云工作流中基于多任务时序卷积网络的异常检测方法
2021-07-02程春玲
姚 杰,程春玲,韩 静,刘 峥*
(1.南京邮电大学计算机学院,南京 210023;2.中兴通讯股份有限公司上海研发中心,上海 201203)
(∗通信作者电子邮箱zliu@njupt.edu.cn)
0 引言
云计算平台使用分布式计算、虚拟化等技术整合了大量的计算设备及基础设施,并通过网络为用户提供计算、数据存储等资源和相关服务,因其高效、廉价和易维护等特点被广泛应用。随着云服务市场的快速发展,云计算系统的安全、可靠运行受到了日益严峻的挑战[1]。云计算系统中存储着大量的数据,其系统规模庞大、结构复杂,系统内通常包含多个组件,相较于一般的计算机软件系统更容易存在系统漏洞或遭受到攻击。因此异常检测[2]是维护云计算系统安全可靠运行的必不可少的步骤之一。
为了了解系统的运行过程,系统中有各种检测程序监测系统在运行过程中的状态,采集监测数据。在基于监测数据的异常检测[3]中,监测数据主要为系统运行过程中采集的性能数据。Nguyen 等[4]设计了一种在线异常定位系统,依靠采集的性能数据建立系统正常执行下的波动模型,并根据找出的异常数据定位异常组件。Wang 等[5]不同于使用阈值确定异常的方法,提出了用熵来计算性能数据的集中度和分散度,并使用数据分析方法区分正常熵和异常熵以检测系统异常。以上基于监测数据方法的不足之处在于监测数据的获取需要依靠相关数据采集程序,同时监测数据难以定位系统异常发生的位置。
基于日志的异常检测利用系统中普遍存在的日志数据,日志是进行系统异常检测的重要信息来源,相较于监测数据,日志数据更容易获取,而且也能够确定异常的位置。传统的基于日志的异常检测方法从系统日志中挖掘出系统正常运行时的特征以用于异常检测[6]。Xu等[7]通过日志解析从日志中提取出结构化信息,用定长的窗口划分日志序列,统计窗口内每个事件模板出现的次数作为一个特征向量,由此构造出特征矩阵,然后使用主成分分析(Principal Component Analysis,PCA)在数量上明显有异于其他集合的异常集合,最后通过统计检验确定异常的日志序列。随着数据的变化,该方法异常检测结果的准确性有很大的波动。基于监督学习的方法在数据处理上采用与PCA 相类似的方式提取特征矩阵,然后使用决策树[8]、支持向量机[9]等方法进行建模。He 等[10]详细比较了现有的各种使用传统机器学习的异常检测方法,这类方法在特定的云计算系统中能够取得较好的异常检测效果,但是缺乏对异常类型的判断。基于日志的事务流图方法构建系统正常执行流程下的事务流图,以用于检验系统的执行过程。Yu等[11]提出的ClouderSeer是一种专门为OpenStack 平台而设计的异常检测算法,它通过多个正常运行下生成的日志流为每一个OpenStack虚拟机构建一个自动状态机,刻画了每个任务的工作流,在在线检测阶段自动识别交错的日志,检测可能存在的异常。基于日志的事务流图[12]能够为异常分析提供强有力的支持,但是由于事务流图难以描绘出整个系统的详细流程,所以其在异常检测方面的准确度较差。
近年来随着深度学习的快速发展,各种深度学习模型被广泛运用于系统的异常检测[13]中,Du 等[14]提出的DeepLog 利用自然语言处理的方式处理日志流,将日志条目视为遵循某些特定模式和语法规则的序列元素,使用长短期记忆(Long Short-Term Memory,LSTM)网络[15]构建循环神经网络模型,从日志流中挖掘出事件序列和日志参数序列分别训练对应的LSTM 模型,用于检测系统异常。Brown 等[16]运用自然语言处理中的词袋模型对原始日志进行处理,将处理后的日志流序列作为模型的输入,并在LSTM 中加入了注意力机制,最后根据日志的异常得分来确定是否发生异常。Lu 等[17]构建了由embedding 层、三个一维卷积层、dropout 层和池化层组成的卷积神经网络用来检测输入的事件序列中是否发生了异常。王易东等[18]在N-gram 语言模型的基础上提出了一种基于门控循环单元网络(Gated Recurrent Unit,GRU)的日志异常检测模型,该模型对权重参数的各维度采用不同的学习速率进行更新[19]。任明等[20]提出了一种基于LSTM 的异常检测方法,利用TF-IDF 提取日志特征,将异常检测建模为二分类任务,该方法在Web 系统日志中取得了较好效果。杨瑞朋等[21]用PReLU(Parametric Rectified Linear Unit)激活函数替换时序卷积网络(Temporal Convolutional Network,TCN)中的ReLU 函数,针对全连接层易引起过拟合的问题,用自适应平均池化层替换全连接层。现有的基于深度学习的方法中普遍采用事件和日志参数各自训练相应的模型,而忽略了这些任务的关联关系。
系统中的路径异常和时延异常是较为常见的异常类型,路径异常由系统偏离正常执行路径造成,而请求或响应超时是造成系统时延异常的常见原因。综合上文中提到的问题,本文提出了一种基于多任务深度学习模型的异常检测框架。该框架选用日志数据,生成日志对应的事件模板及模型的训练和检测数据,从事件和时间这两个维度针对系统中存在的路径异常和时延异常进行检测。
本文的主要工作如下:实际的云平台系统中事件发生频繁,相邻事件的时间差过小,因此通过间隔采样的方式生成时延异常检测任务的数据,有效解决了短时延难以预测及检测的问题。此外根据事件预测任务和时延预测任务之间的关联性,提出了一种基于TCN 的多任务深度学习模型,并设计了异常检测逻辑。在实际日志数据中的检测结果表明,本文的异常检测框架取得了较高的异常检测准确度。
1 云计算工作流的异常
云计算工作流中的异常主要包括时延异常和路径异常。路径异常是系统中常见的异常类型之一,基于日志的路径异常检测主要依靠从日志流中挖掘的事件序列,路径异常在日志流中具体表现为某一位置处的事件模板偏离了正常的路径,可能出现的路径异常类型有跳过下一条关键日志和不遵循关键日志。例如,正常执行下得到路径为:事件1→事件2→事件3→事件4,如果某次执行产生的日志流对应的路径变为:事件1→事件2→事件5→事件4,则在事件5 的位置处可能发生了类型为不遵循关键日志的路径异常;如果对应的路径变为:事件1→事件2→事件4,则在事件4 的位置处可能发生了类型为跳过下一条关键日志的路径异常。
由于系统程序的执行是一种严格的流程,且系统的日志输出语句一般书写在程序的固定位置,所以两条日志间的输出时间间隔应该服从一定的分布,受计算机硬件以及网络环境等因素的影响,该时间间隔在一个固定的区间内波动。因此,系统的时延异常在日志流中具体表现为两条日志的输出时间间隔不在正常的范围内,例如“Deploying os_pkg_repo begins.”和“Deploy os_pkg_repo successfully.”这两个事件之间的时间间隔应该在一定的时间范围内,如果超出了这个范围,就可能存在时延异常。
本文提出了基于日志的异常检测框架,可以检测系统中存在的路径异常和时延异常,该异常检测框架包含以下三个步骤:
1)事件模板及序列生成:通过日志解析[22]将半结构化的日志解析为结构化的事件模板,提取出每一条日志对应的事件ID和时间戳,从而将日志流转化为事件序列和时间序列。
2)多任务学习模型:构建并训练基于时序卷积网络的多任务学习模型,多任务学习通过共享模型参数学习两个任务的共同特征。
3)日志异常检测:针对系统中存在的路径异常和时延异常设计相应的异常检测方法,利用多任务学习模型进行日志的异常检测。
2 事件模板及序列生成
2.1 事件模板生成
日志解析是在进行异常检测之前必不可少的工作,因为系统产生的原始日志是半结构化的文本信息,由日志关键字和变量参数组成,其中变量参数记录着如时间戳、IP地址这类随着系统运行而变化的信息。日志解析从原始日志中提取日志关键字,将变量用占位符代替(比如可以用*代替的变量参数),例如如下的OpenStack原始日志:
2019-04-29 14:05:03.993 INFO sqlalchemy.orm.mapper.Mapper(Com_Server|com_servers)_configure_property(msb_info_v2,Column)req-115af119-b549-4b0b-9056-fbf97a5d6009.
经过日志解析后得到的事件模板如下:sqlalchemy orm mapper Mapper(Com_Server|com_servers)(*Column)<reqparam>。日志解析将半结构化的日志信息转化为结构化的事件模板,每个事件模板尽可能代表着一条日志打印语句。
云计算数据中心包含多个组件,首先生成每个组件的事件模板,本文采用的日志解析算法为基础签名生成(Basic Signature Generation,BSG)算法[23],BSG 通过分析日志消息的长度和关键词,从而实时解析出日志消息所属事件和对应的消息签名,能够在保证解析速度的情况下解决现有日志解析算法需要真实消息签名辅助调参工作的问题。日志解析后得到事件模板集合,每一个事件模板用一个事件ID 进行编号。由于BSG是一种流式解析算法,会造成解析质量的下降,解析算法会将本属于同一事件模板的日志,解析为不同类型的事件模板,影响了异常检测中对异常的判定,所以进一步用编辑距离计算事件模板Ei与其他的事件模板的相似度,然后对解析生成的事件模板采用层次聚类合并相似度较高的事件模板,生成新的事件模板,得到新的事件模板集合E={E1,E2,…,Em}。
2.2 序列生成
序列是由系统某次运行产生的原始日志条目中的参数或其对应的事件ID 组成的,通过滑动窗口划分序列数据以生成模型的训练和检测数据,用事件模板匹配原始日志条目得到原始日志对应的事件ID,系统一次运行对应的事件序列SE={e1,e2,…,ei,…,en},ei∈E。
系统一次运行对应的时间序列由日志条目中的时间戳组成。对于时间序列ST={t1,t2,…,tn},普遍采用的处理方式为取两个相邻事件的时间差,但是系统事件发生频繁,相邻事件间的时间差过小。如图1 所示为OpenStack 某次正常部署下时延的分布情况,当k=1,即取两个相邻事件的时间差时,多数时延小于0.001 s,不利于模型训练和预测以及时延异常的检测。因此本文采用间隔采样的方式生成新的时延序列,采样的间隔为k,取事件序列中事件ei发生时间与事件ei-k发生时间的时间间隔,当i-k<0 时,采用zero padding 生成时延序列ST'={0,0,…,ti-ti-k,…,tn-tn-k}。
如图1 所示,当采用间隔采样后,相较于相邻采样,当k=5 时,处于0~0.001 s 内的时延大幅减少,多数时延处于0.001~0.01 s 的区间内。进一步扩大间隔采样值,即k=10时,时延继续增大,位于0.01~0.04 s 区间的数量明显增多。可通过间隔采样的方式减小短时延对异常检测带来的影响。

图1 不同k值下时延分布Fig.1 Time delay distribution with different k values
k值的选取通过事件发生处时延集合的均值来确定,时间是与事件相关的,不同的事件流程可能导致不同的时延,假设每个事件Ei(i=1,2,…,m)在其发生位置处对应的时延集合符合正态分布,其均值和标准差分别为MEi和SEi。如图2 所示的序列生成过程中,展现了事件E5的时延集合生成。为了保证所有事件对应的时延处于一个较为合理的值,设定阈值tthreshold,当k的取值为某个固定值时,应满足如下条件:
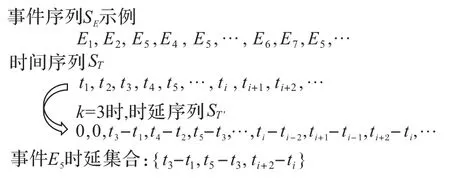
图2 序列生成示例Fig.2 Sequence generation example

本文取tthreshold=0.01,其k=30,最后使用长度为h的滑动窗口划分事件序列SE和时延序列ST'。
3 基于时序卷积网络的多任务学习模型
3.1 基于时序卷积网络的单任务学习模型
循环神经网络因其能够有效保留历史信息,一直是序列建模的首选,但是因为循环神经网络需依次计算每一步状态,所以不适合并行。时序卷积网络是Bai 等[24]在近年来使用卷积结构解决时序任务研究的基础上,提出的对时序任务有较好适用性的卷积网络结构。作为一种卷积结构的序列模型,TCN 结构更加简单清晰并且能够并行化,相较于LSTM 等循环神经网络结构,TCN可以通过堆叠卷积结构,捕捉到更加长远的依赖关系。
时序卷积网络的设计主要遵循以下两个原则:1)网络的输出与输入等长,卷积结构使用一维全卷积,使得隐藏层的输出与输入等长,采用zero padding 来保持层与层之间的长度相同;2)网络不会遗漏任何历史信息,卷积层采用因果卷积[24]。
TCN 使用了扩张卷积,扩张卷积可以有效地减小网络的深度并使模型具有长期记忆,此外,增大扩张系数或卷积核大小可以扩大感受野,感受野Rf=d*z。对于输入的一维序列:x∈Rn和卷积核f={0,1,…,z-1},序列中某个元素a扩张卷积运算F定义如下:

其中:d是扩张系数;z是卷积核大小。
随着输入历史序列长度的增加,TCN模型也在加深,为了避免TCN 模型出现梯度弥散,引入了残差连接。如图3 所示为残差块的结构,其中扩张系数d=1,卷积核大小z=2。输入长度为3的序列x=(x0,x1,x2),残差块的输出O如下:

图3 残差块结构Fig.3 Structure of residual block

其中F(x)为x经过的一系列计算。
本文将事件序列的路径预测任务建模为多分类问题,将时间序列上的时延预测任务建模为回归问题。对于输入的历史事件序列和时间序列,模型预测的是正常情况下的下一位置处应该发生的事件和时间,模型的训练数据为系统多次正常运行产生的日志数据。单任务学习模型基于TCN 分别训练路径异常检测和时延异常检测对应的模型。
单任务的路径预测任务中,给定窗口长度h,对于长度h的一维事件子序列we={er-h,…,er-2,er-1},采用常用的Word2Vec 方法,经过词嵌入后将每个事件映射为一个固定长度H的一维向量,词嵌入层输出维度为h×H的特征he。he为TCN 的输入,TCN 的输出通过一个激活函数为softmax 的全连接层后,输出每个事件Ei∈E(i=1,2,…,m)在下个位置r处发生的概率分布P(er|we)={E1:p1,E2:p2,…,En:pn}。损失函数为交叉熵函数L1:

其中:yi为事件Ei的标签;pi为事件Ei的概率。
单任务的时延预测任务中,TCN 的输入为长度h的时间子序列wt=TCN 的输出通过一个激活函数为linear 的全连接层后,输出下个位置r处的时延大小损失函数为均方误差函数L2:

3.2 多任务学习模型
本文从事件和时间两个维度检测系统异常,即路径异常和时延异常。利用3.1 节中提出的时序卷积网络,可以分别为路径异常和时延异常两个任务构建两个单独的学习模型,从而完成相应的异常检测。为路径异常或时延异常单独构建学习模型忽略了两种异常直接的关联关系,例如不同事件对于事件直接时延的影响,或是不同时延对于事件预测的判断,从而不能取得较好的异常检测效果。
多任务学习[25]通过学习任务之间的共有特征,提高了学习模型的表现。Long 等[26]先通过共享卷积层,然后在特定任务层中设定张量的正态先验,学习多个任务之间的关系。Misra等[27]在并行的两个任务之间设计了十字绣单元,通过正则化模型参数距离的相似度,来约束各个任务模型参数的相似度,从而控制任务之间的共享程度。
本文考虑到日志类型的事件ID 和日志发生时间的时间戳之间的相关性,提出利用多任务学习同时解决路径异常和时延异常的检测,设计了融合的多任务时序卷积网络,通过共享深度神经网络隐藏层的参数,不仅捕捉不同种类异常之间的关联关系,提升了异常的检测效果,还降低了模型的复杂度。更优的是,共享参数的多任务融合的时序卷积网络为不同种类的异常检测引入了噪声,提高了模型的泛化能力,进一步提高了异常的检测效果。
本文提出的多任务融合的时序卷积网络中包括两个异常检测的学习任务:路径预测任务和时延预测任务,模型在时序卷积网络的浅层部分共享路径预测任务和时延预测任务的隐藏层参数,再分叉成两个各自的特定任务层。基于TCN 的多任务学习示例模型如图4(a)所示,该多任务学习模型主要由输入层、时序卷积网络(包括共享层和特定任务层)和输出层组成。时序卷积网络的详细示例如图4(b)所示,由共享层和任务层组成,共享层中扩张系数d=1,2时残差块共享参数,任务层中扩张系数d=4,8,…时为两个任务各自的残差块。给定窗口长度h,多任务模型路径预测任务和时延预测任务的输入同单任务学习模型。在时序卷积网络层中,将事件序列经过词嵌入层后输出的特征he和时间序列wt进行特征联合(concatenate)后的特征X=(x0,x1,…,xn)输入共享层中,特征X的维度为h×(H+1),时序卷积网络的激活函数为ReLU 函数,定义共享层中有k1个残差块,hsi(i≤ki)为特征X经过共享层中第i个残差块的输出,式(6)表示共享层第一个残差块的输出hs1:
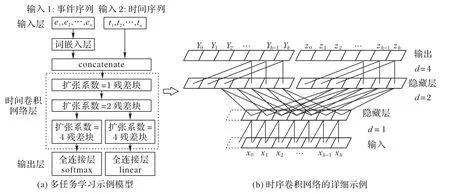
图4 基于TCN的多任务学习模型Fig.4 Multi-task learning model based on TCN
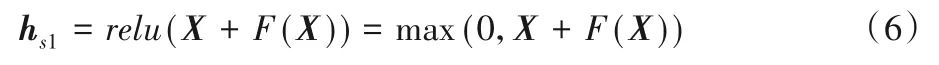

损失函数中的λ和1-λ分别为交叉熵损失函数和均方误差损失的权重。由于不同的任务之间的损失尺度不同,所以通过设置不同的权重来平衡各个任务的训练,以保证模型在所有的任务上都能取得较好的效果。
4 异常检测
4.1 路径异常检测
本文将路径预测任务建模为多分类任务,对于历史序列we={er-h,…,er-2,er-1}和实际发生的事件er,模型预测的是下一个位置r处每一个事件发生的概率,如果实际发生的事件er在模型预测的高概率事件中,则该位置处正常。本文的路径异常判断方法如下:设立概率阈值Pthreshold,如果er预测的概率大于该阈值,则正常;否则异常。
4.2 时延异常检测
将时延预测任务建模为回归任务,对于历史序列wt=和实际的时延,模型预测的是下一个位置r处的时延大小。本文认为事件和时间是相关的,不同的事件可能会导致不同的时间间隔。
具体示例如图5 所示,在利用模型进行事件预测时,输入固定长度的事件序列{A,B,C,D}和其对应的时延序列,假设为{0.1 s,0.2 s,0.3 s,0.4 s},模型预测的高概率事件可能有多个,比如事件E 和事件F 都有可能发生,事件E 发生时对应的时延大小为t1,事件F 发生时对应的时延大小为t2,而模型预测的值为单一的固定值t3,因此单一地依靠模型的预测值来判断时延异常是不准确的。

图5 模型的时延预测Fig.5 Time delay prediction of model
本文对于时延异常的检测主要分以下两步:1)将训练集中每个时间步的时延的实际值与模型的预测值的绝对误差拟合为高斯分布,可以得到正常情况下误差的均值M和标准差σ,输入长度为h的时间子序列wt=如果实际的时延大小与模型的预测值tpre在上述高斯分布的置信区间内,则是正常的;否则进行下一步。即:

2)判断实际的时延大小是否处于该时间步的事件er时延的高斯分布的置信区间内,即:

在本文的异常检测的流程中,时延异常检测依赖于路径异常检测,在路径检测正常后才进行时延异常检测,路径和时延只要有一个为异常,则认为当前位置发生了异常。
5 实验与结果分析
5.1 数据及配置
实验日志数据为OpenStack 云平台日志数据集:OpenStack 是一种基于PASS 的云计算平台,从OpenStack 收集的数据集包括虚拟机部署过程中cf-pdman 组件和pdm-cli 组件的生成日志,考虑到系统内的故障也有可能是跨组件或者跨服务的,单独对每个组件进行异常检测会遗漏这些异常。因此合并各个组件的日志文件,并按时间重新排序。数据集一共包括125 次部署,其中包括16 个虚拟机部署过程中的异常部署(包括缺失关键日志和跳过下一条日志等异常)。日志是由三台计算机用分布式的方式收集,这些部署的持续时间大约为3 d。每次部署的日志条目数量为747~109 493 不等,所有部署共包括771 125 条日志。日志解析后的事件模板经过层次聚类后共包含819 个事件。将正常部署的日志数据经过数据处理后提取出事件和时间序列,经过定长的滑动窗口划分打乱后,按6∶2∶2 的比例划分为训练集、验证集和检测集。本文将异常部署的日志数据也加入检测集以测试对于异常部署检测的效果。
如图6(a)所示为正常部署的日志数据中事件发生次数的分布,可以发现多数事件发生次数较低,少数事件以较高次数发生,这表明模型预测的发生概率较小的事件也有可能发生。如图6(b)所示为OpenStack 某次正常部署过程中事件发生的频次,每隔60 s统计发生的事件数,可以发现事件发生的频繁程度和程序运行的过程相关。
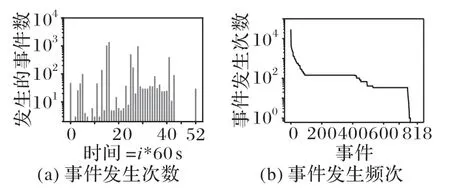
图6 正常部署中有关事件统计Fig.6 Statistics of related events in normal deployment
5.2 参数选择及评价指标
这里介绍本文的多任务TCN 模型和异常检测过程中一些较为重要的参数设置。在模型参数方面,模型的输入序列长度为40,设置损失函数中的参数λ=0.7,用以调节两个损失函数的尺度。受日志解析和较长日志参数的影响,尽管进行了层次聚类,还是有部分的事件模板是相似的。模型预测的高概率事件和实际发生的事件er不是同一个事件,但是两个事件对应的事件模板很相似,因此如果事件er不在预测的高概率事件中,则计算事件er和高概率事件的事件模板的相似度,并设立阈值Sthreshold,如果大于Sthreshold,认为这两个事件是一个事件,判断其为正常。模板相似度Sthreshold要保证模型在检测出异常的同时,避免将正常检测为异常,由于事件模板经过了层次聚类,所以模板相似度Sthreshold需要设置为较小的值,本文的实验中设置为0.6。
用于对比的方法如下:DeepLog 是基于LSTM 的日志异常检测模型,该模型利用从日志流中挖掘出事件序列和日志参数序列分别训练对应的LSTM 模型,预测发生在系统中的路径异常和参数异常;PCA 统计定长的窗口内每个事件模板出现的次数作为一个特征向量,由此构造出特征矩阵,使用PCA分析在数量上有异于其他集合的异常集合,通过统计检验确定异常的日志序列。本文以DeepLog为基线方法进行比较。
本文所采用的评价指标主要有如下几种:
1)准确率(Accuracy)表示被正确检测出的样本占总样本的比例,计算式为:

2)精度(Precision,P)表示实际为异常的样本占检测出异常的样本的比例,计算式为:

3)召回率(Recall,R)表示正确检测出异常的样本占异常样本的比例,计算式为:
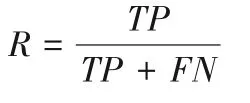
4)F1 值(F1_score)为精度和召回率的调和平均数,用于评价异常检测的整体性能:

其中:Ps为异常样本数;Ns为正常样本数;TP为被正确检测为异常的样本数;TN表示被正确检测为正常的样本数;FP表示被错误检测为异常的样本数;FN表示被错误检测为正常的样本数。
5.3 结果分析
如表1 所示为OpenStack 数据集中检测出的路径异常和时延异常示例,通过异常位置处实际输出的原始日志和模型的预测信息,可以大致分析出异常发生的原因。以pdm-cli组件中检测出的异常为例:表1 中的第一条路径异常示例可以结合模型预测的高概率事件模板,进一步分析得出其异常原因为相关部署初始化问题;在表1 中的第三条时延异常示例中,模型预测其时间间隔在正常情况下应为200 s 左右,而实际的时间间隔为260 s,结合实际输出的日志可以进一步发现导致时延异常的原因为http 请求失败。通过对比正常执行和异常位置处的相关信息可以进一步深入分析导致异常的原因。
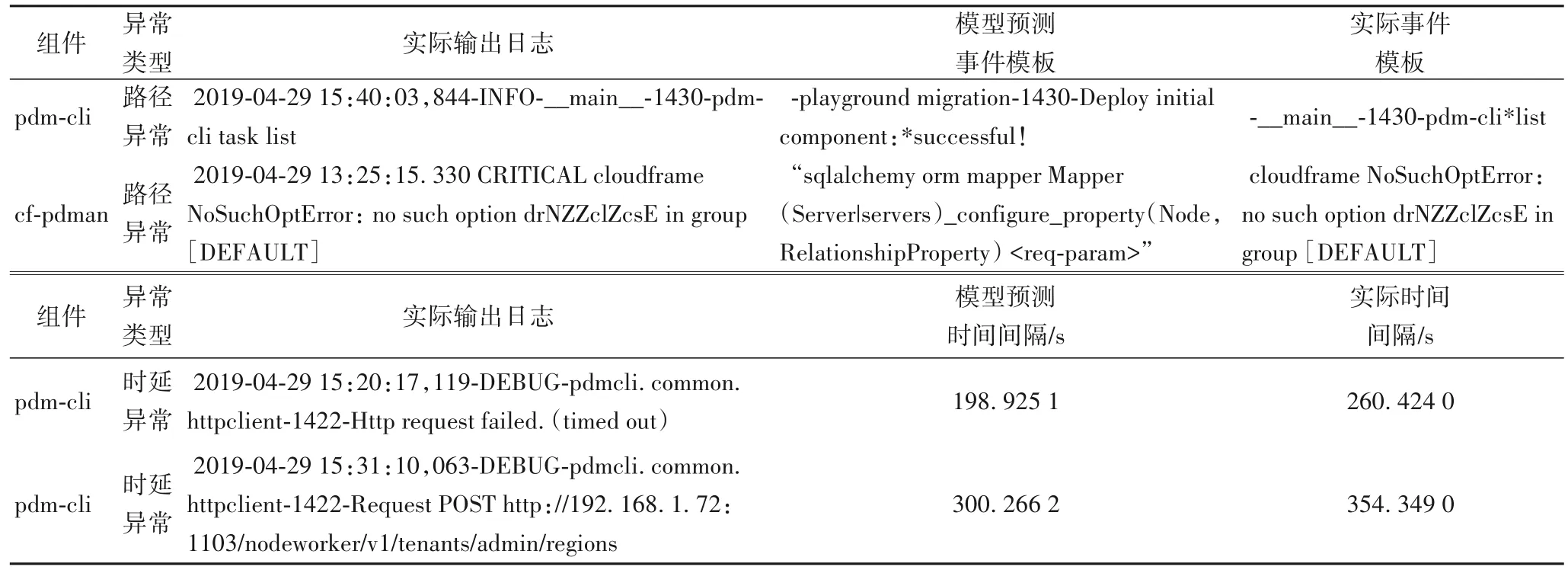
表1 OpenStack数据集中检测出的异常示例Tab.1 Examples of anomalies detected in OpenStack dataset
如表2 所示为PCA、DeepLog、单任务的TCN 模型和基于TCN 的多任务学习模型在OpenStack 数据集上的异常检测效果。从Recall 中可以发现,单任务的TCN 模型和基于TCN 的多任务学习模型都可以检测出所有的异常部署。从Precision可以看出,为了确保异常部署能够被检测出,基于深度学习的异常检测方法都不同程度地将正常部署划分为异常的,DeepLog 尤其容易将正常的部署误检为异常。PCA 虽然避免了这一情况的发生,但是其异常检测的效果较差。本文的基于TCN 的多任务学习模型取得了较好的异常检测效果,其异常检测准确率(Accuracy)相较其他对比模型至少提升了7.7个百分点。
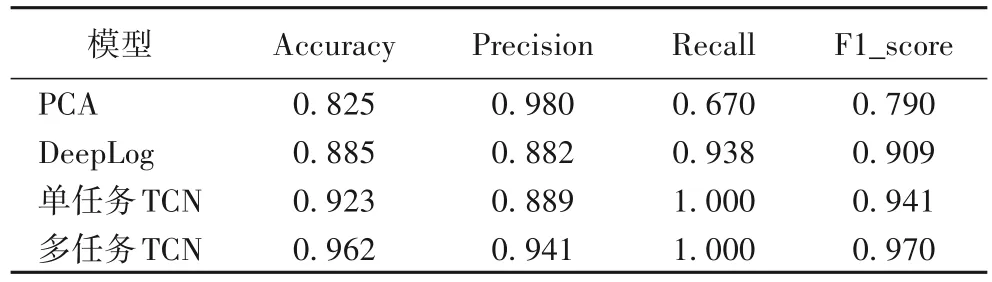
表2 OpenStack数据集上的异常检测效果Tab.2 Anomaly detection effects on OpenStack dataset
为了评价多任务TCN 模型相较于单任务TCN 模型的优势,下面将比较基于TCN 的多任务学习模型和单任务学习模型在路径异常检测和时间预测任务上的效果。如表3 所示为路径异常检测中不同概率阈值Pthreshold对于两种模型异常检测准确率的影响。在系统正常运行过程中,有部分事件发生次数很少,这在模型预测中表现为相关事件的概率较小,因此在路径异常的检测中概率阈值的设置尤为重要,较大的概率阈值会导致正常的部署被误判成异常,当Pthreshold=10-6时,异常检测的准确率最高,多任务TCN 模型的准确率高于单任务TCN模型,因此本文的路径异常检测中Pthreshold设置为10-6。
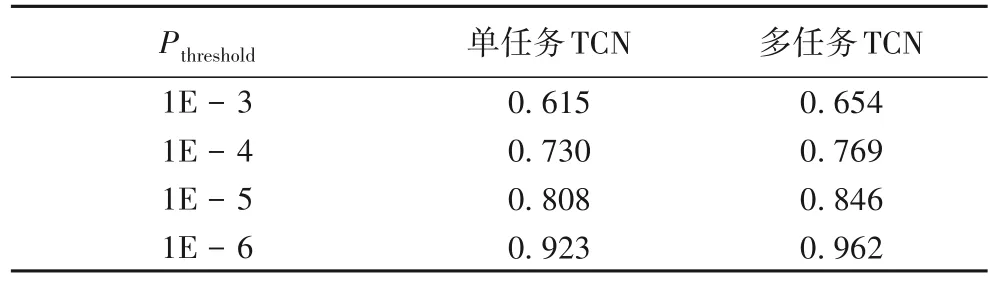
表3 概率阈值对异常检测准确率的影响Tab.3 Influence of probability threshold on anomaly detection accuracy
为了对比单任务TCN 模型和多任务TCN 模型在路径预测任务上的准确性,对于某种类型的事件Ei,统计并计算下个位置处实际发生事件为Ei时两种模型预测事件Ei发生的概率的均值。如图7所示为多任务TCN 模型和单任务TCN 模型在正常的测试样本中对于每个事件预测概率均值的对比。从图7 中可以发现,较多事件的多任务TCN 模型的预测概率均值大于单任务TCN 模型的预测概率均值,检测的正常样本中共包含752 个事件,其中533 个事件的多任务TCN 模型的预测概率均值大于单任务TCN 模型的预测概率均值。多任务模型在预测下个位置处发生的事件时,正常的事件有更高的概率,多任务学习模型预测更为准确。
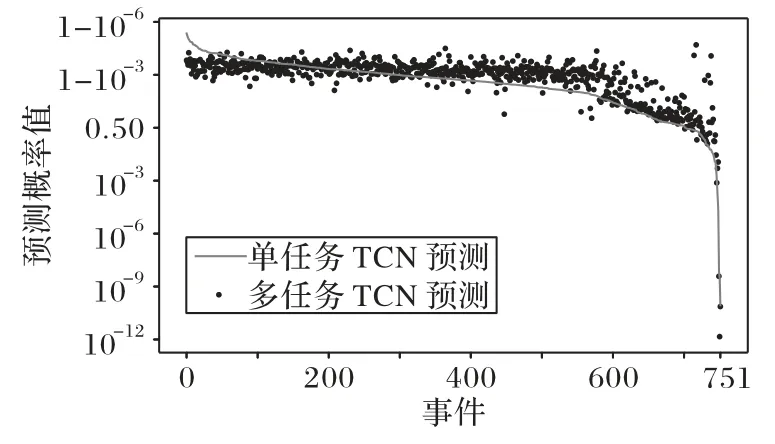
图7 事件预测概率值对比Fig.7 Comparison of event prediction probability
图8为多任务TCN 模型和单任务TCN 模型在时延预测任务上的对比,数据为检测集中的正常样本,计算了每个事件模板发生位置处对应时延预测值和实际值的平均误差。
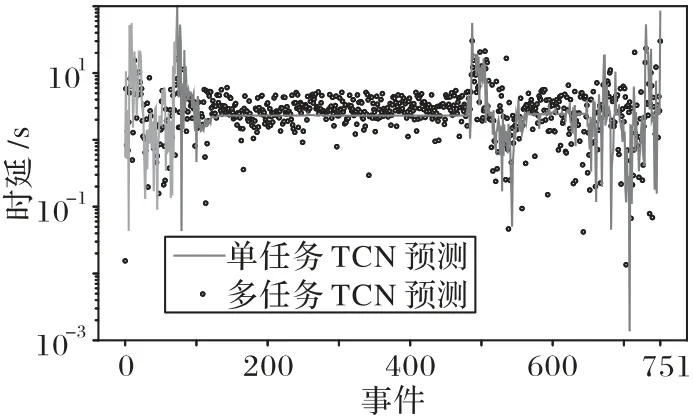
图8 时延预测误差对比Fig.8 Comparison of time delay prediction error
从图8 中可以看出,单任务TCN 模型在较小的时延数值预测中要优于多任务TCN 模型,但是整体上多任务TCN 模型的时延平均误差区间比单任务模型更小,总体上多任务模型的时延预测效果要优于单任务模型。
6 结语
针对云计算工作流中存在的路径异常和时延异常,本文提出了一种基于日志的异常检测方法。该方法将路径异常检测建模为多分类任务,将时延异常检测建模为回归任务,构建并训练了一种基于时序卷积网络(TCN)的多任务学习模型用于日志的异常检测,通过事件模板生成从日志流中提取事件序列,通过间隔采样的方法从日志流中提取时间序列。基于TCN 的多任务学习模型通过共享TCN 的浅层部分,促进各自任务的学习。实验结果表明该方法在异常检测方面取得了较好的效果。
接下来进一步的工作如下:首先,所提模型中损失函数参数权重的优化较困难,下一步工作需要设计相关方法以代替设置损失函数权重。其次,本文时延异常检测方法对数值较小的时延并不敏感,如何避免将正常划分为异常以提高异常检测的精度,仍是未来需要进一步解决的问题。
