基于数据挖掘的财务信息管理系统风险识别
2021-06-24司桥林
司桥林
(天津市眼科医院, 天津 300020)
0 引言
随着信息技术不断发展,许多企业以及政府部门都建立了自身的财务信息管理系统,并通过网络进行信息共享,因此当前存在大量、各种类型的财务信息管理系统[1]。在财务信息管理系统的实用过程中,其同其它信息系统一样,不可避免地受到一些非法用户的干扰和入侵,使财务信息管理系统面临巨大风险[2-4]。由于财务信息管理系统保存着一些重要的信息,一旦出现安全问题,如信息泄露、被非法篡改,会给企业带来不可估量的损失,因此财务信息管理系统风险识别一直是人们关注的焦点[5]。
由于财务信息管理系统风险识别的研究可以保证系统的安全,为管理人员提供有价值的信息,可以提早做出相应的防范措施,因此企业的一些财务信息管理人员以及一些有名的研究机构投入了大量的时间对财务信息管理系统风险识别问题进行了不懈的研究,并且取得了不错的财务信息管理系统风险识别研究成果[6]。财务信息管理系统风险识别方法划分为传统技术和现代技术两种,其中传统技术方法中最具代表的为基于时间序列的财务信息管理系统风险识别方法,其将财务信息管理系统风险的变化过程看作是一个根据时间先后顺序变化的系统,从历史数据分析中揭示出财务信息管理系统风险变化的特点,但是其财务信息管理系统风险识别误差极大,识别结果可信度低[7-9];现代技术方法中最具代表性的方法为:基于灰色模型的财务信息管理系统风险识别方法、贝叶斯网络的财务信息管理系统风险识别方法,它们的财务信息管理系统风险识别结果要优于时间序列分析法,但是它们的缺陷也十分明显,如存在财务信息管理系统风险识别结果不稳定、建模时间过长、风险识别效率低等[10-12]。
近年来,随着数据挖掘技术的不断发展,BP神经网络得到了长足的发展,为财务信息管理系统风险识别建模提供一种新的研究工具[13],由于财务信息管理系统风险变化十分复杂,为了提高财务信息管理系统风险识别正确率,本文提出了数据挖掘的财务信息管理系统风险识别算法,该方法结合了灰色模型和BP神经网络的优点,分别对财务信息管理系统风险变化特点进行挖掘,全面评价财务信息管理系统所处的风险等级,并与其它财务信息管理系统风险识别方法进行了对比测试,结果表明,本文方法是一种高正确率、速度快的财务信息管理系统风险识别方法,为解决复杂多变化的财务信息管理系统风险识别问题提供了一种新的研究思路。
1 数据挖掘的财务信息管理系统风险识别方法
1.1 灰色模型
GM(1,1)是灰色模型中最典型的一种,其一阶微分为式(1)。
a(1)x(1)+a⊗x(1)=u
(1)
对式(1)进行白化微分处理得式(2)。
(2)
式中,a和u为参数。
采用LS算法计算a的值得式(3)。
(3)
1.2 BP神经网络
BP神经网络是一种非线性的数据挖掘方法,具有很好的拟合和逼近能力,第k个节点的输入和输出分别为x(k)=(x1(k),x2(k),…,xn(k))和yo=(yo1,yo2,…,yoq),两者之间的变化关系,如式(4)—式(6)。
net=x1ω1+x2ω2+…+xnωn
(4)
(5)
(6)
期望输出为d(k)=(d1(k),d2(k),…,dq(k)),神经网络的全局误差计算为式(7)。
(7)
如果输出误差在实际要求的范围内,那么BP神经网络完成训练,否则需要调整相应的参数,进行下一轮学习。
1.3 数据挖掘的财务信息管理系统风险识别原理
基于数据挖掘的财务信息管理系统风险识别原理为:首先收集财务信息管理系统风险的历史值,采用专家系统对它们分别从设备风险、网络风险、入侵风险、人员意识风险、技术风险等对企业财务信息管理风险的影响和危害方面进行打分,打分参考国内外相关企业的先进经验,本文采用100分制形式,然后采用灰色模型和BP神经网络对影响因素和财务信息管理系统风险之间的变化关系进行拟合,建立财务信息管理系统风险识别模型,得到各种财务信息管理系统风险识别结果,最后采用加权形式对灰色模型和BP神经网络的识别结果进行组合,得到财务信息管理系统风险识别的最后结果,如图1所示。

图1 数据挖掘的财务信息管理系统风险识别原理
2 仿真测试
2.1 测试数据集合
为了分析数据挖掘的财务信息管理系统风险识别性能,选择一个财务信息管理系统的风险样本数据进行仿真测试,样本数据如图2所示。

图2 仿真用到的实验样本数据集合
从图2可以看出,该信息管理系统风险变化比较复杂,具有多种变化特点,如规律性、时变性、随机性等。为了使数据挖掘的财务信息管理系统风险识别结果更具说服力,选择传统的财务信息管理系统风险识别作为测试对比测试,它们分别为:基于灰色模型的财务信息管理系统风险识别方法、基于贝叶斯网络的财务信息管理系统风险识别方法,选择财务信息管理系统风险识别正确率、拒识率以及财务信息管理系统风险识别建模时间作为评价指标。
2.2 训练样本和测试样本的划分
在财务信息管理系统风险识别的建模过程中,首先要进行训练,因此训练样本的选择十分关键,为了体现实验结果的公平性,每一种方法均进行5次财务信息管理系统风险识别的仿真实验,采用不同数量的训练样本对模型进行训练,而测试样本主要用于检验财务信息管理系统风险识别方法的泛化能力,每一次实验的训练样本和测试样本的划分结果如表1所示。

表1 训练和测试样本的划分结果
2.3 结果与分析
统计3种方法从财务信息管理系统识别训练样本中识别出的正确数量,与测试样本数量比即可得到风险识别正确率,建模时间为财务信息管理系统识别训练和测试时间,如图3、图4所示。

图3 财务信息管理系统风险识别正确率对比
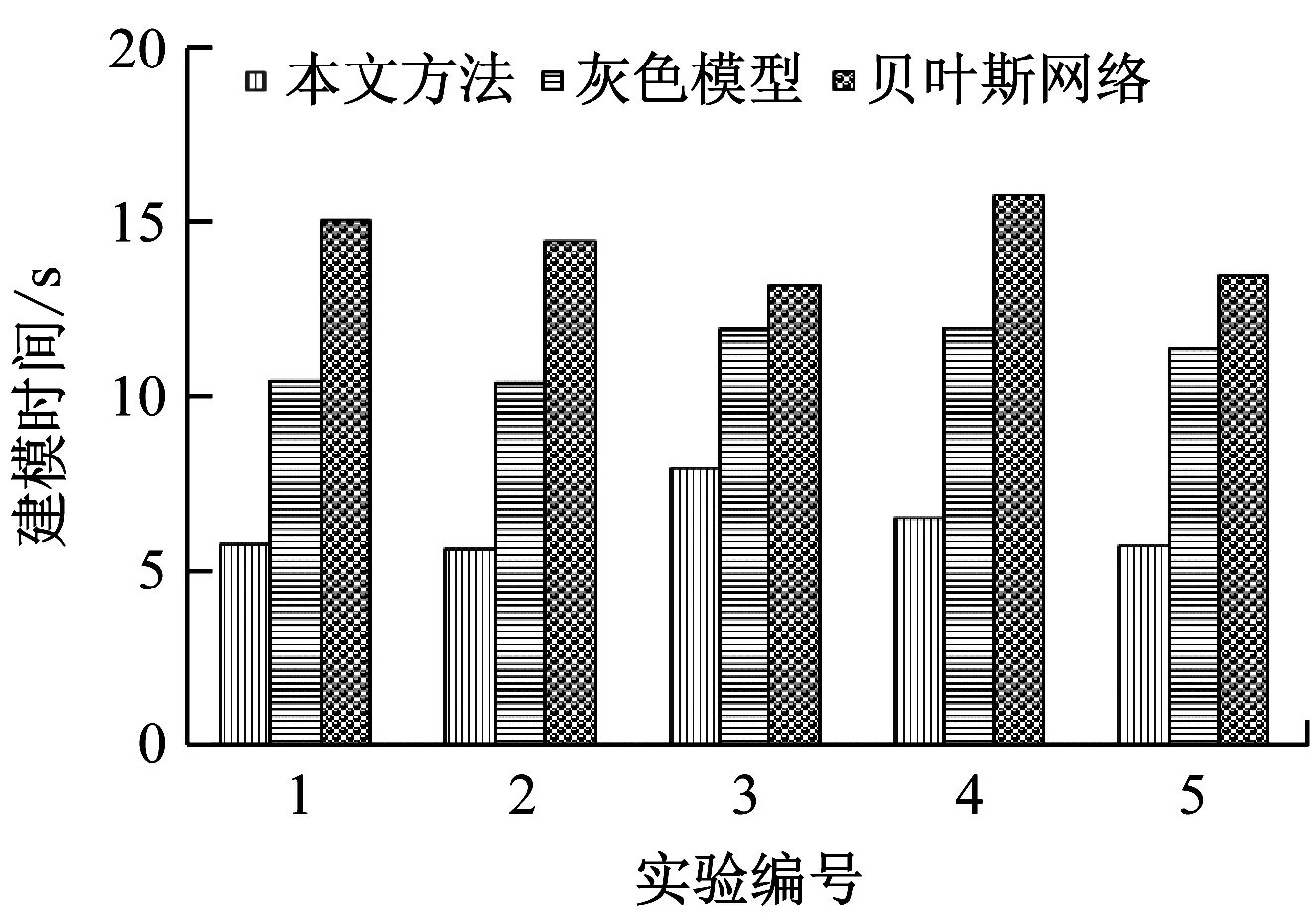
图4 财务信息管理系统风险识别建模时间对比
对它们进行分析可以得到如下结论。
(1) 在所有的方法中,灰色模型的财务信息管理系统风险识别效果最低,这主要因为灰色模型方法是一种简单的线性建模技术,不能全面描述系统风险变化规律,财务信息管理系统风险识别结果不理想。
(2) 基于贝叶斯网络的财务信息管理系统风险识别效果要优于灰色模型的财务信息管理系统风险识别效果,减少了灰色模型的财务信息管理系统风险识别误差,但是贝叶斯网络同样存在缺陷,如财务信息管理系统风险识别结果不稳定,可靠性差。
(3) 数据挖掘的财务信息管理系统风险识别效果要优于灰色模型和贝叶斯网络,减少了财务信息管理系统风险识别误差,大幅度降低了财务信息管理系统风险的拒识率,财务信息管理系统风险识别结果更加可靠,克服了传统方法的不足,验证了数据挖掘的财务信息管理系统风险识别方法的优越性。
(4) 数据挖掘的财务信息管理系统风险识别时间少于灰色模型和贝叶斯网络,财务信息管理系统风险识别效率得到明显的改善。
2.4 稳定性仿真分析
稳定性也是评价一个财务信息管理系统风险识别方法性能的重要评价指标,因此选择100个财务信息管理系统进行风险识别,统计它们的财务信息管理系统风险识别正确率和拒识率,如图5所示。
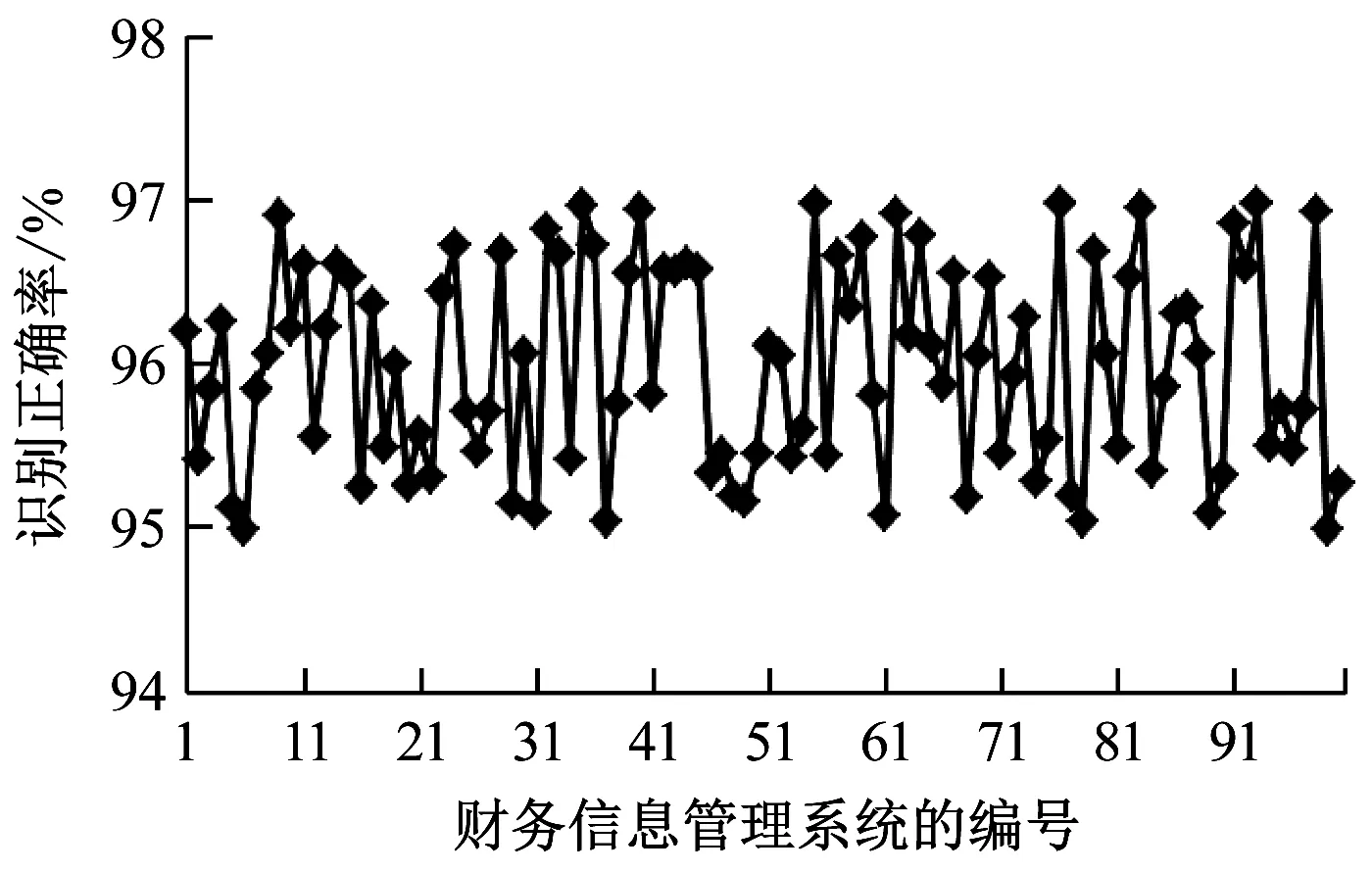
a 识别正确率

b 拒识率
从图5可知,数据挖掘的财务信息管理系统风险识别正确率超过95%,财务信息管理系统风险拒识率控制在了10%以内,具有较好的稳定性,可以广泛地应用于各种财务信息管理系统风险的识别中,具有较高的实际应用价值。
3 总结
财务信息管理系统风险识别研究具有十分重要的价值,成为当前财务领域研究的一个重大课题,传统方法无法全面、科学描述财务信息管理系统风险的变化态势,它们的识别结果十分明显,无法保证财务信息管理系统的安全,为了获得理想的财务信息管理系统风险识别效果,本文设计了基于数据挖掘的财务信息管理系统风险识别方法,与其他财务信息管理系统风险识别方法的对照结果表明,数据挖掘可以客观跟踪财务信息管理系统风险的变化态势,建立了高正确率的财务信息管理系统风险识别模型,并缩短了财务信息管理系统风险识别时间,可以为财务信息管理人员提供有价值的参考信息。
