基于新型关系注意力机制的实体关系抽取
2021-06-25毛养勤覃俊尹帆叶正李蔚栋
毛养勤,覃俊,尹帆,叶正,李蔚栋
(中南民族大学 计算机科学学院 & 湖北省制造企业智能管理工程技术研究中心,武汉 430074)
近年来,无结构化文本信息的快速增长给人们获取有价值的信息服务带来了巨大的困难.信息抽取技术[1]是对无结构化文本进行结构化处理的主要技术,为人们带来更佳的用户体验.然而实体关系抽取作为信息抽取领域的核心子任务,是指对文本中所含实体对进行语义关系提取.在构建知识图谱,智能问答等方面有着重要意义.
目前,有监督方式的实体关系抽取将该任务当作一个分类任务并且取得较好的效果.但该方法依然受到标注语料的限制,人工标注费时费力,因此影响了实体关系抽取的大规模抽取效果.针对其语料缺乏的问题,MINTZ[2]提出了一种利用知识库中已存实体三元组信息自动对齐自由文本来标注语料的远程监督方法.其主要思路是:如果知识库中的实体对含有某种关系,那么包含这种实体对的句子都会标注上这个关系.显然这种方式存在不严谨的地方,引入了许多噪声标注数据.因此引入了注意力机制,对表示某一关系的语料中的每一个句子分配一个权重,旨在找到更能表达实体之间关系的句子.然而在计算某些关系语义表示的时候,传统注意力模型使用两实体表示相减得到,会忽略不同关系其实关注的是实体的不同方面.例如:
“斯内普深情地看着莉莉.----恋人”.
针对上面的句子可能两实体相减得出一个可能是朋友的语义,也可能是爱人的语义.因为两实体间可能有多种关系存在,不同关系关注的是实体的不同方面.所以针对上述问题本文提出了适用于多种关系存在的实体关系表示方法,并构建了一种基于新型关系注意力机制(New Relational Attention Mechanism,NATT)的远程监督关系抽取模型,即我们参考了知识表示模型TransR的思想,利用变换矩阵为每个实体对集合学习一个新型的关系语义表示,进而改造原有的注意力机制.达到进一步降低噪声的目的.
(1)前人提出的注意力模型中利用实体对的向量表示相减得到关系语义表示,进而使用关系表示来达到降噪的效果,然而同一实体对间存在多种关系,此种表示方法会导致噪声无法很好的过滤.
(2)针对上述问题本文提出了适用于多种关系存在的实体关系表示方法,并构建了一种基于新型关系表示的注意力机制(NATT)的远程监督关系抽取模型.
(3)该模型的预测结果优于基于远程监督的实体关系抽取问题的基线 .
1 相关工作
近年来,许多方法被广泛用到实体关系抽取任务上,主要分为有监督、半监督、无监督三种方式.有监督方式将关系抽取任务当作一个分类任务并且能取得较好的效果.然而该方法需要大量的人工标注语料,耗时耗力.为了解决语料缺乏的问题,HOFFMANN[3]提出了多实例学习,并且SURDEANU[4]认为同一实体对之间可能存在多种关系,于是在HOFFMANN的研究基础上引入了多标签的方法来缓解错误标注的问题,也称之为多实例多标签学习. BENJAMIN[5]则通过利用主题模型LDA和判决学习方法提高了抽取事实的排名质量,降低了噪声数据的影响.近年来,许多深度学习的策略都在远程监督关系抽取任务上进行尝试使用,ZENG[6]避免使用特征工程采而是使用卷积结构和分段最大池化来自动学习句子相关特征,并采用多实例学习来解决远程监督中的错误标注数据问题;LIN[7]提出了使用句子级别的注意力机制来动态的计算每个句子的权重,达到过滤噪声数据的抽取效果;JIANG[8]首次放宽了“至少表达一次”的假设,对多句使用最大池化来利用不同句子间的共享信息,从而提高抽取效果;LEI[9]提出了一种能有效利用文本语料库和知识图谱信息的双向知识蒸馏的神经网络框架.可以动态的减少噪声问题;FENG[10]提出利用强化学习来解决远程监督中的错误标注问题;JI[11]引入外部知识库的实体的相关信息,充分的学习实体的向量表示,从而改造了句子层的注意力机制,提高了抽取的准确率.
以上研究虽然采用注意力机制能改善远程监督关系抽取模型,但目前大多数研究仅在句子层引入注意力机制,忽略了在计算某些关系语义表示的时候,会存在表示多种关系的情况.在我们计算句子与关系相似性的时候,由于关系表示的偏差可能会导致注意力得分比较低.因此,为了能充分学习到关系表示,我们使用变换矩阵为每一个实体对集合(简称包)学习一个新型的关系语义表示.
2 算法描述
本文提出了PCNN+NATT的关系抽取模型来解决句子中的噪声问题.模型结构包含PCNN网络、NATT注意力机制、训练目标三个部分,如图1所示.PCNN网络用来获取句子语义向量,NATT注意力机制赋予每个句子权重以获取包级别向量,训练目标用来学习关系抽取任务中的关系向量表示.
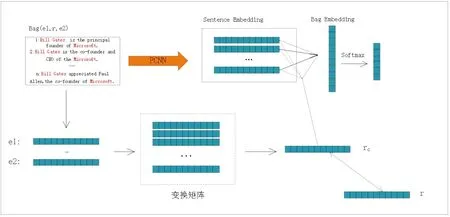
图1 PCNN+NATT模型结构图Fig.1 PCNN+NATT model structure diagram
2.1 PCNN 模型
在前人的研究中,可以发现PCNN模型[7]被广泛的应用于远程监督关系抽取任务中,如图2所示.主要用来提取一个包内句子的语义向量.假设一个句子由m个词组成(w1,w2,…,wm),PCNN模型主要的目的提取出句子的语义向量S.

图2 PCNN模型结构图Fig.2 PCNN model structure diagram
模型输入:在自然语言处理过程中,一般将单词转化成低维实值向量来构建模型的输入. 在本文中,每个单词的特征向量是由词向量和位置向量拼接而成.词嵌入一般是给定一个句子s=(w1,w2,…,wm),通过映射词向量表E∈R|v|×dw(V是词表的大小)将每个单词wi表示为dw维实值向量ei,即句子s被转换成s=(e1,e2,…,em)∈Rm×d.使用word2vec模型[12]来预训练词向量.位置嵌入用来记录当前单词到两个实体的相对距离.例如:在句子“Bill Gates is the principle founder of Microsoft.”中,单词founder 到头实体Bill Gates和尾实体Microsoft的相对距离是4和-2,然后转换成对应的向量表示.将句子中的每个单词的词嵌入和位置嵌入的拼接后组合在一起形成句子的向量表示矩阵x∈Rm×d,其中,m表示句子的长度,d表示拼接后的维度,即d=dw+dp×2.
卷积操作:卷积计算可以定义成矩阵A∈Rm×n和B∈Rm×n进行以下运算:
(1)
对于输入句子向量表示s=(e1,e2,…,em),其ei表示第i个单词的词向量.使用Si:j表示取到序列[ei,ei+1,…ej]的矩阵,滑动窗口的长度为l,所以定义的过滤器权重矩阵为W∈Rl×k.最后卷积权重矩阵在句子s上的卷积操作得到的结果向量C∈Rt-l+1可以由下式表示:
(2)
其中1≤j≤t-l+1,b是偏置值.
对于句子s,使用n个过滤器W1,W2,…,Wn(本文使用的是3个)来获得最终的结果C={C1,C2,…,Cn}.

2.2 NATT注意力机制
注意力机制用来分配有正实例以较高权重,负实例以较低权重,从而可以计算出一个包的向量,最后将其送到softmax分类器.
注意力机制: 许多知识图谱嵌入方法[13-14]将关系当作头实体到尾实体的链接.对于知识库的元组r(e1,e2)来讲,他们符合e1+r≈e2并取得了很好的表现.MIKOLOV等[12]展示词向量的一些属性例如:v(“Madrid”)-v(“Spain”) = v(“Paris”)-v(“France”)可以说明实体对向量的不同可以反映出两实体间关系的特征.LIN等[15]提出了为每一个实体对组学习不同的关系向量来解决头尾实体对具有多种模式的情况.
受多种知识图谱嵌入方法的思想启发,针对一个包中的三元组(e1,r,e2),我们引入一个新的关系向量rc(见公式3)来表达包中两实体间的关系特征,包内的句子如果表达了此关系,则具有高相似性,反之则具有无关性.
rc=(e1-e2)Mr,
(3)
e1,e2代表实体1和实体2,Mr代表变换矩阵并采用Xavier初始化方式生成,随后通过反馈进行调整.
假设一个包内存在m个句子,{s1,s2,…,sm}表示句子的语义向量,使用得分函数(相似性和无关性)来计算每个句子语义向量和关系向量的注意力权重,公式如下:
(4)
ωi=wTa(tanh[Si:rc])+ba,
(5)
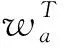
(6)
其中b∈R3n.
Softmax:为了计算每个关系得置信度,将包得特征向量b送入softmax分类器.
o=Msb+bs,
(7)
其中o代表输出,Ms代表中间矩阵,bs代表偏置值,采用Xavier方式随机初始化生成.假设θ代表模型中所有的参数,B表示包,则属于第i个关系的条件概率为:
(8)
2.3 训练目标
对于每一个包的关系rc,首先利用两实体向量得到原始向量r,即r=(e1-e2).然后让两向量rc和r相互靠近.因此,可以定义以下目标函数:
(9)
其中N是包的总个数.
针对于远程监督关系抽取任务,定义其目标函数为:
(10)
为了学习每个包的关系表示,所有总的目标函数为:
minL=LD+λLe,
(11)
其中λ>0是Le的权重.
3 实验与结果分析
3.1 数据集与评价指标
本文使用的数据集是远程监督关系抽取中使用较为广泛的NYT10 数据集.该数据集由RIEDEL等人[16]发布的.利用纽约时报语料库对齐 Freebase知识库中的三元组信息根据远程监督的假设产生的,训练集是2005~2006年的新闻语料中获取的句子.测试集是2007 年对标NYT语料中的句子.该数据集中包含53 类关系,包括特殊关系类型“NA”,表示两个实体之间没有关系.训练集和测试集分别包含570088和172448个句子, 63428和16705个实体,291010和96678个实体对.文献[3]和文献[7]也使用该数据集做了相关研究.
遵循文献[3]和文献[7]的工作,采用两种方式进行评估:held-out和manual.并在held-out评估中比较基线模型的准确率和召回率等两种评价指标,对比本文提出模型的效果.
3.2 实验参数设置
在本文的实验中,使用word2vec预训练了词向量.使用句嵌入的向量维数选择范围为{50,100,200,300},位置嵌入的选择范围为{5,10,20},特征图的选择范围为{100,200,230},batch_size的大小选择范围在{100,200,500}.经过实验验证,最佳的参数配置如下:dw=50,dP=5,batch_size = 100,lr= 0.001,dropout_rate=0.8.
3.3 实验结果分析比较
为了验证本文提出的注意力机制的效果,文中主要采用APCNN,PCNN+ATT,PCNN+MIL[6]模型作为实验的对比模型.
Held-out评估:图3展现了各个模型的准确率/召回率曲线,从图中可以看出,PCNN+NATT比其他基线模型(APCNN,PCNN+ATT,PCNN+MIL)取得更好的表现.可以看出NATT注意力机制可以有效的赋予负实例以较小权重从而减轻噪声.

图3 1-PCNN+NATT 2-APCNN3-PCNN+ATT 4-PCNN+MIL 的p-r曲线图Fig.3 The p-r curve of 1-PCNN+NATT 2-APCNN 3-PCNN+ATT 4-PCNN+MIL
Manual评估:表1是各个模型的Top N比较表,该表表示在按照测试输出的概率排序的基础上,前N条句子的准确率.从表1中数据的比较可以看出:(1)PCNN+MIL算法的准确率都是最低的,说明噪声对模型的影响严重.(2)PCNN+ATT算法的效果要全面优于PCNN+MIL算法,注意力机制能有效的利用句子信息,同时减少了噪声的影响.(3)APCNN算法取得的效果优于PCNN+ATT算法,说明了两实体信息能反映关系的某些特征.(4)PCNN+NATT注意力机制可以有效的赋予负实例以较小权重从而减轻噪声.

表1 各模型Top N对比表Tab.1 Top N comparison table of each model
4 结语
为了尽可能地赋予远程监督数据集中噪声数据以较小的权重,本文提出一种基于新型关系注意力机制的实体关系抽取模型.该模型考虑到实体对之间可能有多种关系存在,不同的关系可能关注的是实体不同方面.所以该模型利用变换矩阵学习到更准确的关系表示进而改造传统的注意力机制.尽可能地赋予正实例以较高权重,负实例以较低权重,降低噪声句子对模型性能的影响.实验证明:本文所提出的模型在准确率上要优于几种经典的对比模型.
