基于向量升维的农情异常数据实时检测方法
2021-06-29江朝晖
赵 刚,饶 元,王 文,姜 敏,江朝晖
(安徽农业大学信息与计算机学院,合肥 230036)
农业物联网系统已成为农业大数据最重要的数据源之一[1]。通过将具有感知、通信和计算能力的微型传感器部署应用于农业生产管理中,全面、准确、高效地监测土壤-植物-大气连续体,能够有效推进“互联网+”现代农业行动,为精准农业的实现提供重要支撑[2-3]。农业物联网设备往往长期工作在复杂的生产环境中,受设备制造技术、工艺与成本以及网络传输的影响,数据收集过程中不可避免地产生远离序列一般水平的极大值或极小值,即异常数据[4-5]。如何实时有效地检测异常数据,保证采集的原始数据质量是开展高价值农业生产分析和实现物联网设备智能调控的根本前提。
Lo 等[6]提出一种基于分布式模型的非线性传感器异常诊断算法,具有较高的检测率,且开销低于集中式算法。Ludeña-Choez 等[7]提出基于非负矩阵分解的机器学习方法提取农业土壤墒情数据特征,再使用逻辑回归和支持向量机进行训练和检测,性能优于基于主成分分析和多尺度主成分分析的检测模型。通过建立回归模型来检测异常数据得到了研究者们的广泛关注。段青玲等[8]采用滑动窗口机制动态更新训练数据集构建基于支持向量回归的畜禽养殖物联网数据预测模型,通过比较预测数据和实际数据的差异判断是否出现异常。但该方法中预测模型与异常值判断区间的频繁更新造成计算开销较大,且异常数据的判断条件较为复杂。新兴的长短期记忆模型能够很好地捕获到数据在时间维度上的关联[9],但模型需要大量的训练数据集,实用性较差。
Zidi 等[10]将4 个传感器节点的短时段历史数据聚合成新观测向量,通过训练高斯核支持向量机SVM(support vector machine)进行异常数据检测,取得了较好的效果。Noshad 等[11]将2 个空气温度和2 个空气湿度传感器的3 次连续采样数据聚合成新观测向量,结果表明随机森林RF(random forest)模型的异常检测能力优于高斯核SVM。然而,以上方法尚存在不足:未对数据进行标准化处理,模型的异常数据检测效果对数据取值范围较为敏感;将多项数据聚合为新观测向量后,异常数据的准确定位存在困难;数据集发生变化时,随机森林RF 和高斯核SVM 均需重新调参、工作量较大。
受到成本、电源供给等因素制约,农情传感器大规模应用部署较为困难。实际农业生产中存在稀疏采样的需求,即选取少量代表性站点、较大采样间隔进行数据采集[12]。本研究以单传感器数据异常检测研究为切入点,提出基于数据向量升维的农情异常数据检测方法,探索数据预处理与升维方法、采样间隔对异常检测效果的影响,比较分析不同分类模型之间检测性能的差异,为实现农情数据的高质量感知提供参考。
1 材料与方法
1.1 数据来源
实验数据来自安徽省合肥市长丰县生态农场,自2018 年10 月起部署传感器节点不间断监测农场羊圈内环境信息,采样间隔为5 min。取2019 年6月10 日至30 日共21 d(504 h,6 048 数据点)时间段内空气相对湿度AirRH(air relative humidity)、CO2浓度、NH3浓度和H2S 浓度观测数据(图1)。受农场的生产习性与天气影响,农场养殖大棚内夜间的空气湿度、CO2浓度、NH3浓度以及H2S 浓度较高,而午间监测数据均会有不同程度的降低。为系统地评估提出方法的性能,以7 d 数据为步长,采用2 组连续14 d 数据进行实验,每组数据中前7 d数据作为训练集,后7 d 数据作为测试集进行异常数据检测模型的训练和性能验证。
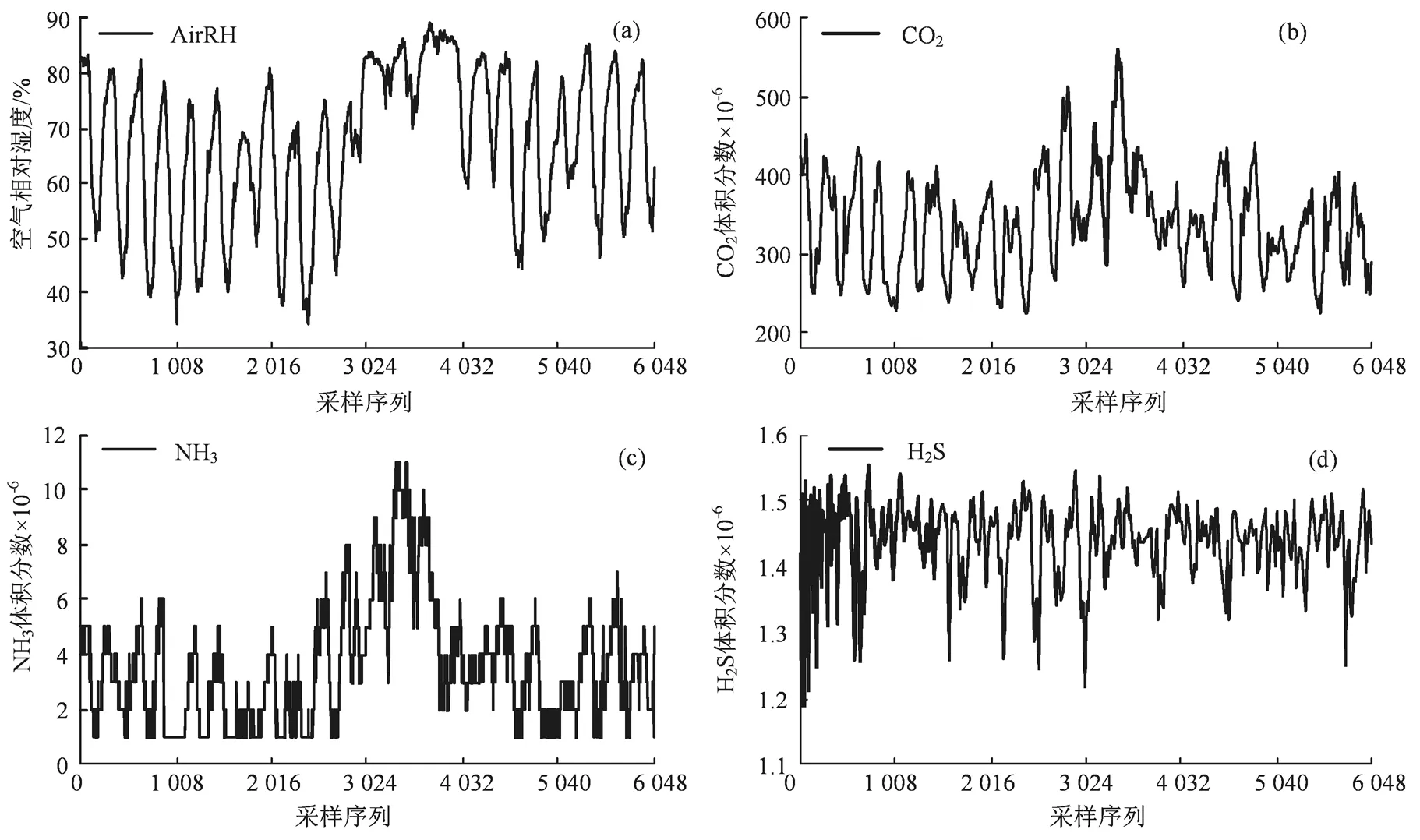
图1 实验数据Figure 1 Experimental data
1.2 向量构建与升维策略
设某传感器节点在某时刻共采集到L个时序数据D{x1,… ,xt,… ,xL}。若以大小为N、步长为1 的滑动窗口对数据集进行转换,可得L-N+1组观测向量。N若取2,则观测向量集为{(x1,x2),…,(xt,xt+1),…,(xL-1,xL)}。如图2 所示,该观测向量在二维空间中线性不可分,采用高斯核支持向量机则可得到数据在高维空间下的分割超平面,红线内外分别为正常值和异常值。然而,该模型泛化能力较差,会将后期采集到值为200 的正常数据判断为异常值(图2中标为New Point 点)。

图2 高斯核SVM 的异常数据检测效果Figure 2 Gaussian Kernel-based outlier detection


图3 基于向量升维的异常数据检测Figure 3 Vector-dimension-increase-based outlier detection
训练向量集构建与升维步骤如下:
首先,将各传感器采样的数据集通过线性标准化处理映射到同一区间。

异常数据实时检测向量的构建与升维步骤为:对接收到的数据与历史最近的N-1个数据点,采用训练数据集的最大值和最小值按式(1)进行标准化处理,消除实时数据流最大、最小值抖动造成异常检测结果的不稳定。然后将标准化后的数据转换为观测向量并升维:
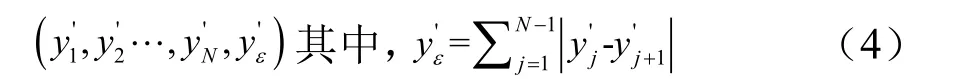
1.3 基于向量升维的异常数据检测框架
基于向量升维的异常数据实时检测框架如图4所示。传感器节点负责数据采样并发往服务器。服务器端负责数据接收、执行模型训练与异常检测。模型训练流程如下:取前一周采集数据,按设定比例和偏离幅度向数据集中随机插入异常数据,构建训练向量集并升维,最后训练分类模型以得到异常数据检测模型。下一周数据采集时,应用该模型进行异常数据实时检测。本研究采用的分类模型有线性核、高斯核支持向量机 SVM 以及随机森林RF[13-15]。下文若未特别说明,默认采用线性核SVM。
在异常数据实时检测过程中,服务器端对来自传感器节点的最新数据与历史最近N-1个数据进行标准化,构建实时检测向量并进行升维,最后传入模型中检测异常。如果被判断为正常数据则保存该最新数据,否则进行异常值校正后再保存。当数据采集时长满一周后重新训练模型。异常值校正方法可采用回归模型预测、均值替换法等方法[16]。
1.4 检测性能评价标准
本研究采用精确度(precision)、召回率(recall)和F1-Score 等指标评估模型的异常检测能力[17-18],公式分别为:

其中,TP是正确分类为异常数据的个数,TN是正确分类为正常数据的个数,FP是错误分类为异常数据的个数,FN是错误分类为正常数据的个数。
精确度、召回率分别是正确分类为异常数据的个数与所有分类为异常数据、实际异常数据个数的比值。除异常数据检测能力外,检测所需的计算耗时也是模型能否满足实际应用需求的重要因素[19]。
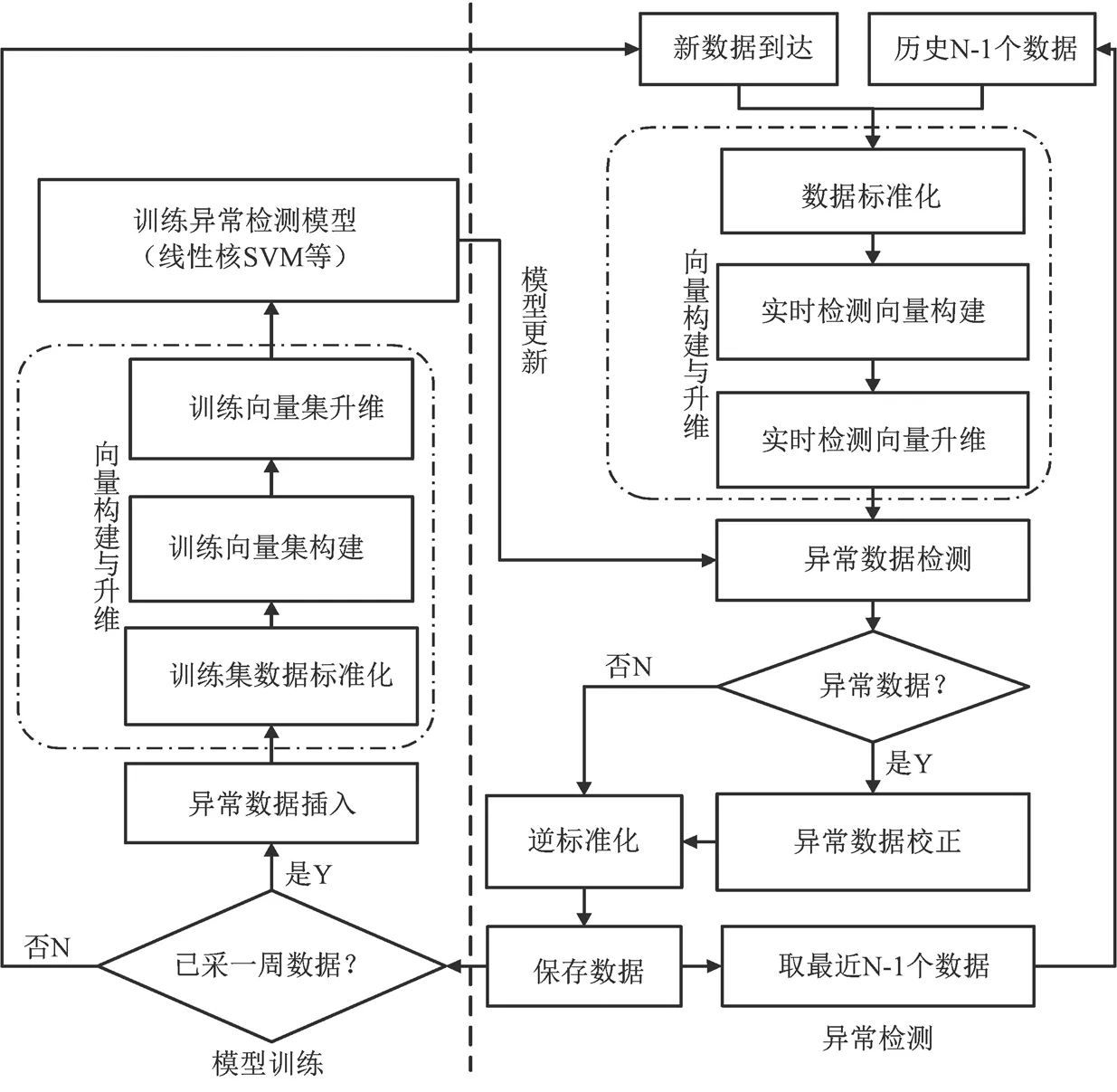
图4 基于向量升维的异常数据实时检测框架Figure 4 Framework of real-time outlier detection based on vector dimension increase
2 结果与分析
实验采用Python 语言编程,系统配置为Intel Core i5、8GB RAM 和Windows 10 操作系统。主要研究不同窗口大小、常规和稀疏采样场景下不同异常值比例和偏离幅度对模型检测效果的影响,以甄选出最佳窗口大小、分析模型对不同数据集的异常检测敏感度。在此基础上,对比分析不同分类模型的性能。为模拟不同的异常值偏离幅度,按照式(8)分别向训练和测试数据集中添加异常数据:

其中,'tx和tx为某项监测数据的训练集/测试集同一数据点修改前后的值,xmaxtrain、xmintrain为该项监测数据训练集中的最大值和最小值,η为异常值偏离幅度。
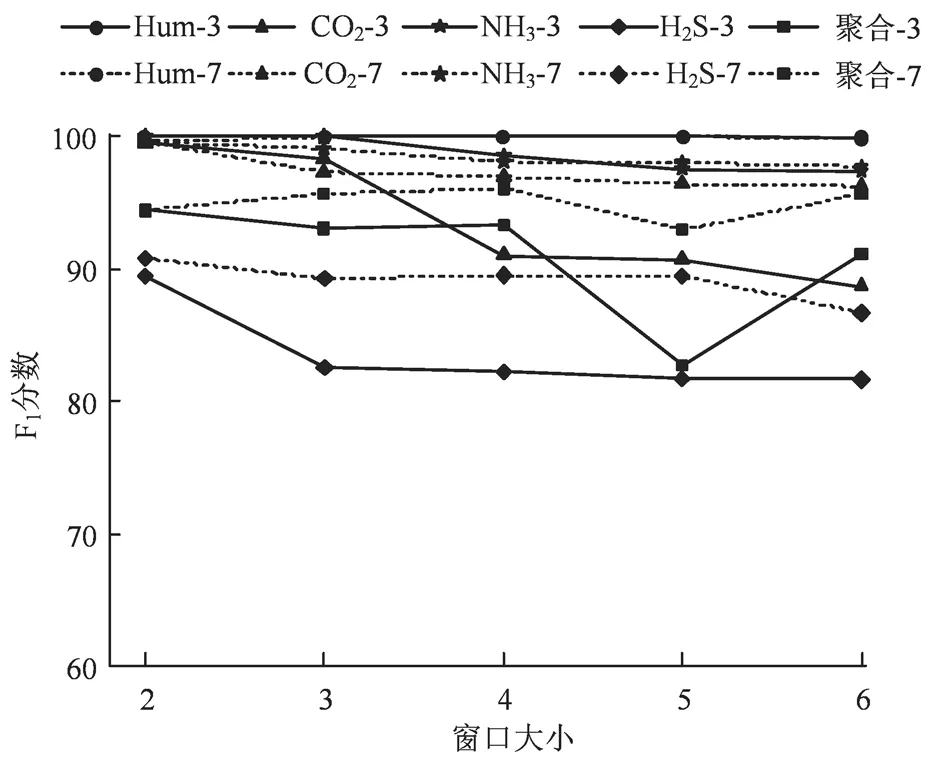
图5 不同窗口大小下异常数据检测性能Figure 5 Outlier detection under various window
初步实验表明畜禽养殖环境下,训练集采样间隔为5 min 时(常规采样)异常数据比例为7%、偏离幅度区间为[10%,30%]时,采样间隔为50 min 时(稀疏采样)异常数据比例为13%、偏离幅度区间为[30%,60%]时,训练得到的线性核SVM 模型泛化能力较强。实验表明所提出的基于向量升维的异常数据实时检测方法具有较高的稳定性,两组实验的异常数据检测等性能均较为接近,下列各节实验结果取两组实验的平均值。
2.1 窗口大小对模型检测性能的影响
测试集中异常值比例为3%和7%、偏离幅度区间为[10%,30%]。从图5 可得,对于空气湿度数据,模型的异常数据检测精确度、召回率和F1 分数均接近于100%。CO2和NH3浓度数据中,模型的异常检测F1 分数在窗口大小为2 时接近于100%,但随着窗口大小的增加,数据变化量的累计效应造成模型异常检测精确度显著下降,造成F1 分数呈现下降趋势。H2S 浓度数据的异常检测F1 分数明显低于其他数据,这是由于H2S 浓度数据波动性较大。此外,尽管H2S 数据的异常检测精确度接近于100%,但随着窗口大小的增加,异常数据易被误检为正常,使得其召回率低于80%。对于聚合数据,模型的异常检测效果不稳定,当窗口大小为5 时F1分数突降。窗口大小为2 时,同类数据在不同异常占比下F1 分数差距最小。故数据独立检测比数据聚合检测有着更优的检测效果。

图6 不同窗口大小下模型计算耗时Figure 6 Computation cost under various window
如图6 所示,模型检测耗时受异常值比例影响较小。较大的数据量导致聚合数据的异常检测耗时明显高于其他单项数据检测方式。数据检测耗时整体与窗口大小呈正相关,窗口大小为2 时模型总耗时最低,2 016 个数据点的单项数据的检测总耗时低于2 ms,平均单次检测耗时小于0.001 ms,能够满足异常数据检测的实时性要求。因此,综合考虑模型的异常数据检测能力、计算耗时等因素,可知:独立进行异常数据检测,窗口大小取2 系较为理想的方案。
2.2 模型对不同异常值偏离幅度的敏感性
常规采样场景下异常数据比例为7%、偏离幅度区间位于[10%,100%]时,模型对各类数据中存在异常数据的检测结果如图7(a)所示。空气湿度、CO2浓度和NH3浓度数据在3 个偏离幅度下的模型异常检测F1 分数均达到99%以上,此时异常检测精确度均为100%,但部分异常数据被误检为正常从而导致召回率略有劣化,为98.8%。对于H2S 数据,当异常值偏离幅度较小[10%,30%]时低至82.3%的召回率使得F1 分数显著下降;当偏离幅度大于30%时精确度达100%、召回率为97.8%,获得了99.26%的F1 分数。因此,常规采样场景下,震荡幅度较为平缓的空气湿度、CO2浓度和NH3浓度数据,模型能够成功地将偏离幅度大于10%的异常值检出,而对于震荡剧烈的H2S 浓度数据,模型对偏离幅度大于30%的异常值才能达到较好的检测效果。
由于稀疏采样时获得的数据点较少且数据间波动幅度大,使得小幅偏离数据与正常数据间难以区分,稀疏采样时的异常值检测性能略差于常规采样。图7(b)为稀疏采样场景下异常数据比例为13%、偏离幅度大于30%时,模型对数据中存在异常值的检测结果。从图中F1 分数来看,模型在空气湿度和NH3浓度数据间的异常检测效果无显著差异,对CO2浓度数据异常检测性能略次于前两者。其中空气湿度数据中出现召回率劣化,而在CO2浓度和NH3浓度数据中精确度和召回率均出现下降,但其精确度和召回率分别保持在83.2%和90.1%以上。稀疏采样时相邻采样点的H2S 浓度数据之间抖动更大,当异常值偏离幅度大于60%时F1 分数才达到92.6%,精确度和召回率分别为98.3%和87.5%。对稀疏采样得到与图7(a)中常规采样相同的数据量进行向量升维、模型训练和异常数据检测,结果表明异常检测精度明显劣于图7(a)。故模型的异常检测性能与异常值偏离幅度正相关、与数据采样间隔负相关。
2.3 不同异常值比例对模型检测性能的影响
异常值偏离幅度区间为[30%,60%],考察模型对包含不同比例异常数据的检测性能。图8(a)为常规采样场景下不同异常值比例下的检测F1 分数。对于同一数据,模型的异常检测F1 分数未呈现显著变化。具体地,4 种数据中模型的异常检测F1 分数均达到98.57%以上,空气湿度和CO2浓度数据中模型的异常检测效果优于NH3浓度和H2S 浓度数据。4 种数据中异常值召回率在98%~100%之间波动。对于NH3浓度数据,初始时其检测精确度与异常值比例呈正相关,当异常值比例上升到6%后趋于稳定。在空气湿度、CO2浓度和H2S 浓度数据的异常检测中,精确度始终为100%,模型的异常检测F1 分数主要受召回率影响。

图7 不同异常值偏离幅度下模型检测结果Figure 7 Detection results under different outlier amplitude

图8 不同异常值比例下模型检测结果Figure 8 Detection results under different outlier ratios

图9 不同模型的异常数据检测性能Figure 9 Outlier detection results of different models
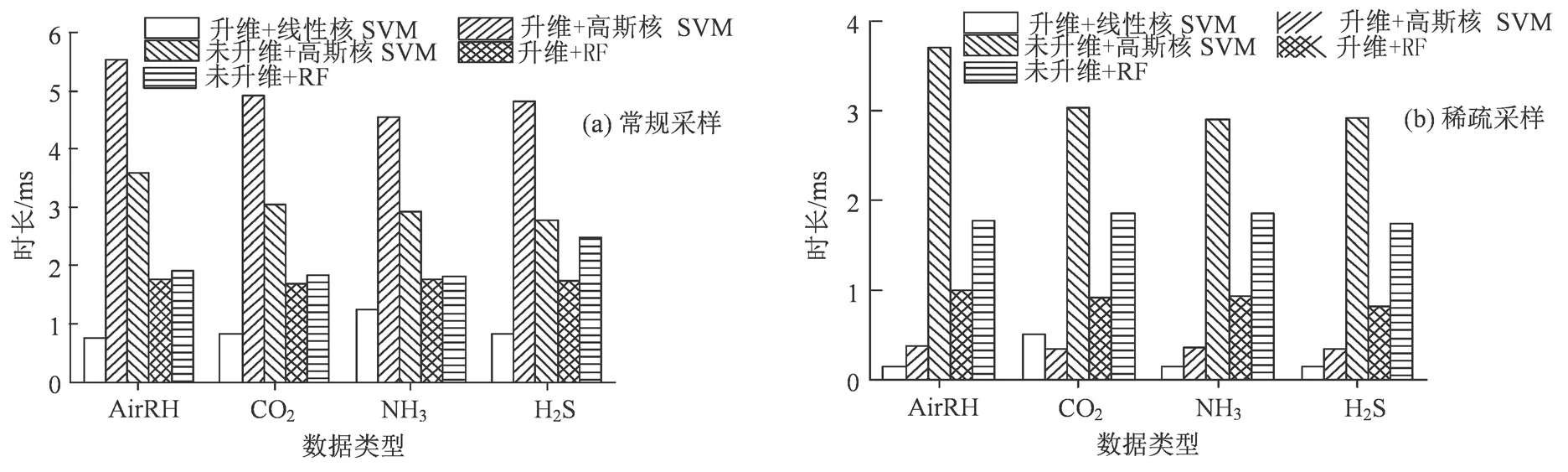
图10 不同模型的异常数据检测耗时Figure 10 Computation cost of different model
稀疏采样场景下模型对异常数据检测的F1 分数如图8(b)所示。尽管异常检测效果劣于常规采样场景,不同异常值比例下模型的异常检测效果均较为稳定。空气湿度、NH3浓度数据中F1 分数均值高于93.6%,CO2浓度数据的平均F1 分数为90.9%,H2S 浓度数据的F1 分数最差,均值为74.1%。具体地,对空气湿度和H2S 浓度数据,模型的异常值检测精确度保持在100%,CO2浓度、NH3浓度数据中异常值检测精确度随异常值占比的增加而缓慢上升。与常规采样相比,稀疏采样后异常值甄别难度更大,尤其在H2S 浓度数据的异常检测中,模型易将偏离幅度小的异常数据判断为正常,其中平均召回率仅为54.5%,但未随异常值比例的改变呈现显著变化。
2.4 不同模型的异常数据检测性能分析
分析观测向量升维前后线性核、高斯核SVM和随机森林RF 的异常数据检测性能。初步实验得高斯核SVM 模型中gamma 和惩罚系数分别取2 和1,RF 模型中树及其最大深度分别取10 和5 较为合适。测试集中常规采样场景下空气湿度、CO2浓度和NH3 浓度数据异常值比例为7%、偏离幅度区间为[10%,30%],H2S 浓度数据异常值比例为7%、偏离幅度区间为[30%,60%]。稀疏采样数据空气湿度、CO2浓度和NH3浓度数据中异常值比例为13%、偏离幅度区间为[30%,60%],H2S 浓度数据中异常值比例为7%、偏离幅度区间为[60%,100%]。
常规和稀疏采样2 种场景下不同模型的异常数据检测性能如图9 所示。在常规采样场景下空气湿度、CO2浓度和NH3浓度数据的异常检测中,数据升维后的线性核SVM 模型和RF模型表现出较好的检测性能,其中线性核SVM 模型的异常检测F1 分数均在99.1%以上,CO2浓度数据中的异常检测F1分数达到了99.4%。在稀疏采样的空气湿度、CO2浓度和NH3浓度数据异常检测中,升维+线性核模型的异常检测F1 分数分别为:98.6%、97.4%和97.5%,均优于其他模型。这3 组数据中,升维+线性核SVM 模型的F1 分数损失在于模型将个别异常值误检为正常从而导致召回率下降,其他模型的F1分数损失主要来自于精确度。对于常规采样场景下H2S 浓度数据的异常检测,除未升维+RF 模型外,其他模型都表现出较好的检测性能,F1 分数均达到99.1%以上。稀疏采样的H2S 浓度数据,5 种模型的检测效果差距较小,其中数据升维后的线性核SVM模型和RF 模型效果最好,F1 分数均在92.6%以上。
总体上,采用向量升维策略后,模型对异常数据的检测能力均得到了不同程度的提升。其中,RF模型在数据升维后异常检测能力的提升最为显著,而高斯核SVM 模型的检测能力提升程度有限。这表明在进行向量升维后,无需采用高斯核再次将数据向高维空间映射。另一方面,对于空气湿度、CO2和NH3 浓度数据,线性核SVM 模型展现了最优的异常数据检测能力。在H2S 浓度数据的异常检测中,线性核SVM 拥有优于或与高斯核SVM 模型、RF模型相当的异常数据检测性能。
各分类模型在两种采样场景下的异常数据检测耗时如图10 所示。由图10(a),对于常规采样数据,高斯核SVM 模型的检测总耗时明显高于其他模型,而线性核SVM 模型耗时最短,在空气湿度、CO2浓度、NH3浓度和H2S 浓度的异常数据检测中,2016 个数据点的检测总耗时小于1.5 ms,单个数据点的检测耗时低于7.44╳10-4ms。在图10(b)所示的稀疏采样场景下各模型的异常数据检测耗时中,高斯核SVM、RF 模型的异常检测耗时均明显高于线性核SVM 模型。综上,对于农情数据的异常检测,线性核SVM 模型在检测能力和耗时两个方面均优于同类模型,具有最优的适用性。
3 讨论与结论
异常数据处理是提高农业物联网数据感知质量的重要手段。本研究提出了基于向量升维的农情异常数据实时检测方法,采用畜禽养殖物联网环境数据,综合评估了其异常数据检测性能与特征。
实验结果表明,通过将时序农情数据标准化、向量转换与升维操作后,支持向量机、随机森林等分类模型的异常数据检测能力均得到明显提升。由于向量升维处理后的数据线性可分,采用线性核支持向量机能够以低计算耗时获得较优的异常数据检测效果,且避免了高斯核支持向量机等模型训练时需要多次确定超参数、泛化能力的不足的问题。
实验发现,异常检测效果与异常值出现频度基本无关,但与数据波动性和采样间隔负相关、与异常值偏离幅度正相关。相同的目标数据集,对于震荡幅度较为平缓的数据,采样间隔为5 min 时,模型对偏离幅度大于10%的异常数据检测精确度和召回率分别可达100%和98.8%;采样间隔增加到50 min 的稀疏采样时,模型对偏离幅度大于30%的异常数据检测精确度和召回率达83.2%和90.1%以上。而对于波动性较强的数据,两种采样间隔下,模型对偏离幅度大于30%、60%的异常数据检测精确度和召回率分别为100%和97.8%、98.3%和87.5%。
本研究的实验数据与大田、温室大棚等农业生产环境和作物生长数据具有相似的变化特征,故所提出的农情异常数据实时检测方法与结论可直接应用于大田、温室大棚等其他农业生产场景下相关数据的异常值检测以提高数据感知质量,具有较好的实际应用价值。后续将开展异常值校正方法的研究,为进一步提升农情数据的感知质量提供支撑。
