基于机器学习方法的游客评论数据智能分析技术研究
2021-06-27马骞
马骞
(西安航空职业技术学院,陕西西安 710089)
随着互联网技术的快速发展与普及,电子商务逐渐被应用于货币交换、商品买卖与旅游服务等多个领域[1-2]。在这些领域中,由于旅游行业严重依赖于资金流动、信息传递与流通,所以如何利用高效率的信息引导普通的游客,是旅游景点提高经济效益的重要环节[3-7]。而在与互联网融合的背景下,通过借鉴淘宝等商品平台,携程网或途牛等旅游服务平台也逐渐引入针对旅游目的地的游客评价等功能,从而优化其相应旅游目的地的服务产品。然而,随着游客数量的快速增加,对于评论数据的情感分析也逐渐成为旅游服务平台亟待解决的技术问题[8]。目前,国内外的学者提出一些经典的解决方法,例如:Bo Yang 等学者通过引入机器学习方法,对互联网上的观众影评进行了准确度较高的情感分析[9];Sanjiv Das 等学者针对投资者对股票走势的评价,建立了情感分析的计算模型[10]。然而,这些研究所提出的分析模型依然存在准确度较低的问题,难以应用到大规模的旅游服务平台中。
为了进一步提高游客在旅游服务平台上的分析准确度,基于支持向量机等机器学习分类算法[11],文中提出了针对游客评论数据的智能分类与分析技术。使用数据的自动抓取技术,实现了旅游服务平台的数据获取与预处理操作,通过引入支持向量机技术,文中提高了分析模型的泛化能力,实现具有较高准确度的情感分析技术。相关仿真结果表明,基于机器学习方法的游客评论数据分析技术优于传统的语义分析方法。
1 情感分类技术
在数学领域中,情感分类是一个映射过程。令a表示由多种数据组成的待分类集合,b表示经过精确分类之后的类别集合,则情感分类f,可用式(1)表达。

在当前研究中,情感分类技术主要可分为语义分析[12-14]与机器学习[15-16]两类,其简介如下:
1)基于语义分析的情感分类技术,是通过对词语的语义倾向进行分析的情感分类方法,该方法需要提取、表示与统计词语的语义特征。其分类流程如图1 所示。

图1 基于语义分析的情感分类流程图
2)基于机器学习的情感分类技术需要使用统计学,比较当前数据与已定义的分类特征向量的相似程度,从而完成文本数据的情感分类。其分类流程如图2 所示。

图2 基于机器学习的情感分类流程图
一般而言,基于机器学习的常用情感分类技术,主要包括支持向量机(SVM)、K 近邻与朴素贝叶斯算法等。在基于语义分析与机器学习的情感分类技术中,由于支持向量机技术具有准确度较高的分类效果,故文中选用该技术对游客的评论数据进行智能分析。
2 支持向量机技术
2.1 数据抓取
在智能分析技术中,鉴于用户数量与关注度均较高,所以文中的训练集与测试集数据均来自于携程网的数据库。为快速获取大量的数据,利用Java语言在Eclipes 平台上,分别编写了网页抓取程序Crawler 与解析数据程序Parse。利用抓取程序与用户数据,建立了由旅游景点信息与评论信息组成的数据表。其中,旅游景点信息主要由城市序号、城市名称、游客人数、综合评分、景点评分、评论数量与评价时间等组成;评论信息主要由评论序号、城市序号、城市名称、评论内容、游客评分、评价时间与游客姓名等组成。
2.2 预处理
为便于机器学习方法的分类与计算,文中还需要对原始的评论数据进行必要的预处理。其中,数据预处理过程又可分为训练集与测试集、文本清理与初始分类流程,其详细内容如下。
1)训练集与测试集
在数据预处理的过程中,文中需要对数据库中的原始数据进行反复地调整与运算,从而选取出由大量游客评论数据组成的训练集;同时,选择出由一定数量评论数据与分类结果组成的测试集。利用数据的自动抓取程序,文中从携程网平台上获取了10个旅游景点的在线评论数据。经过反复地训练与测试,文中对多个分类器的参数进行了优化与改进。
2)文本清理与初始分类
在旅游服务平台上,原始数据的自动抓取程序是直接复制相应的评论内容,导致了抓取的数据中包含较多英文、符号等额外信息。所以,文中需要对原始的抓取数据进行一定的“过滤”,该过程主要由以下行为组成。
①剔除无意义的游客评论数据。其中,无意义的评论数据主要包括3 种数据,即外文或符号等无法判别内容、特别简略而无法判断情感倾向的内容、包含大量广告的评论内容;
②精简有意义的游客评论数据。在具有参考意义的评论数据中,大量的英文单词或怪异的表情符号等内容较难反映游客的真实情感倾向,需要进行一定的精简与优化。
为了实现更加精确的评论自动分类,文中需要对经过清理的文本数据进行人工初始分类,即将文本的评价内容简单分成积极正面评价与消极负面评价内容,从而尽量提高分类的准确度。
2.3 情感分类
当完成原始数据的预处理后,基于机器学习的评论数据分类技术还需要执行特征表示、特征提取与分类计算等多个流程,其详细介绍如下。
1)特征表示
由于机器学习算法无法直接对文本数据进行处理与运算,所以文中利用向量空间模型表示文本数据。
一般而言,向量空间模型是使用具有权值的特征向量空间表示文本的方法。在所有文本数据中,每个文本d均由n维向量空间V的一个点来表示,即V(d)=(w1,…,wn)。其中,向量空间的分量wi(1 ≤i≤n)均表示文本数据在特征向量空间中的权重值。利用该方式,文中即可将游客的文本数据逐一匹配到n维的特征向量空间。
2)特征提取
由于中文的词语总数较多,所以经过特征表示的特征向量,仍需要进行特征提取,从而降低特征向量的维度。目前,针对中文文本的常用特征提取方法主要有:文档频率统计、信息增益计算与交互信息统计等。其中,因为机器学习方法被用于分类计算,所以文中选用信息增益计算的方法来完成特征提取。
通常,信息增益计算是广泛用于机器学习领域的特征提取方法,令t表示文档词语,c表示文档类别,s表示文档的类别数量,p(c)表示c类文档在中文语料集合中的出现概率,而p(t)与表示文档词语t在中文语料集合中的出现与不出现的概率,分别表示文档词语t在c类文档中出现与不出现的概率。则文本特征提取的计算结果I(t)如式(2)所示。

3)分类计算
为了提高评论数据的分析准确度,文中选用支持向量机(SVM)技术,作为评论文本数据的主要分析工具。在概率论与数理统计原理的基础上,以结构风险最小化为运算基准原则,SVM 的学习泛化能力更高,解决了传统机器学习算法始终存在的非线性与过学习等问题。其基本思想为利用监督学习的方法,对文本数据进行二元线性分类。

而样本集F的所有点(xi,yi)满足以下不等式:

而在数据空间Rd中,样本数据x到分类超平面距离l的计算方法,如式(5)所示。

通常而言,为了实现更加精确的分类,文中需要寻找最优的分类超平面,而这一问题可以转化为支持向量机二次规划的数学计算模型。其中,该数学模型的目标函数obj(w)如式(6)所示。

对于样本数据集F={(xi,yi)},令i=1,2,…,s,则该数学模型的约束条件如式(7)所示。

此外,令ai表示第i个样本对应的拉格朗日算子,文中分别将目标函数与约束条件细化为式(8)与式(9):
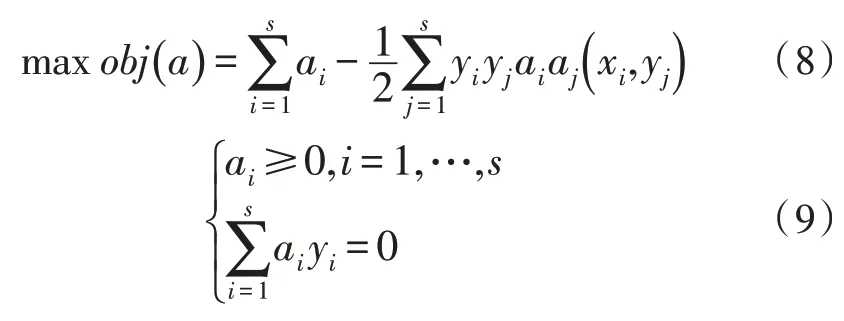
根据库恩塔克尔定理,通过一定的推导可知,上述数学模型的优化解必然满足以下条件,如式(10)所示。

其中,在大部分样本数据的求解过程中,ai=0 。而当ai≠0 时的少部分样本即为支持向量,通过推导与求解可得分类判别函数D(x,y),如式(11)所示。
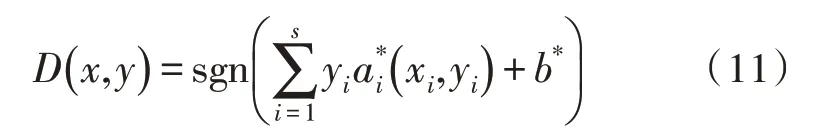
3 仿真结果与分析
为验证文中提出的智能分析方法的有效性,利用携程网的游客评论内容,分别对基于语义分析与机器学习的智能分析方法进行了仿真与分析。在仿真过程中,文中采用卡方检验的方法衡量这两种文本分析方法的优劣。需要说明的是,所有的仿真均采用相同的样本数据与检验条件。经过多种训练集与测试集等样本数据的测试和分析,文中得到了测试集的分类正确率结果。其中,当训练集样本数据的数量分别为50、100、200 与400 时,这两种方法的测试集分类正确率,如表1 所示。

表1 测试集评论数据分类正确率结果
由表1 可知,在同样的仿真条件下,基于机器学习方法的智能分析技术具有较高的正确率,显著优于传统的语义分析方法,证明了文中所提分析技术的优越性。
4 结束语
针对游客评论文本的数据分析问题,文中基于机器学习方法提出了一种文本智能分析技术。通过引入支持向量机的数据处理方法,这种智能分析技术显著提高了游客评论数据的分类正确率,具有一定的借鉴与参考意义。然而,由于仿真条件的限制,文中并没有对这种技术进行大规模的仿真与分析,该技术的稳定性表现无法判定,下一步将致力于解决这一问题。
