一种基于国产异构众核处理器的C++智能源码转换框架*
2021-06-25俞茂学贾东宁魏志强许佳立马广浩
俞茂学,贾东宁,2,魏志强,2,许佳立,马广浩
(1.青岛海洋科学与技术试点国家实验室,山东 青岛 266237;2.中国海洋大学信息科学与工程学院,山东 青岛 266100)
1 引言
超级计算机是当前信息时代世界各主要国家竞争激烈的科技制高点,是一个国家科技水平和综合国力的重要标志。中美竞争愈演愈烈,超算作为第四次工业革命的重大基础设施,已成为两国角力的主要战场之一,其国产化已经上升为国家战略。我国国产化处理器以异构众核的申威SW26010为代表,该处理器包含4个运算核组CG(Core Group),每个核组包括1个内存控制器MC(Memory Controller)和64个运算核心,理论峰值性能达到125.4 Pflop/s,核心工作频率1.5 GHz,性能指标世界领先[1]。该芯片的架构面向高性能计算,通过统一指令系统、统一执行模型和支持一致性的主存共享,实现了异构核心的深度融合[2]。在基础软件生态方面,已经部署完成了神威·太湖之光操作系统神威睿思(RaiseOS 2.0.5),支持Linux系统,支持国际标准的编程语言,如C/C++ /Fortran编译器以及相适配的向量工具、基础数学库等。此外,在并行编程工具方面,主要采用神威OpenACC,兼容OpenACC 2.0标准,并添加了部分定制功能[3]。该国产芯片打破了国际对我国的技术封锁,实现了软硬件全部国产定制开发。
异构众核架构虽然具有诸多优势,但在单个计算结点内集成了大量不同类型的处理器核心,使得体系结构更为复杂,这给程序设计特别对于多核架构的遗产代码移植带来了挑战。另一方面,当前人工智能与大数据领域应用软件九成以上是基于x86和GPU开发的,海量的遗产代码对移植工作造成了较大困难。采用人工进行并行程序编写和优化往往具有很高的运行效率,但存在成本高、效率低等问题。王一超等人[3,4]在神威·太湖之光上完全手工移植了科学应用GTC-P,代码效率高,但成本也较高。当前,国产众核架构的并行编译系统无法支持众核C++ 编译,导致大量C++ 遗产程序无法利用神威·太湖之光的从核加速优势,阻碍了国产众核系统的发展步伐。
在众核结构的并行化编译领域,面向GPU平台,研究人员针对并行编译系统的自动移植做了大量工作。Matsumura等人[5]提出了基于OpenACC的普适于多GPU的源-源转换器,通过识别GPU类型生成不同的OpenACC制导语句。Lashgar等人[6]提出了一种将OpenACC自动翻译成OpenCL(Open Computing Language)和CUDA(Compute Unified Device Architecture)的源-源翻译工具,将输入代码进行归一化处理后,经过中间层XML格式分离出主机代码和加速代码,对加速代码进行转换,形成CUDA和OpenACC代码。Lee等人[7]实现了将面向共享存储结构的OpenMP程序转换成GPGPU程序的自动转换和优化框架,能够将已有的OpenMP程序移植到GPU众核平台。国内研究主要集中在利用clang编译前端对OpenACC进行源码转换的工作上。江霞[8]提出利用clang编译前端对Intel Xeon Phi协处理器进行自动OpenACC转换。本研究过程中采用的开源ANTLR(ANother Tool for Language Recognition)是一个功能强大的解析器生成器,用以读取、处理、执行或翻译结构化文本,被广泛用于构建语言、工具和框架,通过利用其强大的语法规则支持,源码转换的难度被大幅降低。
C++ 作为面向对象的语言,其关键语言特性为类和对象、模板和泛型设计、标准库及并发设计[9]。本文针对这几个关键特性,基于ANTLR的源码翻译工具,探讨其自动转换成C语言的原理和可实现性。针对科学运算的领域代码特点,对于较少使用或者转换复杂的STL(Standard Template Library)库函数等进行自动标注,构建了一整套C++ 转换成C语言的辅助转换框架,协助程序开发人员实现存量遗产代码的快速移植。
本文首先介绍了国产众核的并行编译系统、ANTLR架构、面向对象和面向过程语言的特点及转换要素。在此基础上,详细论述了源码转换的关键技术,最终将转换后的代码在神威·太湖之光国产众核系统上进行了转换代码的试运行。
2 研究基础
2.1 国产众核架构及并行编译系统
神威·太湖之光超级计算机上使用的神威SW26010芯片架构如图1所示,使用64位自主申威指令系统,采用片上融合异构的体系结构,每个核组内64个从核按照8×8的mesh拓扑结构,由片上内部网络互连[2]。众核处理器体系结构不仅对科学工程计算具有较高的效能和较好的适应性,对双精度、单精度的矩阵计算的支持同样能够在一定程度上满足人工智能的关键计算需求[10]。
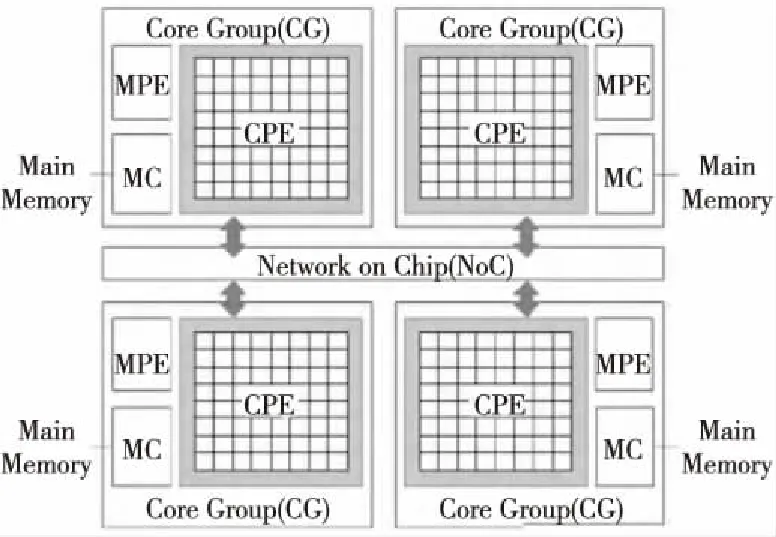
Figure 1 Architecture of Sunway many-core processor
神威·太湖之光的软件系统采用定制的64位Linux操作系统,由基础编程语言、并行编程语言和接口、用户使用环境、基础编程环境和工具等4部分组成,如图2所示。并行编程支持与国际接轨的并行编程标准,包括MPI 3.0、OpenMP 3.1、Pthreads、OpenACC 2.0,支持消息并行编程模型、共享并行编程模型、加速并行编程模型,满足科学与工程计算课题开发和移植的多样性需要[11]。
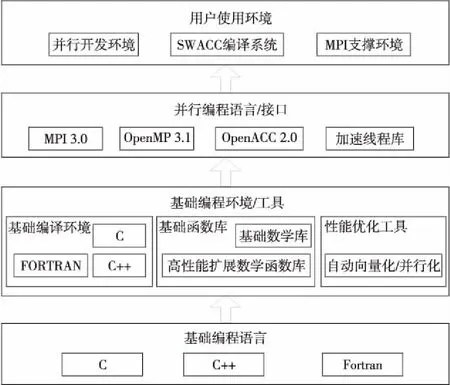
Figure 2 Software environment composition of Sunway TaihuLight
并行开发主要采用2种架构,MPI+Athread和MPI+OpenACC*。其中,Athread直接控制LDM和DMA,可以控制使用所有的硬件功能,需要编写主核、从核程序,改造时间较长,需要性能细节人为可见、可控,需要深刻理解架构特点,掌握优化方法。如刘徐等人[12]对遗传算法的并行参数自动寻优的研究。OpenACC*可以在短时间完成移植,并获得可观的加速性能,保持跨平台的可移植性,在“神威·太湖之光”上获得了广泛应用。面向申威SW26010异构众核处理器结构特点,OpenACC*是在OpenACC 2.0的基础上进行适当精简和扩充构建而成的,以编译指令的方式提供众核编程所需的语言功能。编译器为国产定制的SWACC/SWAFORT。整个编译系统的支持情况如表1所示。

Table 1 Sunway basic compilation command
2.2 面向对象语言和面向过程语言的特点及转换要素
面向对象程序设计语言的核心思想是数据抽象、继承和动态绑定。通过使用数据抽象,可以将类的接口和实现分离;使用继承,可以定义相似的类型并对其相似关系建模;使用动态绑定,可以在一定程度上忽略相似类型的区别,而以统一的方式使用它们的对象[13]。面向过程程序设计基于结构化程序设计思想,强调程序结构规范为顺序、选择和循环3种基本结构。以算法为核心,把数据和操作分离。按照解决问题的过程划分模块,集中处理数据,运行效率高。但是,代码的重用性和可扩展性比较差。C语言作为面向过程的语言更为普及地应用于并行计算。根据2种完全不同架构的语言特点,其转换要素主要聚焦于类的封装、继承和多态,模板和泛型设计,标准库和并行设计。
本文构建了C++转换成C语言的辅助开发框架,建立C++转换后的C代码框架、增加转换标注以及建立C转换常用函数代码,加速开发人员的移植速度。类封装和继承的C转换采用C语言的结构体作为类转换的目标,识别基类和继承类,并赋予不同的结构体命名规则。多态的转换利用多态规则的识别,通过类名和函数名对多态函数进行区分和重定义。借鉴编译器处理模板和实例化的方法,建立模板和实例化的关系,并通过2次语法树遍历解析,实现了C语言转换。C++作为典型的面向对象的语言,其提供了丰富的STL库,对于STL库的解析,本文创建了自动标注及辅助部分C函数对应实现的方式。通过以上设计,表明了辅助快速移植的可行性和有效性。
2.3 ANTLR的开源翻译工具
ANTLR是以PCCTS(Purdue Compiler Construction Tool Set)为基础构建的开源工具,致力于解决编译前端的所有工作。研究表明,ANTLR的语法可以用来定义模板语言的词法记号和语法规则[14]。该工具可以对Java、C/C++、C#等语言进行语法描述,自动生成词法分析器和语法分析器,将开发人员输入的程序根据相对应的编程语言语法规则转换为抽象语法树。在ANTLR强大的支持下,大大降低了源码转换的难度。首先,采用词法分析器处理字符序列,并把产生的词法符号交给语法分析器。其次,基于以上信息开展语法检查,并构建一棵语法分析树。在这个过程中,使用的ANTLR类包括:CharStream、Lexer、Token Stream、Parser和ParseTree。通过TokenStream,可以把词法分析器和语法分析器进行连接[15],实现类之间的交互,如图3所示。
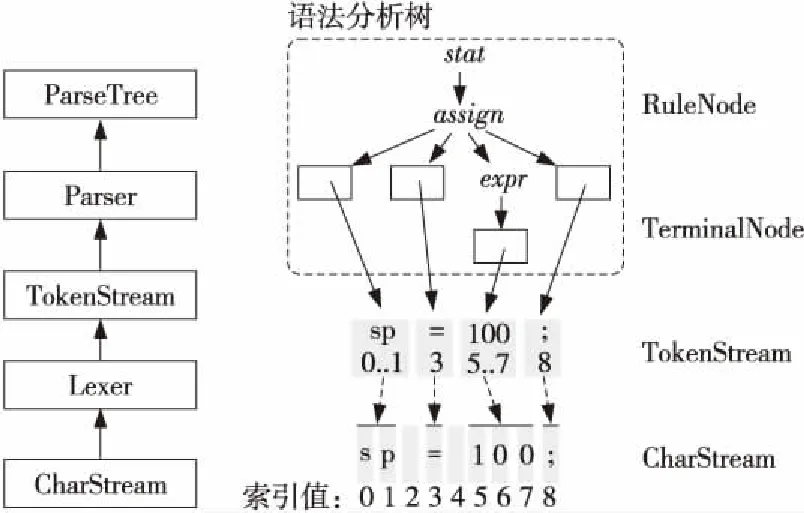
Figure 3 Interaction mode between ANTLR classes
3 C++代码辅助智能转换工具的设计与实现
3.1 总体架构设计
在开源的C++语法规则CPP14.g4的基础上,使用ANTLR对C++源码进行词法分析、语法分析和语义分析,生成抽象语法树,结合ANTLR自带的ParseTreeProperty类,实现每个子节点内容的C转换,最终形成目标C语言的解析树。
依据C++的代码特点和抽象语法树的节点路径关系,本文将C++代码分为5部分进行解析:基类声明、继承类声明、函数定义、函数参数和main函数。针对以上不同部分,构建区别化的解析转换流程。
对于C++特有的泛型设计、引用、运算符重载等语法特点,本文采用2次语法树遍历解析的方式进行转换。在第1次语法树遍历中,获取模板和实例化的对应关系,引用变量名称等关键数据,同时构建通用的Utility类,保存关键解析数据。在第2次语法树遍历中,使用先前获取到的关键解析数据实现实例化的C语言转换。
以科学计算领域常用的STL库为研究对象,进行STL库的转换。对频繁调用的STL库,采用预先完成转换的C语言函数进行替代和重构。对不常用的STL库函数或者C++的特殊用法,创建自动标注体系辅助开发人员进行快速有效识别,并进行替换。
整个架构设计如图4所示。
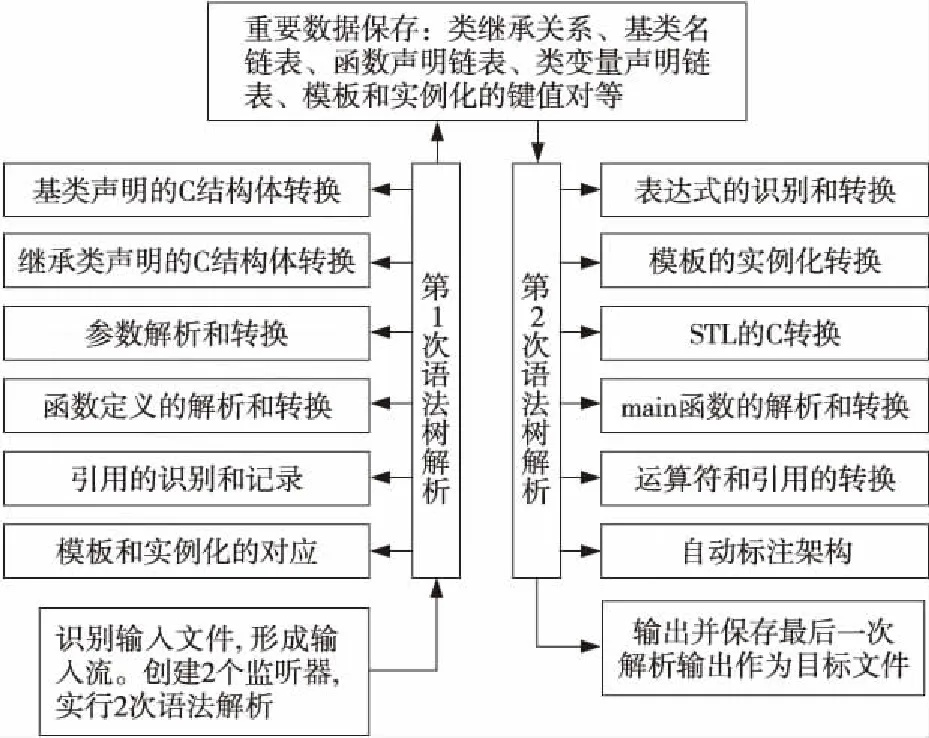
Figure 4 Overall architecture of source code transforms
3.2 类的识别及结构体转换
C++的类转换成C的结构体声明,其实现步骤如下所示:
(1)基类和继承类的划分。继承类的C转换需要将对应基类作为结构体指针变量,从而实现C++的继承特性。
(2)类成员通用函数解析与转换。在C++中,类成员函数中可以直接调用类中的其他成员变量,但对于C语言而言是非法的。因此,需要在C语言所有类成员函数的参数中增加此类的结构体指针变量,用于类成员变量的相互调用。
(3)类的构造函数解析与转换。构造函数名称需要与类名称进行区别化处理,增加Str前缀,且指针化(*Str+函数名)处理。针对构造函数使用初始化列表的过程,需要进行2部分转换。首先,对构造函数的声明进行先行转换;其次,在函数定义过程中进行初始化列表转换。
(4)类的虚函数和析构函数的解析与转换。首先,通过virtual关键字识别类的虚函数。其次,采用类名+变量名组合的形式进行函数名称的转换。然后,在虚函数参数中增加结构体指针变量,以解决类的多态转换问题。
(5)类成员变量的解析变换。针对C++中特有的变量,例如String、vector、list等,需要进行类型转换和标注,以满足转换需求。
类声明的C结构体转换实例如图5所示。

Figure 5 Example of class structure transforms
3.3 函数定义转换
函数定义是源码转换的重要环节,本文采用预先设定的范围标签进行区别化转换。函数定义的解析分为2部分:函数头和函数体。函数定义的转换需要考虑类型因素。根据函数定义的特点,其类型主要包含类成员函数、构造函数、虚函数、析构函数、普通函数和main函数等。函数定义转换的具体过程如图6所示。首先,通过函数类型识别,查表获得预先保存的函数头。其次,在函数体转换中,识别出构造函数的初始化列表,结合预先保存的类成员变量对初始化列表进行C转换。解析函数体中的表达式的类型和关键字,进行对应的自动标注或C转换。最后,组合解析后的函数头和函数体,形成转换后完整的函数定义。
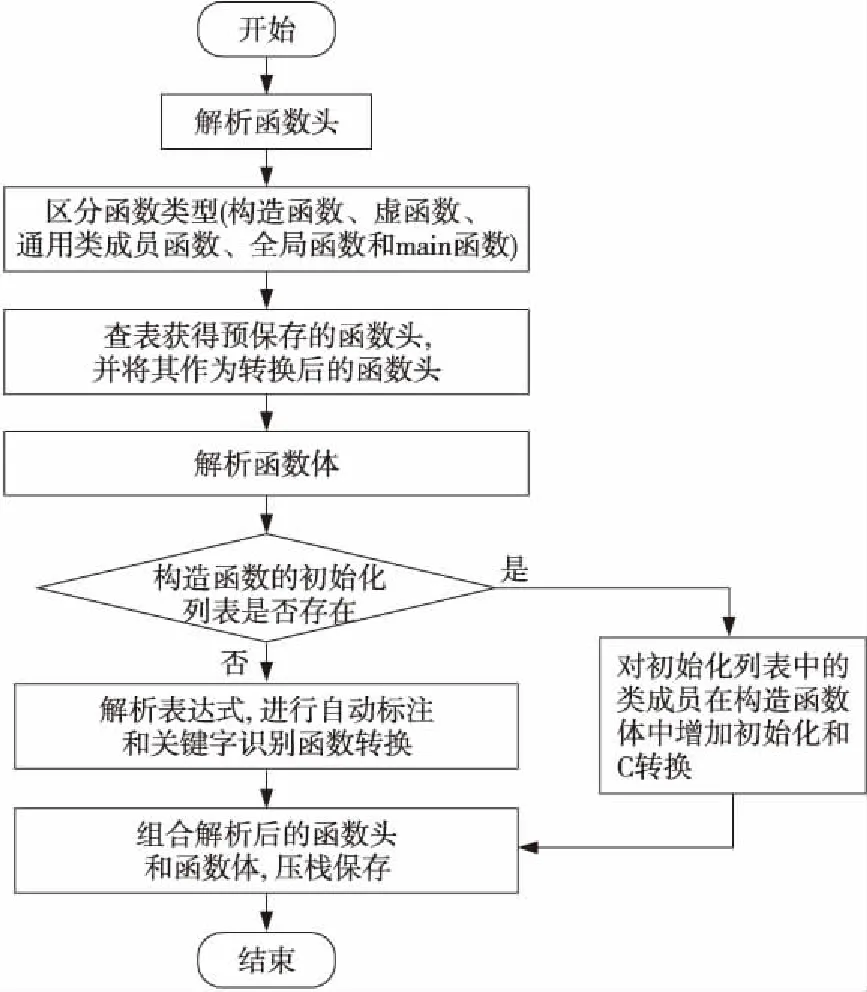
Figure 6 C transform process of function definition
3.4 模板实例化转换
泛型程序设计是一种把算法程序从独立的源程序中抽离出来的抽象编程机制,具有简化程序、提高代码可读性与复用性的特点。模板作为泛型程序设计的核心部分,一直被用于开发可复用软件,是C++最重要的语言特性之一[16]。模板作为泛型设计的一个典型应用,分为函数模板和类模板。其中,函数模板通过函数调用实现实例化,类模板通过将模板形参与实参实现绑定实现实例化。
为了便于模板的实例化转换,本文在第1次语法遍历过程中,实现了数据的结构化,其结构为:map〈〈模板,实例〉,类名(函数名)〉。在类模板数据结构化方面,由于其格式比较固定,一般出现在类的变量定义和初始化阶段,数据结构化过程相对固定;在函数模板数据结构化方面,由于其实例化的表现形式较多,会出现多个函数模板嵌套调用的现象,导致数据结构化获取不全。针对这种状况,本文增加了map〈模板,函数名〉键值对的数据结构,以保证嵌套模板函数的完全实例化。
在第2次语法树遍历过程中,实现了模板的实例化转换,其主要过程如图7所示。
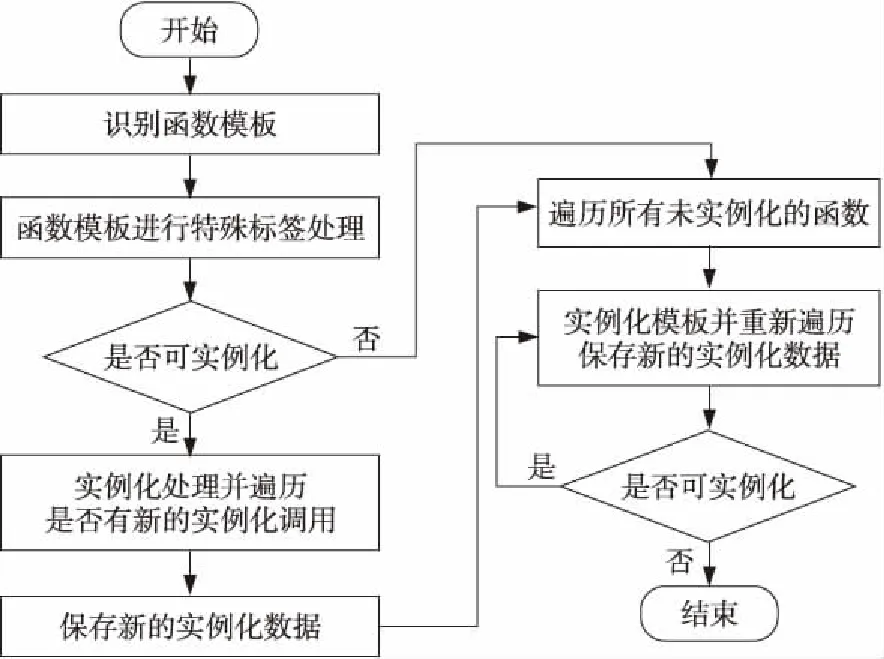
Figure 7 Instance process of template function
具体表现为:
(1)添加特殊标签。对语法树解析的变量类型入口trailing-type-specifier添加特殊标签,同步对模板名和实例名增加相同的标签,以解决对类或函数模板实例化时出现的误替换问题。例如,模板名称为D,实例化为float类型,如果代码中有变量定义包含D,如 D Data = 0.1;则表达式会被误替换为float floatata=0.1;类型增加了特殊标签后,表达式变更为Dqnlm Data = 0.1;进行模板实例化替换时则杜绝了误替换的问题。
(2)语法树节点判断。类的实例化导致实例化前后的类所处的语法树节点发生变化,如图8所示。因此,在Declaration节点中增加判断,确保实例化后的C结构体声明正确压栈,解决了实例化后无法从下一级语法树上正确获取的问题。
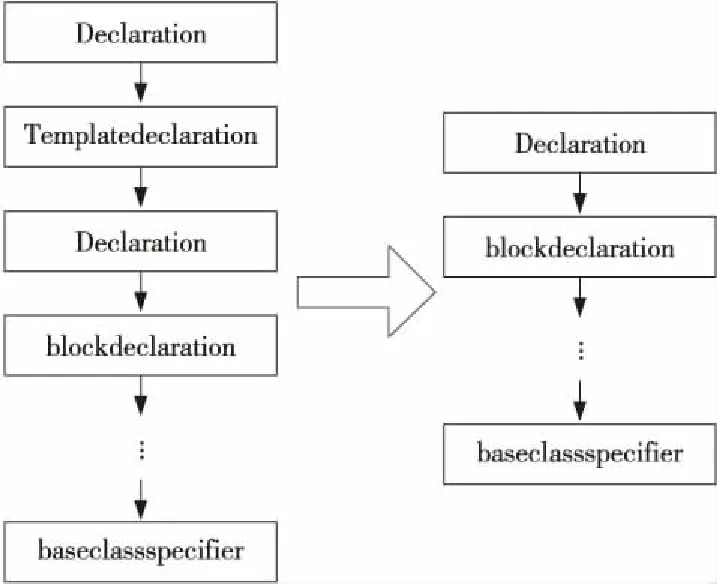
Figure 8 Change of syntax tree after instantiation
(3)函数模板实例化。考虑到函数模板中嵌套调用函数模板的情况,将第1次遍历过程中未找到实例化的函数模板统一保存,并集中处理。首先,对第1次遍历中找到的实例化函数进行解析。其次,对此函数进行2次遍历,使用预先保存的尚未实例化的数据结构〈模板,函数名〉进行查找,判断是否存在新的实例化对象,并保存到newinstance数据结构中。最后,针对所有的未实例化的模板函数进行统一实例化,通过对数据结构newinstance的增加和删除,实现所有模板函数的实例化。
(4)类模板实例化。首先,对类模板及类成员函数进行实例化。在此基础上,建立实例化的类名称和类成员函数的赋值对应关系。对实例化的类名和类成员函数进行键值对保存,以用于在结构体初始化时进行对应赋值。
需要说明的是,基于函数模板的STL库是一类使用频繁且封装好的库,因此该部分的实例化转换采用预先完成转换的C语言函数进行替代和重构。以cout标准输出为例,汇总其输出的格式化标记、格式操作符及格式化函数,并进行C语言Printf的对应转换,实现了cout标准输出的C转换方式,如表2所示。
3.5 自动标注体系
C++11的标准库由11个子库构成,包括3个新型标准库和8个传统标准库。由于C++标准库的实现主要依赖于模板,使得STL库组件具有广泛通用性的底层特征。STL库由容器、算法、迭代器、仿函数和内存分配器组成,包含了诸多在计算机科学领域中常用的基本数据结构和基本算法,提供了一个可扩展的应用框架,高度体现了软件的可复用性[17]。

Table 2 Transform key points for cout STL library
在C++到C语言的源代码转换过程中,STL库的转换是主要难点之一。本文基于对C++标准库的理解,构建了自动标注体系,通过关键字和语义的识别,标注出需要替换的库函数,便于程序员进行快速分析和开发,以实现STL库的快速转换。其中,本文构建的自动标注体系类别信息如表3所示。

Table 3 Category corresponding information of automatic marking system
4 实验结果与分析
4.1 转换后的代码框架
本文选取经典的BableStream内存基准带宽程序为实验对象。该程序提供了基于GPU的内存传输速率的基准测试[18],编程语言为C++,支持包括OpenACC、OpenCL和OpenMP在内的多种并行架构,提供了4种主要的加速任务,由于具有跨平台性及高可靠性,该程序被广泛应用于并行计算领域。BableStream仅能支持Intel和PGI的编译器,并且编程语言为C++,无法在国产众核平台上直接运行。本文对BableStream程序进行了辅助智能转换,加速了代码转换的效率,转换框架如图9所示。
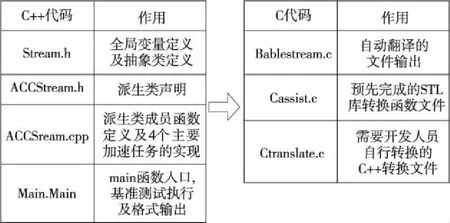
Figure 9 C language translation framework of BableStream
转换后的代码经过标注代码修改后,在神威·太湖之光的编译系统上可以完成编译并运行,经过实际测试,自动转换时间为7.9 s,转换后的C代码811行,标注代码73行,手动对标注代码修改后可以编译通过并正确运行,修改后的代码1 301行。目前智能转换率为60%左右。
4.2 在国产神威·太湖之光上的运行结果展示
实验平台为神威·太湖之光异构众核系统,其参数如表4所示[19]。

Table 4 Experimental environment
多核普通计算机的运行环境如下所示:
(1)Linux架构:x86体系结构64位;
(2)操作系统版本:Ubuntu 18.04.3 LTS;
(3)CPU信息:处理器:Intel(R)Core(TM)i5-10210U CPU @ 1.6 GHz;一共8个CPU,每个CPU 4核,缓存:6 MB;
(4)PGI的编译版本:19.10.0。
C++在多核计算机上的运行结果如表5所示。
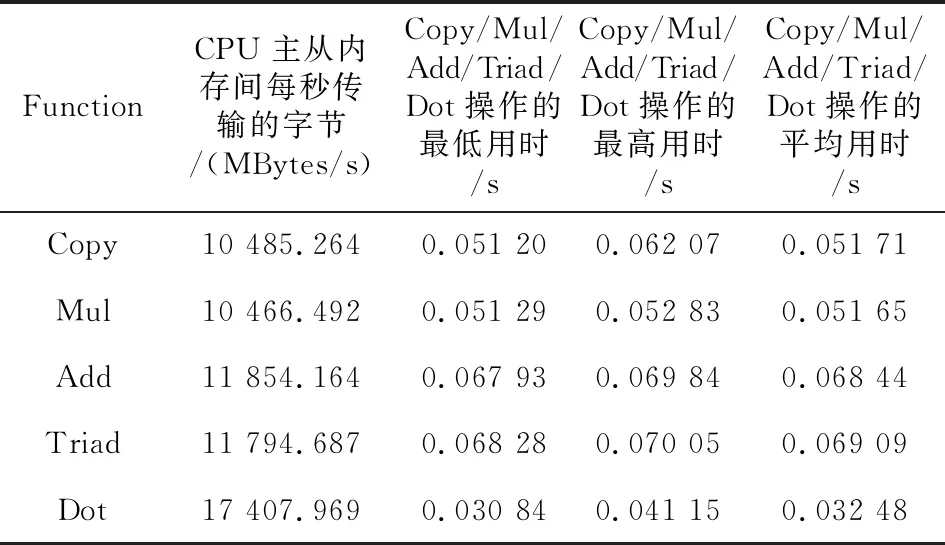
Table 5 Test results of BableStream on mutlicore computer
转换后的C代码在神威·太湖之光上的运行结果如表6所示。
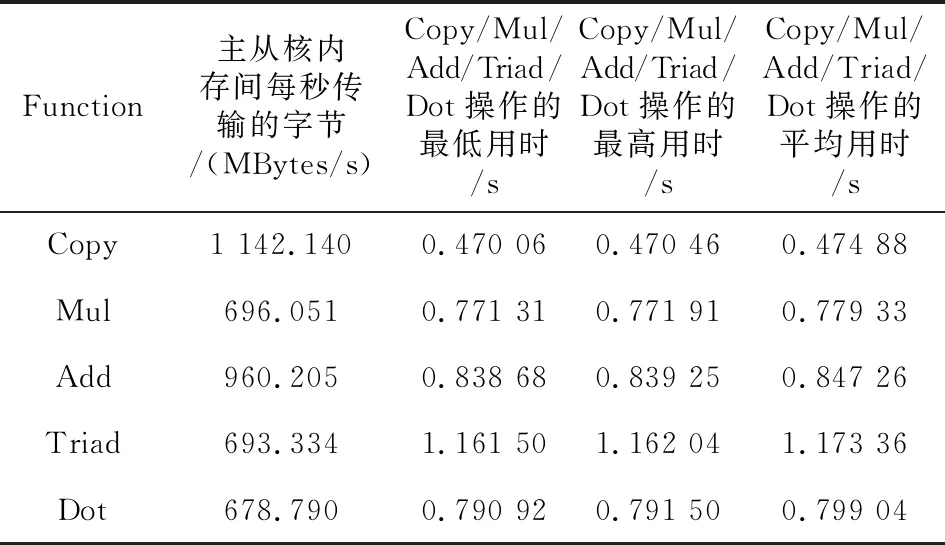
Table 6 Test results of BableStream on Sunway TaihuLight
通过实验对比分析发现,转换后的性能数据较差,原因是由于BableStream的OpenACC版本和神威·太湖之光使用的版本存在较大差异,OpenACC的制导语句及加速代码都是使用类C语言实现,不涉及本文的转换内容。后续需要进一步对OpenACC的制导语句进行并行优化。
5 结束语
从数量和性能综合来看,我国超级计算机的台数比美国多一倍,但总运算性能和美国基本相当,说明我国超级计算机的平均性能和美国相比有较大差距,这是由于在当前超级计算机生态系统中,基于x86架构的CPU生态最为完善,操作系统、应用软件和工具最多。我国基于申威CPU的超级计算机对应的软件生态环境一直处于劣势,急需加快建设速度。本文提出了一种基于国产众核的C++辅助源码智能转换框架,基于开源软件ANTLR对C++语言进行词法、语法和语义分析并形成抽象语法树,结合面向对象语言的关键特征,完成了C++代码自动转换成C代码的架构,建立了部分STL库函数的预先对应转换代码和自动标注系统,加快了源码转换的效率。
在转换过程中发现了可持续优化的方面,如针对不同C++代码的兼容性设计,对内存的使用需要更好地予以标注或自动转换,转换后函数的顺序不一致导致出现编译出错的问题,C++的容器转换通过智能方式优化,以及OpenACC的制导语句并行优化的智能转换等都需要进行持续研究和优化。后续会持续深入研究转换的稳定性和兼容性,以及并行优化的智能转换。
