基于机器学习的在线评论倾向性分析
2021-06-25支世尧
支世尧 彭 栋 朱 旭
(南京审计大学信息工程学院,江苏 南京211815)
1 概述
随着社交网络的迅猛发展,互联网上的用户评论和观点激增。这些隐含用户情感倾向的文本在产品推荐、舆情监控以及信息预测等方面具有重要意义,并得到了广泛应用。本次研究以去哪儿网站上南京地区如家和汉庭酒店的客户评论为分析对象,运用朴素贝叶斯方法对评论文本进行倾向性分析研究。
2 倾向性分析
2.1 相关文献
Pang[1]等人于2002 年针对电影评论数据进行倾向性分析,此次试验首次应用机器学习算法。结果表明,基于SVM、NB 等机器学习方法的得出的实验结果要优于大部分基于规则的算法。Ye[2]等人使用了N-gran、NB 以及SVM 三种方法进行了文本分类研究,研究结果表明,当训练集不断增大,NB 的分类效果与其余两种渐趋统一。
2.2 研究思路
研究思路分为以下步骤:先使用爬虫从去哪儿网站爬取所需的评论数据,接着对文本数据进行清洗和预处理,预处理包括中文分词、词性标注、停用词去除等步骤,然后运用朴素贝叶斯方法对处理好的文本进行倾向性分析,最后对分类结果进行LDA 主题挖掘,图1。
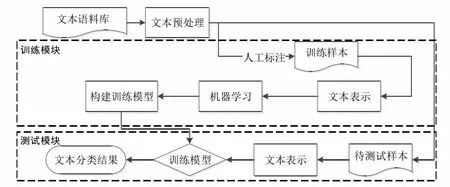
图1 研究流程与框架
2.3 实验数据集
数据采集:(1)如家酒店和汉庭酒店在2019 年的“中国连锁酒店品牌规模排行榜”上占据前两名。因此本次实验以去哪儿网作为数据来源,爬取了该网站上南京的如家和汉庭酒店的用户评价。(2)谭松波博士分享的标注了褒贬类别的10000 条中文酒店评论语料。
2.4 文本预处理
数据清洗:去除没有分析价值的文本语料,包括:存在emoji表情符号与乱码文本、存在大量无意义字符的文本、语料太短的无意义文本。经过数据清洗,最终获取如家用户评价21362 条和汉庭用户评价18341 条。中文分词:中文分词任务是按照需求将中文文本切分为词序列。未登录词识别和歧义消解是中文分词的两大难点。未登录词是指分词词典中没有的词或词组,歧义是指对同一个待切分字符串存在多个分词结果[3]。中文分词算法可以分为机械分词法、统计分词法以及理解分词法三种。在中文分词过程中,很多工具通常是结合使用机械分词法与统计分词法。比如本文选用的自然语言处理工具-结巴分词,就先采用机械分词法进行中文分词,然后利用HMM 识别未登录词,图2。
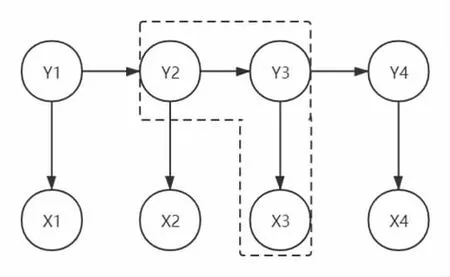
图2 隐马尔可夫模型
词性标注:词性表示一个词的特点以及在上下文中的作用。词性标注是指在中文分词的基础上,根据词在句子中的含义,结合上下文确定该词在句子中的词性,例如名词、动词等,并添加标签的过程。由于中文中的词组不具有前缀、后缀且词性不固定,导致了中文的词性标注相比较英文更加困难。中文的词性标注算法可以分为两大类:一是基于规则的词性标注;二是基于统计算法的词性标注。本文选用的NLP 工具-结巴分词,就是同时采用词典和HMM 对文本进行词性标注。停用词去除:停用词一般出现频率较高但自身却不具有实际意义。本文采用正则表达式法将其过滤[4]。
2.5 模型训练
通过查阅资料发现,基于朴素贝叶斯算法判断积极、消极情感倾向,对训练样本有着较强的依赖性。为了提高效率以及准确率,本文直接使用了中科院计算所的谭松波博士分享的标注了褒贬类别的10000 条中文酒店评论语料。其中积极评价7000条,消极评价3000 条。抽取积极评价样本6000 条和消极评价样本2000 条进行训练,将剩余的各1000 条评价样本进行测试。训练结果如表1 所示。

表1 模型训练结果
基于朴素贝叶斯方法进行倾向性分析,其中消极评价准确率达到了82%,召回率达到81%;积极评价准确率达到了86%,召回率达到83%。该算法能较好地反映文本针对酒店评论的意见倾向数值。但由于消极评价训练集样本较少,无法完全学习消极评价特征,导致消极评价准确率较低。
2.6 实验结果分析
利用上文得到模型,对已清洗过的酒店评论数据进行情感分析并收集所有包含标签的情感评论文本,得到表2 所示结果。

表2 评论数目
经过倾向性分析得知,如家酒店积极评价数占比77%,消极评价数占比23%;汉庭酒店积极评价数占比75%,消极评价数占比25%。两家酒店的消费者消极评价占比接近总评价数的1/4,说明消费者对两家酒店不满意的情况较多。即酒店自身需要重点关注消费者的消极评价,并对消费者关注的领域进行改进完善。若想直观体现两家酒店各自的优劣势,只关注倾向性分析的结果还远远不够。为了进一步展示两家酒店的利弊,下面使用LDA 主题模型挖掘消费者对如家酒店和汉庭酒店的满意和不满的地方。
3 基于LDA 的评论主题挖掘
3.1 LDA 主题模型介绍
2003 年,David Blei 等三人[5]提出具有重要意义的LDA 主题模型(潜在狄利克雷分布,Latent Dirichlet Allocation),掀起了主题模型研究的浪潮。该模型有特征词层、主题层、文档层三个层次,实质就是利用文本的特征词的共现特征来挖掘文本的主题。
LDA 主要是通过无监督学习,在众多文本中挖掘其中隐含着的主题信息,提高用户了解文档内容的效率。其主要思想为:整个文本集是基于主题的概率分布,而每个主题又是基于特征词的概率分布[6]。
3.2 LDA 流程
3.2.1 对使用朴素贝叶斯分类器完成情感分析的语料进行分词。
3.2.2 使用向量化工具对于文本集进行向量化。
3.2.3 调用LDA 函数,获得主题识别结果[7]。
3.3 LDA 主题挖掘结果展示
LDA 结果只有一系列用于描述该主题的高频关键字。经过梳理总结,得到表3 结论。

表3 积极评价主题挖掘结论
积极评论主题挖掘结论两家酒店基本相同,可见两家酒店的优势无太大差异。消极评论主题挖掘结论才是影响消费者选择的重点,表4-5。

表4 消极评价主题挖掘结论

表5 消极评价主题挖掘结论
两家酒店的消极评论主题挖掘结论有部分差异,但也有许多相似点,这些可以说是经济型快捷酒店的通病。
4 结论
本文对两家酒店的用户评论进行倾向性分析和LDA 主题挖掘,分析出两家酒店各自的优点和缺点,为消费者的选择提供了帮助。也希望两家酒店的管理人员在发扬优点的同时对各自的缺点加以改进,为消费者提供更优质的服务。
