视频帧预测算法探究
2021-06-28刘志超
刘志超

摘 要:视频预测一直以来都是计算机视觉领域的热点问题,由于其广泛的实用价值和理论价值,引起了研究人员的广泛关注。该文对主流的视频帧预测算法进行了研究,首先介绍了视频预测领域的常见问题,并由基本架构对视频预测算法进行了分类,接下来介绍了该领域常用的数据集并给予评价,最后从视频预测算法的运行流程和最新的论文角度上,总结该领域算法的发展方向。
关键词: 视频帧预测;长短时记忆网络 ;自编码器 ;生成对抗网络;注意力机制;强化学习
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2021)10-0249-03
Abstract:Video prediction has always been a key issue in the computer vision field.Because of its extensive pratical and theoratical values,the video prediction technique has attracted attentions of many researchers.This paper reviews the main video prediction algorithms.Firstly,this paper introduce the common problems in video prediction,and classify many famous video prediction algorithms according to basic architectures.Then,the common datasets of video prediction are introduced and evaluated.Finally,on the basis of the process of the algorithms and the latest papers,this paper summarize the development of algorithms in this field.
Key words:video prediction; long short-term memory network; autoencoder; generative adversarial net; attention mechanism; reinforcement learning
视频帧预测(video predictin)是指通过对视频中的历史图像帧序列进行学习,从而生成未来的图像帧。在自动驾驶技术日趋成熟的今天,能够预测图象的未来帧序列变得越来越重要。目前视频预测已经在无人驾驶、机器人导航、人机交互等广泛的应用领域取得了一定的成功,如预测未来的活动和事件[1]、目标的位置预测、交通中行人的轨迹预测、自动驾驶等。
轨迹预测是视频中运动预测的关键,预测系统不仅需要知道目标周围对象的当前状态,还需要知道它们未来可能的状态。在视频预测研究兴起之前,物体运动轨迹预测更加受学术界关注。二者的区别与联系在于:运动预测一般是指从静态图像或视频前几帧中推断出人体动作、物体移动轨迹等动态信息;而视频预测是从静态图片或视频前几帧中直接预测未来图像。目前的,针对视频预测算法的常用评价指标为均方误差(MSE)、绝对误差(MAE)、峰值信噪比(PSNR)和结构相似性(SSIM)。前两者越小越好,后两者越大越好。
本文由常见的视频预测基本架构作为分类准则,按时间顺序回顾了现有的视频预测算法。具体结构如下:首先简要介绍视频预测领域常见的问题;之后对视频帧预测领域中的算法按照上文提及的基准进行分类;其次介绍该领域常用的数据集,并评价其特点;最后介绍改善该领域算法的新方向和视频预测算法的下一步发展与展望。
1 视频预测的常见问题
视频帧预测技术的性能在近几年逐渐改善,但是由于视频数据中存在大量的复杂信息,同时相邻的视频帧间具有较强的相关性,而传统的机器学习算法在自动标注特征信息和根据历史帧序列生成预测帧的能力方面有所欠缺,因此视频预测领域仍然存在很大的挑战,面临的挑战主要如下:
1)模糊的预测。这个问题一般是误差在循环模型中的传播造成的,而这与视频预测的固有不确定性有关。对于之前给定的一系列先前帧,存在多个平行的未来。如果不加以限制,就会产生一个模糊的预测,同时这预测结果会影响后续帧传播回网络的信息,产生更大的误差。
2)高内存消耗。伴随着视频预测技术的发展,神经网络的深度逐渐增加,模型高内存消耗的特点逐渐凸显。而这一特点极大地限制了他们的应用场景和降低预测效率。
3)预测的长期性。由于复杂的动力学和背景外观的变化,在模型架构生成較为遥远的未来帧时,由于存储单元记忆能力的限制和长期预测中主要由遮挡、照明条件变化和摄像机运动等因素造成的视觉外观可变性,未来帧可能出现与现实情况不符甚至不合理的结果。
4)无法捕捉全部分布。在上文中提到视频数据高复杂性的特点,而这直接导致了当目标对象的运动场景较为复杂时,会导致模型架构对视频前后帧间部分复杂关系的疏漏。
2 基本的算法架构
在视频预测的研究过程中,我们发现了各种架构和计算单元所组成的算法,而这些所产生的算法主要是依据以下三种基本神经网络架构发展得到的:基于自动编码器(Auto-Encoder, AE)的方法、基于生成对抗神经网络(Generate Adversarial Network, GAN)的方法,以及基于长短时记忆神经网络(Long Short-Term Memory, LSTM)的方法,如图1。
2.1 自编码器
2.1.1 自编码器思想
传统的自编码器模型主要由编码器和解码器两部分构成,通过将视频帧序列编码成为一个潜在变量,然后再利用潜在变量生成视频帧序列。
2.1.2 基于AE结构的改进
Patraucean团队通过将一种具有长短时记忆功能的卷积模块加入编码器的架构中而提出一种新的时空视频自动编码器[2],与早期的编码器和短时性记忆模块的简单连接,该模型所需的参数更少;而DeBrabandere等提出的方案中,卷积模块是用来融入编码器架构来产生滤波器生成网络[3],最终达到在模型参数不会过度增加的前提下进行自适应特征提取。同时,由于视频数据的时序特性,其算法架构大多会使用循环结构,而Lotter等人基于对循环结构中误差的传递考虑,提出了PredNet,该网络通过将预测信息与实际信息相对比来产生误差信息,再将误差信息自下而上传递回去来更新预测信息,最终减小误差信息对于预测的影响。Villegas等人提出MCnet网络,该网络在基础架构中融入了ConvLstm,创新性地将视频预测的输入分成了两个易识别的组成,即内容组和运动组。该网络可以通过从运动组编码空间区域的局部动态和从内容组编码图像的空间布局信息,最终实现将提取出来的内容信息和动作信息加入未来帧,来简化预测的工作量。与MCnet算法的拆分思想类似,Hsieh等人结合结构化概率模型和深层网络架构提出了DDPAE,将预测的高维视频拆分为组件,并将每个组件拆分为低维时间动态来进行预测,从而对视频进行良好的分解和理解,最终达到降低预测工作的复杂性的目的。FAN等人提出分层自动编码器(HRPAE),则是利用编码器编码成不同层次的卷积特征,并使用ConvLSTMs对这些特征分别建模。同时,在该架构下,编码器和解码器之间的特征信息更容易共享。
2.2 生成对抗网络
2.2.1 生成对抗网络思想
生成对抗网络的核心思想在于以零和博弈的方式进行交替训练。该网络由一个生成器(generator,G)和一个判别器(discriminator,D)组成。在视频预测中,生成器在鉴别器网络的指导下,基于输入像素的联合分布模型而无需进行任何其他独立假设来生成未来帧。
2.2.2 基于GAN结构的改进
基于生成对抗网络的方法通常是利用GAN中的生成器作为预测模型来实现对未来视频帧的预测。Liang等为了使生成的未来帧与视频序列中的像素流一致,提出了一种双重运动生成对抗网络模型[4],来通过双重学习机制来学习预测未来帧。在该学习机制下,原始的未来帧预测和后续的未来流预测形成一个闭环来反过来纠正现实数据,来使生成的信息相互反馈,从而实现更有效的预测。这类方法中,由于其融入的对抗思想,能够较为清晰地预测未来的视频帧,但是处于长期预测的任务中时,视频帧质量会迅速下滑。而Xiong等人提出运用多个阶段GAN来生成和细化原始帧。类似的思想还有,Bhattacharjee等人基于对时间维度上的考虑,提出了两个基于归一化互相关和成对对比散度的目标函数和一个多阶段生成对抗框架,并通过两个阶段的生成对抗网络来生成清晰的未来帧。Lee等人提出的随机对抗生成网络(SAVP),通过结合对抗性损失和潜在变量等方法来进行预测,在GAN架构的基础上加入变分自编码器来观察真实的视频帧潜在编码,最后结合ConvLstm来进行视频帧预测。Ying等人[5]提出差异导向的生成对抗网络,通过引入双路径网络的方式,来尽可能地保留未来帧的细节信息。一条路径生成未来帧的粗略结果,另一条路径则是用来生成历史帧和预测帧之间的差异图像。该模型的特点在于摆脱了从随机噪声中生成图像的局限性,而创新性地从对相邻帧之间的差异得到灵感,从而以历史帧序列的分布为基准进行像素偏移。其价值在于在未来帧的SSIM等指标合适的前提下,使生成的帧可以具有精细的细节。
2.3 长短时记忆网络
2.3.1 Lstm的思想
Lstm模型通过有选择性地丢失存储的信息,并将选择出来的信息与后续输入的时序信息相结合来完成对时间序列数据的处理与分析,同时也由于视频数据的特点,许多视频帧预测算法都是在该模型上发展而来的。
2.3.2 基于Lstm结构的改进
早期,由Lotter等人将卷积模块与传统的LSTM模型结合,而提出了预测神经网络[6],该网络能够对每一层都进行局部预测,并且将预测的偏差向后传递,最终实现对视频序列进行预测。Oliu[7]等人创新性地提出了GRU计算单元和一种递归结构,通过叠加多层ConvGRU结构形成一个具有双重门控循环单元的循环自动编码器。同时,由于编码器和解码器的权重共享,减少了计算成本,并且达到了较好的预测效果。与Oliu的信息共享思想类似的,Wang等人先提出PredRNN,其架构中的每一个LSTM单元的记忆状态并不独有且允许不同单元的内存状态跨层,其信息可以垂直和水平地穿过所有的RNN堆叠层,同时该网络可以同時提取和记忆空间信息和时间信息,后来在该算法的基础上提出了一个梯度公路单元,来缓解梯度传播的困难。接着,Wang等人提出了MIM模块来利用相邻循环状态之间差分信息,最终实现处理时空动力学的非平稳和近似平稳变量。对于之前提到的架构,虽然都可以进行较长的时间预测,但是由于架构内部的计算单元提取特征能力较弱而受一定局限。最近,Wang等人利提出将3D-Conv单元集成到循环神经网络,来使网络更好地感知运动,同时,存储更好的短期特征。该网络通过门控自我注意模块来提升其长期记忆的能力,并得以在多个时间点回忆存储记忆,所以对于长时间的干扰有着很好的纠正能力。
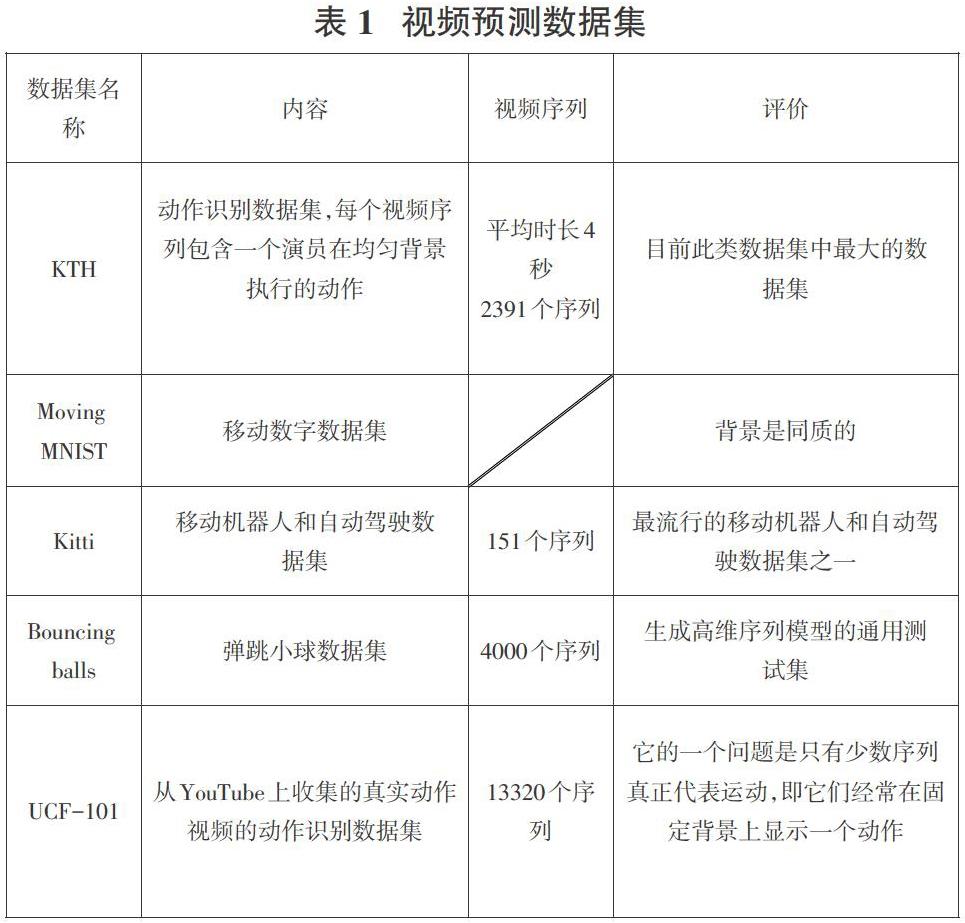
3 常用数据集
由于常见的视频预测算法所需要的输入大多是一系列有着连续变化关系的视频帧,所以数据之间有着逻辑关系的数据集大多比较适合作为该领域的使用数据,例如人的运动姿态、汽车行驶鸟瞰图、3维弹球运动等。
KTH数据集记录了一个演员在相同背景下進行运动的视频数据。该数据集包含包括2391个平均持续时间为4秒的视频序列,视频序列中演员的动作可以分为6种。分辨率下采样至160 × 120像素。
移动数字数据集为一个人工合成数据集。其记录的数据为两个不同的阿拉伯数字伴随着时间的推移,在同质的黑色背景下各自进行连续运动的视频序列。该数据集的分辨率为64×64像素。
Kitti数据集是一个移动机器人和自动驾驶数据集。该数据集有151个视频序列,采样至1392×512像素。他是由数小时的交通场景组成,用各种传感器记录得到的,例如RGB、3D激光扫描仪等。
弹跳球数据集记录的是三个弹球在盒子中跳动的情况,它是生成高维序列模型的通用测试集。同时,该数据集共同包含4000个视频序列,其采样分辨率为150×150。
4 视频帧预测算法改进方向
从上文中,可以看出在改善视频预测网络结构的方向上,学者已经做出了许多成果,并取得不错的成效。这一章节,将介绍有别于之前专注于改善模型架构的算法提升方向。
自然语言任务转换模型(Transformer),近年来在计算机视觉领域取得了许多令人兴奋的结果。该模型由于利用了注意力机制来编码输入中的依赖关系而得到了很高的表达能力。同时由于编码特征的一般化,该模型在视频预测、动作识别、图像超分辨率等领域都得到了广泛的应用。Zhong等人提出的基于行为条件的未来帧预测模型,该学习框架通过将强化学习与视频预测模型融合来解开可控对象,其特点在于利用行为条件进行未来帧预测,并使用行为信息来学习可控对象的解开。其模型的运行方式为将预测任分为了三部分,分别是预测相关动作信息、图像的背景信息和掩模图像信息,最终达到生成未来帧的目的。Kim等人提出了一种检测任意对象的关键点算法,该算法被训练成以无监督方式检测任意对象的关键点。然后,在此算法的基础上,提出了一种新的从输入上进行处理的视频预测算法。其缺陷也十分明显,由于该算法是基于关键点展开的,所以它的目标对象更适合于在运动时会产生关键点的人等对象。Lin等人提出SA-ConvLstm模型,其特点在于提出了一种新的自我注意记忆(SAM)来记忆时空领域的长期特征。较之于之前的算法模型,在MSE等指标上有了突破。Lange等人[8]同样在算法中加入注意力机制,而提出了SAAConvLstm和TAALSTM,来解决视频预测过程中的移动对象显著模糊和消失的问题。
5 结论
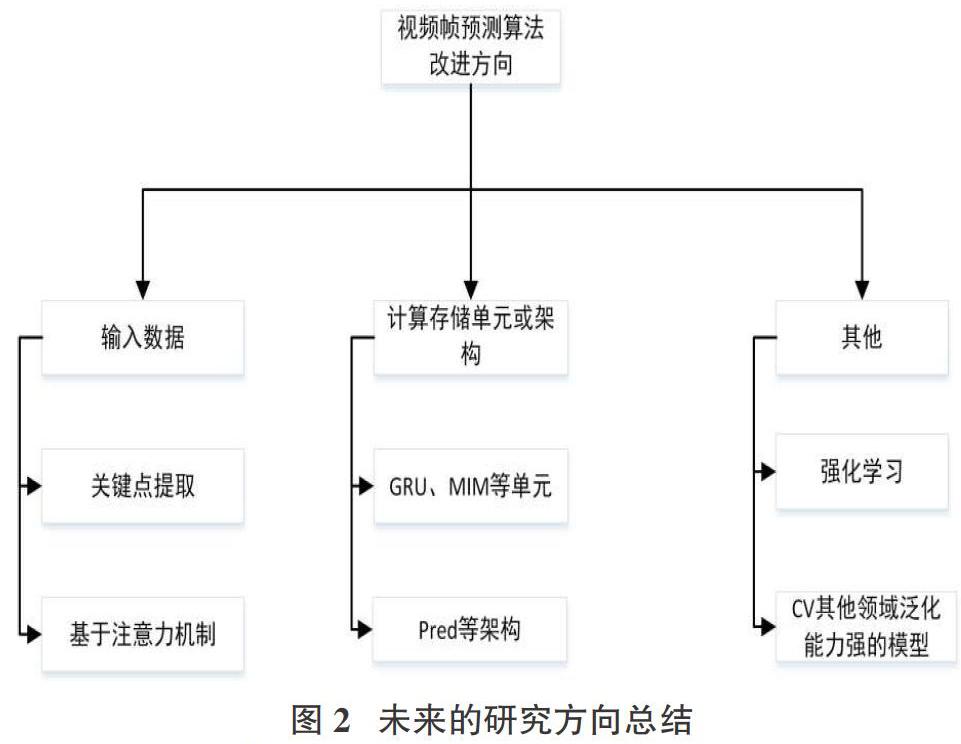
通过本文的讨论,未来的研究方向可以从以下几个方面来进行,具体如图2所示:
在视频帧的输入端上,为了捕捉视频数据中复杂且长期的空间关系,可以从预先处理输入数据开始,例如上文提到的关键点和注意力层面,未来可以研究如何针对不同的运动对象和应用场景来创造合适的视频数据预处理方法;视频预测的架构是视频预测领域一直着力研究的方向,未来学者可以提出更加合理的计算单元来生成准确率更高的未来帧;融入其他计算机视觉领域算法到视频帧预测领域也是未来发展的前景,上文中提到的transformer模型本为自然语言处理领域提出的算法,但由于其良好的泛化能力,在众多CV方向得到了广泛应用。本研究团队未来欲将强化学习的知识运用到视频预测领域,期待产生更加惊喜的效果。
参考文献:
[1] Hoai M,de la Torre F.Max-margin early event detectors[J].International Journal of Computer Vision,2014,107(2):191-202.
[2] PATRAUCEAN V, HANDA A, CIPOLLA R. Spatio-temporal video autoencoder with differentiable memory[C].ICLR,San Juan, Puerto Rico,2016.
[3] Brabandere B D,Jia X,Tuytelaars T,et al.Dynamic filter networks[EB/OL].2016.
[4] Liang X D,Lee L,Dai W,et al.Dual motion GAN for future-flow embedded video prediction[C]//2017 IEEE International Conference on Computer Vision (ICCV).October 22-29,2017,Venice,Italy.IEEE,2017:1762-1770.
[5] Ying G H,Zou Y T,Wan L,et al.Better guider predicts future better:difference guided generative adversarial networks[EB/OL].2019.
[6] LOTTER W, KREIMAN G, COX D. Deep predictive coding networks for video prediction and unsupervised learning[C] ICLR., Toulon, French.
[7] Oliu M,Selva J,Escalera S.Folded recurrent neural networks for future video prediction[C]//Computer Vision - ECCV,2018: 745-761.
[8] Lange B,Itkina M,Kochenderfer M J.Attention augmented ConvLSTM forEnvironment prediction[EB/OL].2020.
【通联编辑:唐一东】
