优化LeNet-5网络的多角度头部姿态估计方法
2021-07-02张娜娜
章 惠,张娜娜,黄 俊
(1.上海海洋大学信息学院,上海 201306;2.上海建桥学院信息技术学院,上海 201306)
(∗通信作者电子邮箱nanazhang2004@163.com)
0 引言
近几年,计算机视觉在人脸识别、人脸检测等方面的应用越来越广泛,逐渐头部姿态估计算法的研究应用成为了计算机视觉的热点话题之一。头部姿态估计指计算机系统对外部输入的图像文件或者视频文件进行解析和预测,从而确定用户的头部在三维空间中的位置和姿态参量。通常头部姿态的参量是指用户头部在三维空间中的旋转角度,分别为左右旋转产生的偏航角(Yaw)、平面内旋转产生的滚动角(Roll)和上下旋转产生的俯仰角(Pitch)[1]。头部姿态估计在疲劳状态检测、智慧教室、活体检测[2]等领域有着广泛的应用。
近年来,国外的麻省理工学院人工智能实验室、国内的浙江大学计算机学院等研究单位都在开展对头部姿态估计的算法研究。目前已经出现了多种头部姿态估计算法,如基于多阵列器分类、基于非线性回归、基于三维图像等方法[3-4],根据是否需要定位用户的面部关键特征点,可以大致分为基于人脸外观和基于模型的两种方法[5]。基于模型的头部姿态估计方法主要是通过计算机系统检测并定位用户面部的关键特征点如唇部的唇峰和嘴角、眼周轮廓、鼻尖等,利用三维空间和二维图像之间的映射关系进行头部姿态分类。基于人脸外观的方法则相反,是通过模型训练确定输入的图像与已标记的图像的相似程度来进行头部姿态估计。
基于模型的方法中,Chun 等[6]对实验处理后获得的正向面部特征点进行跟踪,用模板匹配方法通过眼角和鼻子的位置估计头部姿态。闵秋莎等[7]结合了Adaboost 算法、椭圆肤色模型和Hough 圆检测法来获得人脸区域,通过面部特征点的空间位置实现头部姿态的判断;但是该方法的人脸检测率不高,当头部转动的幅度较大时,双眼易被遮挡,使得人眼定位的准确率下降或无法定位人眼。为了避免因无法定位面部特征点而使得头部姿态估计失效的问题,Ranjan 等[8]在卷积神经网络(Convolutional Neural Network,CNN)的基础上进行改进,提出了可以检测面部、用户性别和头部姿态的Hyper Face 网络,该方法在自然环境下可以有效地检测面部和判别用户的头部姿态,但是改进后的方法误差比较大。贺飞翔等[9]将检测到的人脸送入卷积神经网络进行表观建模。李成龙等[10]使用卡尔曼滤波估计深度图像中用户头部的位置,随机森林是利用多棵二叉树建立的分类器,基于上述两种方法结合的头部姿态估计方法可以很好地处理光照变化、遮挡情况下等问题。文献[9-10]方法用于训练和测试的数据集样本数较少,训练仅依赖于标准公开数据集,这使得网络结构的泛化能力较弱。Yang 等[11]提出了学习单个图像的细粒度结构聚集网络(Fine-Grained Structure Aggregation Net,FSA-Net)的头部姿态估计方法,该方法在年龄分类算法SSR-Net(Soft Stagewise Regression Network)的基础上优化了特征融合,对头部姿态角度分类,并将完成细粒度结构映射和记分功能的特征图聚合,形成新的特征图。
上述方法存在因面部特征点定位不准确、外界环境等影响因素造成的头部姿态估计偏差或失效,训练数据集较少,网络泛化能力较弱等问题。针对这些不足,本文提出了优化LeNet-5网络的多角度头部姿态估计方法,该方法是基于人脸外观方法的头部姿态估计方法。本文对传统神经网络的深度、卷积核大小、池化层等方面进行优化提高网络的提取特征能力,引入AdaBound优化器,自建头部姿态数据集,对常见的九类头部姿态进行训练分类。实验结果表明,所优化网络有较好的鲁棒性,运行速度也有所提高。
1 卷积神经网络
近年来,深度学习在自然语言处理、计算机视觉等方向展现了优秀的性能,各个研究机构和学者对其展开了研究学习。其中美国著名学者LeCun[12]提出的CNN已经成为深度学习中的代表算法之一。由于它的泛化能力优于传统人工设计的算法,CNN在语言识别、图像修复和物体识别等领域有了较为成熟的研究成果[13-15]。CNN 通常分为输入层、卷积层、采样层(或池化层)和全连接层,结构如图1所示。

图1 卷积神经网络结构Fig.1 Structure of CNN
1)卷积层。卷积层的作用是提取图像文件中的特征。卷积运算是指卷积核对感受野内的输入特征做矩阵元素的乘法运算,运算结果和偏置项相加,卷积层利用该运算方法完成特征提取。不同大小的卷积核产生的感受野大小也不同,较大的卷积核其产生的感受野较大,而较小的卷积核产生的感受野则较小。卷积运算的计算式为:

其中:i和j分别表示第i个输入特征图和第j个输出特征图;k表示卷积核的大小;b表示偏置项;l表示卷积层的层数位置;Mj表示感受野;f(•)则为激活函数。
2)池化层。池化层则是通过最大池化或平均值池化的方法将上层输出的特征图作为输入图像再次进行特征信息的过滤筛选,减少特征图中参数数量的同时保留了重要特征。
3)全连接层。此处的全连接层相当于传统的前馈神经网络中的隐藏层,它将池化后的特征图进行非线性的组合输出,通过激励函数完成学习目标。
目前,许多研究学者对CNN 进行改进,不断深化网络结构使其在分类、识别等复杂模型上的准确率和网络性能有所提高,例如GoogLeNet、AlexNet、VGGNet(Visual Geometry Group Net)、深度残差网络(deep Residual Network,ResNet)等网络。对于卷积神经网络而言,当神经网络的网络结构开始复杂化时,网络中学习的参数数和样本训练数增加,整体网络运行速度变慢;反之,较为简单的网络结构则会存在准确率不高的问题。因此,如何设计一个合理的卷积神经网络成为了研究中的一个重要问题。
2 优化LeNet-5网络
LeNet-5网络模型是最早出现的卷积神经网络之一,它的基本结构包括了2 层卷积层、2 层池化层和1 层全连接层,在卷积层和池化层中用不同的采样大小对输入图像进行特征提取。LeNet-5 网络在识别手写数字和识别文档这两类生活场景中应用广泛,同时这也成为了该网络模型在生活中最早的应用[12]。
为了解决因特征点定位失效而无法进行头部姿态估计的问题,同时提高网络的泛化能力,本文提出了改进LeNet-5 网络的头部姿态估计方法,在设计网络结构时从以下几方面考虑:
1)考虑网络的层数、深度。
原网络的层数较少,太浅的网络通常泛化能力不强,且对输入图像的特征提取能力不强,通过增加网络的深度可以提高网络的特征提取能力,但是网络深度太深容易造成过拟合的现象。因此,针对网络的泛化能力,网络深度的设计也十分重要。
2)考虑卷积核、激活函数对网络的影响。
卷积核的大小对训练过程中的全局特征和局部特征的学习有较大的影响。过大的卷积核会导致参与运算的参数数过多,增加计算量,难以训练;相反过小的卷积核不容易提取全局特征,影响训练结果,造成训练误差较大,准确率下降[16-17]。因此,针对网络的特征提取能力和性能,本文优化了卷积核的大小。
3)考虑网络的分类输出。
为了避免网络的过拟合、提高网络的收敛速度,改进了全连接层和输出层,以实现多分类的目的。
改进后的网络结构包含7 层卷积层Conv_1、Conv_2、Conv_3、Conv_4、Conv_5、Conv_6 和Conv_7,全连接层Full_1、Full_2和输出层Output。具体的网络结构如表1所示,网络结构示意图如图2所示。

图2 优化后网络的结构Fig.2 Structure of optimized network

表1 优化后网络的结构Tab.1 Structure of optimized network
2.1 卷积层设计
在优化网络结构时,卷积核的设计好坏决定了特征提取的优劣、网络泛化能力的强弱和收敛速度的快慢。改进后的神经网络用了3×3的卷积核代替原先网络中的5×5的卷积核。借鉴VGGNet16 的网络结构[18],使用卷积组可以减少参数量从而提高模型计算速度,同时又能保证感受野大小不变。利用连续的3×3 大小的卷积核运算后可以学习较大的全局特征,获取更多的图像细节特征。单个3×3的卷积核对头部转动的角度变化比较敏感,容易捕获局部的较为精细的特征信息。
激活函数选择用修正线性单元(Rectified Linear Unit,ReLU)激活函数代替原网络层中的Sigmod函数。该激活函数有单侧抑制作用,可减少模型训练的时间,加快模型的收敛,有效缓解过拟合问题[19]。ReLU函数的计算式为:

2.2 池化层设计
卷积网络中的池化层可以提高模型的计算速度、提取特征的鲁棒性和压缩模型大小,实现降维目的。本文使用卷积操作代替池化操作,采样步长增加为2,有利于提高模型的计算速度、优化模型的非线性能力。
2.3 全连接层和正则化设计
为了加快模型的收敛,选择了全连接层而不是全局平均池化层。相较传统的LeNet-5网络,将全连接层增加到2层。
Dropout正则化[20]是指神经网络在向前传播的时候,按照一定的概率让某部分神经元停止工作,即随机把(·)%的神经元的激活偏值为0,在权重更新计算时,不会对冻结的神经元进行计算操作,从而获得随机的网络结构。没有增加Dropout正则化时的全连接层计算式如下:

其中:i表示第i个输入特征图;l表示卷积层的层数位置;ω表示权值;x表示输入图像;b表示偏置;f(•)则为激活函数,激活函数选择ReLU函数。
增加了Dropout正则化后的全连接层计算式则为:

在全连接层增加Dropout可以避免过拟合现象的发生,提高神经网络的性能,减少对局部特征的依赖性,增强训练模型的泛化性。本文改进后的网络结构设置Dropout的值为0.3。
2.4 输出层和损失计算
输出层采用了非线性分类中的Softmax 回归模型[17]作为多分类器。Softmax 函数是在Logistic 函数的基础上推广衍生而来的,可以支持实现多分类,具体计算式为:

其中,yi表示第j个输出特征图,网络用Softmax 函数对输入图片的角度分类。
回归模型算法的评价指标常用的有均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean Squared Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)和交叉熵(Cross Entropy,CE)。均方误差、均方根误差和平均绝对误差计算相似,是通过方差来反映正确值与预测值之间的差异程度。交叉熵是指通过概率分布(预测值)来计算表示概率分布(正确值)的困难程度,交叉熵的值越小则表示两个概率的分布越近。MSE、RMSE、MAE、CE计算式分别为:
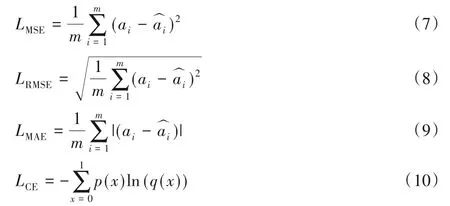
其中:ai表示期望输出值即正确值表示实际输出值即预测值;m表示采样数量;x表示输入数据,p(x)表示物体分类真实值,q(x)表示概率分布值。因为one-hot 的label 特殊性,交叉熵损失函数Loss又可以进一步简化为:

相较于另外三种误差评价法,交叉熵损失函数曲线呈单调性,损失值越大,梯度越大,有助于梯度下降反向传播和模型优化。
3 实验与结果分析
3.1 数据集
本文的实验数据集分为公共数据集和自建数据集,其中公共数据集为Pointing04 数据集和CAS-PEAL-R1 数据集。CAS-PEAL-R1数据集包含每人21张头部姿态变化图像,共计21 840 张图片;Pointing04 数据集共有15 组图像,每组包括了同一人186 张头部姿态变化的图像。公共数据集部分示例如图3所示。

图3 部分公共数据集图片Fig.3 Some public dataset images
为了解决公共数据集的训练样本偏少、自然遮挡情况下训练样本不足、影响网络模型的泛化能力等问题,使用了图4所示的方法采集数据,增加训练和测试集,组成了自建数据集。自建数据集中添加了遮挡头发、做出夸张表情、佩戴眼镜等动作的数据,部分自建数据集示例如图5所示。

图4 自建数据集采集方法Fig.4 Collection method of self-built dataset

图5 部分自建数据集图片Fig.5 Some self-built dataset images
3.2 实验设置
3.2.1 样本设置
本实验主要研究用户头部姿态的九种分类情况,即向前正视、抬头仰视、低头俯视、左转侧视、右转侧视、左上仰视、左下俯视、右上仰视、右下俯视这九个方向。实验主要针对Yaw方向和Pitch 方向两个角度,由于自建数据集和公共数据集的头部姿态角度并不统一,且考虑到在实际生活中头部姿态的变化角度范围,本文对这九种姿态进行分类识别。具体头部姿态角度分类结果如表2所示。

表2 头部姿态角度分类Tab.2 Head pose angle classification
对数据集预处理,可以减少无关因素对模型训练的影响,达到增强数据提高模型准确率的目的。使用文献[21]中提到多任务卷积神经网络(Multi-Task Cascaded Convolutional Network,MTCNN)检测人脸感兴趣区域(Region Of Interest,ROI)并裁剪,将裁剪后的图片归一化为64×72,图像预处理后的结果如图5所示。
取CAS-PEAL-R1 数据集、Pointing04 数据集和自建数据集总量的96%作为测试集,共44 866 张,测试集共1 869 张,为数据集总量的4%,分布如表3所示。
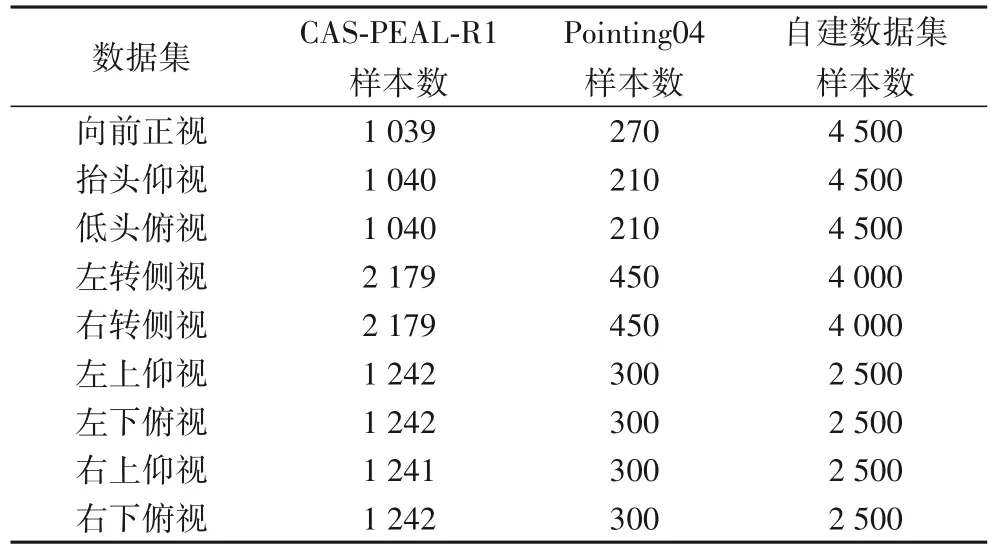
表3 数据集样本分布Tab.3 Distribution of dataset samples
3.2.2 环境和评价指标
本实验使用Python3.6 环境编程、Tensorflow-1.13.1、OpenCV-4.1.2,硬件环境为Intel i5-9300H、GTX 1660 TI,内存为8 GB。由于实验数据和参数较多,实验优化器选择了AdaBound 优化器[22]。训练迭代次数为10 000 次,批处理参数设置为100,学习率设置为0.001。在训练的前200 次迭代中AdaBound 优化器的精度有明显的提高,在训练后期,该优化器泛化能力较好,收敛较快。采用准确率作为实验的评价指标,计算式为:

其中:A表示准确率;Npre表示预测数;Nact表示样本数。
3.3 结果分析
在实验过程中,本文方法在测试集上的平均准确率达到98.7%,测试结果如图6 所示,自建数据集在左上仰视、左下俯视、右上仰视、右下俯视的数据集数量相较水平位置的数据数量较少,准确率较低。左上仰视的分类被错分的情况偏多,准确率为97.5%。将模型运用到摄像头实时头部姿态上,每秒可处理帧数达到22~29,满足实时系统要求。

图6 预处理后的图像Fig.6 Pre-processed images

图7 测试集分类准确率Fig.7 Test set classification accuracy
将本文方法与几种不同方法做对比,其中,包括基于模型的Adaboost+Hough[7]、局部二值特征(Local Binary Pattern,LBP)+BP(Back Propagation)方法[23];基于CNN 的热图定位(CNN+Heatmaps)方法[24]、深度卷积网络(Deep Convolutional Neural Network,DCNN)[5]、FSA-Net[11]等。Adaboost+Hough 方法通过定位人眼、鼻子的位置,将位置信息与正脸的头部姿态信息进行对比,达到头部姿态估计的目的。FSA-Net方法被提出优化SSR-Net。LBP+BP方法通过LBP和随机森林定位人脸68 个特征点,利用多层前馈BP 神经网络作为分类器,对头部姿态分类。CNN+Heatmaps 方法利用CNN 回归头部估计姿态,对输入的2D 热图图像定位面部5 个特征点进行定位。DCNN 方法,采用多变量标签分布作为分类器学习头部姿态。不同方法在公共数据集CAS-PEAL-R1 数据集和Pointing04 数据集上进行实验对比的结果如表4所示。
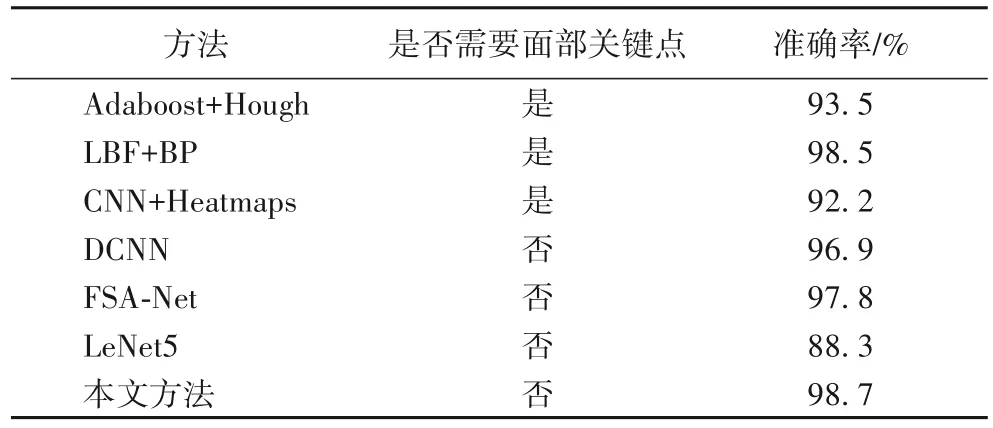
表4 不同方法的准确率对比Tab.4 Accuracy comparison of different methods
经过比较可以看出,Adaboost+Hough 方法、LBP+BP 方法方法和CNN+Heatmaps 方法依赖面部特征点,其中CNN+Heatmaps 方法对于面部除该5 个标志点外的学习能力较差,对自然环境下、大角度或大面积遮挡的头部姿态估计的准确性不高且容易失效。针对该问题,本文方法不需要定位面部关键点,泛化能力较好。FSA-Net方法不需要面部特征点的定位,对深度图像、实时视频图像的细节捕捉能力较好,且运行内存小,但是该方法对遮挡下的图像分类的准确率不高。改进的LeNet 方法同样不需要定位面部特征点,对水平前视、仰视、俯视、左转、右转识别的准确率较高,对于其他角度的识别容易分类错误。从对比结果看,本文方法的准确率略高于其他对比方法。经过实验验证,本文方法在戴眼镜、头发部分遮挡等情况下也能正确分类,具有较好的鲁棒性,通过实时摄像头运行验证,实时性约在每秒22~29帧,运行速度能够满足现实应用的要求。
4 结语
本文通过加深原网络,用多个卷积组来替代较大卷积核的卷积层,改进池化层,在全连接层中增加正则化等方式优化LeNet-5 网络。同时在网络中加入了AdaBound 优化器,该优化器对超参数的敏感度较低,可以极大地节约调参时间,并自建数据集,增强了网络的泛化能力。该头部姿态估计方法不依赖于人脸定位点的检测,有效地提高了计算机在外界环境因素下的头部姿态判断效果。在实时系统实验下,运行速度较好,在面部夸张表情、头发部分遮挡、戴眼镜等情况下表现出较好的鲁棒性,能简单高效地实现九分类头部姿态估计。由于训练数据集较为单一,向左方向的仰视和俯视、向右方向的仰视和俯视数据集较少,后续将对这些方向以及精细角度的头部姿态估计进行研究。
