基于循环和卷积神经网络融合的中文命名实体识别与应用
2021-06-29汪小龙吴曲宁范佳佳
汪小龙,吴曲宁,范佳佳
(安徽建筑大学 a. 机械与电气工程学院; b. 电子与信息工程学院,安徽 合肥 230601)
0 引言
互联网的迅速发展导致文本信息量呈指数级增长,信息抽取技术旨在从这些海量的文本信息中挖掘出有价值的关键信息.命名实体识别作为信息抽取的重要子任务,受到了广大国内外研究者的关注.命名实体识别NER属于自然语言处理NLP中的序列标注问题,其任务就是给输入语句的每一个字做实体标注(如地名、机构名、人名等).
近年来,基于神经网络和基于语言模型的NER方法被相继提出.2003年,Hammerton等人[1]首次提出使用神经网络模型解决NER问题,其网络结构是单向的LSTM.2011年,Collobert等[2]利用CNN和CRF构建模型处理NER问题.2015年,Huang等[3]提出了BiLSTM-CRF模型,并加入了手工拼写特征.
相比于CNN,RNN更适合处理序列文本,但RNN会存在梯度消失问题.通常用LSTM解决普通RNN梯度消失问题,但LSTM也只是缓解这个问题,而CNN可以捕捉全局信息.对于命名实体识别任务,普通的CNN为了覆盖更多的原始信息,会加深网络的层数,最终导致模型庞大并且难以训练.为此,2016年,Yu等[4]提出膨胀卷积Dilated Convolution.膨胀卷积在标准卷积的卷积图上注入空洞,可以快速覆盖全部输入数据.虽然膨胀卷积神经网络可以获取全局的信息,却会丢失局部信息,所以本文结合LSTM和DCNN的优点来解决处理长文本序列的问题.
中文汉字存在多义性,传统词向量(Skip-gram、CBOW等)无法表征汉字的多义性,而语言模型可以预训练词表征解决一词多义问题.Peters等[5]利用LSTM构建ELMo语言模型.2017年,Vaswani等[6]提出了Transformer网络结构,其提取特征信息能力强于RNN.2018年, Devlin等[7]利用Transformer构建的BERT模型比Radford等[8]提出的GPT模型在表征汉字语义方面效果更好.由于BERT模型的有效性,2019年,杨飘等[9]提出BERT-BiGRU-CRF模型,王子牛等[10]使用BERT-BiLSTM-CRF模型来解决中文NER问题,但这2个模型只用了单一的循环神经网络.
本文提出的BLDC-NER模型可以较好地解决长序列和汉字多义性问题.命名实体识别是自动构建知识图谱的关键任务,其研究主要用于金融和医疗等领域.本文将BLDC-NER模型应用在建筑施工安全领域,实现该领域实体的自动识别.
1 BLDC-NER模型
1.1 BLDC-NER模型结构
BLDC-NER模型整体结构如图1所示,模型由3部分构成,分别是BERT层、BiLSTM-DCNN层以及解码层.
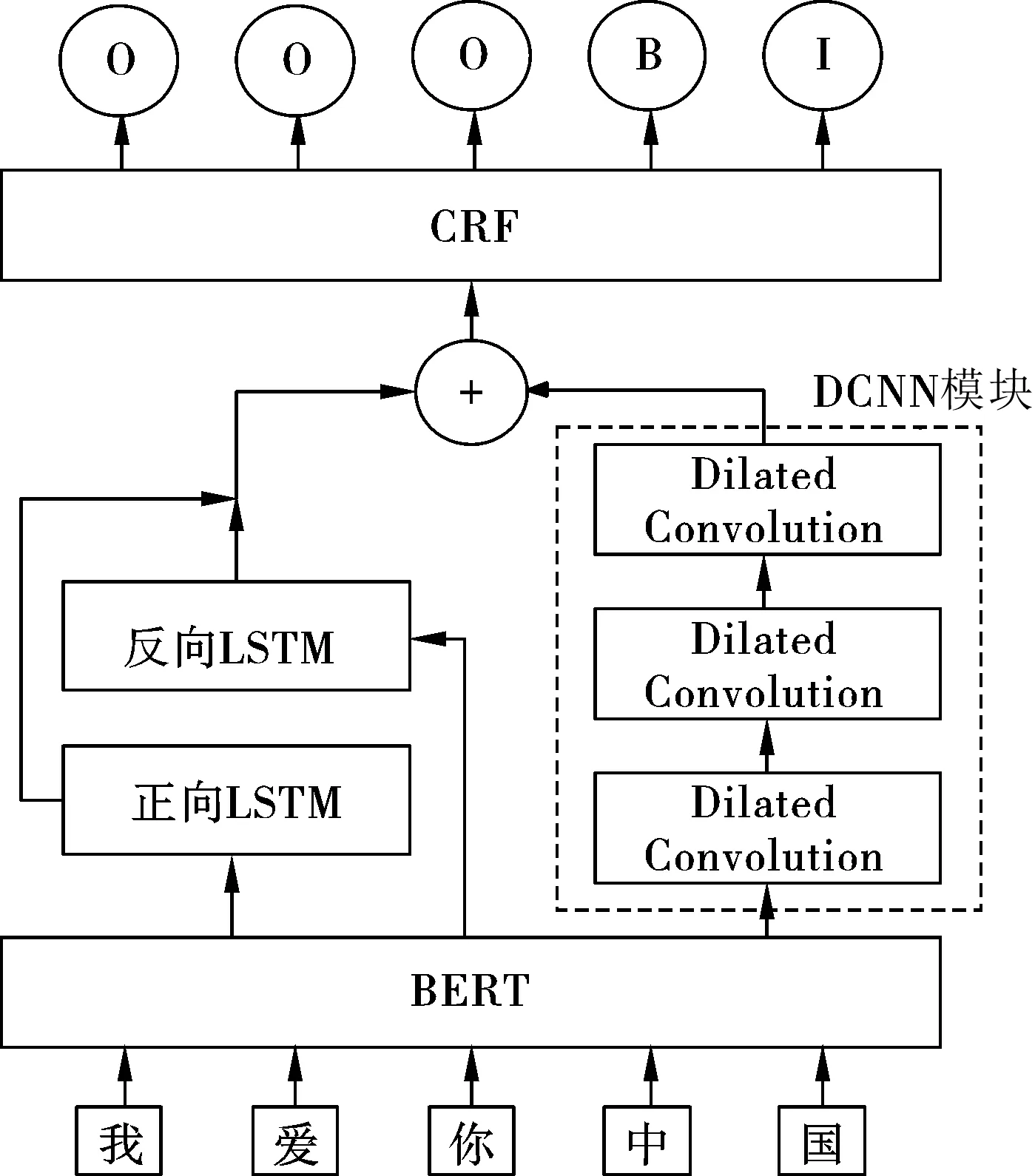
图1 BLDC-NER模型整体结构
模型首先利用BERT层对输入文本中每个字符进行编码,获取每个字符的动态语义向量.接着利用BiLSTM-DCNN层对字向量序列进行进一步语义编码,BiLSTM可以捕捉当前字符的上下文时序信息,DCNN模块可以获取输入文本的全局信息,将两者编码后的向量融合,使得模型既能获取文本的上下文时序信息,也能捕获输入文本的全局语义特征,输出的语义编码则包含更丰富的特征信息.最后将融合后的语义向量输入CRF层进行解码,CRF层可以学习标签之间的约束信息,从而提升最终的预测结果.
1.2 BERT层
BERT采用Transformer的编码器作为特征抽取器,通过遮掩语言建模和预测句子间关系来构建语言模型.遮掩语言建模任务是随机遮盖每一个句子中15%的字,让模型来预测这些字,这种方法不再是简单地将正序和反序的句子编码拼接起来,而是实现了双向语义建模;自然语言处理中有些任务需要对句子进行理解,预测句子间关系训练任务是为了学习句子间的相关性.BERT模型的结构如图2所示.

图2 BERT模型结构
Transformer是一种编码器-解码器结构,其中的编码器采用了自注意力机制.Transformer编码器由输入层以及多个子编码模块组成.由于Transformer缺少循环神经网络的迭代操作,无法确定文本中每个字的位置,必须提供每个字的位置信息给Transformer.Vaswani等使用正弦函数和余弦函数的线性变换提供模型位置信息.
PE(pos,2i)=sin(pos/10 0002i/dmodel),
(1)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel).
(2)
公式(1)和(2)中pos表示句中字的位置,i指的是词向量的维度.
每个子编码模块皆由自注意力层和前馈神经网络层组成,自注意力层和前馈神经网络层后均再接个残差连接与归一化层.
Q=XWq,
(3)
K=XWk,
(4)
V=XWv,
(5)
(6)

1.3 BiLSTM-DCNN层
BiLSTM-DCNN层由BiLSTM层和多个DCNN模块组合,将两者的输出特征向量进行融合,从而使特征向量包含更丰富的特征信息.
BiLSTM是正向LSTM和反向LSTM组合,单向LSTM只能捕捉文本上文信息或者下文信息,而BiLSTM可以捕捉双向信息.
LSTM结构表示公式为
ft=σ(Wfxt+Vfht-1+bf),
(7)
it=σ(Wixt+Viht-1+bi),
(8)
ot=σ(Woxt+Voht-1+bo),
(9)
(10)
(11)
ht=ot× tanh(ct),
(12)
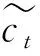
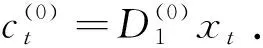
(13)
在DCNN中,随着层数的增加,参数数量呈线性增加,而感受野呈指数增加,这样便可捕捉输入全局信息.为防止过拟合,本文模型使用4个DCNN模块.
1.4 解码层
对于观测序列X=(x1,x2,...,xn)和对应的标记序列Y=(y1,y2,...,yn),条件随机场(Conditional Random Fields,CRF)在训练时,利用训练集通过极大似然估计法得到条件概率模型P(Y|X);预测时,通过观测序列求出条件概率P(Y|X)最大的输出序列.
定义打分函数为F(X,Y),如式(14),其中si,yi表示编码层输出的值,即当前标签分数;tyi-1,yi表示标签转移分数.
(14)
正确路径的概率公式为
P(Y|X)=eF(X,Y)/∑Y∈YXeF(X,Y).
(15)
对于概率问题,一般使用极大似然估计法来计算,对训练集合{(xi,yi)},其似然函数为公式为
(16)
2 数据集及评价指标
2.1 试验数据集
本文选取的数据集是2个公开中文数据集MSRA[11]、RESUME[12]和1个自制的建筑施工安全数据集,数据集大小如表1所示.

表1 中文数据集 ×103
MSRA数据集包含人名、地名和机构名3类实体,RESUME包含人名、专业、学位、职业、机构名、地名、国籍和种族8类实体.
根据知识图谱的应用需求,本文对建筑施工安全事故领域定义了6类实体,即事故名称、公司名称、施工项目名称、事故发生时间、事故发生地点和事故造成损失,如表2所示.数据集语料是从网络爬取的建筑施工安全事故案例,经过清洗、整理得到1 200条文本数据,并利用YEDDA开源工具[13]对文本采用BIO标注策略进行标注.

表2 建筑施工安全事故实体类型
2.2 评价指标
在测试过程中,只有当1个实体的边界和实体的类型完全正确时,才判断该实体预测正确.
NER的评价指标有精确率(P)、召回率(R)和F1值.具体定义为
(17)
(18)
(19)
式中:Tp为模型识别正确的实体个数;Fp为模型误检的实体个数;Fn为模型漏检相关实体的个数.
3 试验及结果分析
3.1 试验环境
本文试验所采用的硬件和软件环境如表2所示.

表3 试验环境
3.2 试验参数设置和训练方式
BERT的网络层数是12,隐藏层的维度是768,注意力机制的头数是12;每次读取的序列长度设置为256,每次训练的批次大小为16;学习率为5×10-5;丢弃率为0.1;优化器选择Adam;正反向LSTM的隐藏单元个数均为128;为防止梯度爆炸,使用了梯度裁剪技术,设置为5.
BLDC-NER模型有2种训练方式:一种是直接使用大量无标注文本预训练好的BERT模型,接下来用已经标注的数据集来对整个模型微调;另一种是有监督学习,随机初始化整个模型的参数,然后用标注好的数据集对整个模型进行训练.考虑到本文采用的数据集较小,使用第一种训练方式.
3.3 试验结果分析
为了验证基于BERT嵌入比传统词向量的效果好,同时也为了验证BLDC-NER模型的识别更准确,本文在各个数据集上进行试验比较,试验结果如表4所示.
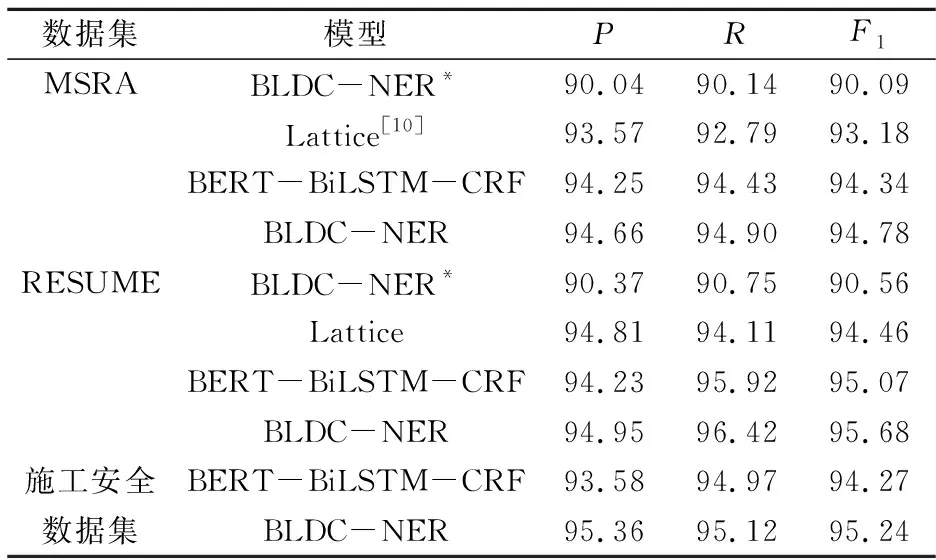
表4 各模型在3个数据集测试集上的结果 %
表4中BLDC-NER*使用传统词向量(使用Skip-gram)和分词后的词向量进行拼接表征文本中每个汉字,其在MSRA、RESUME上的F1值分别为90.09%和90.56%,比BLDC-NER在2个数据集上的结果分别低了4.69%和5.12%.Lattice模型在当时取得最佳结果,使用的是传统词向量方法,其在MSRA、RESUME上的F1值分别为93.18%和94.46%,相比于BLDC-NER模型的结果具有一定的差距.这组对比试验表明了BERT比固定词向量表征汉字的语义更好,可以使模型理解更深的语义信息.
目前常被用来解决NER问题的是BERT-BiLSTM-CRF模型,其在2个数据集上的精确率、召回率和F1值均低于BLDC-NER模型.BLDC-NER模型在MSRA、RESUME上的F1值分别为94.78%和95.68%,表明本文模型具有更佳的识别效果.
在建筑施工安全数据集中,随机将语料按照7∶2∶1比例划分,为了避免随机性划分语料造成试验误差,按照相同的比例进行5次重复试验, 对5次试验结果取平均为最后结果,试验结果如表5.BLDC-NER模型在施工安全数据集上的F1值为95.24%,识别效果优于BERT-BiLSTM-CRF模型.图3是2个模型在建筑施工安全数据集中训练的Loss值变化,可以看出BLDC-NER模型在训练过程中拟合速度更快,相比于BERT-BiLSTM-CRF模型更快达到平衡状态.

图3 在建筑施工安全数据集训练时Loss值
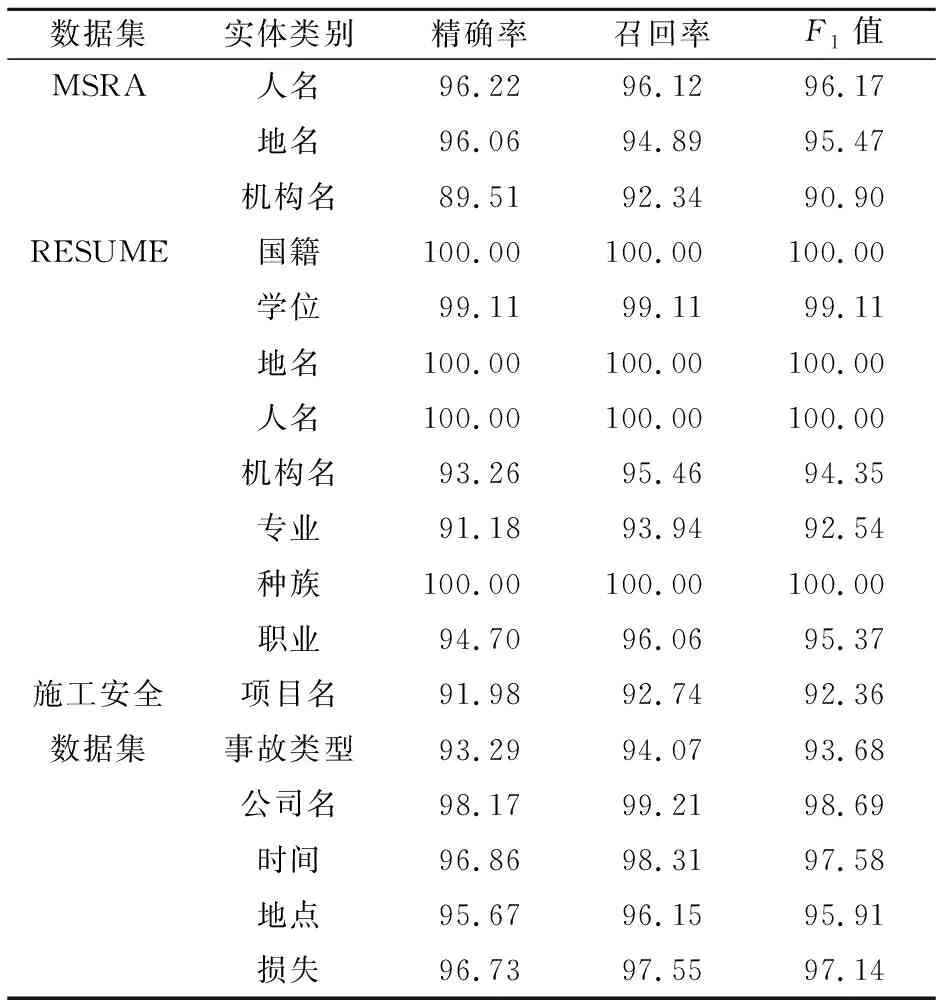
表5 BLDC-NER模型对不同类型实体的识别结果 %
从表5中可以看出:在MSRA数据集中,机构名的结果较差,因为在文本中机构名常常存在实体嵌套和缩写现象.预测错误结果见表6,例句1中,模型将“比利时通用银行”识别为机构名,这是因为该实体存在嵌套;例句2中,模型未能识别出实体,“经贸代表团”是机构名的缩写.在RESUME数据集中,机构名和专业实体识别的结果较差,因为文本中存在书名和实体嵌套.例句3中,模型将书名识别为机构名;例句4中,是职业的实体中存在专业的实体.在建筑施工安全数据集中,公司名、时间和损失3类实体识别的F1值较高,主要是因为这3类实体有明显的边界,表述形式较为相似.项目名和事故类型识别结果较差,例句5中,项目名中嵌入公司名称,导致预测错误;例句6中,由于事故类型表达形式多样化,对训练集中未出现过的实体无法正确识别.

表6 BLDC-NER预测错误的结果
4 结语
本文提出的BLDC-NER模型能够较好地捕捉长序列文本中丰富的特征信息,利用动态向量编码汉字解决传统词向量存在的缺陷,在MSRA、RESUME数据集上的F1值为94.78%、95.68%,识别结果超过了Lattice和BERT-BiLSTM-CRF等模型,本文模型在中文命名实体识别任务中具有一定的优势.在建筑施工安全领域中,BLDC-NER模型处理中文命名实体识别任务时其F1值达到95.24%,优于BERT-BiLSTM-CRF模型的识别结果,同时训练时收敛速度更快.但是,对于文本中存在实体嵌套和缩写时,BLDC-NER模型识别效果不佳.另外,本文自制的建筑施工安全数据集存在语料范围局限性以及定义的实体类别不够详细,有必要进一步扩大语料范围,定义更全面的实体类别,从而满足该领域知识图谱的构建.
