基于多任务学习的轨道车辆轴承异常检测方法
2021-06-24蒋雨良曾大懿邹益胜卢昌宏张笑璐
蒋雨良,曾大懿,邹益胜, ,卢昌宏,张笑璐
(1.西南交通大学 机械工程学院先进设计与制造研究所,四川 成都 610031;2.西南交通大学 轨道交通运维技术与装备四川省重点实验室,四川 成都 610031)
轴承是轨道车辆重要的旋转部件,随着列车在交路中运行,安装在车辆走行部上的各个轴承因承受各项激励而产生变化,当轴承出现故障时所引起的油膜不均匀、润滑失效等一系列状况往往导致轴承温度异常,因此对轴承的温度进行实时监测至关重要[1−4]。基于轴承温度的时间序列变化趋势进行建模,尽可能地提前对轴承进行预警,提前诊断轴承是否故障,对列车运行安全具有重要意义[5−6]。目前轨道车辆轴温异常检测的方法主要有3类:1)运用规则进行判别。如采用序列对比的方式,曹源等[7]基于仿真数据,使用基于动态时间规整的方法,能够识别仿真故障,杨云等[8]更进一步的在判别上加入证据理论,通过模糊数学的理念确立故障等级,并在实测数据上取得效果。2) 运用聚类方法进行判别。针对多列数据,聚类方法相较于序列对比更具效率,刘强等[9−10]运用动态内在典型相关分析,多模态动态内在典型相关分析等方法,能够对温度数据进行重构、变维,藉此识别故障轴温数据的异常变化情况。3) 运用预测方法进行判别。通过预测值与设置的阈值进行对比,王竹欣[11]使用了多元回归、随机森林、梯度回归树等多模型融合对轴温进行估计,判别轴温故障等级;谭思雨[12]使用长短时记忆进行轴承温升估计,进而判别轴承是否异常,建立模型预测轴承温度,通过将预测值与设置的阈值比较是针对列车各部件的常用做法;罗怡澜[13]将最小二乘支持向量基模型(LSSVM)预测得到的温度与同车关联轴承温度进行对比,依据设定的阈值进行判别。上述方法在异常检测过程中,设定阈值或判别准则受线路、环境等干扰较大,容易造成误判,同时预警的提前量往往不够。实际上,运用预测方法进行异常检测时还可以采用另一种做法:即首先基于机器学习等方法构建预测模型,提高预测精度,再通过预测值与实际值进行幅值和趋势等对比判别的方式,为改善以上问题提供了一种有效途径。侯冶等[14]将与电机相关的负载、转速等输入非线性自回归模型(NARX)预测温度,分析预测值与实际值变化,能够发现残差逐渐增加的趋势。本研究团队前期也采用预测方法的思路进行了尝试,以关联轴承温度作为输入预测单个轴承温度,能够提早发现轴承温度残差趋势在故障时的不同变化,但轨道车辆轴承型号不同且位于走行部不同位置,以某型号轨道车辆为例,一列车以8节或16 节为编组,一节非动力车的走行部上存在至少36 个轴承温度传感器,逐一训练模型极为耗时且维护困难。为此,本文提出基于多任务学习的轨道车辆轴承温度异常检测方法:1) 依据关联测点的方法,将走行部36 个轴承温度测点细分,同时对一轴上共9个轴承温度测点建立多任务学习模型进行预测并检测;2) 考虑到传统的循环网络模型运算效率低且难以考虑全局信息,使用自注意力机制构建并行运算模型进行预测;3) 使用极大似然估计方法与点预测模型结合的方法,将点预测模型转换成概率预测模型,求得置信区间,依据置信区间作为判别准则指导轴承温度异常检测工作。
1 轨道车辆多轴承异常检测方法
本节提出基于自注意力机制的多轴承异常检测方法。首先阐述轨道车辆走行部采集的温度信号,说明关联测点的具体方法,然后对整个神经网络结构进行解构,说明网络各个部分的作用。
1.1 关联测点
轨道车辆装有多个能够实时返回车体情况不同规格的传感器,其中轴承温度传感器位于轨道车辆走行部的转向架两轴上。轨道车辆在运行中,走行部不同部位间承受相似的激励与载荷,因此不同轴上同测点之间的温度呈现高度线性相关[8,13]。
以图1某轨道车辆为例,按照每节车辆转向架共四轴的设置情况,每轴有9个测点,动力车一轴仅有轴箱2 个测点,一节车共8 个温度测点;非动力车一轴分别有轴箱2 个测点、电机3 个测点和齿轮箱4个测点,一节车共36个温度测点。

图1 轨道车辆温度测点分布Fig.1 Distribution of temperature measuring points for railway vehicle
关联测点是分布于4 个轴上同位置的温度测点,其温度的线性相关程度高。对轴承温度进行异常检测,无论采用对比还是聚类的方法,关联测点都能体现正常态与故障态的差异性。
轴承发生故障导致异常温升的同时,也会对同轴上的整个传动链产生影响致使传统链上其他轴承发生故障,使得基于自回归的预测方法难以体现故障趋势,将运用于对比、聚类的方法中的关联测点用于预测,考虑到故障和正常时关联测点的关联性存在不同,运用关联轴承温度作为输入预测本轴上轴承温度,能够避免传动链对各个轴承造成的故障影响网络预测。
1.2 多任务学习
多任务学习属于一类迁移学习领域的学习方法,通过假设不同任务数据分布之间存在一定关联,在此基础上通过共同训练和优化建立任务之间的联系[15]。这种训练模式充分促进任务之间的信息交换并达到了相互学习的目的,在缓解因反复训练模型、调整超参数导致的大量时间消耗之外,也达到了提升各自任务性能的目的。
轴承温度异常检测方法中,一节车辆36 个轴承,依靠对比分析或是单任务学习的方式建模,需要针对每个测点进行建模,从而耗费大量的时间在训练模型上。运用多任务学习的方式建立预测模型,对转向架单个轴不同类型的轴承进行统一预测,有助于关联测点数据的相互运用,也提升了模型的泛化能力,将原本需要一节车36 个单任务模型转换为4个多任务模型。
多任务模型如图2所示,以单个转向架前后车轴为例,运用1.1 节中所提的关联测点作为输入可构建单任务模型,转向架上的两轴相互关联,车轴上共9 个温度测点的温度作为输入预测另一轴9个测点的温度,多个测点能够增加模型置信度,获得更高精度的模型。
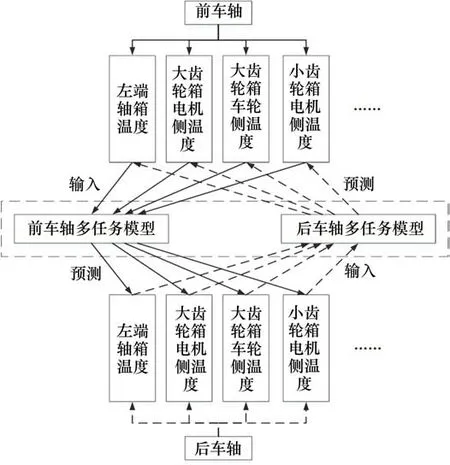
图2 多任务模型Fig.2 Multi-task model
1.3 多头自注意力机制
VASWANI 等[16]于2017 年提出了Transformer模型运用了多头自注意力(Multi−head self−atten‐tion)机制,注意力机制的实质在于模拟观察行为,对时间序列等数据进行资源分配,相比于需要递归循环才能理解全局信息的循环神经网络,或是需要扩大感受野才能了解更多信息的卷积神经网络,注意力机制运用类似点积运算地方式,可更快实现网络地并行化计算,极大程度上加快运算效率,并减少内存占用。
注意力的方程式:


通过将这个过程反复独立进行几次,每一次获得不同的结果,拼接起来为多头自注意力,其公式为:

1.4 极大似然估计
极大似然估计方法(Maximum Likelihood Esti‐mate,MLE)是求估计的一种方法,通过总体的分布类型,求取参数空间。
设数据分布表示为θ,似然函数表示为l(y|θ),在本文中轴承温度数据为真实环境采集数据,拟合分布采用Gaussian分布,则分布符合公式:

式中:μ为均值;σ为标准差在网络模型中,为保证标准差在模型中恒定大于0,选用softplus激活函数,均值采用线性激活函数。
1.5 网络构建
在通常的时序预测中,会将点预测作为最终的输出结果,然而点预测的方法难以直接指导诊断或预测,仅能通过蒙特卡洛模拟等方式将点预测模型转化为概率区间预测模型。
假设每个时间步上的目标值yn服从概率分布l(yb|θn),训练时使用多头自注意力机制分配注意力,再计算概率分布的参数θn,最后通过极大化对数似然L来学习网络参数,依靠注意力机制,不再需要如循环神经网络递归计算每一个时间步长,而是一次性计算所有时间步长上的θn:
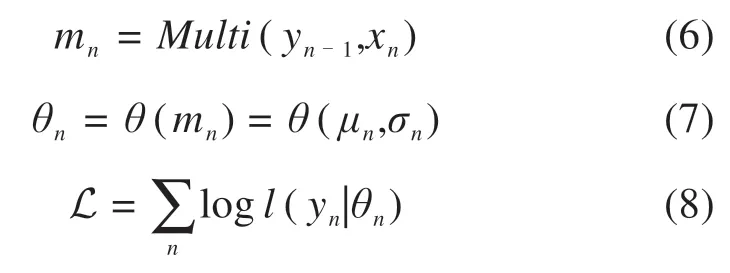
所预测的序列在每个时间点不能使用未来的信息进行预测,因此注意力机制也有部分变动,公式为:
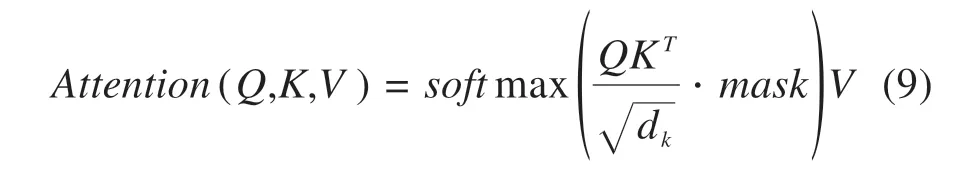
mask为掩码,将注意力矩阵的上三角元素置为-∞。
验证模型时则通过求得的概率分布得到分布的区间,求得分布区间的均值和标准差,得到预测值的置信区间。

多任务的损失函数如式(10),式中:αi表示第i类任务的权重,M表示样本数据量,为预测值,yn为实际值,每个任务都进行误差衡量,本文运用了极大似然估计,因此求取使得分布最接近实际值的模型以获得最优模型参数。
2 模型验证
轨道车辆遵循各个运用所的调用规则,在不同的交路上进行往返切换。为了体现模型的精度以及异常检测的有效性,本文在正常与故障多个数据集上进行验证,在正常数据集上对比算法、多任务与单任务的优劣,并画出预测数据的置信区间;在故障数据集上主要体现异常检测能力,表明方法能够依据算法直接判别是否异常的优势。
2.1 训练、验证和测试过程
轴承温度数据经传感器采集传回本地后先进行预处理,将数据中存在的异常值、缺失值进行清洗,清洗数据之后将数据集进行7:3 划分训练集和验证集,测试集为了体现在实际场景中运用模型,选用与训练集和验证集中不相关车的数据,包含正常工况与异常工况,证明模型具有足够的泛化能力与异常检测能力。
基于数据增强的目的,对清洗后的数据设置了滑窗函数,滑窗大小均等于模型的输入/输出长度,训练集的滑窗步长设置为1,依据实时数据实时检测的形式,验证集、测试集的滑窗步长设置为等于滑窗大小。整个过程如图4所示。

图4 流程图Fig.4 Flow chart
本文设置学习率为0.001,使用Adam 优化器进行优化,batch-size 为256,设置输入/输出长度均为10,多头自注意力头数为4,dv为64,全连接层大小为20,考虑到本文每个任务的属性相似且均为回归任务,给每个任务权重相等,本文均设置为1。
本文所有实验配置环境为Tensorflow 2.1.0,Keras 2.3.1 以及Python 3.6.10 进行实验,使用操作系统Windows10,CPU Intel 7-8550U @1.80 GHz,GPU NVIDIA GeForce GTX 1050,内存16G DDR4的计算平台进行建模。
2.2 正常数据下的精度、模型能力
数据集选用了某轨道列车连续半年行车采集数据,如图5 所示,采样频率为1point/min,为了获得模型最佳的泛化能力,将数据按照时间轴进行7:3 划分为训练集和测试集并滑窗增强数据集,使用同型号不相关的另一列轨道车辆行车所采集数据进行置信区间预测以体现模型泛化能力。

图5 某轨道列车连续多日不同轴承温度变化Fig.5 Temperature changes of different bearings of a rail train for several consecutive days
网络结构如图3所示,为了验证多头自注意力机制的有效性,将该网络层分别替换成RNN,GRU 和LSTM 进行对比,考虑到循环神经网络需要递归才能遍历数据,对每个循环神经网络都使用双向功能,以保证模型能尽可能获取全局信息,算法对比的Loss如图6。

图3 网络结构Fig.3 Network structure
Loss 为最大似然,由图6 的Loss 可知:RNN作为最初始的循环神经网络单元,在迭代中会快速过拟合,GRU 与LSTM 具有类似的性能,保持验证集的Loss 在大致相同的范围,注意力机制则能够达到比所有循环神经网络更低的Loss值。
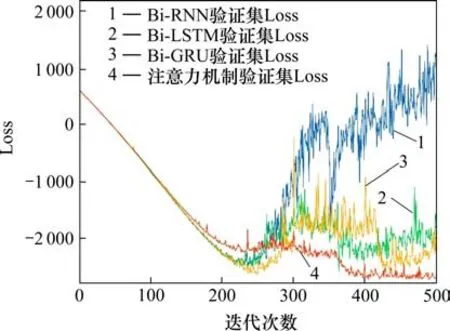
图6 Loss下降对比Fig.6 Comparison of loss decrease

表1 算法参数量、训练用时及测试用时对比Table 1 Comparison of algorithm parameters,training time and test time
对比算法所占用的参数数量以及训练、测试所用时间,也可以发现循环神经网络所特有的递归式原理使得模型需要更长的时间训练整个网络,相比之下,注意力机制采用点积运算并行处理整个时间序列,能够极大程度减少训练时间。综合考虑模型训练时间,参数量等因素,注意力机制能够在数据相同的情况下经同样迭代次数达到对比网络中验证集的最低Loss 值,这说明该网络学习全局信息的能力更强。
上述算法的对比运用了多任务模型,为了验证多任务模型相比于单任务模型更有优势,将多任务中与单任务中相同任务的Loss进行对比。
如图7所示,以小齿轮箱车轮侧轴承为例,对比多任务模型其中一个单任务的Loss 与单任务模型的Loss,多任务Loss 值能够在迭代过程中更快速地下降,而单任务模型的Loss 值则会在一定程度地下降后保持稳定,多任务模型在多个轴承测点上均能达到上述效果,这说明多个任务之间特征相互交互,所获得的拟合能力显著地超越了单任务,能够帮助模型进一步达到更高拟合精度。

图7 小齿轮箱车轮侧轴承单任务与多任务Loss对比Fig.7 Comparison between single-task and multi-task for wheel side bearing of small gearbox

表2 一节车辆建模消耗时间对比Table 2 Comparison of vehicle modeling time consumption
将一节车辆的每轴9个轴承分为轴箱、齿轮箱和电机3 类,一共4 根轴则对应4 个多任务模型,相比于单任务模型,多任务模型在训练时间上只消耗了单任务模型12.39%的时间即可完成整节车辆的建模,极大幅度提升了建模效率。
轴承温度预测出的置信区间如图8所示,因为预先设立数据分布符合Gaussian分布,预测值为所取Gaussian 分布的均值,置信区间取(μ-2σ,μ+2σ),数值分布在该范围内的概率约为95.44%,对于正常数据集,可发现大部分数据均落在该范围内,同时直观对比了注意力机制与Bi-RNN 的置信区间,可知在数值分布上注意力模型能够保有更精准分布形式,缩小σ的取值范围。

图8 轴承温度置信区间Fig.8 Confidence interval of bearing temperature
2.3 故障数据下的异常检测能力
故障数据来源于某同型号不同车次轨道车辆,该车三轴最终小齿轮箱电机侧温度异常升高至报警线触发报警导致列车降速停车,同时引发三轴多个测点的温度异常,从温度信息可知,一个轴承测点异常温升会导致同轴其他测点出现类似异常,造成同轴多点复合故障,提早检测出温度异常可避免该类情况。
从图9列举的部分轴承异常温升数据看,导致轴承大幅度异常温升最后触发报警的故障在前期已有离群的趋势,部分测点的异常则是紧急停车制动后的突然变化导致了温度异常。
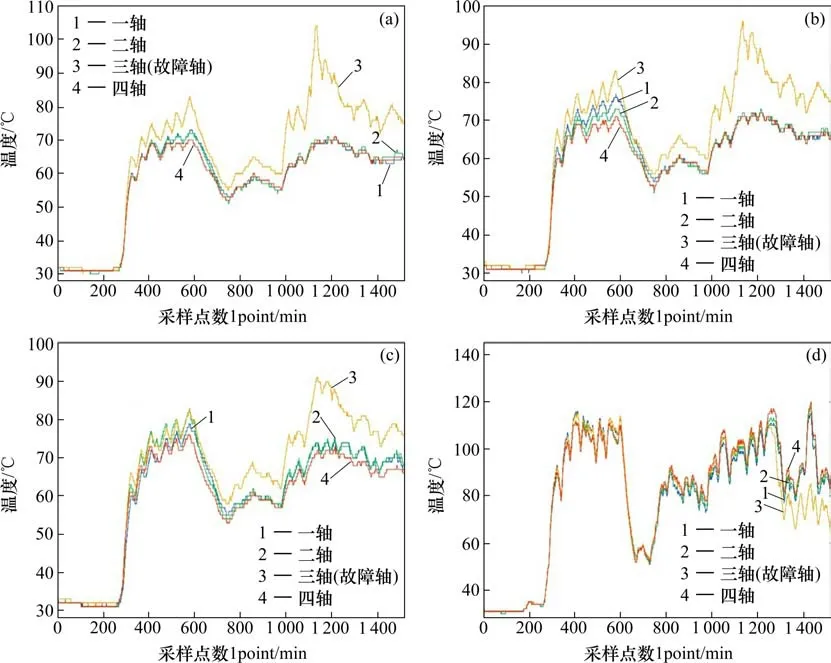
图9 发生故障当天各轴数据Fig.9 Data of each axis on the day of failure
使用本文提出的模型对三轴测点进行预测,所得到的结果如图10。

图10 故障轴数据置信区间Fig.10 Confidence interval of fault axis data
按照在异常温升最高点报出故障作为现行阈值预警方法,以本文方法报出故障的起始点作为开始,将截止现行阈值预警方法报出故障之前所有报出异常的故障轴上轴承时间进行统计后的结果进行整理,如表3所示。
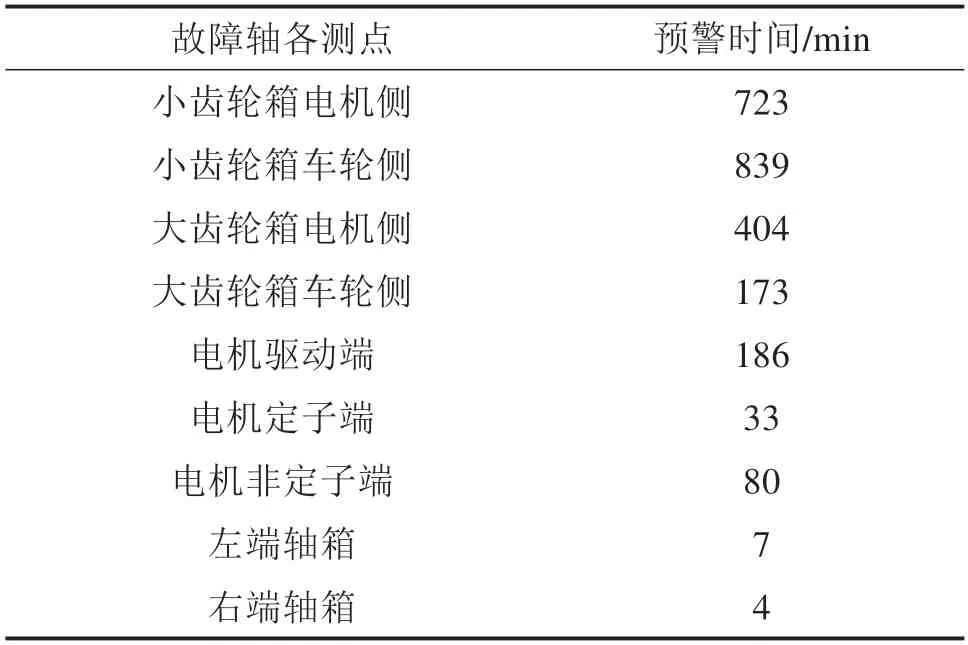
表3 异常持续时间Table 3 Abnormal duration
齿轮箱各个测点的报警时间最长,同时小齿轮箱的报警时长高于大齿轮箱,这说明故障是由小齿轮箱的某部位引起的,并随着各个部位的协同传动导致了故障逐渐扩散到其他部位,电机、轴箱相对离齿轮箱较远而异常情况较少,从传动链上电机距离齿轮箱更紧密,致使报警时间仍高于轴箱。
3 结论
1) 以关联测点作为输入,构建的基于多头自注意力机制的多任务模型,极大减少了一节车的模型数,并使得每个模型具有同时检测多个轴承的能力;同时结合点积运算的方式,极大程度减少了运算时间,有效降低了运算成本;
2) 在现有点预测模型的基础上,使用极大似然估计法将点预测模型转为区间预测模型,直接输出数据置信区间辅助算法判异,赋予模型直观可理解的涵义;
3) 提出的方法有效降低了轴承温度异常检测建模和实际运用所需时间,并构建了无需考虑环境、车况等多项变量的判别指标,成功运用在相同车型的轨道车辆走行部,在多个轴承故障数据上依据温度提前检测出轴承故障。
