基于改进CHI和TF-IDF的短文本分类的研究
2021-06-29代继鹏邵峰晶孙仁诚
代继鹏,邵峰晶,孙仁诚
(青岛大学计算机科学技术学院,山东 青岛 266071)
0 引 言
文本分类是在给定分类体系的情况下,根据文本的内容或属性将其分到一个或多个预定义的类别[1]。文本分类的主要步骤包括文本预处理、特征选择模型训练以及效果评估[2]。文本分类中常常会遇到特征空间的维度太高,导致计算量巨大,分类效果不好,主要是因为选择的特征词数量巨大。进行有效的特征选择可以极大减少选取特征词数量,大幅度降低特征空间维数,能够提高分类的效率和精度。因此,在进行文本分类中,特征选择就显得至关重要[3]。特征选择降低空间维度的主要方式是在高维空间中选择出带有大部分文本信息的特征词,用这些特征词代表文本,从而有效地提高文本分类的效率和精度。因为特征选择在文本分类中的作用极其重要,所以不少国内外研究学者致力于改进特征选择方法。Salton等人[4]在1983年提出结合词频权重和反文档频率计算方法,即TF-IDF(Term Frequency-Inverse Document Frequency)算法。英国统计学家Karl Pearson在1900年首次提出卡方统计量用于卡方检验,用来验证类别和变量之间是否存在相关性,发展至今已经是文本分类中特征选择方法中比较常用、效果比较好的特征选择方法[5]。Jin等人[6]使用样本方差计算词的分布信息,并考虑最大词频信息来改进CHI(Chi-Square Statistic)方法,在3个数据集上均取得较好的结果。高宝林等人[7]通过引入类内和类间分布因子,提出了基于类别的CHI特征选择方法,对低频词进一步处理,主要针对特征词类别间均匀分布的情况,来降低其权重。但这些方法都没有考虑高频特征词在少数文本集合中的分布。
传统特征选择方法和权重计算方法都存在着不足。TF-IDF权重计算方法主要有以下问题:主要考虑词频来度量特征词所携带的文本信息量,忽略了特征词在类别之间均匀分布等特殊情况。传统CHI统计方法对于低频词所赋予的权重较大,如果只使用CHI统计方法不能很好地过滤低频词中的噪音词,影响特征词的选取,进而影响分类准确性。本文引入类词因子用来改进CHI和TF-IDF特征选择方法,将其相结合来提高特征词在类别间和类别内的分类能力,并且以社区居民提交的话题事件数据为例,通过对比特征选择方法在多分类上的实验结果,验证了本文提出的基于改进特征提取方法的有效性。实验表明,该方法分类效果明显优于传统CHI特征选择方法、TF-IDF权重计算方法和文献[7]、文献[8]的方法。
1 相关方法与不足
1.1 传统TF-IDF权重计算方法
文本分类过程中的特征选择通常选择可以清楚地区分不同类别的特征词。传统TF-IDF权重计算方法中,用词频TF(Term Frequency)来表示特征词在文本中出现次数[9]。IDF(Inverse Document Frequency)表示逆文档频率,特点是:如果某一特征词出现在不同类别的文档中,出现在不同类别的数量越多,那么这个特征词的分类能力就越差[10]。IDF计算方法如公式(1)所示:
(1)
公式(1)中N表示整个训练样本中文本总数,nk表示所有类别中包含特征词的文本数。TF-IDF通过加权方法将2种方法结合在一起,TF-IDF计算公式如下:
(2)
1.2 传统TF-IDF权重计算方法的不足
传统TF-IDF权重计算方法的缺点主要是不能很好表征特征词在类别之间的分布情况。特征选择所选择的特征词应该是在某一类别文档中较为集中出现,几乎不在其他类别中出现,即该特征词在各类别文档频率具有明显差异。如果特征词在各个类别中是均匀分布,则该特征词对类别没有区分度,对分类基本没有贡献,不具备很好的分类能力。如果某一特征词在某一类别文档中较为集中出现,几乎不在其他类别中出现,那么这个特征词就能很好地表征这个类的特征,但是TF-IDF不能很好区分这2种情况[11]。
例如:特征词a在第一类所有文档中出现的文档数为m,在其他类文档中出现的文档数为n,则在所有类别的所有文档中包含特征词a的文档数l为m与n的和。当特征词a集中出现在第一类文档中,即m数值较大,当m大的时候,l也大,由公式(1)可得IDF的值变化较小甚至可能不变,这表示特征词a不具有很好的类别区分能力[10]。但是实际上,特征词a较为集中地出现在第一类文档中,此时特征词a可以用来代表第一类文档,所以特征词a应该被赋予较高的权重,可以作为该类文本的特征词,以区别于其他类文档[12]。
不仅如此,当特征词在各类别中是均匀分布时,该特征词不具有很好的类别差异,不能代表类别,应该赋予较低的权重。但是由公式(2)计算的TF-IDF权重值却很高,这并不符合实际情况。这是TF-IDF的一个不足之处:没有考虑特征词在类间分布情况[13]。
最后,TF-IDF对于特征词在类别内部的分布情况也缺乏考虑。如果一个特征词均匀分布在类内的各个文本中,则表明该特征词能很好代表该类别,分类能力较强,在将文本向量化时应该赋予较高的权重[14]。这是TF-IDF另一个不足之处:没有考虑特征词在类内分布情况。
1.3 传统CHI统计方法
CHI统计方法作为常用的特征选择方法,特征选择效果比较稳定[15]。CHI统计方法是先假设特征项w与类别c之间具有非独立关系,然后计算具有一维自由度x2分布的值[16],CHI统计量x2值计算公式如公式(3)所示:
(3)
其中,A表示包含特征词w且属于类别c的文本数,B表示包含特征词w但不属于类别c的文本数,C表示属于类别c但不包含特征词w的文本数,D表示既不包含特征词w也不属于类别c的文本数,N表示文本总数[17]。x2(w,c)的值用来度量特征词w和类别c之间的相关性。特征词w与类别c相互独立时,x2(w,c)=0。w与类别c的相关性越强,x2(w,c)的值就越大,此时特征词w所携带的与类别c相关的信息量就越多,特征词w越有可能属于类别c。
1.4 传统CHI统计方法的不足
美国卡内基梅隆大学的Yang等人[18]针对文本分类问题,对IG(Information Gain)、DF(Document Frequency)、MI(Mutual Information)和CHI等特征选择方法进行了比较,得出IG和CHI方法分类效果相对较好的结论。但CHI方法仍然存在一些问题:对于低频词所赋予的权重较大,不能很好地过滤低频词中的噪音词,无形之中增大了低频词的权重,使其受低频词影响较大,导致分类准确性不是很好[19]。
CHI方法只考虑了特征词在文档中出现的频数,没有考虑到低频词的影响,增大了低频词的权重。如果一个特征词集中出现在某一类文档中,则计算出来的权重会比较小,有可能会在特征选择时被过滤掉,但该特征词往往具有较好的分类能力。
2 改进特征选择的方法
2.1 TF-IDF权重计算方法的改进
由上章可知,传统TF-IDF权重计算方法忽略了特征项在类别之间的分布情况[20],特征词的卡方统计值能够很好地对特征词的分类能力以及特征词在类别之间的分布信息进行描述,且卡方统计值与其分类能力成正比。一个特征词的卡方统计值越大,则说明该特征词与类别的相关度越大,所携带分类信息越多[21]。所以,针对TF-IDF权重计算方法不能很好表征特征词在类别之间的分布情况以及只出现在某一类文本的不足,引入类频因子α并结合卡方统计方法CHI来更好地描述特征词在类别间的分布信息,进而提高其分类能力。引入的类频因子α公式如下:
(4)
其中,f(w,ci)表示在类别ci的文档中,包含特征词w的文本数,f(ci)表示类别ci的文本总数,f(w,cj)表示在除类别ci的其他类别文档中,包含特征词w的文本数。加入类频因子后特征词权重改进方法如公式(5)所示:
W′=α×TF×IDF×x2(w,c)
(5)
由公式(4)、公式(5)可知,引入了类频因子并结合使用卡方统计方法的TF-IDF权重计算方法考虑到了特征词在类别间和类别内分布的缺陷,可以将那些在类别间分布均匀但并不具备类别区分能力的特征词和在类别内集中分布的特征词赋予较低权重,降低噪声词影响,有效地提高了TF-IDF权重计算的准确性。
2.2 CHI统计方法的改进
CHI方法对于低频词所赋予的权重较大,不能很好地过滤低频词中的噪音词,只关注于特征词在类别中是否出现,导致分类准确性不是很好。针对CHI方法的这一不足之处,引入词频因子β进行调节,β的计算方法如公式(6)所示:
(6)
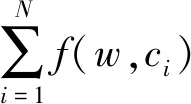
词频因子β表示在某个特定类别文档中特征词w出现次数和在所有类别文档中w出现次数之比。β越大,表示该特征词在各个类别之间的类别差异度越大,具有越好的分类能力。反之,β越小,该特征词越有可能是出现均匀的噪声词,应赋予较低的权重。
2.3 最终改进后的特征选择方法
类词因子λ由公式(4)和公式(6)计算可得:
λ=α×β
(7)
则加入类词因子并结合卡方统计的TF-IDF权重计算方法如公式(8)所示:
W″=λ×TF×IDF×x2(w,c)
(8)
3 实验结果与分析
3.1 实验数据来源
本文以对话题数据分类为例,数据为青岛市社区网格居民使用APP提交的话题数据,这些数据均为较短文本且数据量较少,将这些数据人工按问题反馈、宣传通知、知识询问分成3类,类别之间的语料数目不平衡是影响分类准确率的一个因素,所以将数据分为平衡语料集1和非平衡语料集2。表1、表2为2个语料集各类文档的选取情况。

表1 平衡语料集1中数据选取情况
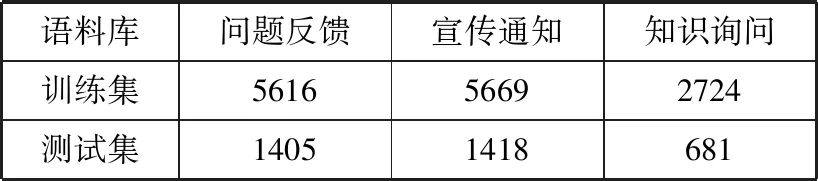
表2 非平衡语料集2中数据选取情况
3.2 分类器
本文使用XGBoost(eXtreme Gradient Boosting)分类器来训练和测试数据。XGBoost是陈天奇等人[22]开发的一个开源机器学习项目,源于梯度提升框架,但是比其模型更加高效,优化方面包括算法的并行计算、近似建树、对稀疏数据的有效处理以及内存使用等方面,使得XGBoost比现有的梯度提升算法模型至少有10倍速度上的提升并且可以处理回归、分类和排序等多种任务。
3.3 评价指标
本文实验采取准确率、查准率、查全率和F1值作为评价实验分类效果的主要指标。表3为分类结果混淆矩阵。

表3 分类结果混淆矩阵
3.3.1 准确率
准确率A(Accuracy)是被预测为正确类别的文本数占总预测文本数的百分比,其计算方法如公式(9)所示:
(9)
3.3.2 查准率和查全率
查准率P(Precision)是指被预测为某一类别的文本中真正属于此类别的文本数所占百分比,主要考虑分类准确率。其计算方法如公式(10)所示:
(10)
查全率R(Recall)是指在原本为某一类别的文档中,分类正确的文本数所占百分比,主要考虑分类的完整性。其计算方法如公式(11)所示:
(11)
3.3.3F1值
F1值(macro_F1)常用作为度量分类的总体指标,该值综合考虑查全率和查准率,其一般形式的计算方法如公式(12)所示:
(12)
3.4 实验结果
实验中各个方法表示为:E1为传统TF-IDF权重计算实验;E2为文献[8]提出传统CHI特征选择+TF-IDF权重计算的实验;E3为引入词频因子后CHI特征选择+TF-IDF权重计算实验。E4为文献[7]提出的基于类别来改进的CHI特征选择+TF-IDF权重计算的实验。E5为本文引入类词因子后CHI特征选择+TF-IDF权重计算的实验。
分类类别为:0表示为问题反馈;1表示为宣传通知;2表示为知识询问。
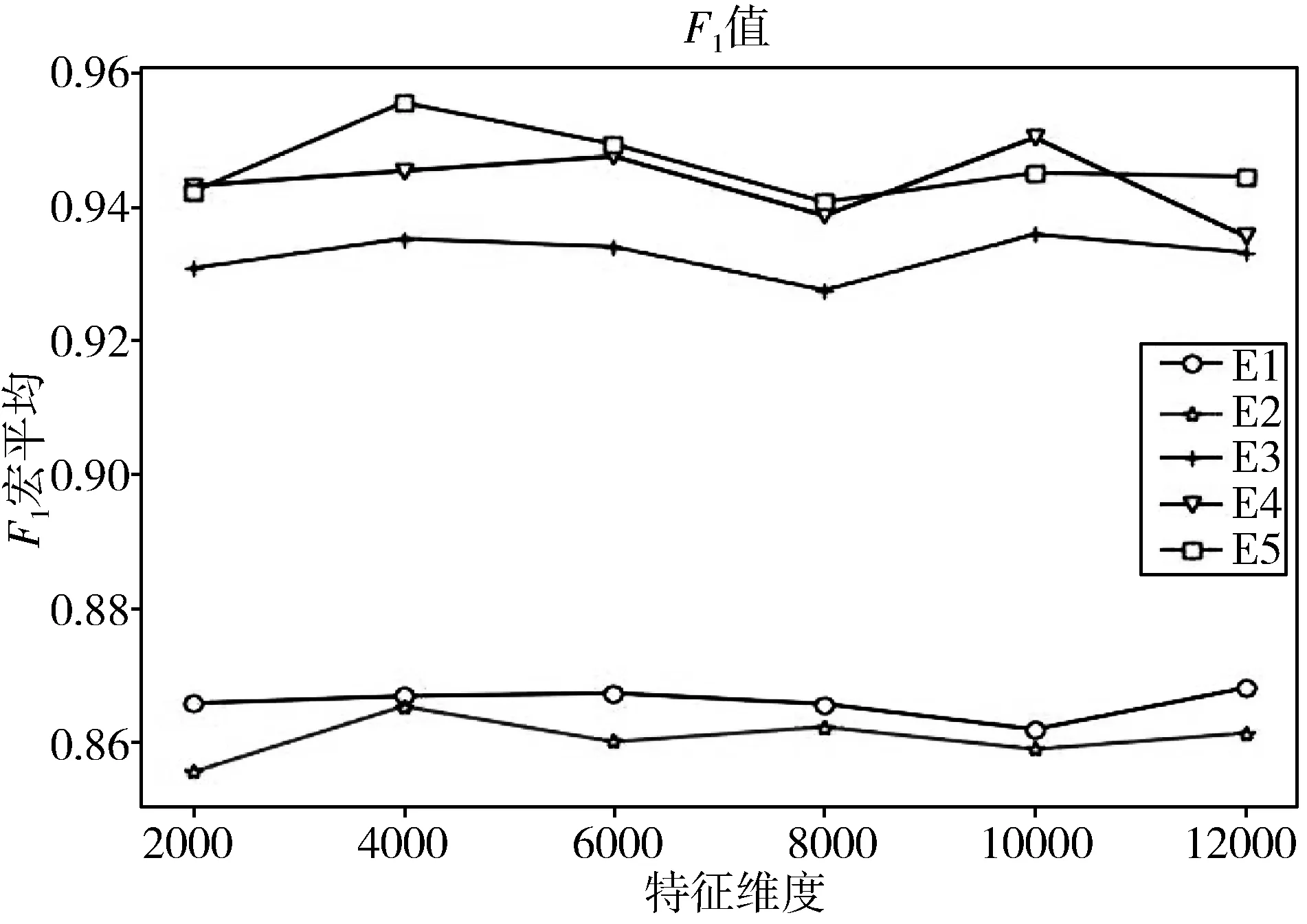
图1 在平衡语料集1中,不同特征维度时不同特征选择方法的F1值
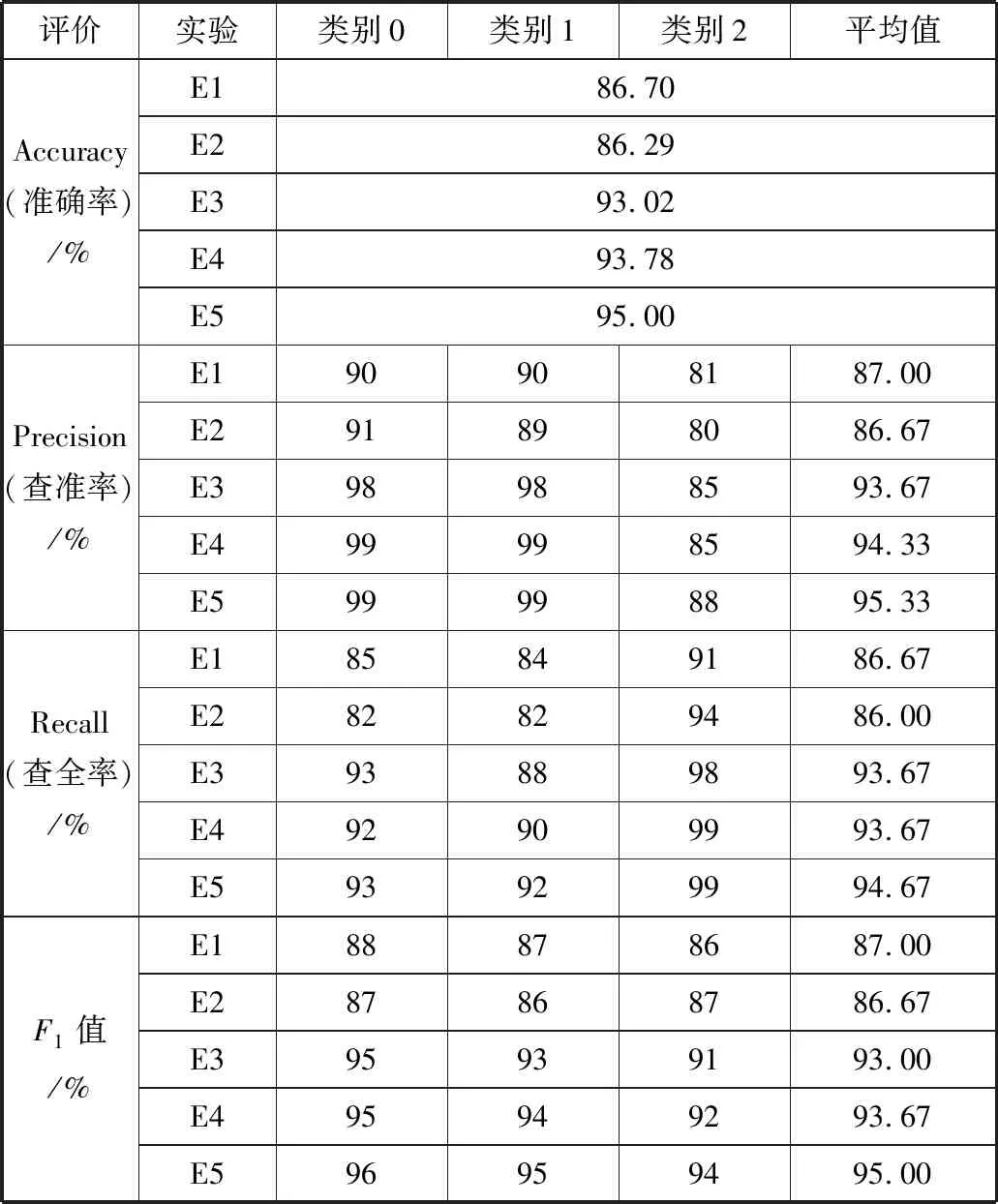
表4 在平衡语料集1中,当特征维度为4000时不同类别的XGBoost分类的评价标准
如图1所示,在平衡语料集1中,当设定的特征空间的维度由2000向4000逐渐增大时,F1值也逐渐增大。特征维度为4000时,E1、E2、E3、E5达到F1最大值86.8%、86.7%、93.7%、95.6%,E4的F1值还在持续上升未达到最大值,此时E5比E1、E2、E3分别高出8.8、8.9、1.9个百分点,当特征维度从4000继续增大到8000时,因为特征词集开始出现小部分冗余的特征,E1、E2、E3、E5的F1值开始下降,引入类频因子的E4与E1、E2、E3的F1值差距较大,但始终低于E5。当特征维度从8000继续增大时,E1、E2开始下降,E3、E4、E5开始上升,但低于之前的F1值,此时特征词集已经有了部分冗余。平衡语料集1中特征维度为4000的XGBoost分类评价标准见表4。
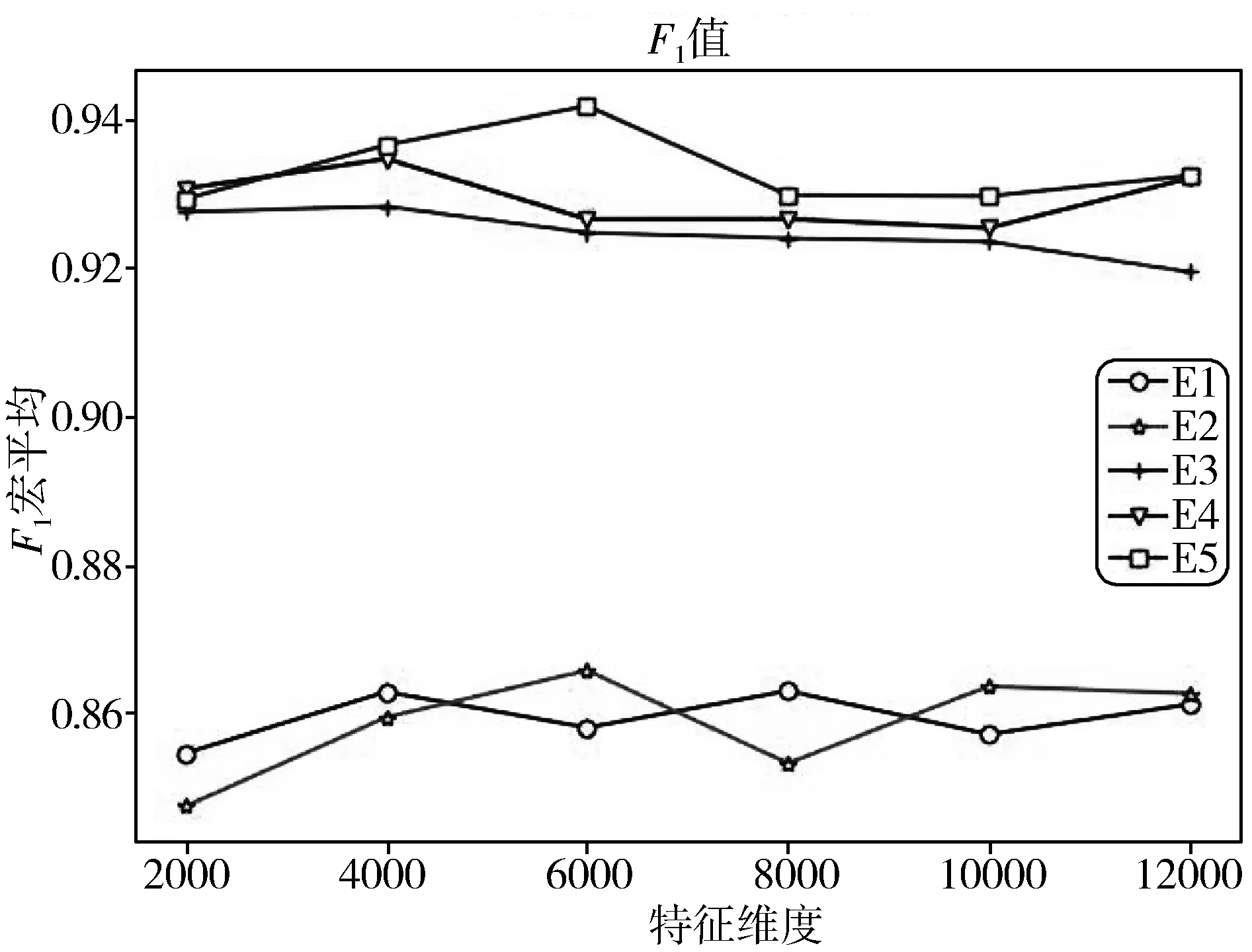
图2 在非平衡语料集2中,不同特征维度时不同特征选择方法的F1值
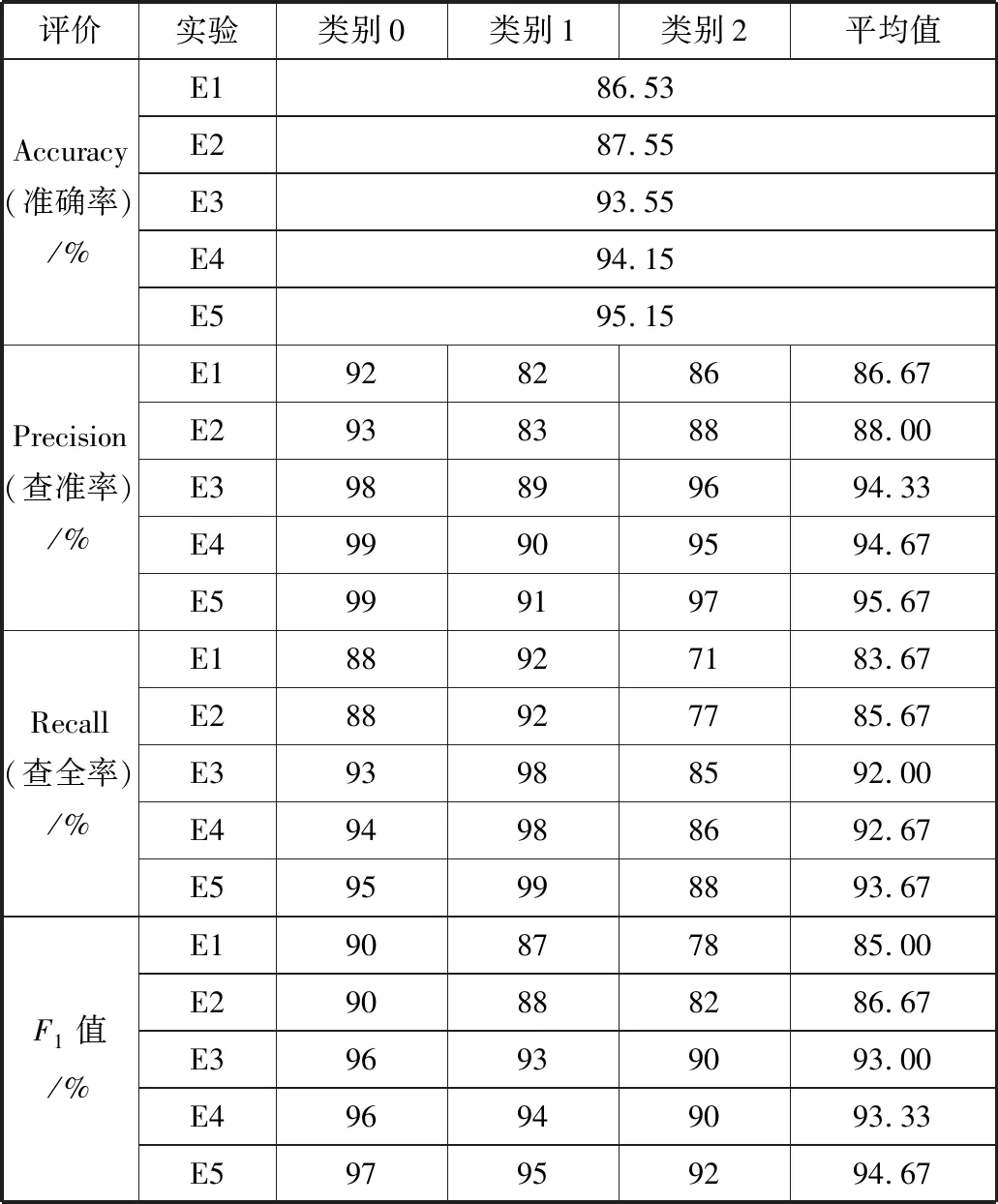
表5 在非平衡语料集2中,当特征维度为4000时不同类别的XGBoost分类的评价标准
如图2所示,在非平衡语料集2中,当设定的特征空间的维度由2000向4000逐渐增大时,F1值也逐渐增大。特征维度为4000时,E1、E3、E4、E5达到F1最大值86.8%、92.5%、93.5%、93.8%,E5的F1值还在持续上升未达到最大值,此时E5均高于E1、E3、E4,当特征维度从4000继续增大到6000时, E2、E5的F1值达到最大值,引入词频因子的E3与E1、E2的F1值差距较大,引入类频因子的E4比引入词频因子的E3也有较大提高。当特征维度在4000到12000之间时,E5始终高于其他方法,足以表明此方法在非平衡语料集中,具有较好分类准确性。特征维度为4000时,较多方法取得较好效果。非平衡语料集2中特征维度为4000的XGBoost分类评价标准见表5。
所以本文选取4000作为在平衡和非平衡语料集中进行对比实验较好的特征维度。
在选取4000作为特征维度后,根据表4和表5,在平衡语料集和非平衡语料集中比较各个方法的F1值可以发现,E3、E4、E5明显高于E1和E2,因为在特征选择时,TF-IDF只考虑词频和位置特性不能达到理想的分类效果,没有排除在类别间出现次数较多但均匀出现在各个类别和在类别内集中分布无法代表该类别等这些情况以及CHI特征选择方法增加了低频词的权重,使E1、E2结果与E3、E4和E5方法得到的结果差别明显。由图可知类频因子和词频因子很大程度上弥补了传统TF-IDF和CHI统计方法的不足,尤其是词频因子提升较大。文献[7]用类别和词频因子改进CHI统计方法后增加了对于类内和类间特殊分布情况的考虑,使得E4对于E1、E2、E3分类能力提升明显。本文提出的类词因子明显比类别和词频因子以及其它方法能更好地弥补之前提出的不足,具有更好的泛化能力。
综上所述,本文提出的方法能有效改善传统CHI和TF-IDF的缺陷,过滤掉低频词语,改善类别间和类别内不同特征词的权重,使得分类效果更好,性能更稳定。
4 结束语
特征选择是文本分类过程中至关重要的一步,特征选择方法能否选择有效的特征词来减少特征空间维度,直接影响了分结果的准确性[23]。本文引入类词因子来改进CHI特征选择方法和TF-IDF权重计算方法,并将其两者结合,同时考虑低频词的影响和类内、类间的特征词特殊分布情况,使其分类效果明显提高。该方法还有很多方面可以提高,在后续工作中,笔者将考虑特征词的语义以及与上下文结构关系,通过这种方式对特征空间进一步降维,在减少算法时间复杂度的同时提高分类精度。
