基于深度神经网络的口罩佩戴检测
2021-06-28刘国明江巨浪严华锋
刘国明,江巨浪,查 兵,任 钰,严华锋
(安庆师范大学电子工程与智能制造学院,安徽安庆 246133)
2020年初新冠肺炎疫情蔓延全球,对人类生命健康构成严重威胁,在公共场所佩戴口罩是预防疫情传播的最有效措施。采用深度神经网络自动检测口罩佩戴,能够弥补人工管控的不足。在新冠肺炎疫情发生之前,还没有专门研究口罩佩戴检测算法的文献,但在人脸检测、目标检测和物体分类等方面已经提出了很多算法。2019年,Insightface团队提出了基于one-state的RetinaFace算法[1],该算法具有较高的检测精度和较快的检测速度。牛作东等[2]通过改进RetinaFace人脸检测算法,实现对口罩佩戴的有效检测,该方法用于自建的3 000 张图片数据集,口罩目标检测准确率为87.7%,但该算法需要检测到眼、口、鼻等特征,存在对小目标和戴口罩侧脸漏检的不足。本文基于ResNet-34深度神经网络模型[3],研究网络输入图片的预处理方法、网络模型的最优学习率和批数据量大小(batch size),对自建的包含12 000幅口罩佩戴图片样本集进行训练。相比于文献[1]的算法,口罩检测准确率得到提高,对小目标和侧面戴口罩人脸漏检的不足得到改善,并且获得一个性能优良的口罩佩戴检测器。
1 理论模型
1.1 残差网络
一般情况下网络越深,检测效果越好,但计算量大,网络很难训练成功。因此,对于深度神经网络难以训练的问题,微软实验室提出了残差网络模块(Residual)并丢弃了dropout机制。引入残差网络解决了超深网络参数优化困难,提高了超深网络的分类准确率,其内部的残差块使用了跳跃连接(shortcut),一定程度上解决了在深度神经网络中的梯度消失问题。ResNet-34网络拥有多个残差模块,对单独一个残差模块来说,网络输入假设为x,希望学习到的函数为H(x),在实验中F(x)相比于H(x)更容易优化,其中H(x)=F(x)+x。图1为残差网络模块示意图。
由图1可知,跳跃连接并没有增加额外的网络参量,所以不会增强原网络的复杂度。但加入了跳跃连接后,训练过程中底层的误差可以通过跳跃连接向上一层传播,减弱了层数过多造成的梯度消失现象,保证了网络训练精度。

图1 残差网络模块
1.2 批归一化(Batch Normalization,BN)
BN就是对每一批训练数据进行标准归一化操作,使得这批数据都满足标准正态分布。在BN出现之前,归一化操作只在数据输入层,现在BN可对网络中任意一层数据进行归一化操作,这样每层的训练数据都是被优化的,网络模型自然就更好。实验结果表明,BN在一定程度上减少了梯度消失和梯度爆炸,加速了模型的收敛速度,获取了更好的网络模型[4-6]。
2 实验设计
2.1 口罩佩戴图像训练集的制作
机器学习中,数据集的质量对模型的泛化能力至关重要[7]。由于没有公开的口罩数据集,本文制作了一个口罩数据集,制作过程考虑:(1)佩戴的口罩外观形式尽量多样化;(2)选取多种视角口罩图片;(3)拉宽口罩在整个图片所占的比例;(4)负样本中选取遮挡口鼻部位的图片;(5)负样本选取有类似口罩的遮挡物;(6)加大图像长宽比范围;(7)大量选取自然场景下拍摄的图片。部分样本如图2所示。所使用的图片数据集大部分是在遵循网络爬虫协议前提下获取的,小部分是从新闻视频中截取的,还有一些为个人所拍摄的,共6 000张,戴口罩和未佩戴口罩比例约为1∶1。

图2 部分样本图片
为了防止网络过拟合,获取更优的网络模型,训练数据集应尽量大,对已有的6 000 个样本数据进一步扩充。根据数据集的特点,选取三分之一的数据作水平方向镜像;三分之一的数据作随机45度顺时针或逆时针旋转;三分之一的数据作尺度缩放,缩放比例控制在0.8~1.2范围内,最终获取的数据量为12 000 张图片。将数据集的60%作为训练集,20%作为验证集,20%作为测试集。未对图像做色彩偏移,主要因为口罩与背景存在较明显的灰度级差距,色彩偏移会使得口罩的特征不能被很好地提取,从而影响检测结果的准确率。
2.2 图片预处理方法
实验用的卷积网络输入图片大小要求为224×224,而图片在采集过程中的尺寸不固定,必须进行预处理。常规的处理方式为中心裁剪或直接按目标尺寸缩放,但是效果不是很好。中心裁剪在处理长宽比较大的图片时,会裁掉戴口罩的部位;直接缩放会导致口罩部位变形,口罩特征会被扭曲。本文处理训练集和测试集稍微有些不同,训练集采用随机缩放裁剪为224×224的尺寸,随机裁剪的目的是增强背景数据噪声,防止过拟合以达到增强模型稳定性的能力;测试集图片边界首先填充到长宽一样的尺寸,再等比例缩放到256×256的尺寸,最后再用中心裁剪的方式获得224×224尺寸的图片。
获得规定尺寸图片之后,对所有数据进行归一化,使数据服从标准正态分布,其作用是使输入数据具有相同的尺度,减少因数据相差过大而引起误差。本文数据集在R、G、B 上的期望分别为0.485、0.456、0.406,标准方差分别为0.229、0.224、0.225,3个维度均进行标准化。
未对输入图片预处理时,网络准确率最高为98.01%,但是对错误分类的图片分析之后发现,有些戴口罩没有被检测出来,如图3中1、2、4图片,这不是希望的结果。于是,采用上述预处理方法,将图片边界填充到等长宽等比例,再进行缩放、中心裁剪,处理之后图3中1~5号图片的问题得以解决,对于7号和10号用手遮挡嘴巴部位也能够正确分类为未佩戴口罩,网络准确率提升到98.41%。对于6号尺度较小的侧面口罩,9号和12号遮挡嘴巴部位图片分类仍然错误。

图3 没有进行预处理被错误识别的图片
2.3 批数据量的选择
批数据量是训练过程中每次喂给神经网络的图片数量,其大小对网络的精度有很大的影响,一般批数据量常见的取值有32、64、128、256,甚至更大。对于深度卷积神经网络而言,批数据量越大,这批数据分布越接近于整体数据集,训练效果会越好。不过更大的批数据量要求更大的GPU显存,受实验设备限制。本文实验所用显卡不足以处理256大小的数据量,故将该数值丢弃,另外选取了100和150进行测试,结果如表1所示。
由表1可以看出,当批数据量为较小的32时,准确率只有97.97%,迭代次数也比较多;当增大批数据量,准确率随之提升,迭代次数也随之下降。准确率最好的是批数据量为128时,准确率高达98.41%,当批数据量继续增加到150的时候,准确率却有所下降。因此,对本数据集的批数据量取128较为合适。
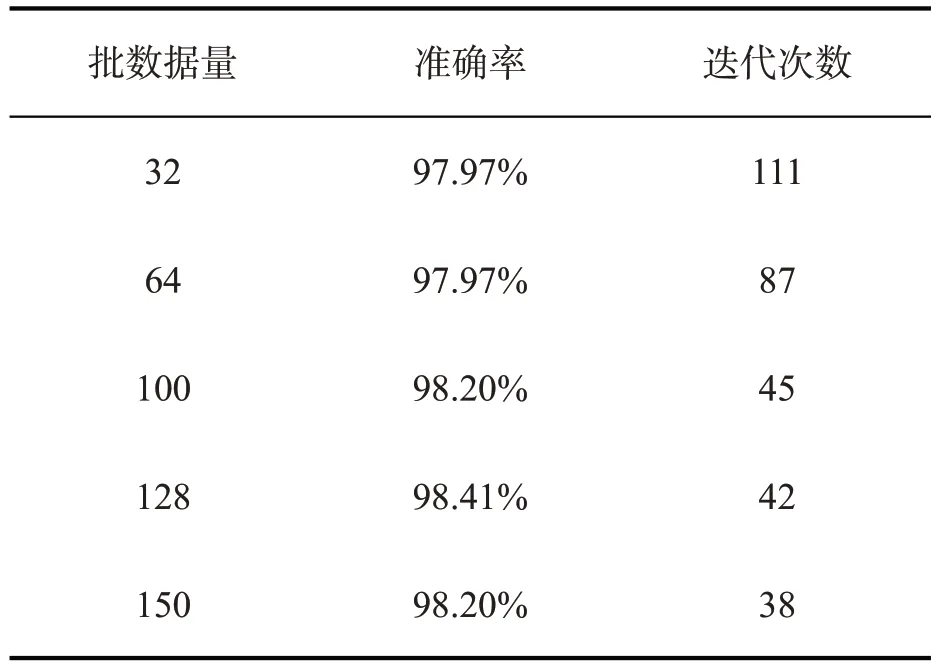
表1 批数据量对模型的影响
2.4 网络学习率的选择
网络的训练其实就是寻找最优解的过程,而学习率反映了优化过程的快慢。学习率设置过大,优化速度快,但是网络会容易跳过全局最优解,在最优解之外来回震荡;学习率设置过小,则会影响网络训练的速度,而且模型容易陷入局部最优解。基于此,进一步研究学习率对上述网络精度的影响。由于采用的是迁移学习方法,网络已经有较好的权重,学习率相对要取较小值,学习率设置和实验结果如表2所示。
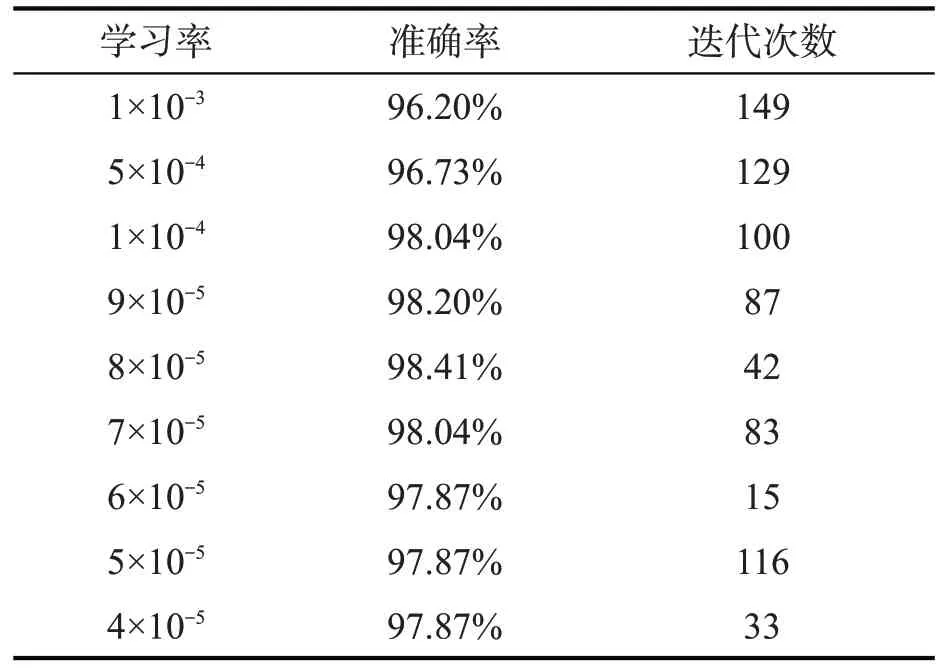
表2 不同学习率模型的准确率与迭代次数
在验证集上,随着学习率下降,准确率会上升,当学习率减小到8×10-5时,准确率达到最高,为98.41%,继续减小学习率,准确率反而会下降,网络模型只能达到局部最优解。
3 实验结果与分析
3.1 准确率分析
为验证口罩检测器模型的效果,与文献[1]的检测准确率和检测效率做了比较。在验证集上,表现最好的模型准确率为98.41%,将此模型在测试集上测试,本文检测准确率为97.25%,文献[1]检测准确率为88.5%。在文献[1]漏检结果中随机抽取了10张图片,如图4所示,这些图片本文能很好地检测出口罩的特征。分析发现,文献[1]算法是基于RetinaFace人脸特征检测,需要检测到眼、口和鼻等特征,在戴口罩的情况下,遮住了人脸部分特征,人脸检测准确率有所下降,从而口罩检测准确率也随之下降。

图4 漏检口罩图片
图4中参数c为本文检出戴口罩的置信度,置信度越高表明相关特征越容易被正确检测出来。图4中较难检测出的是(c)和(d),置信度为0.87和0.86,但也维持在较高的水平。其他图片的置信度都接近于1.00(四舍五入后的结果),说明口罩特征较容易检测出来。本文模型不但具有更高的检测精度,而且具有更高的抗干扰能力,对侧面口罩、遮挡口罩、异形口罩和花纹口罩具有很好的适用性。
3.2 检测效率
随机选取尺寸大小各异的10张图片来进行速度测试,结果如表3所示。
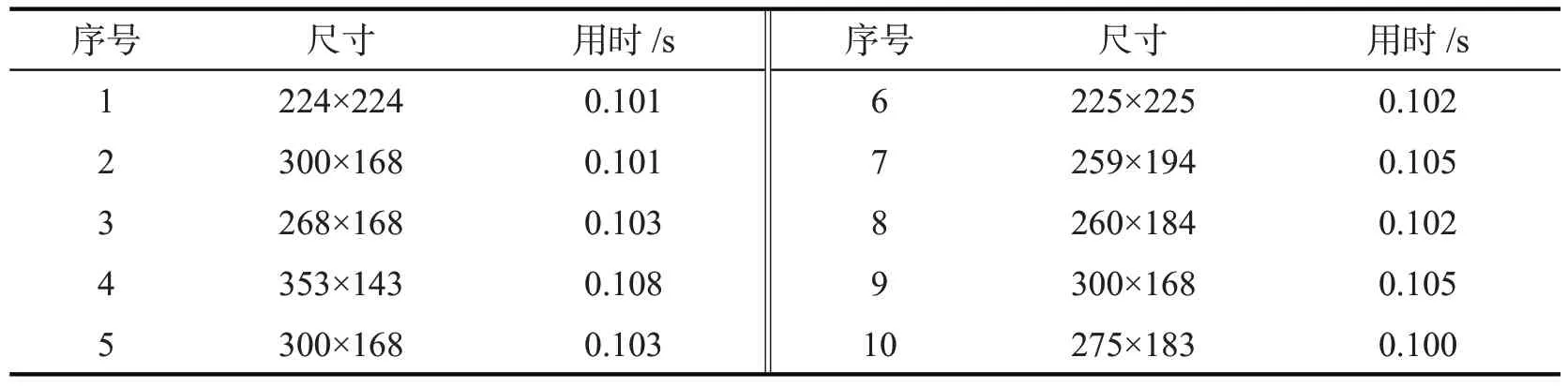
表3 检测口罩用时统计
检测用时都在(0.10~0.11)s之间,平均用时0.103 s,帧率为9.71 fps,相比于文献[1]中18.3 fps的帧率,检测效率有待提高,但9.71 fps的帧率可以达到实时检测的要求,这对在公共场所的安防监控、企事业单位楼宇的门禁处检测是否佩戴口罩具有重要的意义。
4 结束语
本文用深度神经网络实现有无佩戴口罩的检测,收集大量戴口罩图片数据,并对数据集进行有效地扩充,制作一套优良的口罩检测数据集。通过不断试验,研究了有效的预处理方法、最佳学习率和训练批数据量,获得了一个性能优良的口罩佩戴检测器,对侧面口罩、遮挡口罩、异形口罩和花纹口罩具有较高的抗干扰能力,同时拥有较高的检测准确率和检测速度,这对新冠疫情防控有较强的实践意义。
