矢量地理信息溯源记录组织验证的区块链技术
2021-06-29姜良存张明达梁哲恒
李 皓,乐 鹏,姜良存,张明达,梁哲恒
1. 武汉大学遥感信息工程学院,湖北 武汉 430079; 2. 湖北大学资源环境学院, 湖北 武汉 430062; 3. 广东南方数码科技股份有限公司,广东 广州 510665
在空间基础设施背景下,地理数据的生产、应用过程逐渐由传统集中式向分布式协作方向发展。在集中式的平台环境下,数据产品严格按照算法处理和工作流等流程生成,具有较高的可信性[1]。而分布式环境下,数据来源多样、质量各异,未经质检的数据被广泛而频繁地处理、应用和共享,数据产品的质量具有很大不确定性。地理数据产品可能来源于专业测绘数据、众源地理数据或自发地理信息(VGI)等[2-3],难以评估数据是否可用可靠,因此通过溯源信息对地理数据产品进行可信评价尤为重要[4-7]。溯源信息记录了地理数据的来源、变动和数据提供者等信息,为数据产品评价提供参考依据。对于地理数据溯源的研究,国内外学者已开展了较多关于溯源模型、追踪方法、溯源信息组织等方面的研究[1,4-6,8-12],但尚缺乏对溯源信息本身的可靠和可信性研究。在分布式协作环境下,对于地理数据产品的溯源信息同样存在着可靠性保证问题,在数据产品的共享、分发和交换中存在元数据的篡改风险。究其原因,在于地理数据共享时缺乏可信的溯源技术支持。特别在数据产品资产化的趋势下[13],对数据权利人、时间戳等元数据进行伪造篡改等行为严重影响了数据评价。因此,可信的溯源信息存储管理是地理数据溯源重要的基础和保障[14]。
近年来,区块链技术快速发展,其所具有的去中心化、不可篡改、可信透明的特点为溯源信息可靠可信的存储管理提供了新的解决思路。区块链是一种多方共同参与和维护的去中心化数据库,也是一种融合了加密算法、共识机制、智能合约等模块的新型分布式账本技术[15-16]。目前已有部分学者将区块链技术应用于数据溯源领域[17-22]。文献[17]利用智能合约和OPM模型(open provenance model)进行了安全捕获溯源信息和溯源验证的试验。文献[19]基于区块链构建了一个分布式系统用于管理溯源元数据以及设置数据访问权限。文献[20]提出了一种云环境下基于区块链的数据溯源架构,用区块链存储溯源信息来提供云文件的防篡改安全特性。
上述对区块链溯源的研究均是面向通用的溯源场景。借鉴相似的思路,区块链同样能够在地理数据的可信溯源方面产生重要价值,为地理信息数据的分发、共享和追溯提供可信技术支持。然而,在地理信息科学领域,特别是VGI场景下,地理数据的生产和更新速度快,产生的溯源信息量大,且溯源信息的记录往往发生在不同粒度层级上[10]。因此,本文以矢量数据为研究对象,提出一种利用MPT树对矢量溯源信息进行链上存储组织的方法,并设计了基于该存储结构的溯源可信验证算法,实现了对矢量溯源信息高效的溯源验证。
1 矢量数据溯源
1.1 矢量数据溯源模型研究现状
矢量数据溯源记录了矢量数据生产、变更所涉及的数据实体、活动、个人或组织等相关信息[1]。现有的研究已从矢量数据处理类型和溯源性能等方面,对矢量数据溯源提出了不同粒度划分的需求[1,4,7,10,23]。例如文献[10]分析了从数据集、要素、属性3个粒度级别进行矢量数据溯源的必要性。具体而言,矢量数据集级别溯源描述了受到相同影响的多个要素的溯源信息。要素溯源用于描述特定要素的变更信息。而属性溯源可分为几何属性和非几何属性的溯源,分别用于描述要素的几何属性和非几何属性上的变化。总体而言,矢量溯源记录在粗粒度上记录细粒度级别的共有信息,而在细粒度级别记录更详细的溯源信息,从而减少溯源信息的冗余和重复性。
溯源模型是溯源信息共享和互操作的基础。PROV是W3C数据溯源工作组在2013年推出一种通用的数据溯源模型[24],其核心结构包含3种类型,分别为实体(entity)、活动(activity)以及代理(agent),通过3种核心类型之间的关系来描述溯源信息。实体可以是任何形式存在的事物,包括客观世界的地理实体和数字世界的地理数据(如所有粒度级别的数据源或输出结果)。活动是作用于实体的行为,例如轨迹数据的绘制操作,活动内容包括了活动类型、活动时间等。代理是对实体、行为负责的对象,可以是人或组织,代理内容包括代理的名称及社会属性信息等。文献[10]分析了PROV模型适合作为一种地理空间数据的溯源模型,并扩展了矢量数据集(dataset)、要素(feature)、属性(attribute)3种类型实体。属性被作为一种实体类型,可分为几何属性(geometry feature)和非几何属性(property)。扩展的PROV溯源模型如图1所示。在本文后续的工作中将基于该扩展的PROV溯源模型对矢量溯源信息进行记录。
1.2 矢量数据溯源案例
本文通过一项矢量数据合并的案例来展示不同粒度的矢量溯源信息的记录细节及特征。该案例的数据来源包括一份专业测绘机构绘制的数据(图2(a))作为参考数据源,以及一份从Open StreetMap(OSM)下载的不同时相的相同区域的数据 (图2(b)) 作为待匹配数据源。通过特定的匹配算法合并最终生成一个数据结果(图2(c))。扩展的PROV溯源模型对合并处理过程中的3种粒度的溯源信息进行记录。溯源信息的捕获参考了文献[23]中提出的一种捕获流程。该流程在矢量数据操作流程中扩展了数据集和要素的溯源捕获模块。数据合并完成后,用户若想了解合并结果来自哪些数据源,甚至某一矢量要素或其属性信息来自哪个数据源,需要在合并时捕获不同级别上的来源信息。在粗粒度级别,捕获模块记录数据集级别的溯源信息,包括数据源、匹配算法、执行参数、处理时间和执行者等信息;在细粒度级别上,如果某一要素完全来自一个数据源,则可记录至要素级别上的溯源信息,如果该要素保留了不同数据源的属性信息,则需要记录属性级别上的溯源信息,其中对应的活动类型包括了属性的保留、新增和更新等。因此在合并处理完成后,溯源捕获将在3种粒度层级上记录丰富的溯源信息。考虑到矢量数据集可能包含了大量的要素及要素属性,单次的矢量数据操作(合并、更新等)便可能产生大量的要素、属性级别上的溯源信息。
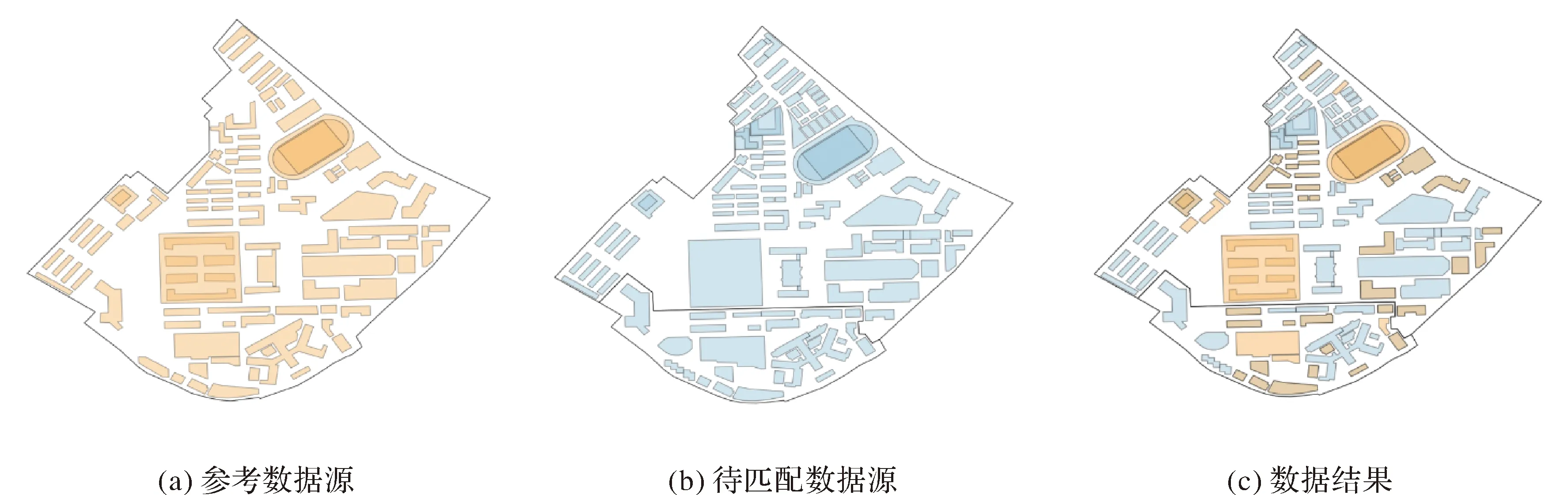
图2 矢量数据合并的案例Fig.2 An example of vector data merging
2 基于区块链的矢量数据溯源挑战
区块链是一种多方共同参与和维护的去中心化数据库,由带有时间戳的区块组成,每一区块引用前一区块的加密散列值,并依此连接成链状结构。在区块链中单个区块是存储数据的基本单元。区块由区块头和区块体两部分组成。区块头中主要包含父区块散列值、时间戳、区块高度、难度值、证明值以及存储树的根哈希值(tree root hash)。区块体是区块链中存储数据记录的位置,通常以树形结构组织,是区块链中重要的数据结构。梅克尔(Merkle)树结构[25]是最常见的一种链上信息存储结构,例如经典的比特币系统[26]采用了二叉Merkle树结构来组织一个区块内所有的交易信息,其叶子节点的值为交易信息的散列值,通过逐层合并计算得到整棵树以及根哈希值。区块体采用Merkle树等树形结构的作用在于验证过程中不需要下载整棵树,而是通过验证路径(tree path)即可完成对信息的验证,验证路径为从该节点出发达到根节点所经过的路径。区块链的这种可信验证机制为链上的溯源信息提供了防篡改、可信任的安全特性。然而在地理数据场景中,由于矢量溯源记录的特征,直接采用Merkle树结构面临着如下挑战:
(1) 由于矢量溯源记录信息量丰富,若将溯源信息直接记录到区块链,必然造成区块链存储压力,并进一步对区块链网络中账本同步的效率造成挑战。
(2) 在地理协作过程中,地理数据更新频繁、不确定性高、溯源数据量大,单个区块内存入大量溯源信息会造成Merkle树的规模增大,这将对溯源信息的查询和验证性能形成挑战。
为应对挑战(1),本文的溯源区块链采用链上链下的存储模式,即链上只存储溯源条目的散列值,而完整的溯源信息存储在链下的本地溯源数据库。这里的溯源条目为链下溯源信息经过溯源模型生成的单元。溯源区块链将溯源条目进行MD5 Hash算法得到散列值,并在区块体中对散列值进行存储组织。该散列值与溯源条目原始信息具有对应的映射关系,同时链上存储散列值减小了区块链的存储压力。为应对挑战(2),本文采用基于MPT树的多粒度矢量溯源信息链上存储组织方法,根据溯源验证算法的流程对溯源验证性能进行对比试验。
3 矢量数据溯源区块链设计
3.1 溯源链设计要求
基于溯源模型需求分析及上述区块链挑战分析,着重考虑矢量溯源信息的多粒度层级、数据量大等特性,本文归纳矢量数据溯源信息的链上存储结构应该尽可能满足以下3个条件:
(1) 在分布式协作的环境下,假设系统环境对溯源记录具有篡改风险,溯源信息存储结构应具有溯源信息的可查询和可验证的特性。
(2) 提供多粒度、可伸缩性的溯源查询请求,以满足用户不同粒度层级(矢量数据集、矢量要素、要素属性)的溯源查询。
(3) 各溯源粒度层级间保持关联关系,同一数据集下的要素溯源信息与对应数据集的溯源信息存在关联性,以增强溯源查询验证的能力。
3.2 溯源信息的链上存储结构
本文设计了一种利用MPT树结构对不同粒度的矢量溯源信息进行链上存储和组织的方法。MPT树是以太坊账户信息和交易信息的存储结构,结合了Merkle树和Patricia前缀树的特点,既具有Merkle树可验证的特点,也具有Patricia树节点间共享前缀的特点。MPT树包含以下3种类型节点,分别是叶子结点(leaf node)、前缀节点(prefix node)、分支节点(branch node)。
(1) 叶子节点为树型结构中的最底层存储节点,存储了编码段Key和溯源条目散列值Val。Key由地理数据统一资源标志符(URI)经特殊编码和处理得到。叶子节点存储的Val也作为节点散列值,被用于后续的真实性验证。
(2) 前缀节点压缩了不同编码的相同前缀,存储了压缩编码段Key和节点散列值hash。
(3) 分支节点为拥有超过1个孩子节点以上的非叶子节点,由指向孩子节点的索引ChildrenNode、所有孩子节点Val值拼接后的节点散列值hash、溯源条目散列值Val构成。其中,ChildrenNode是一个长度为16的数组,范围是十六进制表示的0至f。
3.3 矢量溯源信息的上链方法
矢量数据溯源链通过上述MPT树结构对矢量溯源信息进行链上的存储和组织,将此步骤定义为溯源信息的上链过程。根据扩展的PROV模型,溯源的实体具有不同的粒度级别。不同粒度实体的URI需符合相应规范,对于细粒度实体应将其所在粗粒度实体的URI作为自身URI的前缀部分,例如数据集A对应的URI为“http:∥example.com/resource/dataset_A”,则数据集A中要素B对应的URI为“http:∥example.com/resource/dataset_A/feature_B”。上链过程主要依据溯源实体的URI将溯源条目的散列值插入到MPT树的特定位置和深度。具体的上链步骤如下:
(1) 对溯源实体的URI进行原生字符向十六进制(Raw-Hex)编码转换。首先Raw编码操作,对原始的URI逐个分隔为单个字符,并转换成ASCII码值。接着Hex编码操作,对转换得到的ASCII码值除以16取除数和余数依次作为新编码的结果,目的是将编码结果的数值控制在16以内。由URI原生字符经过Raw-Hex编码得到的结果记为对应溯源条目的初始编码段。例如数据集A的URI为“http:∥example.com/resource/dataset_A”,则其初始编码段表示为(仅展示前后6位)[6,8,7,4,7,4,…,7,4,5,f,4,1]。
(2) 生成初始树节点。选取某一粗粒度的溯源条目插入MPT树中,依据树节点类型的定义,第1个树节点也是最底层的存储节点,即为叶子节点。
(3) 继续插入粗粒度溯源条目。将当前待插入的溯源条目定义为新插入的节点。根据新插入节点的初始编码段寻找当前树型结构中的具有最长相同前缀的树节点,将剩余编码段定义为初始编码段减去当前树型中相同前缀后所剩余的编码部分。若寻找到的树节点为分支节点,则将当前溯源条目作为一个叶子节点插入到分支节点对应的孩子节点位置。若寻找到的树节点为叶子节点或前缀节点,判断该树节点与新插入节点的剩余编码段是否具有相同前缀,若有则新生成一个前缀节点,并将该树节点变更为分支节点,原树节点与新插入节点作为分支节点的两个孩子节点插入。若两者无相同前缀,则直接生成分支节点,原树节点与新插入节点作为两个孩子节点插入。
(4) 重复步骤(3),直至所有的粗粒度溯源条目插入到MPT树中。
(5) 插入更细粒度级别的溯源条目。例如溯源条目对应实体为数据集A下要素B,要素B的URI为“http:∥example.com/resource/dataset_A/feature_B”,则其初始编码段表示为(仅展现部分编码)[6,8,7,4,7,4,…,7,4,5,f,4,1,…,6,5,5,f,4,2]。
(6) 同理粗粒度溯源条目的插入,直至完成所有细粒度溯源条目的插入。
(7) 逐层计算节点散列值,最后得到整棵树的tree root hash,将tree root hash存入区块头内。
上述上链方法根据实体URI确定了不同粒度溯源条目在MPT树中的位置,并形成一种粗细粒度间的包含关系,即细粒度的溯源条目存储于所属粗粒度溯源条目所在的子树中。基于表1的用例数据在图3中展示了一个MPT树的示例,树状结构的不同深度层次分别对应矢量数据集、矢量要素和要素属性3种粒度的溯源条目存储位置。
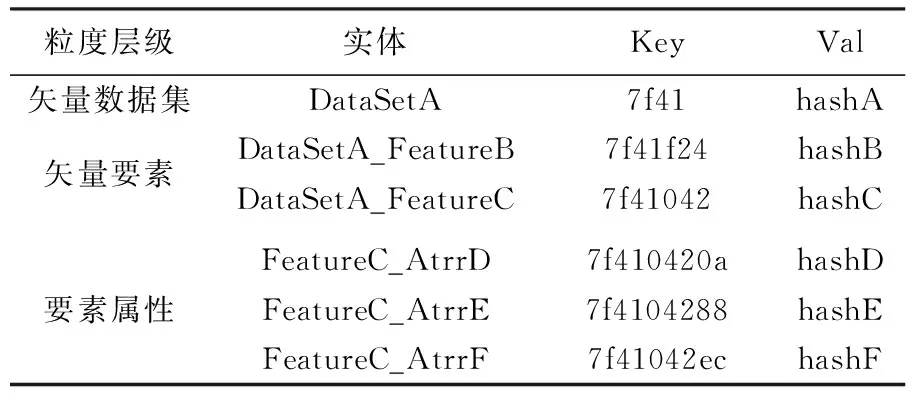
表1 溯源信息的用例数据

图3 不同粒度溯源条目在MPT树中存储位置的一个示例Fig.3 An examples of storage locations of provenance entries with different granularities in the MPT tree
4 矢量数据溯源验证
MPT树结构保留了Merkle树的验证原则,通过验证算法对溯源信息真实性进行判断。溯源验证包括溯源查询和真实性验证两部分。首先进行溯源查询,通过遍历树形结构检索到目标溯源条目的存储树节点位置;第2步是进行真实性验证,通过溯源条目的存储位置计算得到一条验证路径。由于无法确定分布式环境下验证路径的响应是否存在欺诈,因此需利用验证路径计算得到一个最终的哈希值,并与区块头中的根哈希进行比较,若相同则证明溯源条目可信。
矢量溯源信息验证的一个特征在于溯源验证请求需要同时验证粗粒度溯源信息及大量细粒度溯源信息。这对溯源验证性能造成挑战。为方便理解,本文将验证矢量数据集及其包含的要素、属性级别的溯源信息的过程定义为矢量数据综合溯源验证。本文提出的溯源信息链上存储结构支持综合溯源验证能力。在验证过程中,对粗粒度(数据集级别)溯源条目验证可信后,可依据粗粒度的验证路径快速定位到所包含的细粒度(矢量要素级别、要素属性级别)溯源条目所在的树节点位置,并在验证子树中完成细粒度的溯源验证。图4以一个简化的MPT树展示了矢量数据综合溯源验证。图中Hash78所在的树节点存储了要素溯源条目,其父节点存储了数据集溯源条目,在数据集溯源条目验证通过后,只需在验证子树中完成更细粒度的溯源验证即可,不需要重新对整棵树进行遍历计算。具体验证算法流程如图5所示。

图4 综合溯源验证示意图Fig.4 Comprehensive provenance verification diagram
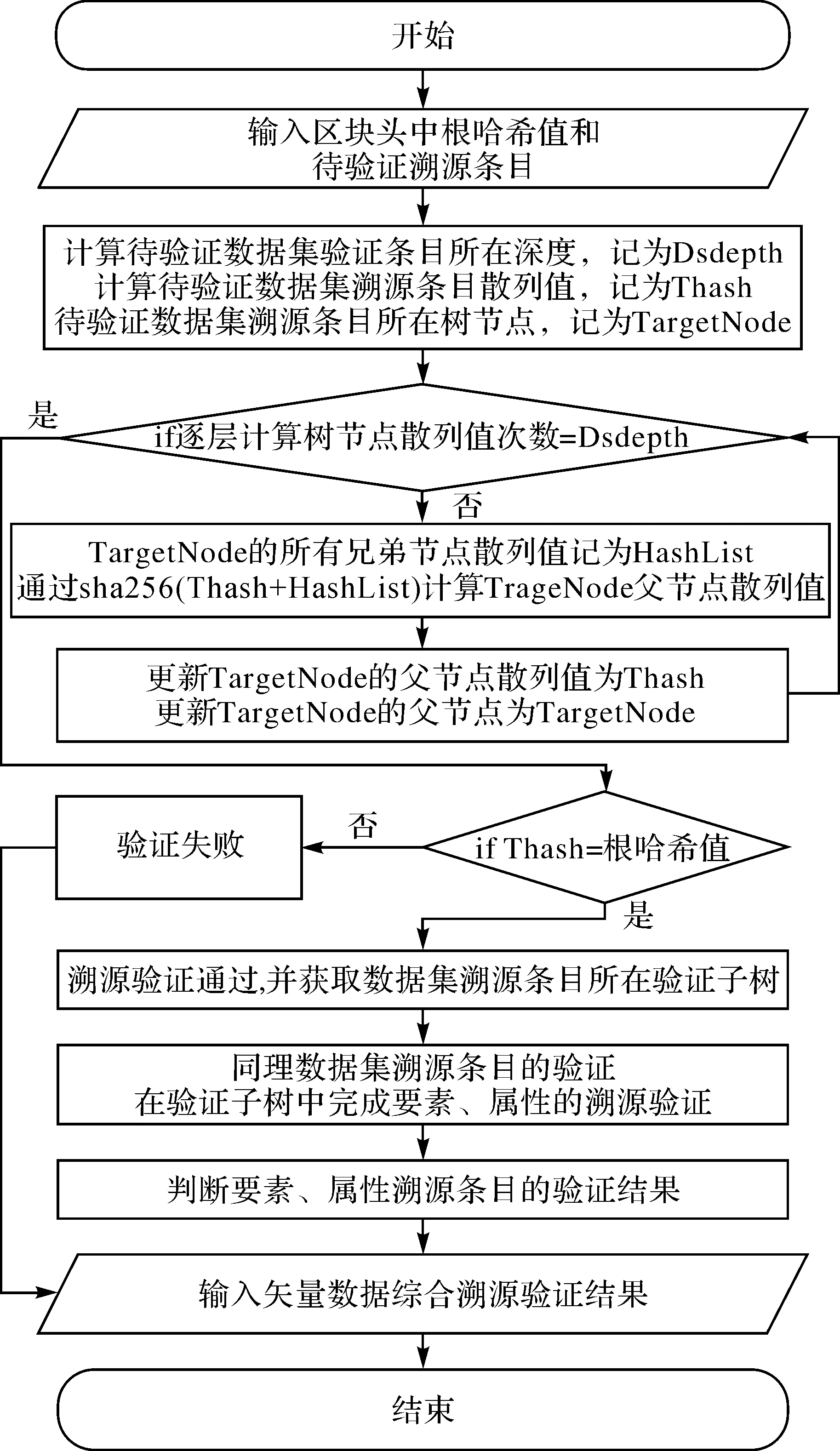
图5 矢量数据综合溯源验证流程Fig.5 Vector data comprehensive provenance verification flowchart
5 试验与分析
5.1 试验环境与准备
矢量溯源区块链系统的试验环境采用分布式集群架构,试验集群由5台服务器组成,服务器系统版本为Ubuntu16.04.6,配置为双核、4 GB,且保证服务器之间可互相通信,如图6所示。每个服务器配置PostgreSQL 9.3数据库用于存储完整的溯源信息。网络中所有服务器节点共同维护区块链账本,用户可通过任意服务器节点连接的客户端进行溯源查询与验证。

图6 矢量溯源区块链试验测试环境Fig.6 Experimental test environment of vector data provenance blockchain
在溯源信息上链准备阶段,试验在地理矢量数据处理平台进行了多次矢量数据合并操作,并通过收集、监听模块对产生的溯源信息进行捕获上链。矢量数据合并所使用的多份参考数据源来自专业测绘机构绘制的建筑物矢量数据,匹配数据源来自OSM中不同时相、相同区域的矢量数据。其中数据源中矢量数据集包含的要素数量在2至100条,每要素包含的属性数量在2至20项。为方便对比溯源验证性能,试验基于原比特币机制中固定区块容量大小的出块策略[27],设置了包含500、1000、1500、2000、2500、3000条溯源条目作为区块大小分级,即溯源信息按照区块大小分级的数量上链至每区块中。在试验测试中,本文忽略了搜寻溯源信息所在区块高度的耗时,而重点测试基于通用的二叉Merkle树与本文提出的基于MPT的链上组织结构的溯源验证性能。
5.2 原型系统展示
为帮助理解矢量数据溯源链的使用与运行,本文开发了基于区块链的矢量数据溯源验证原型系统,原型系统可作为区块链节点的交互客户端,系统界面如图7所示。用户可以查询合并案例中的数据结果及其溯源信息,系统界面的下边栏展示了从本地溯源数据库中查询到的所有溯源信息。进一步,用户通过原型系统向区块链网络发起验证请求,利用区块链对查询到的溯源信息进行真实性验证,如系统界面中红线框内即为验证结果。当结果返回“True”时表示溯源信息真实可靠,未被篡改;当验证结果为“False”时表明该条溯源信息已被改动。

图7 基于区块链的矢量数据溯源验证系统Fig.7 Vector data provenance and verification system based on blockchain
5.3 溯源验证耗时对比
以下对比测试基于二叉Merkle树和MPT树的溯源验证耗时。首先对比在不同区块大小分级下两种链上组织结构的单次溯源验证耗时。选取100次溯源验证耗时的平均值进行对比(图8),不难发现单个溯源条目的响应耗时均在秒级。从整体来看,溯源验证耗时都随着区块大小增大而增加,二叉Merkle树下的溯源验证耗时要大于MPT构建的3种粒度的溯源验证耗时。当溯源查询验证所需遍历的树节点数目越少,验证耗时与开销也相应减少。本文进而对比了不同区块大小下树节点的数量(图9),可以看出MPT树相比二叉Merkle树大约可以减少28.8%~37.5%的树节点的冗余。在3种粒度的溯源验证耗时对比中,数据集级别的验证耗时最少,原因是粗粒度的溯源条目平均存储位置相比细粒度的溯源条目更加靠近根节点,验证路径更短,其单次溯源响应的耗时也相对更短。

图8 二叉Merkle树与MPT树的溯源耗时对比Fig.8 Time-consuming comparison of provenance between binary trees and MPT
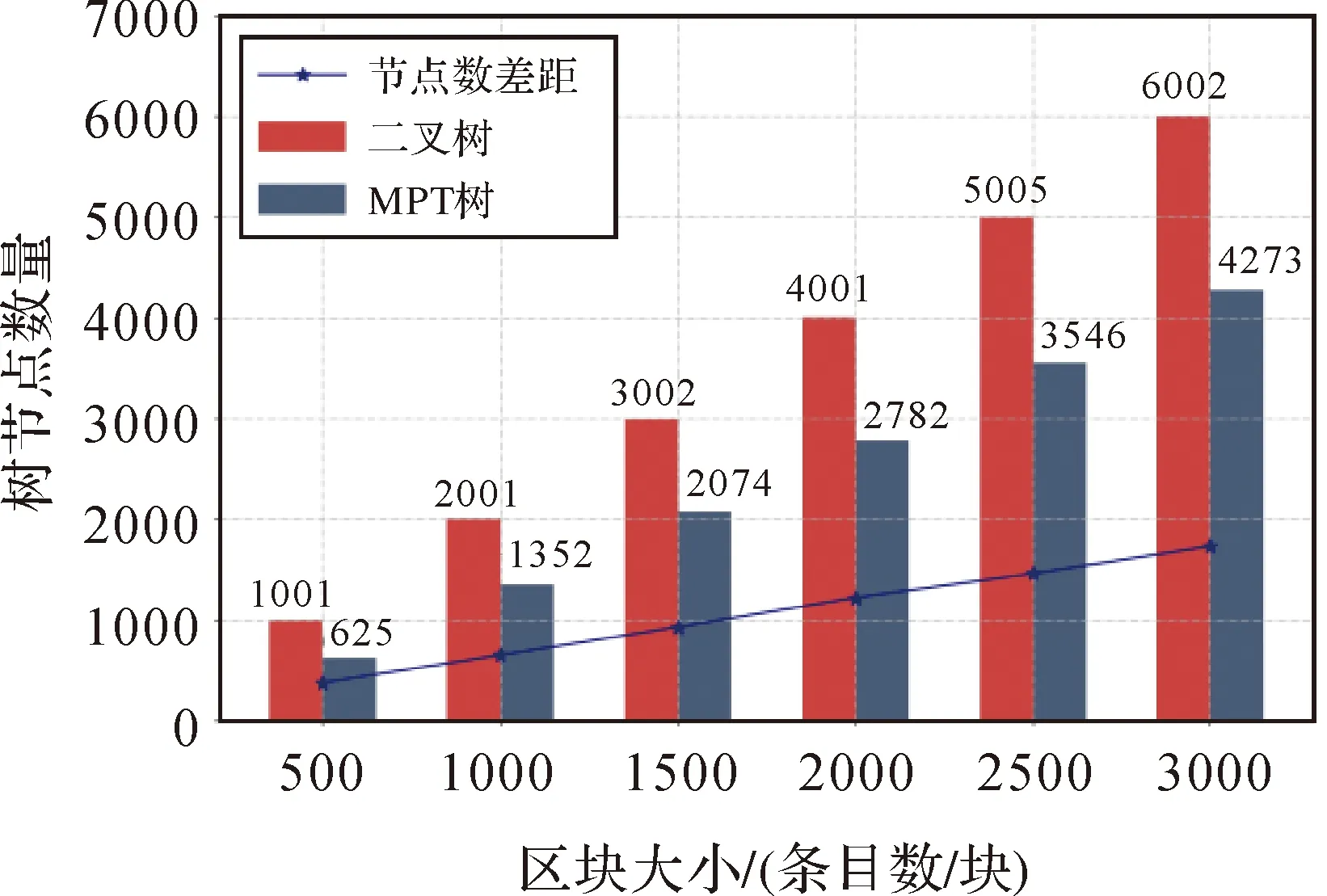
图9 二叉Merkle树与MPT树节点数量对比Fig.9 Binary tree and MPT node number comparison
本文进一步测试了矢量数据综合溯源验证的试验。在实际场景中,不同的综合溯源验证对象所需验证的溯源条目数量往往相差较大,对溯源验证耗时影响也较大。因此本次试验在不同区块大小分级下,对不同的矢量数据合并案例生成的数据集实体进行100次综合溯源验证,图10显示了二叉Merkle树与MPT树的验证耗时结果。从试验结果来看,二叉Merkle树综合溯源验证的耗时随区块大小增大而快速增加,且具有较大的浮动,而基于MPT树的综合溯源验证基本保持了较低的验证耗时,且更加稳定。经对比,不同区块大小分级下二叉Merkle树综合溯源验证的平均耗时约为MPT树的2.29~19.95倍,表明本文提出的基于MPT的链上存储组织方法具有更高效的溯源验证性能,更加适应实际场景中的矢量数据综合溯源验证。
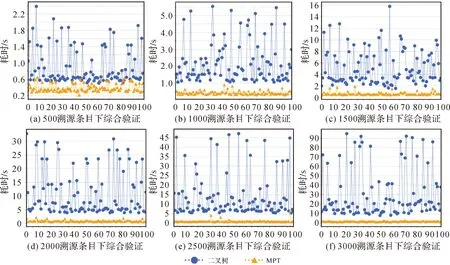
图10 二叉Merkle树与MPT树的矢量数据综合溯源验证耗时对比Fig.10 Time-consuming comparison of comprehensive provenance between binary trees and MPT
6 结 论
针对矢量溯源信息的可靠性问题,本文将区块链技术应用到了矢量数据溯源领域,探索了基于区块链的矢量溯源信息链上存储组织和验证方法。首先分析了基于区块链的矢量数据溯源存在的挑战,接着提出了矢量溯源区块链的设计要求。本文提出了一种利用MPT树对不同层级的矢量溯源信息进行链上存储组织的方法,并设计了相应的溯源信息验证算法。试验表明,与通用的二叉Merkle树相比,本文所提出的顾及矢量数据溯源粒度的链上存储组织方法具有更高效的溯源验证性能,可基本满足实际场景下的验证需求。
目前区块链应用于地理信息领域的研究刚刚起步。除了矢量数据溯源方向,在面向地理信息领域更为丰富的场景和数据源时,上链数据的范畴与接口标准需要进行必要的约定和统一。同时考虑到区块链政策因素,对于一些区块链隐私保护、权益分配等都应在相应的政策监管范围下实施。因此,未来对于区块链在地理信息领域的研究,也将从数据标准、技术研发、政策制定等多角度展开探讨。
