基于多源数据的南方丘陵山地土地利用随机森林分类
2021-06-30李恒凯王利娟肖松松
李恒凯,王利娟,肖松松
基于多源数据的南方丘陵山地土地利用随机森林分类
李恒凯,王利娟,肖松松
(江西理工大学土木与测绘工程学院,赣州 341000)
针对南方丘陵山地因地形破碎和山体阴影而导致的分类精度低问题,该研究以东江源地区为例,通过结合多源数据,以Sentinel-1、Sentinel-2A卫星影像和DEM作为数据源提取27个指标,构建了6种特征变量集,并设计了9种方案,探讨加入红边特征、雷达特征和地形特征对南方丘陵山地土地利用分类信息提取的作用。同时结合随机森林算法和递归特征消除法进行特征变量优选和特征重要性排序,将随机森林特征优选后的分类结果与支持向量机算法(Support Vector Machine,SVM)和K近邻算法(K-Nearest Neighbor,KNN)作对比。结果表明:在未进行特征变量优选时,仅使用Sentinel-2A的光谱特征提取的东江源地表覆盖分类总体精度和Kappa系数最低,在以光谱特征、植被指数和水体指数作为基本方案时,加入红边特征、雷达特征和地形特征后均可以有效地提升各地物分类精度,其中地形特征的加入更有助于对东江源园地和耕地信息的提取。通过结合随机森林和递归特征消除算法进行特征优选,在保持分类精度最优的情况下将所有特征变量从21个降低到13个,并且总体精度达到0.937 2,Kappa系数达到0.923 4,分类精度优于相同特征下的支持向量机算法(SVM)和K近邻算法(KNN),对东江源土地利用信息提取效果最佳。该研究提出基于多源数据的随机森林方法可为地形复杂的南方丘陵山地土地利用信息提取提供技术支持和理论参考。
土地利用;分类;丘陵山地;随机森林;多源遥感数据;Sentinel-2A;Sentinel-1
0 引 言
土地利用/覆盖变化(Land-Use and Land-Cover Change,LULC)是全球环境变化的重要组成部分,在自然灾害和危害监测、城市和区域规划、土壤侵蚀和盐分估算、生态环境脆弱性和生态系统服务等领域发挥着重要的作用[1-3]。当前在大尺度的土地资源遥感研究应用中,主要使用的是Landsat TM/ETM+、SPOT和MODIS等中等空间分辨率遥感数据,然而受其传感器空间分辨率影响,在地形复杂区域的应用中仅依赖有限的光谱特征难以保证分类精度[4]。欧空局于2015年发射的Sentinel-2A卫星遥感数据因其光谱波段丰富、时空分辨率较高,为土地利用遥感分类提供了多维特征空间和新的数据源[5-6]。蔡文婷等[7]利用Sentinel-2A光谱和纹理信息对山东禹城冬小麦作物茬覆盖度估算发现Sentinel-2A与Landsat OLI相比具有较大优势。Antoine等[8]和Markus等[9]利用Sentinel-2A数据对城市不透水面和农作物进行变化监测和制图,发现Sentinel-2A红边波段对提高分类精度有重要作用。尽管目前光学遥感技术已经非常成熟,但是在南方多云多雨的丘陵山区,由于受云雾和地形的影响较大,在一定程度上影响了光学遥感对地物识别的精度。雷达影像不仅能全天时全天候的工作,而且能获取不同于光学影像的地物信息[10],通过结合光学和雷达数据可以增强对地物的识别能力和提高分类精度。相关学者通过结合Sentinel-2A和Sentinel-1成功应用在农耕区[11-12]、城市用地[13]和湿地[14]等地表信息提取并取得较好的分类效果。此外,Wang等[15]通过在地形复杂的祁连山通过引入地形因子并取得了 88.84%的分类精度,证明了地形因子对山区分类的重要性。
近年来,机器学习算法在土地利用分类研究中得到广泛应用,如最大似然法、支持向量机、随机森林等。其中随机森林方法因其分类精度高、处理多维数据变量能力强、训练和预测速度快的优点被广泛应用于土地利用分类研究中[16-17]。文献[18-20]使用随机森林算法对农耕区、湿地进行土地利用信息提取并取得较高的精度,为特定区域的土地利用信息提取提供了可行的方法。尽管现有全球10 m分辨率土地利用制图,然而该产品主要应用于全国尺度城市的土地利用遥感制图研究[21],在地形破碎、土地利用分散的南方丘陵山地的具体区域的应用分类效果上具有一定局限性,尤其是丘陵山地由于山体阴影和混合像元普遍存在,对地表信息精准提取造成较大干扰[22]。
上述研究表明,结合光谱、红边、雷达特征和地形特征使用随机森林方法可提高丘陵山地的土地利用分类精度,因此本研究以东江源地区为例,结合多源遥感数据Sentinel-1、Sentinel-2A和DEM,构建适合于南方丘陵山地土地利用分类的随机森林模型。同时经过特征优选和特征重要性排序筛选出最佳分类组合,最后通过与支持向量机算法(Support Vector Machine,SVM)和K近邻算法(K-Nearest Neighbor,KNN)分类结果进行对比,研究特征优选后的随机森林算法在南方丘陵山地的土地利用分类的适用性。
1 材料和方法
1.1 研究区概况与数据源
1.1.1 研究区概况
东江源位于江西省赣州市境内寻乌、安远和定南3个县,其东临福建省,南接广东省,地理坐标位于114°47′36″E~115°52′36″E、24°30′30″N~25°12′18″N,属于珠江流域东江水系,其水质及区域生态环境直接影响着粤港两地人民群众的饮用水安全[23]。东江源流域总面积约为3400km2,约占东江流域面积的 10%,海拔为161~1 498 m;属于亚热带季风湿润气候,平均年降水量在1 500~2 400 mm,西南多,东北少。东江源区地物分布复杂,地块小且破碎,林地农作物混杂度高,园地以脐橙、百香果种植为主,是典型的南方低山丘陵山地。研究区地理位置如图1所示。
1.1.2 数据来源与预处理
东江源位于多云多雨的南方丘陵山地地带,无云或少云量的数据一般较难获得,通过结合光学影像和微波雷达影像各自优点可以提高地物识别精度,因此本研究选用的是质量较好的2019年9月19日的Sentinel-2A L1C级别的多光谱数据和2019年9月17日的Sentinel-1的宽幅模式(IW)的地距(GRDH)产品数据(来自于欧空局网站(https://scihub.copernicus.eu/))。Sentinel-2A搭载的多光谱传感器可覆盖从可见光到短波红外的13个波段,其中包含10、20和60 m 3种空间分辨率。本研究采用的是空间分辨率为10和20 m的10个波段,相关波段参数如表1所示。由于Sentinel-2A L1C级数据已经进行几何校正和辐射校正,因此只需利用ESA提供的Sen2Cor插件和SNAP软件对L1C级数据进行大气校正和重采样,通过Sen2Cor插件将大气表观反射率(TOA)转化为L2A级别大气底层反射率数据(BOA),然后在SNAP中剔除60 m的分辨率波段数据并使用最近邻法将20 m波段数据重采样至10 m。

表1 Sentinel-2A 波段参数
针对Sentinel-1的宽幅模式(IW)的地距(GRDH)产品数据,空间分辨率为10 m,采用VV和VH双极化方式。本研究利用SNAP软件对该数据进行轨道校正、热噪声去除、辐射定标、滤波和地形校正,最后通过分贝化处理将雷达强度图像转化为VV和VH方向后向散射系数图。其他辅助数据为空间分辨率为30 m的SRTM DEM,使用最近邻法将其重采样至10 m用于地形因子的提取。
1.1.3 地表覆盖分类体系及样本点选取
参照国家土地利用分类标准《GB/T21010-2017》并结合研究区Sentinel 2A影像的光谱和纹理特征,将东江源土地利用类型分为:林地、园地、建设用地、水体、耕地和裸地。本研究通过东江源实地考察利用手持GPS获取部分土地利用类型的样本点,同时在ArcGIS使用采用分层随机采样方法对样本进行补充。为进一步保证样本点的精确性,结合Google Earth高分辨率影像剔除所选样本中异常点最终获得样本点391 9个,其中林地1039个、园地530个、建设用地546个、水体645个、耕地777个和裸地382个。
1.2 研究方法
1.2.1 技术路线
本研究通过对多源遥感数据Sentinel-1、Sentinel-2A和DEM进行预处理,然后构建东江源土地利用分类特征变量集和特征变量组合方案,最后分别进行随机森林分类。结合递归特征消除法和随机森林法进行特征优选和特征重要性排序从而筛选出最佳分类组合,同时与支持向量机算法(SVM)和K近邻算法(KNN)分类结果进行对比,评价特征优选后的随机森林算法在南方丘陵山地的土地利用分类的适用性,技术路线图如图2所示。
1.2.2 特征变量集的构建与实验方案的设计
Forkuor等[24-25]发现通过加入红边波段和雷达指数可以有效提升土地利用分类精度,因此本研究基于多源遥感数据:Sentinel-2A遥感影像数据、Sentinel-1雷达影像数据和DEM,通过提取的27个指标构建了6组东江源地表分类特征变量集,如表2所示。
本研究设计了9种方案(如表3所示),方案1仅使用Sentinel-2A原始影像光谱特征(红边波段B5、B6、B7除外),方案2使用传统遥感影像特征:光谱特征、无红边植被指数和水体指数。在方案2的基础上,方案3增加了红边特征变量,方案4增加了雷达特征变量,方案5增加了地形特征变量。方案6为所有特征变量。通过随机森林分类,探索使用随机森林算法在加入红边特征、雷达特征和地形特征后对东江源土地利用分类的影响。方案7-9使用RF、SVM、KNN 3种机器学习分类算法对特征优选组合进行分类对比验证。

表2 特征变量集
注:特征优选是通过递归特征消除法和随机森林法相结合的方法实现。0(db)为后向散射系数0分贝化。
Note: Feature optimization is realized by combining recursive feature elimination method and random forest method.0(db) represents the backscatter coefficient0in decibels.

表3 组合方案信息
1.2.3 特征变量优选
在分类过程中所有特征波段参与分类不仅会增加模型复杂度和导致信息冗余,还会造成“维数灾难”,从而导致分类性能下降,因此非常有必要对不同特征变量进行特征选择[26]。为了确定最佳分类个数和变量类型,本研究通过利用递归特征消除法和随机森林法相结合的方法来选取适合东江源的最佳分类特征组合。
递归特征消除法(Recursive Feature Elimination,RFE)是一种寻找最优特征子集的贪心算法,其核心思想是在保持分类性能不变的同时进行特征指数的降维,在分类时用于特征选择以取得比较理想的结果。该方法首先通过正则化回归剔除正则化系数为0的特征变量,在新的特征集基础上通过循环移除特征变量和反复建立模型对特征准确率进行评价,剔除得分最低的特征,直至遍历所有特征最后得出最有效的特征组合[27]。本研究通过采用scikit-learn的RFE模块来实现特征消除,并使用RFECV模块进行交叉验证对特征进行排序。

1.2.4 随机森林分类算法
随机森林(Random Frost,RF)算法是由Breiman等于2001年提出的一种非线性和非参数分类器,允许来自多源的高维数据的融合,对缺失值和异常值有较高忍耐性,适用于高维复杂数据集,并且能自动判断变量的重要性。它以决策树为基本单元,通过集成学习的思想将若干决策树集成在一起,利用多棵树对样本进行训练与预测,采用投票方式决定样本的分类结果[28]。
随机森林通过构造不同的样本训练集,扩大决策树各分类模型间的差异,从而提高组合分类模型的外推预测能力。在通过轮训练得到一个分类模型序列{1(),2()…h()},此时构成一个多分类模型系统,通过采用简单多数投票决策的方式得到最终分类结果,最终的分类决策为
式中()表示组合分类模型,h表示单个决策树分类模型,表示输出变量,(°)为示性函数。在构建随机森林分类算法的过程中需要设置决策树的个数(n_estimators)和保证模型达到最优时的最大特征数(max_feature)。本研究使用网格搜索交叉验证方法(GridSearchCV)进行参数寻优。通过大量实验发现当n_estimators设置为300时误差逐渐收敛并趋于稳定,此时最大特征数设置为总特征数的平方根。
1.2.5 精度评价
考虑到东江源区位于南方丘陵山地,地形破碎和像元噪点数据对分类精度产生影响,本研究使用117 5个验证样本点数据,利用混淆矩阵中的用户精度(User’s Accuracy, UA)、生产者精度(Producer’s Accuracy, PA)、总体精度(Overall Accuracy, OA)和Kappa系数来对分类器的性能进行评价。其中Kappa系数用来描述分类器的整体性能,用户精度(UA)和生产者精度(PA)可以评价某一类别的优劣。其具体公式如下所示:

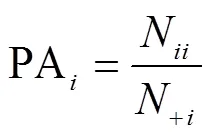

式中代表总样本数,为总类别数;N为被分到正确类别的样本数;+i和N+分别是第类的真实样本数和预测为第类的样本数。
2 结果与分析
2.1 特征变量优选
本研究通过结合随机森林法(RF)和递归特征消除法(RFE)对东江源27个特征波段进行特征变量的优选。首先采用Loss L1-正则化线性回归方法剔除6个特征权值为0的特征指数,得到二次“初始”的特征指数;其次基于测试数据集通过递归特征消除法绘制了最佳特征组合个数和总体精度、Kappa系数之间的关系(图3)。从特征筛选的过程曲线中可以发现,当特征变量为13时,随机森林分类的总体精度和Kappa系数值达到最大,随着特征数量的增加,分类精度趋于稳定,分类效果并不会持续改善。通过特征优选可以发现在保证分类精度最优的同时可以减少无关特征变量参与分类,提高了分类效率,因此本研究确定最佳特征个数为13。
根据随机森林算法的OOB袋外误差对提取的21个特征变量进行重要性排序并进行特征优选,选择前13个特征指数结果如图4所示,特征重要性由高到低依次为B12、RNDVI、RVI、B5、B8、B11、DEM、B6、NDWI、SLOPE、GNDVI、B2和B7。综合特征类别来看,特征变量的重要性贡献率排序如下:光谱特征>红边特征变量>植被指数>地形特征>水体指数。其中光谱特征变量和红边特征变量贡献率较高,分别为26.09%和23.55%;植被指数和地形特征次之,分别为11.62%和11.62%,水体指数特征贡献最小为5.57%。雷达特征变量虽对分类结果提高提供了一定的贡献率,但是在考虑保持分类精度和效率的同时,优选后的特征未包含雷达特征变量。其中Sentinel-2A的短波红外波段(B12)的重要性得分最高,达到0.090 1,对研究区土地利用分类覆盖贡献度最大,这是因为短波红外波段对叶片含水量反映敏感,能够很好地区分出植被[29]。而东江源林地和园地占地面积大,林地多为针叶林和阔叶林,植被覆盖度高,因此其重要性较高,这与实际情况相符合,同时与Antoine等[8]和Markus等[9]研究结果相一致。红边植被指数RNDVI的重要性得分次之,值为0.067 7,正是由于受到植物体内叶绿素吸收作用的影响,植被在红边波段存在陡峭的“反射肩”后,在东江源区域内使得红边波段更有利于植被和其他地物类型的区分。比值植被指数RVI能较好地反映植被的健康状况,重要性排名位于第三,重要性得分为0.065 5。
2.2 东江源土地利用分类精度评价
本研究采用总体精度、Kappa系数、生产者精度和用户精度作为东江源区土地利用分类结果的评价指标,提出的9种实验方案的分类结果如表4所示。在未进行特征变量优选时,仅使用Sentinel-2A的光谱特征提取的东江源地表覆盖分类总体精度和Kappa系数最低;方案2使用光谱特征、植被指数(无红边)和水体指数的总体精度为0.884 8,Kappa系数为0.858 8,与方案2相比较方案3、4和5总体精度分别提高了0.77、1.79和4.27百分点,Kappa系数则分别提高了0.94、2.18和5.2百分点,说明在加入红边特征、雷达特征和地形特征后可以有效地提升东江源区地表土地利用分类精度,其中加入地形特征后精度提升最高。方案6将所有特征变量组合在一起取得了0.936 9的总体精度,Kappa系数达到0.922 5,但是特征组合变量过多容易造成信息冗余和提高模型复杂度。在经过特征优选后方案7不仅取得了最好的分类效果,总体精度达到0.937 2,Kappa系数为0.923 4,还有效的将所有特征变量从21个降低到13个,提高了数据处理效率。
各个地物类型的生产者精度和用户精度(图5)可知,方案3在加入红边特征变量后,园地和耕地的用户精度有所下降,其他地物分类精度有所提高。这是因为在随机森林特征重要性排序中光谱特征对植被分类贡献大,加入红边特征后可能由于数据冗余降低分类器性能,造成园地和耕地分类精度下降,因此红边特征的加入有助于建设用地、裸地和林地的提取。
方案4加入雷达特征变量后,虽然总体分类精度提高,但是建设用地和裸地分类精度下降,这是因为雷达波段重在其具有穿透力,能够穿透冠层获取植物信息。对于光谱特征相似的园地和耕地,雷达后向散射系数是对光学波段反射率的有效补充,能提高类型间的差异程度;而建设用地和裸地因其光谱反射率差异相对较大,雷达后向散射系数的加入增加了信息冗余,从而降低了分类精度;雷达特征因其对水体比较敏感而提高了水体的分类精度。方案5在加入地形特征变量后,与方案2相比较耕地和园地的分类精度有了较大幅度的提升,耕地的生产者精度和用户精度分别提高了10%和16%,园地生产者精度和用户精度分别提高了13%和11%。这与东江源实际情况相符,由于东江源位于南方丘陵山地,园地主要以寻乌和安远县种植的蜜桔和脐橙为主,且大多位于海拔200 m以上的山坡上。耕地和园地混合分布、相互渗透并且在影像上是相似的,在光谱上“同物异谱”和“异物同谱”的现象严重,导致仅使用光谱特征变量、植被指数和水体指数很难将其进行有效的区分。因此在分类过程中存在将耕地误分为园地的现象,而地形特征变量中的高程、坡度和坡向特征变量能够有效减少园地和耕地的错分情况。

表4 各方案分类结果精度比较
2.3 不同分类方法精度比较
为评价构建适合于南方丘陵山地土地利用分类的随机森林模型的适用性,本研究将特征优选后的波段组合与遥感影像分类中常用的机器学习非参数分类方法支持向量机(SVM)和K近邻算法(KNN)的分类结果作对比分析[30]。分类精度结果如表5方案7、8和9所示,其中基于RF算法的分类精度最高,总体精度为0.937 2,Kappa系数为0.923 4,总体精度比SVM和KNN分别提高了5.75%和6.6%,Kappa系数比SVM和KNN分别提高了7.1%和8.15%。虽然不同分类方法对于单个地物类型分类精度存在差异,总体来说本研究提出的基于多源数据特征优选的随机森林算法能够有效的改善南方丘陵山地分类精度,不同方法分类结果如图6所示。
通过选择局部分类结果图7与谷歌地球高分影像对比可发现,在东江源土地利用分类中误差主要为园地和耕地的错分。通过RF优选特征分类后得到的结果耕地和园地生产者精度达到最高分别为0.90和0.82,用户精度达到0.84和0.93,大部分区域能够被正确识别,各地物能得到很好的区分,最终的分类结果边界清晰且基本没有破碎化现象,比较符合东江源实际情况,分类结果较好。而SVM和KNN分类结果图中耕地和园地错分现象比较多,通过图7可知基于RF分类的园地生产者精度和用户精度分别比SVM和KNN提高了11%、15%和11%、17%;耕地生产者精度和用户精度分别比SVM和KNN提高了13%、16%和13%、14%。虽然现有10m分辨率的全国土地利用产品,其5个一级类和12个二级类总体分类精度分别为61.2%和57.5%[21]。但其是以全国范围尺度为研究区域,故存在多样性、复杂性,影像的时相难以统一性的问题,研究区域越大其局部区域纹理细节越难兼顾[31];而通过特征优选的随机森林分类产品是针对东江源地区中小区域范围,相对较注重细节纹理,且总体精度达到0.937 2,Kappa系数达到0.923 4,更为符合东江源地表真实情况。
3 结 论
1)在加入红边特征、雷达特征和地形特征后可以有效地提升东江源区地表土地利用分类精度,相比光谱指数、植被指数和水体指数提取的东江源地表覆盖分类总体精度分别提高了0.77、1.79和4.27百分点,Kappa系数则分别提高了0.94、2.18和5.2百分点。
2)结合随机森林法(RF)和递归特征消除法(RFE)可以有效的选取对分类精度影响的有效特征变量,在保证分类精度最优的同时减少无关特征变量参与分类,将所有特征变量从21个降低到13个并且总体精度达到0.937 2,Kappa系数达到0.923 4。经过特征变量重要性排序得到在东江源光谱特征变量和红边特征变量贡献率较高,分别为26.09%和23.55%;植被指数和地形特征次之。其中波段B12、红边归一化植被指数(RNDVI)、比值植被指数(RVI)对模型的分类影响较大。
3)优选特征后的波段通过使用RF、支持向量机算法(SVM)和K近邻算法(KNN)3种机器学习分类算法进行分类可得RF算法的分类精度最高,总体精度为0.937 2比SVM和KNN分别提高了5.75%和6.6%;Kappa系数为0.923 4比SVM和KNN分别提高了7.1%和8.15%。
由于东江源区主要以林地和园地为主,其他地物类型较为破碎,尽管使用RF算法对南方丘陵山地土地利用分类信息提取精度较高,但当前分类类别较粗。下一步可以充分利用多源遥感数据的优势,将随机森林模型和面向对象方法结合,把纹理因素加进去对占主体的林地和园地做更细致的划分,对随机森林算法的普适性进行更深入的研究。
[1] 唐华俊,吴文斌,杨鹏,等.土地利用/土地覆被变化(LUCC)模型研究进展[J]. 地理学报,2009,64(4):456-468.
Tang Huajun, Wu Wenbin, Yang Peng, et al. Recent progresses of land use and land cover change (LUCC) models[J]. Acta Geographica Sinica, 2009, 64(4): 456-468. (in Chinese with English abstract)
[2] 翟天林,金贵,邓祥征,等. 基于多源遥感影像融合的武汉市土地利用分类方法研究[J]. 长江流域资源与环境,2016,25(10):1594-1602.
Zhai Tianlin, Jin Gui, Deng Xiangzheng, et al. Research of Wuhan City land use classification method based on multi-source remote sensing image fusion[J]. Resources and Environment in the Yangtze Basin, 2016, 25(10): 1594-1602. (in Chinese with English abstract)
[3] 张宇硕,吴殿廷,吕晓. 土地利用/覆盖变化对生态系统服务的影响:空间尺度视角的研究综述[J]. 自然资源学报,2020,35(5):1172-1189.
Zhang Yushuo, Wu Dianting, Lv Xiao. A review on the impact of land use/land cover change on ecosystem services from a spatial scale perspective[J]. Journal of Natural Resources, 2020, 35(5): 1172-1189. (in Chinese with English abstract)
[4] 张卫春,刘洪斌,武伟. 基于随机森林和Sentinel-2影像数据的低山丘陵区土地利用分类:以重庆市江津区李市镇为例[J]. 长江流域资源与环境,2019,28(6):1334-1343.
Zhang Weichun, Liu Hongbin, Wu Wei. Classification of land use in low mountain and hilly area based on random forest and Sentinel-2 satellite data: A case study of Lishi town, Jiangjin, Chongqing[J]. Resources and Environment in the Yangtze Basin, 2019, 28(6): 1334-1343. (in Chinese with English abstract)
[5] 何云,黄翀,李贺,等. 基于Sentinel-2A影像特征优选的随机森林土地覆盖分类[J]. 资源科学,2019,41(5):992-1001.
He Yun, Huang Chong, Li He, et al. Land-cover classification of random forest based on Sentinel-2A image feature optimization[J]. Resources Science, 2019, 41(5): 992-1001. (in Chinese with English abstract)
[6] Kollert A, Bremer M, Markus L, et al. Exploring the potential of land surface phenology and seasonal cloud free composites of one year of Sentinel-2 imagery for tree species mapping in a mountainous region[J]. International Journal of Applied Earth Observation and Geoinformation, 2021, 94. doi:10.1016/j.jag.2020.102208.
[7] 蔡文婷,赵书河,王亚梅,等. 结合Sentinel-2光谱与纹理信息的冬小麦作物茬覆盖度估算[J]. 遥感学报,2020,24(9):1108-1119.
Cai Wenting, Zhao Shuhe, Wang Yamei, et al. Estimation of winter wheat residue cover using spectral and textural information from Sentinel-2 data[J]. Journal of Remote Sensing, 2020, 24(9): 1108-1119. (in Chinese with English abstract)
[8] Antoine L, Christophe S, Thomas C, et al. Monitoring urban areas with Sentinel-2A data: Application to the update of the copernicus high resolution layer imperviousness degree[J]. Remote Sensing,2016, 8(7): 1-21.
[9] Markus I, Francesco V, Clement A. First experience with Sentinel-2 data for crop and tree species classifications in central Europe[J]. Remote Sensing,2016, 8(3): 166.
[10] Pierre D, Douglas J K, Dikaso U, et al. Mapping the dabus wetlands, ethiopia, using random forest classification of Landsat, PALSAR and topographic data[J]. Remote Sensing,2017, 9(10): 1056.
[11] 郭交,朱琳,靳标. 基于Sentinel-1和Sentinel-2数据融合的农作物分类[J]. 农业机械学报,2018,49(4):192-198.
Guo Jiao, Zhu Lin, Jin Biao. Crop classification based on data fusion of Sentinel-1 and Sentinel-2[J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(4): 192-198. (in Chinese with English abstract)
[12] van Tricht K, Gobin A, Gilliams S, et al. Synergistic use of radar Sentinel-1 and optical Sentinel-2 imagery for crop mapping: A case study for Belgium[J]. Remote Sensing, 2018, 10(10): 1642.
[13] Tavares P A, Beltrão N E S, Guimarães U S, et al. Integration of Sentinel-1 and Sentinel-2 for classification and LULC mapping in the urban area of belém, eastern brazilian amazon[J]. Sensors, 2019, 19(5): 1140.
[14] Slagter B, Tsendbazar N E, Vollrath A, et al. Mapping wetland characteristics using temporally dense Sentinel-1 and Sentinel-2 data: A case study in the St. Lucia wetlands, South Africa[J]. International Journal of Applied Earth Observations and Geoinformation, 2020, 86:102009.
[15] Wang H, Liu C L, Zang F, et al. Impacts of topography on the land cover classification in the Qilian Mountains, Northwest China[J]. Canadian Journal of Remote Sensing, 2020, 46(3): 344-359.
[16] Talukdar S, Singha P, Mahato S, et al. Land-use land-cover classification by machine learning classifiers for satellite observations: A review[J]. Remote Sensing, 2020, 12(7): 1135.
[17] Frank T, Stefanie S, Javier M, et al. Long-term land use/land cover change assessment of the Kilombero Catchment in Tanzania using random forest classification and robust change vector analysis[J]. Remote Sensing, 2020, 12(7): 1057.
[18] 马玥,姜琦刚,孟治国,等. 基于随机森林算法的农耕区土地利用分类研究[J]. 农业机械学报,2016,47(1):297-303.
Ma Yue, Jiang Qigang, Meng Zhiguo, et al. Classification of land use in farming area based on random forest algorithm[J]. Transactions of the Chinese Society for Agricultural Machinery, 2016, 47(1): 297-303. (in Chinese with English abstract)
[19] Abdi A M. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data[J]. GIScience & Remote Sensing, 2020, 57(1): 1-20.
[20] 常文涛,王浩,宁晓刚,等. 融合Sentinel-2红边波段和Sentinel-1雷达波段影像的扎龙湿地信息提取[J]. 湿地科学,2020,18(1):10-19.
Chang Wentao, Wang Hao, Ning Xiaogang, et al. Extraction of Zhalong wetlands information based on images of Sentinel-2 red-edge bands and Sentinel-1 radar bands[J]. Wetland Science, 2020, 18(1): 10-19. (in Chinese with English abstract)
[21] Gong P, Chen B, Li X C, et al. Mapping essential urban land use categories in China (EULUC-China): Preliminary results for 2018[J]. Science Bulletin, 2020, 65(3): 182-187.
[22] Yang Y K, Xiao P F, Feng X Z, et al. Accuracy assessment of seven global land cover datasets over China[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2017, 125: 156-173.
[23] 李恒凯,吴娇,王秀丽. 基于GF-1影像的东江流域面向对象土地利用分类[J]. 农业工程学报,2018,34(10):245-252.
Li Hengkai, Wu Jiao, Wang Xiuli. Object oriented land use classification of Dongjiang River Basin based on GF-1 image[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(10): 245-252. (in Chinese with English abstract)
[24] Forkuor G, Dimobe K, Serme I, et al. Landsat-8 vs. Sentinel-2: Examining the added value of sentinel-2’s red-edge bands to land-use and land-cover mapping in Burkina Faso[J]. GIScience & Remote Sensing, 2018, 55(3): 331-354.
[25] Hütt C, Waldhoff G, Bareth G. Fusion of Sentinel-1 with official topographic and cadastral geodata for crop-type enriched LULC mapping using FOSS and open data[J]. International Journal of Geo-Information, 2020, 9(2): 120.
[26] 王李娟,孔钰如,杨小冬,等. 基于特征优选随机森林算法的农耕区土地利用分类[J]. 农业工程学报,2020,36(4):244-250.
Wang Lijuan, Kong Yuru, Yang Xiaodong, et al. Classification of land use in farming areas based on feature optimization random forest algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(4): 244-250. (in Chinese with English abstract)
[27] 梁继,郑镇炜,夏诗婷,等. 高分六号红边特征的农作物识别与评估[J]. 遥感学报,2020,24(10):1168-1179.
Liang Ji, Zheng Zhenwei, Xia Shiting, et al. Crop recognition and evaluationusing red edge features of GF-6 satellite[J]. Journal of Remote Sensing, 2020, 24(10): 1168-1179. (in Chinese with English abstract)
[28] Breiman L. Random forest[J]. Machine Learning, 2001, 45(1): 5-32.
[29] Tucker C J. Remote sensing of leaf water content in the near infrared[J]. Remote Sensing of Environment, 1980, 10(1): 23-32.
[30] Li W, Michael H. Coastal wetland mapping using ensemble learning algorithms: A comparative study of bagging, boosting and stacking techniques[J].Remote Sensing, 2020, 12(10): 1683.
[31] 阮永俭,邱玉宝,李恒凯,等. 近26年赣州地区陆表环境遥感与变化分析[J]. 遥感信息,2016,31(6):110-120.
Ruan Yongjian, Qiu Yubao, Li Hengkai, et al. Land cover and ecological assessment of Ganzhou region in recent 26 years by remote sensing[J]. Remote Sensing lnformation, 2016, 31(6): 110-120. (in Chinese with English abstract)
Random forest classification of land use in hilly and mountaineous areas of southern China using multi-source remote sensing data
Li Hengkai, Wang Lijuan, Xiao Songsong
(341000)
Land use has been critical to global environmental change and structure adjustment, particularly to the sustainable development of land resources. However, there are complex terrains, broken distribution of ground objects, as well as the cloudy and rainy weather in hilly and mountainous areas of southern China. High-resolution optical remote sensing data is still lacking for the effective and accurate extraction of land use information. Therefore, the use of multi-source remote sensing data can achieve complementary advantages between remote sensing data and classification accuracy. The Sentinel series of remote sensing satellites launched by the European Space Agency (ESA) can provide new data sources for land-use change research. Multi-dimensional features can be adopted for the land use classification using the Sentinel-2A with red edge characteristics and Sentinel-1 with the nearly fog-free performance. Taking the reaches of Dongjiang River in Jiangxi Province of China as the study area, 9 schemes were designed in the Random Forest (RF) classification of land use to explore the effect of red edge, radar and terrain features on the extracting accuracy in hilly and mountainous areas of South China. In this study, the satellite images from the Sentinel-1, Sentinel-2 and digital elevation model (DEM) were combined to extract 27 feature indices, and then to construct 6 feature variable sets. The RF and Recursive Feature Elimination (RFE) were coupled to rank the importance of feature variables for the optimal one. The classification data from the RF feature selection was compared with the Support Vector Machine (SVM) and K-Nearest Neighbor (KNN). The results showed that the Sentinel-2A spectral features extraction presented the lowest overall accuracy and Kappa coefficient of land use classification in the study area, when the feature variables were not optimized. The addition of red edge, radar and topographic features effectively improved the classification accuracy, when the spectral features, vegetation and water indices were taken as basic schemes. Specifically, the overall accuracy increased by 0.77, 1.79, and 4.27 percentage points, respectively, while, the Kappa coefficient increased by 0.94, 2.18, and 5.2 percentage points, respectively. The topographic features more contributed to the extraction of orchard and cultivated land information in the study area. The RF and recursive feature elimination were combined to optimize all the feature variables from 21 to 13 with an overall accuracy of 0.937 2 and Kappa coefficient of 0.923 4, while maintaining the optimal classification accuracy. There were relatively significant contribution rates of spectral and red edge features variables, which were 26.09% and 23.55%, respectively. The vegetation and topographic indices were then followed in the importance of feature variables. The RF classification depended mainly on the short infrared band of B12, Relative Normalized Difference Vegetation Index (RNDVI) and Ratio Vegetation Index (RVI).The overall accuracy of RF was 0.937 2, 5.75% and 6.6% higher than that of SVM and KNN, respectively, whereas, Kappa coefficient was 0.923 4, 7.1% and 8.15% higher than SVM and KNN, respectively, indicating that the RF classification accuracy was superior to SVM and KNN with the same features. Therefore, the RF classification using the multi-source data can provide a promising technical support and theoretical reference for the extraction of land use in the hilly and mountainous regions of South China.
land use; classification; hilly mountain; random forest algorithm; multi-source remote sensing data; Sentinel-2A; Sentinel-1
2021-01-10
2021-03-13
教育部人文社会科学研究规划项目(18YJAZH040);江西省教育厅科学技术研究重点项目(GJJ180423);江西省高校人文社会科学研究项目(JC20119)
李恒凯,博士,副教授,主要研究方向为遥感建模与分析。Email:giskai@126.com
10.11975/j.issn.1002-6819.2021.07.030
P237
A
1002-6819(2021)-07-0244-08
李恒凯,王利娟,肖松松. 基于多源数据的南方丘陵山地土地利用随机森林分类[J]. 农业工程学报,2021,37(7):244-251. doi:10.11975/j.issn.1002-6819.2021.07.030 http://www.tcsae.org
Li Hengkai, Wang Lijuan, Xiao Songsong. Random forest classification of land use in hilly and mountaineous areas of southern China using multi-source remote sensing data[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(7): 244-251. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2021.07.030 http://www.tcsae.org
