基于RNN的房地产估价回归模型
2021-06-24谢志伟
谢志伟
(东莞职业技术学院 计算机工程系, 广东 东莞 523808)
0 引言
对大多数人来说,住房一直是最大的开支之一。买房是一个高度参与的决定。消费者对房产价值的判断和对房产未来价值的估计,会影响他们的购买决策和预算分配[1]。此外,房地产价格是反映经济活动的重要因素之一。因此,对土地价格的准确预测,可以帮助政府或企业在未来的财政年度内做出操纵财务状况的关键决策。从这个角度看,房地产价格的测算过程与人们的生活和国民经济息息相关[2]。
自动估价模型(AVM)是在分析房地产的区位、周围条件和特性的基础上,对房地产市场价值进行评估的数学程序[3]。房地产行业的一些企业提供了易于访问的AVM Web应用程序来估计房产价格,主要是基于套索回归(LASSO)和支持向量回归(SVR)[4-5]。但这些方法没有更多考虑房屋本身的属性,如房间数量、房屋大小和房屋的装修情况等。所以为了更加准确地评估房产价格,在此基于递归神经网络(RNN)和房屋自身属性,提出了一种新的房地产价格评估方法。同时,Boosting树模型作为数据分析竞争中一种很有前途的机器学习方法[6-7]。因此,在本研究中,为了使结果更加准确,通过RNN网络模型与Boosting树的一种变体,XGBoost模型相结合,对房价进行预测。
1 基于LSTM和XGBoost的模型
在本节中,简要介绍所提出模型的主要组成部分。首先,介绍RNN中的长期短期记忆(LSTM)的基本体系结构,然后介绍了XGBoost模型。
1.1 长期短期记忆
在自然语言处理(NLP)中,整个句子被定义为顺序数据,每个词都基于对先前词的理解。当人工神经网络执行自然语言处理时,它需要一种结构来根据句子的上下文来推理下一个单词,该结构将先前的输出作为推论的输入进行组合。递归神经网络(RNN)是用于处理顺序数据的一系列神经网络[8-9]。
RNN结构示意图如图1所示。
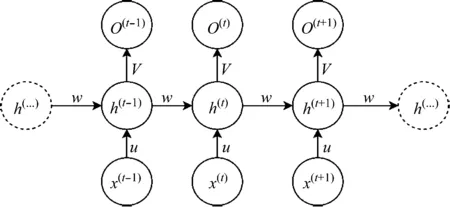
图1 RNN结构示意图
图1说明了简单RNN的结构。{O(1),…,O(T)}是给定输入序列{x(1),…,x(T)}和隐藏单元的神经网络的隐藏层{h(1),…,h(T)}。来自输入单元的单向信息流到达隐藏单元,而来自隐藏单元的另一单向信息流到达输出单元。h(t)是基于当前输入层的输出和先前隐藏层h(t-1)的状态来计算的,估算方法如式(1)。
h(t)=f(Ux(t)+Wh(t-1))
(1)
式中,f表示非线性激活函数,如tan或ReLU,具有共享参数U,W。O(t)是步骤t的输出,它取决于当前神经元的激活函数,如式(2)。
O(t)=σ(Vh(t))
(2)
式中,σ表示输出层的激活函数。
从理论上讲,RNN可以从句子开始处理上下文,这样可以更准确地预测句子结尾的单词。然而,序列长度越长,隐藏层就越多,这就产生了消失梯度问题,从而阻碍了RNN的优化[8]。
LSTM是解决这个问题的架构[10],每个LSTM将整个神经网络分割成多个单元{C(1),…,C(T)},如图2所示。
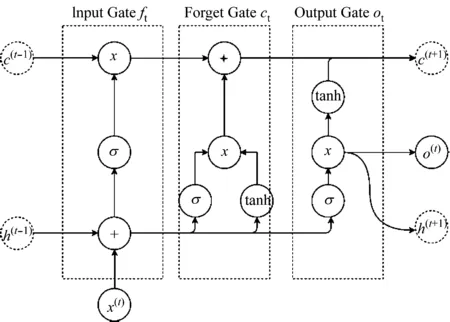
图2 LSTM的结构
每个单元包含输入门、遗忘门和输出门,其能够在正向传播阶段存储错误。遗忘门将误差从单元中删除,以求解消失梯度。
Wf、Wc和Wo分别是输入门、遗忘门和输出门的对应参数。输入门将电流输入和先前的输出结合起来,在神经元中使用激活函数σ和偏置bf。然后,tan为单元值创建新的候选值,并分别用偏差bi和bc与先前的更新决策值进行比较,如式(3)—式(5)。
ft=σ(Wf[h(t-1),x(t)]+bf)
(3)
(4)
ot=σ(Wc[h(t-1),x(t)]+bo)*tan(ct+ft)
(5)
1.2 XGBoost原理
XGBoost是Boost算法的一种,是基于gradientboosting框架实现的[11-12]。它是一个分布式梯度的优化增强库,由很多分类回归树组成。由于XGBoost可以进行多线程计算,所以它具有运算速度快、体积小的特点[13-14]。XGBoost算法核心是为了拟合前一次迭代中实际值和预测值的差,所以在每次迭代的过程中都会增加一棵树,从而让预测值不断接近真实值。然后每棵树的总得分就是该样本的得分。XGBoost的预测值计算如式(6)。
fg∈F,r∈n
(6)
(7)
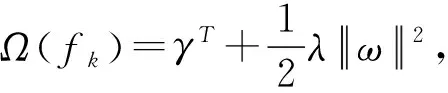
(8)
式中,P表示损失系数;C表示损失因子;V表示分裂的节点数。在XGBoost中判断节点是否进行分裂的方法是通过分裂后的左右节点的分数减去未分裂的节点分数。由于XGBoost中利用正则化因子来限制树的增长,所以当收益小于正则化因子时,节点分裂则停止。整个XGBoost的流程如图3所示。
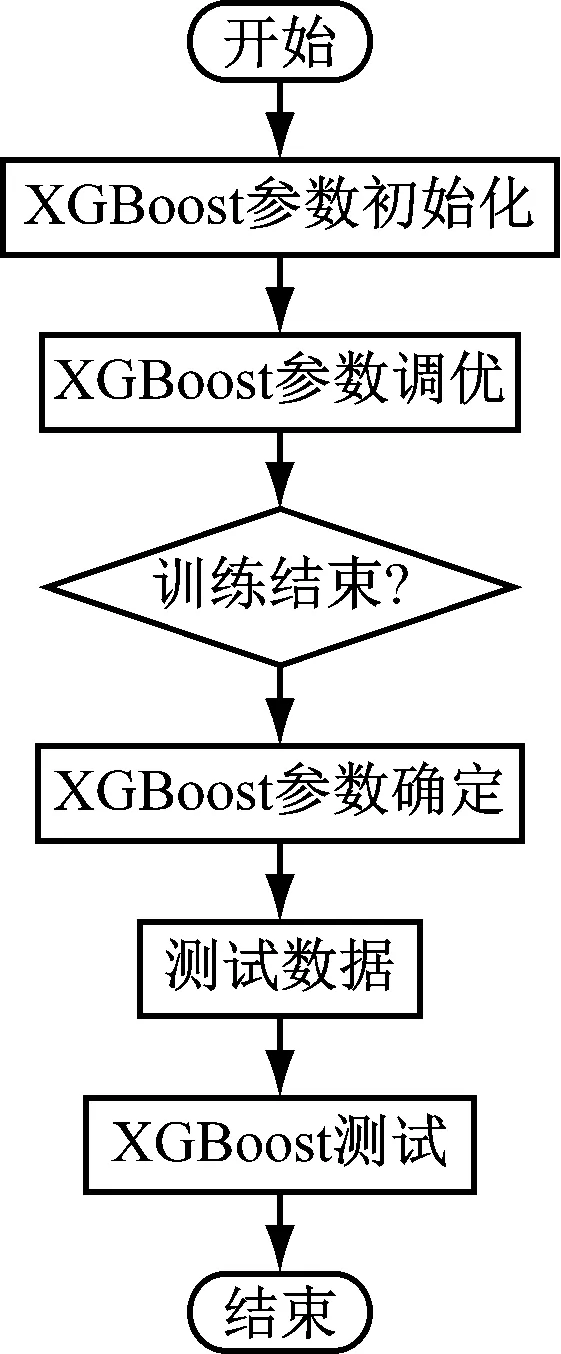
图3 XGBoost预测流程图
2 模型建立
一般来说,图像包含的有价值的信息不能简单地写下来,例如,属性的质量或状态是什么?它看起来如何?这些颜色是否很好地融合并增强了房屋的外观和感觉?所以在此,希望有一个图像评估模型可以给定一个图像作为输入,自动分配一个评分,可以模仿人类来观察和欣赏其价值,并从不同的图像中评估房屋属性。
2.1 数据预处理
由于相关房屋照片的尺寸大小不一,所以在进行特征提取之前,需要对图片数据进行预处理。首先先要将图片尺寸统一,在此,LSTM网络的输入尺寸是244×244像素的图像。同时,由于提出的LSTM网络需要对房屋多个属性进行评分,因此,在此将输入的图像切割成122×122像素的4个小图像。
由4个小图像构成整个大的输入图像,如图4所示。

图4 LSTM输入图像示例
同时,由于房屋图片存在通过调亮光线进行美化的情况,因此,为了使得整个模型对房屋的评估更加准确,所以对于美化过的房屋图片需要进行反美化处理。为了确定图像是否经过光线增强处理,首先需要统计同一房屋其他区域的图片及相似房源的图片的光线强度。因此,将原RGB图像转为YCbCr图像,然后计算每一幅图像的光亮值,对参考图像的光亮值进行平均处理,确定阈值。如果高于阈值则说明该幅图像经过美化处理,需要调低光亮,如图5所示。





该图显示了去美化前后图像对比。
2.2 特征的选择和提取
尽管网上的房产图片可以对一栋房子进行整体评价,但却不能捕捉到一些特征,如窗户、门、镜子、屋角等。文献[15]指出,从房地产图像中提取视觉特征与正常属性有显著关系,可以提高房价估计的准确性。因此,利用RNN神经网络中的LSTM网络进行图像的特征提取和视觉特征学习。
输入层是对应的视频帧特征向量,在输入层上层是正向的LSTM层,由一系列的LSTM单元构成。再将全部时刻的LSTM输出进行加权平均操作后的结果作为上层的表示。最后通过softmax层,进行全连接的操作。
数据集中有太多用于建模的变量,选择这些功能有两个原因。一是特征集过大会使算法速度变慢;二是当变量的个数明显高于最优值时,会导致机器学习的不精确性。因此,根据真实性和相关性来选择最佳特征是至关重要的。Boruta是一种基于随机森林的特征选择方法,并应用于我们的实验中进行特征提取。在特征选择之后,只有部分特征被用来构建模型。特征选择的结果包括有楼房单元号、屋顶类型、房间数、附加设施和地址等一系列与房产有关的因素。
每个特征的相关属性都有不同数量的图像,其中有些属性有5个图像,有些属性有大约35个图像。通过对现有的数据进行统计,大部分记录都有10到30幅房产图片。对于构建此模块,将删除少于10个图像或多于30个图像的属性记录。受文献[16]发表的神经图像评估的启发,属性平均质量评分可以定义为式(9)。
(9)
式中,M表示每个属性的图像总数,对于这个实验,M被设置为5≤M≤30,因为大多数属性都在这个范围内;S表示1到10的评分等级,所以S的范围为S∈[1,10];N表示总分列数,通过大样本分析,N设置为10,这意味着它有10列评分;P表示每个评分的响应百分比。
2.3 价格预测
这一部分说明了房价预测模型的具体流程,该模型结合了一些用于房价预测的特征。混合模型包括在数据集上预先训练的LSTM模型,具有softmax功能,用于评估房产图像,并给出总体房屋评分;激活校正线性单位(ReLU)以分析表格数据集/数字特征;另一个具有ReLU激活功能的LSTM模型用于从属性图像中提取视觉特征,作为属性评估的附加属性;用XGBoost预测房地产价格。
3 实验与评估
3.1 实验环境与数据
本文的实验环境是基于一台联想ThinkPad笔记本电脑,其处理器为英特尔I7处理器,显卡为英伟达Quadro T2 000,内存大小为16GB,系统为windows 10 64位系统。
在整个实验中,数据都是来自于Data Nerds的数据库。收集的数据来自美国最大城市之一的伊利诺伊州的芝加哥市,以及美国房产的多重上市服务系统中的图片数据。本节介绍如何与SVR和LASSO回归相比,对数据进行预处理和评估所提出的模型。整个数据集随机分成抽取80%的数据作为训练集,剩下20%的数据作为测试集。
3.2 数据集预处理
美国房价指数(Housing Price Index,HPI)数据集由联邦政府提供。整个数据集包含1979年至2019年美国所有地级市的所有HPI。在这个实验中,我们提取了芝加哥邮政编码级别的60个HPI系列。
原始数据集包含许多变量,如房屋质量,房产地理信息。它还包含了房价随时间变化的交易记录。在这里,只选择了2017年内,并通过HPI将2018年和2019年的价格转换为该实验的真实数据。在全市范围内筛掉了价格极高或极低的房子,筛选数据的摘要如表1所示。

表1 芝加哥的平均价格和标准价格偏差
为了训练和验证提出的模型并防止过度拟合,采用了5倍交叉验证技术。该算法将完整的数据随机分成五个子集。一个唯一的子集作为测试的验证数据,其余四个子集用于每个验证过程中的训练。经过5倍交叉验证,我们可以得到每套房子的预测价格。
3.3 训练方法
模型训练过程,如图6所示。
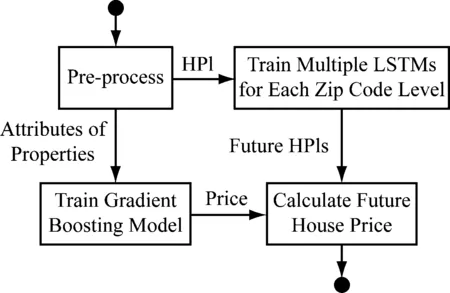
图6 模型训练过程
首先,预处理后的过滤数据包含1979年至2017年的房屋和其属性,如前所述。其次,采用多个LSTMs分别对每个邮政编码级别的HPIs,以及房屋自身照片进行评分和预测。它是一个具有4个激活ReLu神经元的单隐层LSTM,窗口大小是3,这意味着预测HPI是由前3个HPI预测的。同时,XGBoost模型有义务根据房产属性预测2017年的房价。最后,利用预测的2017年的结果对2018年和2019年的房价进行评估。
3.4 评估模型和实验结果
模型对于不同房屋的评分结果如图7所示。
由图7可知,两个房屋的评分均显示在卧室图片中,可以看到(a)图的评分高于(b)图,这与实际结果也是相同的。
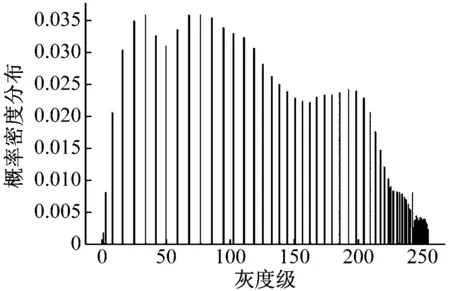
(a) 未处理的图像及其均衡化直方图
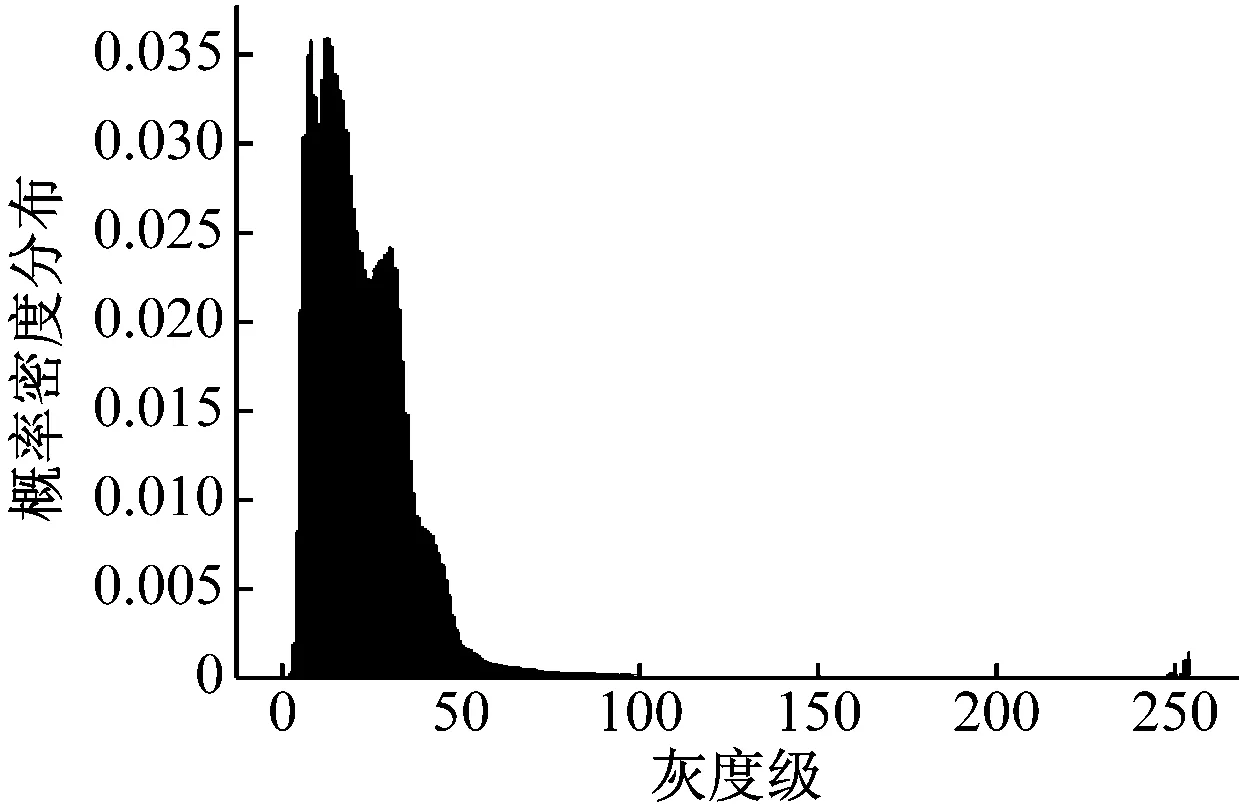
(b) 反增强后的图像及其直方图

(b) B房屋卧室图

(a) A房屋卧室图
在整个评估过程中,所采用的评价指标为平均绝对误差(MAE)和平均绝对百分比误差(MAPE)。两个度量的定义,如式(12)、式(13)。
(12)
(13)
式中,turei表示真实值;predi表示预测值。
在此使用相同的训练和测试集来评估所有的模型。所有不同模型的回归结果如表2所示。
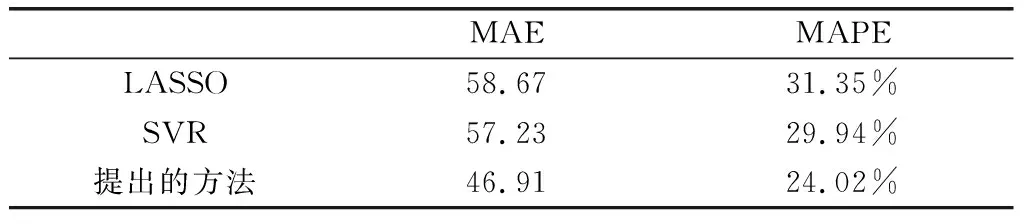
表2 结果比较
结果表明,提出的方法,相对于LASSO回归,误差减小了近15%,相对于SVR回归,误差减小了10%,所以该模型比其他两个模型具有更好的性能。
4 总结
本文提出了一种用于房地产估价的集成学习回归模型。该模型能够综合考虑房屋质量、区位和市场价格走势。实验结果表明了所提出方法是有效的,也为深度学习方法与统计学习算法的集成提供了一种新的途径。这也说明了深度学习在房地产领域具有广阔的未来。
