每一个用户对视频内容提供商带来的基础利润为ψ。当用户对所看到的视频进行点赞、收藏、转发操作时,视频内容提供商就能获得更多的广告费用。为表述方便,本文将点赞、收藏、转发等操作统一称作被用户认可,并且同一个视频内容k只能被一个用户认可一次。定义为在时间t类型为j的视频内容k的被认可度:

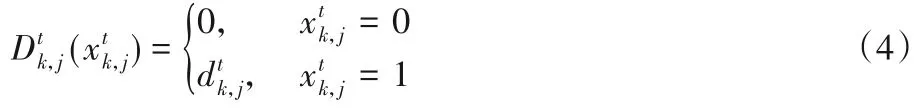

3 问题定义
本文将分发策略定义为视频内容提供商获取利润最大化问题,即在每一个MEC 服务器覆盖的范围内视频内容提供商都能获得最大利润。假设每一个用户所观看的视频内容都由它所在区域的MEC 服务器主动推送,该优化问题可以定义如下:

上面的目标函数用于最大化视频内容提供商获取的利润。第一个限制条件表示在MEC 服务器上缓存的视频总大小不能超过MEC 服务器的最大容量;第二个限制条件表示在时间t时类型为j的视频内容k是否缓存在MEC服务器上。
定理1本文求解的视频内容提供商利益最大化问题是NP-难问题。
证明 本文求解的视频内容提供商利益最大化问题是要将用户群感兴趣的多种类型的短视频分发到MEC 服务器上。如果每种类型的短视频内容所占存储空间一定,而且其被分发到MEC 服务器后视频内容提供商所获得的利润总是一定的,此时该优化问题就是传统的0-1 背包问题。因此本文要求解的优化问题至少与0-1背包问题一样难。已知0-1背包问题已经被证明为NP-难问题,因此本文求解的问题是NP-难问题。
解决以上优化问题还存在如下挑战:1)在日常的实际应用中,用户对某些类型的短视频兴趣度并非是一成不变的,存在着常见的兴趣飘移现象,即用户对某一类型的短视频的感兴趣程度会随着场景的改变或时间的推移发生变化。2)由于视频内容提供商服务的用户具有移动性的特点,MEC 服务器所覆盖范围内的用户数量是变化的,这会导致每种类型的短视频内容在不同时间段内被浏览的次数是变化的。因此,不能提前准确获知某一类型的短视频内容被某一MEC 服务器覆盖下所有用户的认可度。为解决这一问题,视频内容提供商需要不断了解用户的兴趣趋向以及不断学习用户对每一类型短视频的认可程度,从而得到一个最优的短视频内容分发策略,使自己获取尽可能多的利润。
4 内容分发策略
在本文中,基于联邦学习分析用户的相册数据,得到用户群的兴趣向量后再基于组合多臂老虎机(Combinatorial Multi-Armed Bandit,CMAB)理论解决第3章所提出的问题。
4.1 基于联邦学习构建用户群兴趣预测模型
4.1.1 模型选择
本节的目标是在移动端获得一个基于相册中图像数据的预测模型,利用该模型预测移动设备使用者的兴趣向量,深度学习可以有效解决这一问题。考虑到移动设备的计算资源有限,而MobileNet 模型[22]由于引入了深度可分离卷积技术,其在尽可能保证训练效果的基础上极大减小了模型参数的规模,因此选择适合移动设备端使用的MobileNet 模型作为本文的预测模型,图2展示了MobileNet的模型结构。

图2 MobileNet模型结构Fig.2 MobileNet model structure
4.1.2 使用联邦学习训练模型
虽然适合移动设备端使用的MobileNet 模型参数量被极大减少,但是训练此模型还是需要一定的计算资源,由于移动设备之间性能不一,对某些移动设备来说单独训练好此模型需要较长的时间。另外如果每个移动设备都单独训练一个完整的模型,这将会造成大量的资源浪费。
如果在MEC 服务器处训练此模型:一方面,参与训练的用户需要将本地的个人数据上传到MEC 服务器,这将会造成个人隐私数据的泄漏以及有可能违反相关法规。另一方面,将移动设备端大量的本地数据上传到MEC 服务器,这将会消耗大量的网络带宽,给无线网络带来沉重负担。
联邦学习作为一个机器学习框架,具有以下优点:1)各移动设备端的本地数据不需要集中上传到服务器,避免了泄漏隐私和违反相关法律的风险。2)联邦学习的建模效果和将所有移动设备端的本地数据集中在一起建模的效果大致相同。3)大量移动设备相互协作,联合训练一个共有的模型,避免了计算资源的浪费。因此,如算法1 所示,本文使用联邦学习的方式训练所需的深度学习模型。步骤1)~7)是MEC服务器和所有移动设备的初始化阶段;步骤9)~11)中MEC服务器随机选择一部分移动设备加入联邦学习的训练中,被选中的移动设备从MEC 服务器中下载MobileNet 模型的参数;步骤12)~19)中移动设备利用本地数据进行模型更新,被更新后的模型参数再被发送到MEC服务器执行模型聚合操作。
算法1 基于联邦学习的兴趣预测模型训练算法。
输入 每轮聚合前移动设备端的训练次数γ0;
输出 MobileNet的模型参数θt+1。

4.2 基于预测模型构建用户群的兴趣向量
在4.1 节的基于联邦学习的兴趣预测模型训练算法中,参与联邦学习的移动设备都会在本地得到一个训练好的MobileNet 模型,本文将利用该模型对移动设备相册中新加入的无标签数据进行预测,得到单个用户z对各类型短视频内容的兴趣向量Vz=进而得到该用户群对各类型短视频内容的兴趣向量表示V=[v1,v2,…,vJ],通过用户群的兴趣向量来指导内容分发系统的内容分发策略。算法2 给出了用户群兴趣向量预测算法,首先每个移动设备端根据算法1 得到的兴趣预测模型预测出单个移动设备的兴趣向量,然后移动设备将自己的兴趣向量上传至MEC 服务器,最后在MEC服务器端计算出该用户群的兴趣向量。
算法2 用户群兴趣向量预测算法。
输入 移动设备端ςz个无标签图像数据,可用设备的个数z′;
输出 用户群对各类视频内容的兴趣度向量V=[v1,v2,…,vJ]。


4.3 基于组合置信上界算法的短视频分发策略
与多臂老虎机(Multi-Armed Bandit,MAB)理论不同,在CMAB 理论中,赌徒进入赌场后,面对一排老虎机,他一次拉动的不是一个臂,而是多个臂组成的集合,将该集合称作超臂。在MAB 问题中,称其中的每个臂为基准臂。当赌徒拉动一个超臂以后,超臂所包含的每个基准臂会给赌徒一个反馈,而这个超臂整体也给赌徒带来某种复合的反馈。拉动超臂之前,赌徒不知道他将获得怎样的反馈。
在短视频分发问题中,视频内容提供商分发一部分短视频内容到MEC服务器之前,由于不知道MEC服务器所覆盖用户群对这一部分短视频的认可情况,所以不能提前获知这部分短视频所能带来的利润。为了更精确地了解用户群的兴趣方向,使缓存在MEC 服务器中的短视频更容易被该用户群认可,从而使视频内容提供商获得更高的利润,结合该用户群的兴趣向量,基于UCB 的动作选择方式[23],设计了短视频分发的FLCUCB算法,给出了接近最优的短视频缓存策略。
本文的目标是从所有的K短视频中选择最有可能被该用户群认可的总大小为C的短视频内容缓存在MEC 服务器上,从而使视频内容提供商尽可能获取更多的利润。用代表在时间t时类型为j的短视频内容缓存到MEC 服务器的总次数。本文提出的短视频缓存策略包括初始化阶段、探索阶段和利用阶段。在初始化阶段,缓存策略确保每种类型的短视频内容至少有一个被缓存在MEC 服务器上。视频内容提供商根据该MEC 服务器的获利反馈进行以下的利用和探索阶段。缓存策略将会计算在以往的时间t中每种类型的短视频在该MEC 服务器所覆盖用户群中的平均获利。为了能在所有的K个短视频中选择总大小为C的一部分短视频使视频内容提供商获取尽可能多的利润,定义了短视频分发价值公式:

其中,μ是一个大于0 的数,它控制试探缓存新的类型的短视频的程度。表示在以往的时间1到t-1中,类型为j的短视频内容在该用户群中获得的平均利润,定义为:


其中,k′表示类型为j的短视频的个数。由式(6)可知,如果某种类型j∈Jagg的短视频内容被缓存在MEC 服务器上的次数相对较小或者该类型的短视频内容在以往的时间1到t-1中获取的平均利润越大、用户群对该类型的短视频内容的兴趣度越高,某个属于类型j的短视频内容k的缓存价值就相对较大,该短视频就会被缓存在MEC 服务器。由此可见,该分发策略在倾向分发已知的能使视频内容提供商获取更多利润的某些类型短视频的同时,还会探索缓存其他类型的短视频内容。因此,该策略能在MEC 服务器缓存总大小为C的最可能被用户群认可的短视频,从而获得更高的认可度使最大化。FLCUCB 算法如算法3 所示,步骤2)~11)是初始化阶段,根据用户群的兴趣向量将每种类型的短视频内容按照不同的比例分发到MEC 服务器中,然后计算每种类型的短视频所获得的平均利润。步骤13)~17)计算每种类型短视频的缓存价值。步骤18)~29)将各类短视频按照缓存价值由高到低的顺序缓存在MEC 服务器上,缓存价值越高的类别被缓存的比例αj*也就越大。
算法3 FLCUCB算法。
输入 待缓存的短视频集合F=∅,V=[v1,v2,…,vJ],Kagg={1,2,…,k,…,K},由大到小排列的短视频缓存比例为[α1,…,,…,αJ];
输出 待缓存的短视频集合F。

5 实验与结果分析
在仿真实验中,基于Python 设计并实现了短视频分发模拟器。考虑系统中包括视频内容提供商、MEC 服务器和代表用户群的多个移动设备,MEC 服务器将它缓存中的短视频内容主动推送给它所覆盖的所有移动设备的场景。被推送到移动设备上的短视频内容获得的被认可度越高,视频内容提供商就能获得越高的利润。假设有分别属于20 个不同的类别5 000 个短视频内容,所有短视频内容的大小固定为κ=100 MB,MEC 服务器的存储空间C=40 GB,1个MEC 服务器向它所覆盖的1 000 台移动设备推送短视频。本文从视频内容提供商获得的总利润和每个迭代时间段t获得的平均利润两个方面进行分析,并将本文所提策略(FLCUCB)与最优算法、随机算法和UCB算法进行比较。
图3 给出了在用户群兴趣趋向不变的情况下四种分发策略在视频内容提供商获得的总利润方面的比较。从图3 中可以看出:1)在最优策略中,因为假设已经知道每种类型的短视频将会获得的被认可度,所以该策略能使视频内容提供商获得最高的利润。2)在随机的缓存策略中,该策略随机地选择短视频内容并将其缓存到MEC服务器中,直到达到MEC服务器缓存的容量上限。因为该策略没有考虑用户群的兴趣趋向和对每种类型的短视频区别缓存,所以在随机分发策略下,视频内容提供商获得的总利润最少。3)在传统的UCB 算法中,因为缓存阶段只选择一定比例的分发价值最高的一类短视频缓存到MEC 服务器中,然后随机地缓存其他类型的短视频内容,直到达到MEC 服务器缓存的容量上限。所以通过传统的UCB算法缓存短视频内容使视频内容提供商获得的总利润要比随机策略高,但比FLCUCB 算法获得的总利润少。4)FLCUCB算法根据每种被缓存在MEC服务器中的视频获得的平均利润和该类型的短视频被缓存的次数,在同一时间段内将多种类型的短视频内容按照不同比例缓存在MEC 服务器中,所以该策略优于传统的UCB策略和随机的缓存策略。
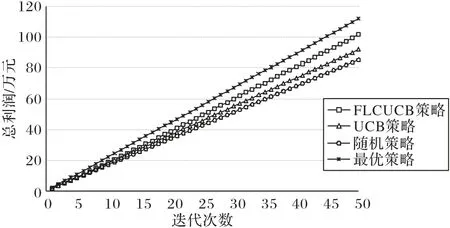
图3 不同分发策略获得的总利润Fig.3 Total profit brought by different distribution strategies
图4 给出了在用户群兴趣趋向不断变化的情况下,本文中所提短视频分发策略和CUCB 策略在视频内容提供商获得的平均利润方面的比较。
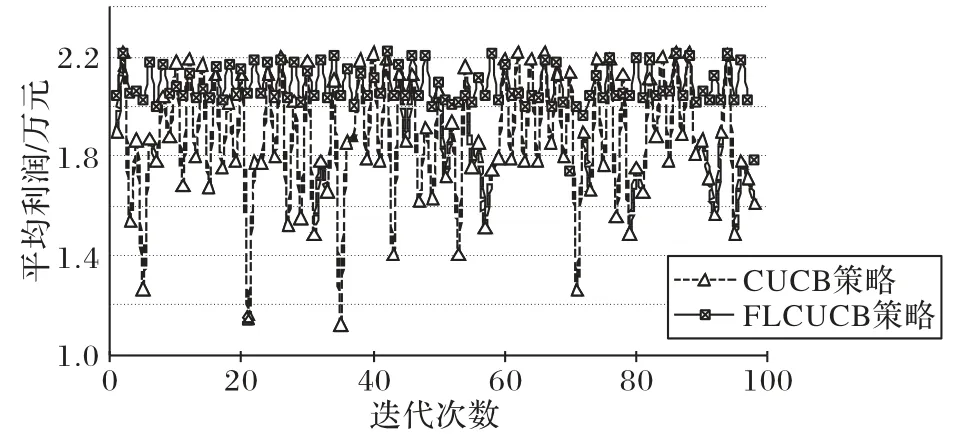
图4 有无联邦学习的平均利润比较Fig.4 Comparison of average profit with and without federated learning
从图4 中可以看出,加入联邦学习后,在大多数情况下视频内容提供商获得的平均利润要高于不加联邦学习的情况,这是因为加入联邦学习后,系统在执行CUCB 算法之前,可以通过由联邦学习训练得到的模型预测出该用户群的兴趣度向量,CUCB 算法结合预测到的用户群的兴趣度向量将短视频内容缓存到MEC 服务器上。通过对移动设备上相册内容的分析,使缓存在MEC 服务器上的短视频内容更加符合用户群的近期兴趣趋向,从而使视频内容提供商获得更高的平均利润。
6 结语
本文对基于边缘计算的短视频内容分发问题进行了研究,基于联邦学习和组合多臂老虎机理论设计了短视频分发策略,该策略可以根据不同用户群对不同类型短视频兴趣的不同,进行差异化的短视频内容分发,使缓存在MEC 服务器中的视频内容更容易被该区域中的用户认可,从而使视频内容提供商获取的利润最大化。仿真结果表明,本文所提策略获得的平均利润相对稳定且明显优于不加联邦学习的短视频分发策略;该策略使视频内容提供商在获取的总利润方面明显优于现有策略,能较好地适应基于主动推荐方式的短视频应用场景。
本文策略有效地卸载了回程链路的流量,然而在实际应用中,无线端仍然存在大量的流量冗余,其给蜂窝网络带来了沉重的负担。下一步研究工作的重点是,在短视频应用场景下,设计有效的策略,以卸载无线端的冗余流量。
