基于TPU和FPGA的深度学习边缘计算平台的设计与实现*
2021-06-25刘昌华
栾 奕,刘昌华
(武汉轻工大学数学与计算机学院,湖北 武汉 430023)
1 引言
我们所处的时代正在经历万物互联带来的巨大变革,随着中心化云计算、数据分析、网络安全和存储技术的进一步成熟,搭建一个稳定、可靠、高效的物联网体系已成为可能。而这样成熟的技术发展带来的是移动设备用户数量和数据流量的爆炸式增长,预计到2030年,全球移动设备接入数量将达到180亿,中国占其中的六分之一;物联网设备接入量将达到一千亿,中国占其中的五分之一[1 - 3]。而随着5G技术标准成熟[4],5G商用化正式启动,未来对于物联网和云计算会有更为严峻的挑战。而如今我们正好可以应用边缘计算[5]技术来弥补云计算的不足之处。但是,深度学习算法本身对准确度的追求会消耗大量计算资源,这与计算资源受限的边缘计算环境相矛盾,因此将深度神经网络模型部署在边缘计算平台面临巨大的挑战。
2017年香港科技大学Mao[5]提出一种绿色边缘计算和通信系统的设计方法,研究了单用户系统下混合能源供应HES(Hybrid Energy Supply)无线网络的基本网能量消耗和QoS(Quality of Service)之间的权衡。香港大学的You[6]也提出了能源高效型的移动边缘计算模型,并将重点放在计算迁移和资源管理上。同年,肖骞[7]也提出了在多用户超密集型的网络中,利用启发式算法ECEP(Enhanced-Cochannel users Equal Power collocation)仿真分析得出尽可能小的时延-能耗权重和。上述研究都将重点放在了优化抽象的网络部署策略或者优化模型推理的框架方面,还没有提出切实的硬件部署方案。
2018年,赵佶[8]提出了一种以树莓派为硬件构建的网关设备,不仅可以实现基本的路由器功能,还可以承担边缘计算所需的任务。2019年开始出现将深度学习与边缘计算相结合的研究,肖云飞[9]以树莓派为硬件,基于边缘计算的系统架构,在车辆终端应用深度学习模型实现了车道保持功能,实现了深度学习样本数据在自动驾驶领域的扩充和应用。也是在2019年,曹泓等人[10]提出了一种基于深度学习的城市管理违章行为分析算法,可以智能分析出视频流中的常见违章行为。但上述研究均是以树莓派为硬件实现的,尽管树莓派与常见的51单片机和STM32等嵌入式微控制器相比,能够运行相应的操作系统,还可以完成更复杂的任务管理与调度,但树莓派的最大优势同时也是自身的短板,它提供了比嵌入式微控制器更多选择与应用的同时,牺牲了自身的性能优势。卢冶等人[11]基于XILINX 7020 FPGA提出了面向边缘计算的卷积神经网络构建方法,图像分类准确度可达79%,同时将系统功耗降低至4.2 W。
为了使深度学习技术能更好地适应边缘计算环境,本文同样选择采用搭载双核Cortex-A9和张量处理器TPU(Tensor Processing Unit)的ZYNQ 7020 FPGA芯片,通过TPU+FPGA的方式,发挥FPGA[12]高速并行、可灵活编程的特点;同时结合TPU计算架构在深度学习领域极高的算力,在FPGA芯片内部搭建全新的边缘计算架构。并且在FPGA框架下,系统功耗性能比较高,适合在边缘结点长期待机。本文在Caffe(Convolutional Architecture for Fast Feature Embedding)[13]框架下对压缩后的MobileNet-V1模型完成了训练和优化,最终将硬件与算法二者结合实现了一种基于TPU+FPGA的深度学习边缘计算平台,该计算架构在测试数据集上取得了良好的效果。
2 TPU基本原理与特点
2.1 TPU基本原理
张量处理单元TPU最早是谷歌在2016年推出的,而谷歌人工智能AlphaGo依靠以单核TPU为核心的计算架构先后击败了围棋大师李世石与柯洁,并因此名声大噪。由于神经网络编程模型的本质是计算图模型,计算图的输入/输出是张量数据,计算图的类型代表操作类型。因此,直观地,最适合于神经网络编程模型的计算体系结构是Graph/Tensor计算体系,其中,处理器的功能由计算图类型决定,而数据则是计算图的输入/输出张量。然而,计算图这一层级的粒度太粗,各类型间并没有太大的相关性,一个典型的神经网络计算由Convolution、Pooling、BN、Scale、ReLU等组成,它们之间的行为差异巨大,如果处理器按照计算图操作的粒度设计,这就意味着需要为每一个(或某几个)计算图操作设计专门的计算硬件(正如NVIDIA DLA那样,NVDLA为卷积、池化和BN专门设计了不同的计算电路),这样的代价是巨大的,而且也不具备可扩展性。
TPU所采用的张量运算集[14,15]用一种巧妙的方式解决了Graph/Tensor体系结构中的核心问题:如何用一套标准、完善且最大粒度的操作(粒度远远高于传统CPU/GPU的加、减、乘、除,同时也是各计算图的子集)来定义基础运算类型。
在张量运算集中,张量运算被划分为1维、2维、3维和4维4大种类,每个种类又由各种不同类型的计算操作组成,从而形成一个完备的计算集合,通过这些张量运算操作的组合,便能在相同硬件架构下完成如普通卷积、DW卷积、Pooling、Resize、ReLU等计算图操作。TPU架构如图1所示。
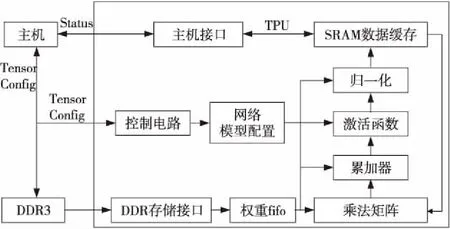
Figure 1 Structure of TPU
2.2 TPU内部主要模块及工作原理
本文通过Vivado 2018.2工具完成TPU的相关设计,其中主要包括:张量计算模块、激活/池化模块、数据缓存模块与动态存储模块。其中最为重要的张量计算模块主要由一个256×256的乘法矩阵和累加器构成,由于本文中张量计算模块所采用的脉动阵列,使得TPU中最主要的计算过程比较固定,因此对控制电路的依赖较低;激活模块与池化模块负责对累加器输出的像素点数据进行激活处理和池化处理;数据缓存模块用于存储即将输入乘法矩阵的像素数据;而动态存储模块负责缓存像素的权值数据并交给乘法矩阵进行相应计算。
(1)数据缓存模块。
该模块的作用是缓存本地输入的像素数据,主要由片外SRAM构成,TPU在推理过程中为了大幅提升响应速率,会以较高的频率访问该模块的数据。因此,选择采用片外SRAM的方式来作为数据的缓存设备。本文采用开发板上提供的96 KB×256×8 bits SRAM作为数据缓存模块的主要设备。
(2)动态存储模块。
在深度神经网络的推理过程中,每一层的权值是不断更新的,动态存储模块就是用于存储更新的权值并将其交给乘法矩阵,配合像素数据进行乘累加运算。该模块的功能可以看做是一个FIFO队列,接收来自开发板上DDR3(512 MB)的权值数据。实际上在Vivado设计中也是通过IP Catalog功能直接例化调用一个256×256×8 bits的FIFO队列。
(3)张量计算模块。
本文中TPU张量计算模块由乘法矩阵和累加器组成,采用脉动阵列的方式工作,其核心概念就是让数据在运算单元的阵列中进行流动,减少访存的次数,并且使得结构更加规整,布线更加统一,提高频率。乘法矩阵由256×256,即65 536个8位MAC组成,其结构图如图2所示。图2左侧就是数据缓存模块,它将每行像素输入乘法矩阵中,数据在矩阵中按照从左至右的方向传播。图2上方为一个动态存储器(权值滤波),负责将当前权值交给下方的MAC单元。乘法矩阵中的每一个cell就是一个乘加单元(MAC)。每个cell执行的计算如式(1)所示:
w×x+b
(1)
其中,x代表从左侧输入的像素数据,w代表从上方cell得到的滤波器权值,b代表从上方cell得到的输出部分和。从左侧传来的像素输入数据会传递到右侧的相邻cell,滤波器权值会传递给下方的cell。从上方cell得到的部分和作为当前cell的加数D。当前cell输出的部分和会传递给下方的相邻cell当作加数D。
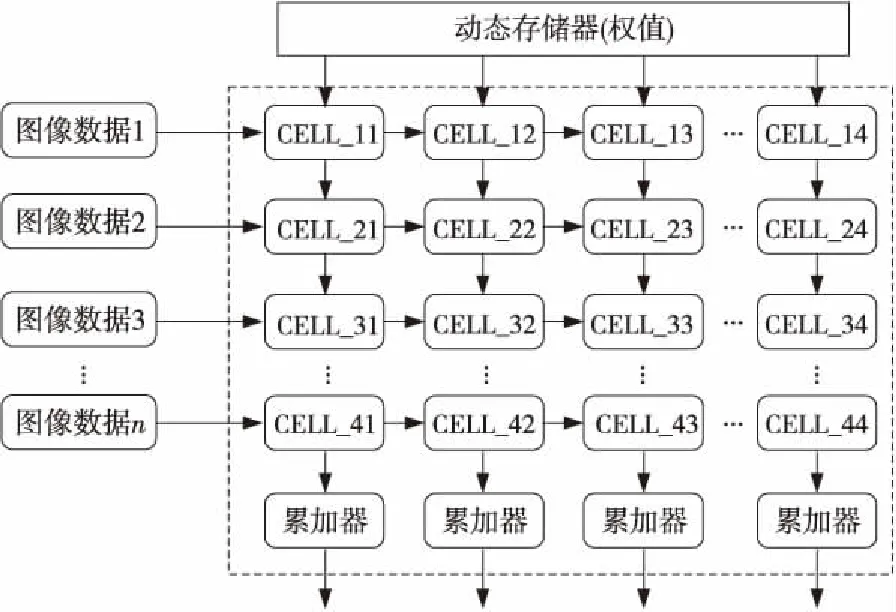
Figure 2 Construction of matrix multiplication
2.3 TPU的特性及优势
TPU所具备的通用性和嵌入式2大主要特性更是为用户进行边缘端AI的相关开发和部署提供了极大便利,从通用性来说TPU具有以下特性:
(1)支持各种类型神经网络计算层,方便后续算法迭代;
(2)支持大多数神经网络算法,方便实现各种解决方案;
(3)支持FP16和INT8数据类型,方便灵活选择;
(4)支持PC训练模型的无缝转换,提供便捷、易用的人工智能推理计算。
3 实验设计方案
3.1 整体方案
本实验中的TPU软核处理器架构是在Vivado 2018.2设计软件下,通过VHDL硬件描述语言完成TPU工程文件的编译并下载到开发板上的FPGA芯片。在PC端创建Linux操作系统的虚拟机,并搭建基于Caffe的深度学习框架,在ImageNet数据集基础上整理并创建小规模实验数据集,完成对深度神经网络的搭建、训练和优化。最后通过TPU编译和交叉编译完成算法编译和嵌入式端应用编译,把神经网络算法模型和超参文件转变成TPU软核处理器可识别的嵌入式端执行文件,同时将C++程序转变成嵌入式端应用程序可执行文件。而TPU神经网络张量处理器已被移植到带有ARM-cortex A9处理器的ZYNQ 7020 FPGA芯片中,等待PC端将上述各执行文件、操作系统及SDK通过以太网下载到芯片之后,就可以通过PC端支配并监视FPGA(TPU)完成图像分类任务及过程并向PC返回分类结果。该深度学习边缘计算平台架构如图3所示。
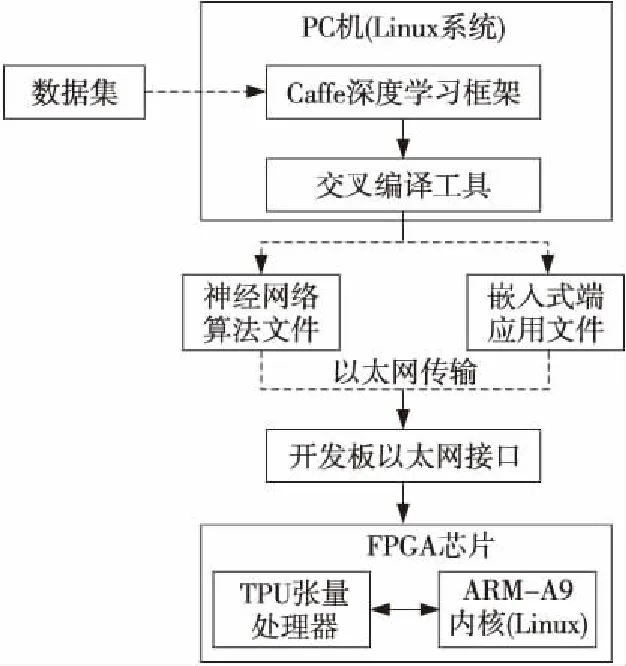
Figure 3 Edge computing platform for deep learning
3.2 实验环境
(1) PC机配置。由于实验中深度神经网络的配置和训练均是在PC中完成的,因此PC的配置对网络训练的效率有着重要影响。本实验中PC机采用Intel i5-7300HQ CPU(2.50 GHz)、NVIDIA GeForce GTX1050(8 GB) GPU。
(2) Linux操作系统。本实验通过VMware Workstation 12 Pro软件,采用Ubuntu 18.04LTS版本的操作系统创建虚拟机文件,并将Caffe深度学习框架植入该系统中。
(3) 编译工具。在完成网络模型的训练后,通过TPU编译器和Arm-linux-gcc6.3.1交叉编译器进行编译,以完成嵌入式端系统文件和算法文件的下载。
4 数据集整理与预处理
本实验在ImageNet数据集[16]的基础上整理出一个较小的数据集。其中训练数据集包含4 000幅图像,验证数据集包含950幅图像,测试数据集包含50幅图像,共计5 000幅图像,涉及100个类别(标签)。由于Caffe要求对数据集中的训练集和验证集进行转换,转换成LMDB数据库,本实验通过脚本命令分别建立用于训练和验证的2个LMDB数据库。同时,为了保证网络在训练时能更快地收敛,本文对数据库中的数据进行均值计算,获取彩色图像三通道的均值并将结果写入.prototxt文件,以便后续工作中调用。本文中数据集经过均值计算后,RGB三通道均值分别为:103.025,115.701,121.234。
5 神经网络模型及优化
5.1 神经网络模型选择
MobileNet-V1原本是谷歌推出的一种深度学习加速模型[17],与传统模型相比它可以在保证不影响准确度的情况下大大减少计算时间和参数规模,这样就使得网络可以被移植到算力和空间受限的移动端和边缘计算平台上。MobileNet采用一种称为深度可分离卷积DW(Deep-Wise)的方式来替代传统3D卷积,以大幅降低计算量,其具体思想是将原本的卷积核拆分成Depthwise和Pointwise 2部分。
Depthwise Convolution部分负责提取输入图像每个通道的空间特征,通常用N表示输入图像数量,H表示输入图像高度,W表示输入图像宽度,C表示通道数,DK表示卷积核的高/宽,那么该部分的乘法计算量可表示为N×H×W×C。也就是说,该计算相当于是将输入图像以通道数为基准,分为C组,并以DK·DK大小的卷积核对每组(即每个通道)进行卷积计算。
Pointwise Convolution部分负责提取每个点的特征,它是对H×W×C的输入进行K个1×1的卷积计算,其乘法计算量为H×W×C×K。这样一来就相当于把一个普通卷积分解为Depthwise+Pointwise 2部分。对DW卷积和普通卷积的计算量进行对比,对比结果如式(2)所示。
(2)
从式(2)中可以看出,DW卷积相比传统3D卷积,在计算量上有了明显压缩,且压缩比与卷积核数量、卷积核大小有关,卷积核数量、卷积核大小越大,则压缩效果越明显,可以显著提高计算速度。
5.2 网络模型优化方案
尽管这样的网络结构已经具备了一定的计算量和参数规模上的优势,但是,在一些对运行速度或内存有极端要求的场合,还需要更小更快的模型。为了进一步压缩、优化网络模型,本文通过超参数宽度因子(Width Multiplier)α和分辨率因子(Resolutionmultiplier)β来对网络规模进行压缩。宽度因子α∈(0,1],附加于网络的通道数,简单来说就是新网络中每一个模块要使用的卷积核数量相较于标准的MobileNet比例更少。对于DW结合1×1方式的卷积核,此时的卷积计算量如式(3)所示:
F=H×W×αC×DK×DK+H×W×αC×αK
(3)
除了通过宽度因子α对模型进行进一步优化以外,本文还加入分辨率因子β来帮助进一步压缩算法模型的计算量。分辨率因子β∈(0,1],是作用于每一个模块输入尺寸的约减因子,简单来说就是将输入数据以及由此在每一个模块产生的特征图都变小了。同时加入宽度因子α和分辨率因子β后,此时DW结合1×1方式的卷积核计算量为:
F′=βH×βW×αC×DK×DK+βH×βW×αC×αK
(4)
因为分辨率因子β仅影响输入数据和特征图大小,并未对参数量有任何影响,仅影响计算量。为了探究配置上述参数对本实验的具体影响,以找出最合适的模型优化方案,实验中分别将α配置为3/4,1/2,1/4,将β配置为6/7,5/7,4/7,再对压缩后的网络进行训练。其中的关键数据对比结果如表1所示。
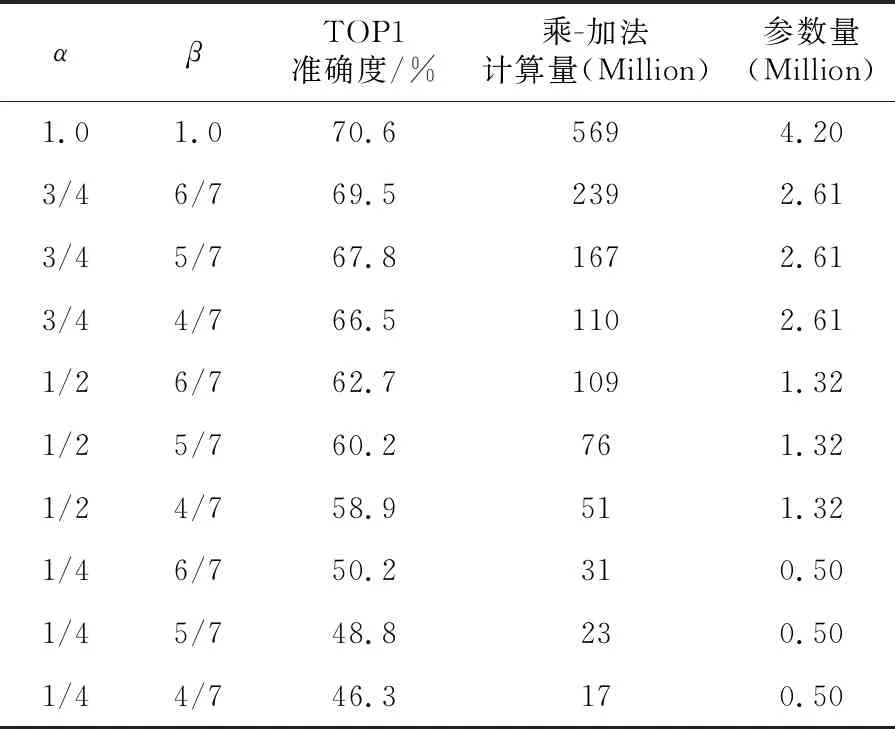
Table 1 Training results under different width and resolution factors
实验中选取原始模型,即α=1.0,β=1.0作为对照组,从上述实验数据中可以看出,随着网络模型的规模下降,准确度也随之下降,尤其当α≤0.5时,虽然此时模型已经得到了极为可观的压缩效果,但准确度却大幅下降,这样会使网络模型在进行分类任务时,多个结果之间的概率区分度降低,无法较好地突出拟合度最高的结果。因此,本文采用宽度因子α=0.75,分辨率因子β=6/7的配置对原有模型进行压缩,不仅对准确度影响最小,还将原有模型的计算量和参数量分别降低42%和62%,从网络结构上进行优化和提速,以更好地适应边缘计算环境。
6 实验数据及对比分析
实验整体上分为PC端与嵌入式端2部分,首先需要在PC端采用CPU/GPU对优化压缩后的网络模型进行训练,训练时Caffe中的超参数配置如表2所示。
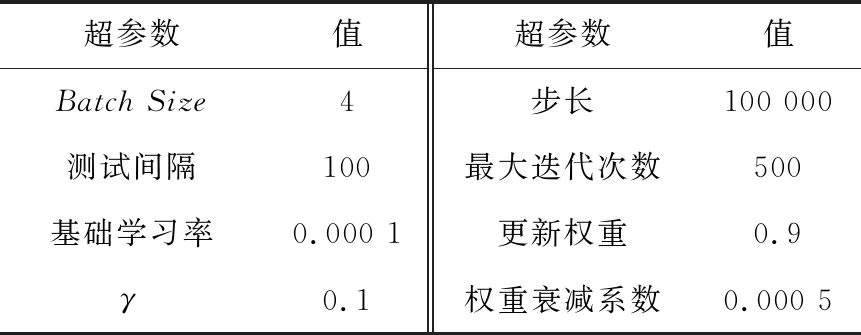
Table 2 Hyperparameters of training model
BatchSize表示测试时每一批次的数量,由于测试数据集有近一千幅图像,一次性执行全部数据效率很低,因此本文将测试数据分成几个批次来执行,每个批次为4幅图像。测试间隔为每100次训练进行一次测试。本实验采用step策略对基础学习率进行调整,该策略与步长(Stepsize)和迭代次数有关,调整方法如式(5)所示:
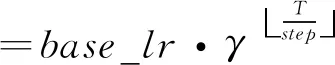
(5)
其中,T表示当前迭代次数,step表示调整步长,base_lr表示基础学习率。该策略的好处是随着迭代次数的变化可以自动降低学习率,不需要人工操作。
相对于二分类问题常用的logistic回归算法,在多分类问题中需要采用Softmax回归算法提高分类结果的弹性,Softmax函数定义如式(6)所示:
(6)
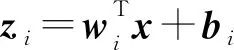
并且本实验通过权重衰减(L2正则化)可以在一定程度上避免过拟合现象。实验中的正则化其实是在损失函数后添加正则化项,添加后的损失函数如式(7)所示:
(7)
其中,l0表示原始损失函数,θ表示权重衰减系数,n表示训练集数量,ω表示所有参数的平方和。正则化是通过约束参数的范数使其处于一定区间,所以可以在一定程度上减少过拟合情况。因为过拟合,就是当拟合函数需要顾忌每一个点时,最终形成的拟合函数波动往往会很大。在某些很小的区间里,函数值的变化很剧烈,这就意味着函数在某些小区间里的导数值(绝对值)非常大。由于自变量值可大可小,所以只有系数足够大才能保证导数值足够大。本文对模型分别采用CPU和GPU训练和测试,其结果如表3所示。

Table 3 Training results under different configuration
虽然实验中采用的CPU和GPU都是移动版的型号,算力不能与台式电脑配置的处理器相提并论,但在使用不同配置的情况下,通过多次测试,可以看出在训练、测试任务计算的速度上GPU明显比CPU更为高效,虽然TOP5的准确度有略微下降,但TOP1的准确度明显提升,这更加有利于对目标的精准分类。
上述研究仅仅是在PC端完成的,为了将网络模型算法完整地移植到FPGA SOC芯片上,还需要对训练完成的网络进行修改才能形成最后的部署网络。在完成所有编译和下载(包括相关SDK以及测试图像)工作后,就可以通过嵌入式端对算法模型进行进一步测试,验证TPU+FPGA的计算架构对算法模型的支持。此时的分类已经不在处于PC中CPU或GPU的架构中计算,而是在TPU+FPGA的架构中进行,实验在同样的测试数据集上,TPU+FPGA组成的计算架构相对于CPU/GPU数百甚至上千毫秒的分类计算速度有了明显提高,如表4所示,每幅图像的分类时间在32~93 ms不等,平均分类时间74.7 ms。

Table 4 Classification performance of edge computing platform
在本实验中TPU对FPGA逻辑资源的占用情况直接影响到片上系统的功耗情况,本文采用的深度学习边缘计算架构与采用同型号的FPGA芯片通过HLS方式实现的计算架构相比,FPGA中各类主要逻辑资源的占用率有了明显下降,如图4所示。

Figure 4 Comparison of FPGA resource utilization under different structures
在本文计算架构下,不仅FPGA片上资源消耗得到大幅改进,而且总功耗仅为3.4 W,与上述仅仅采用FPGA逻辑资源搭建的计算架构4.2 W的功耗相比降低了20%。
而与同样将深度学习应用在边缘计算环境的结果相比,基于树莓派实现的深度学习边缘计算平台[9]对每一幅图像的计算时间往往需要数百毫秒,且准确度无法满足需求,而采用TPU软核+FPGA的异构计算架构,无论是功耗还是性能都具有一定优势。本实验中的边缘计算平台在计算速度上,比起基于树莓派的深度学习边缘计算平台,速度提升了3~6倍,准确度提高了13%,而功耗更是降低了50.7%,如表5所示。
而将本文中的系统与其他非边缘计算环境下的深度学习计算相比,虽然采用CPU协同多个FPGA的异构计算架构可以使同类数据集中的单幅图像分类时间缩短到1 ms以下,但其平台的整体功耗高达24 W,仅CPU就占了总功耗的37.5%。然而,在边缘计算平台上计算资源和功耗的控制都是极为严格的,本实验所采用的计算架构在各计算层以及整体的计算速度上远不如后者,但拥有极为明显的功耗和体积优势,也更进一步表明了本实验中的计算架构在边缘计算平台的意义和适用性。

Table 5 Comparison with other deep learning edge computing platforms
7 结束语
本文通过对ImageNet数据集的裁剪和整理,形成更适应边缘网络的小型数据集。
依靠Caffe深度学习框架,搭建面向边缘计算的神经网络算法模型,并对网络模型算法的结构进行压缩优化,以适应嵌入式端的硬件应用环境。以ZYNQ 7020 FPGA SoC芯片的逻辑资源为基础构建TPU软核处理器,并与SoC内部的ARM处理器协同构建深度学习边缘计算架构,实现了在边缘结点这样计算资源、功耗受到明显限制的环境中,仍然能够以优势速度完成分类计算任务,并且大大降低系统功耗,使其在边缘结点长期待机中不会消耗过多能源。同时,由于FPGA中仍有部分资源未被使用,因此该系统尚有扩展余地,可利用Verilog HDL/VHDL硬件描述语言或直接采用抽象等级更高的HLS编译方式对这些资源加以利用,丰富边缘结点的功能,进一步提高上云数据的有效性。
