城市故障共享单车回收路径优化
——以摩拜单车为例
2021-06-24许美贤
许美贤,郑 琰
(南京林业大学汽车与交通工程学院,南京 210037)
共享单车行业的蓬勃发展极大地方便了人们的出行,但是新兴事物运营过程难免会导致各种各样的问题。在共享单车初始发展阶段,企业为了抢占市场,耗费巨资生产大量车辆进行投放,而且每家企业运营模式基本一致,导致供给远远大于需求。而在投放使用阶段,政府和企业缺乏相关运营管控经验,由于乱停乱放、人为毁坏、系统故障等因素导致共享单车的故障率不断上升。故障共享单车的出现以及回收的延时性,不仅会造成大量坏车堆积,严重占用城市空间资源,还将危及用户的人身和信息安全,降低运营企业的服务质量,这些问题都阻碍着共享单车系统的持续健康发展。因此为了解决故障车辆对用户、企业、社会带来的影响,及时回收数量庞大的故障共享单车来进行维修或更新成为当务之急,而合理优化故障车辆回收路径,提高回收效率等研究已成为学者和企业关注的焦点问题。
近几年关于共享单车的研究大多数是分析其发展状况、盈利模式、监管措施等几方面,但对于故障共享单车回收问题的研究较为少见,仅有的也只在文字叙述上展开讨论,并不能把定量数据和定性分析相结合,如Liu等[1]在对固体废弃物治理方案的理论基础上进行梳理后,认为造成共享单车故障率偏高的主要因素是车辆本身质量问题及系统的不完善,同时明确了共享单车在现代交通中起到的重要作用,因此针对废旧共享单车回收问题提出了一种回收二阶段法,旨在提高故障共享单车回收效率; Wang等[2]提议以整体效益最大化为目标,减少个人遗憾等因素对回收成本的影响,引入第三方物流供应商助力回收工作,优化回收管理流程从而达到最大限度地提高回收效益的目的。这些文献研究深度大多停留在探究影响故障车辆回收因素的表面上,鲜有能够全面系统地针对故障共享单车回收问题优化服务进行深入分析。
因此,现主要针对城市故障共享单车回收问题进行优化研究,通过构建科学的故障共享单车回收框架,并利用K-means算法对回收维修服务中心区域内的故障车辆进行聚类处理,形成初始服务节点。以回收总成本最小为优化目标建立路径优化模型,并设计改进的蚁群算法对所建模型进行求解,分析满载率大小和聚类服务节点个数对优化结果产生的影响,验证模型和方法的可行性。
1 问题描述
1.1 故障共享单车定义和分类
把共享单车故障车辆定义为在运营过程中因车辆发生损坏而无法保障正常骑行、存在安全隐患的车辆。另外为了更好地开展后续回收问题的研究工作,有必要对故障共享单车进行分类处理,将其分为三大类。
(1)由于人为毁坏、车辆自身缺陷等因素造成的不符合安全标准的故障单车(类型一)。这类车辆通常可以由用户扫码解锁时被识别出来,如果用户发现将要使用的车辆存在二维码丢失或损坏、无法解锁等问题,可以马上在手机APP进行报修,运营企业的线上运维系统就能确定故障单车的设备信息和地理位置,及时进行回收处理。
(2)超过规定使用年限,强制要求报废更新维修的故障单车(类型二)。政府规定共享单车的正常使用寿命是三年,在车辆投放市场超过规定期限后,无论车辆是否丧失使用价值,所有共享单车都必须进行回收更新。企业的运营管理系统能够根据市场投放时间自动识别此类车辆,并列入故障单车名单,切换运行系统使得车辆无法解锁骑行,从而防止用户的误骑。
(3)因为车锁的GPS定位器损坏,而无法定位或定位不准的故障共享单车(类型三)。当企业运维系统对某辆共享单车的位置信息追踪不到时,通常都会将其标识为定位出现故障的车辆,智能查找位置信息记录条,追踪搜索此车辆上一次所在的地址和状态,并根据这些信息在邻近范围寻查故障单车。
1.2 故障共享单车的回收准则
故障共享单车回收依照着特定的准则,根据回收系统的4个组成要素:故障共享单车、初始服务节点、回收车辆、回收维修服务中心,设计了一个双层空间回收网络,该网络主要由上下两层平面网络构成,中间属于投影的连接[3]。
根据图 1故障共享单车的回收网络,分析回收过程需要依照的具体准则如下。
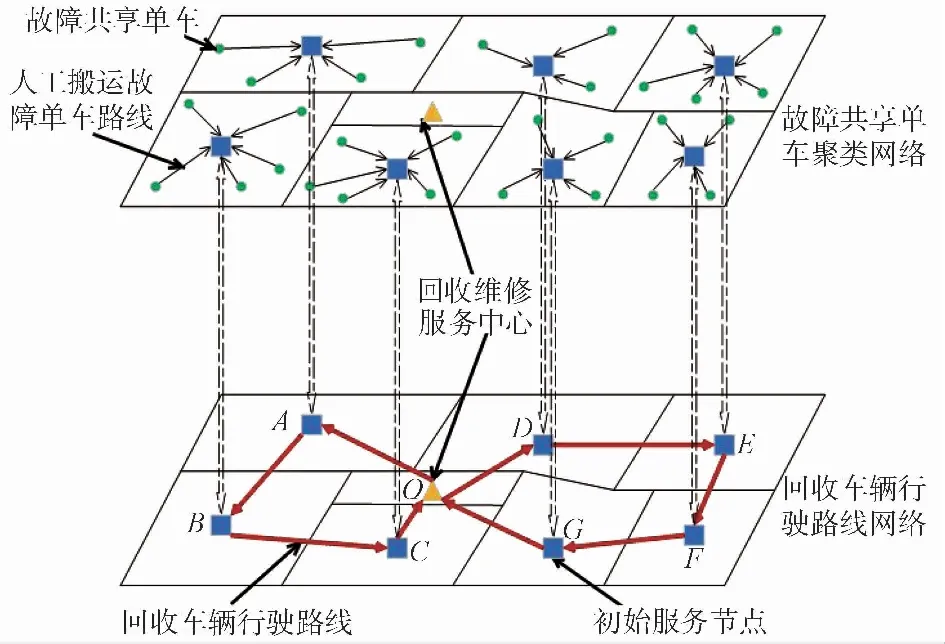
图 1 故障共享单车回收网络Fig.1 Unusable sharing bicycle recycling network
(1)在城市中,为了能够容纳大量的故障单车,需要规划设计若干个回收维修服务中心。每个回收维修服务中心承担着其管辖区域内的故障单车回收处理任务,设计规定在每个正常工作日对故障共享单车的位置信息进行数据统计,对出现故障单车数量较多的区域及时执行一次回收任务,而该区域中后续新增的故障单车则留在下一次再回收处理。
(2)在每个回收维修服务中心的管辖区域内,需要依据故障共享单车的数量和位置决定形成若干的初始服务节点,如图1中A点,在执行回收任务时,回收车辆停放在初始服务节点,搬运工人需要将一定区域中散落错乱的故障共享单车移送至该初始服务节点,当把该节点区域内的故障单车收集完成后,驾驶回收车辆访问下一个节点区域继续执行故障单车回收任务。
(3)在规划设计的若干回收维修服务中心内配备着一定数量的回收车辆,执行回收任务时,回收车辆会从某个回收维修服务中心内出发,访问历经每个初始服务节点,最后把收集到的故障单车全部送到回收维修服务中心,完成一次回收任务。
综上,故障共享单车的回收过程划分成两个环节:①先依据回收维修服务中心管辖区域内故障共享单车的数量和位置决定形成若干的初始服务节点,再把位置错乱的故障共享单车聚集在邻近的初始服务节点上;②运算设计出能够实现优化目标的回收车辆行驶路线,同时满足访问历经每个初始服务节点的要求。
1.3 故障共享单车的回收流程
结合上述对故障共享单车回收准则的分析,确定回收流程,主要包括四大步骤,如图 2所示。
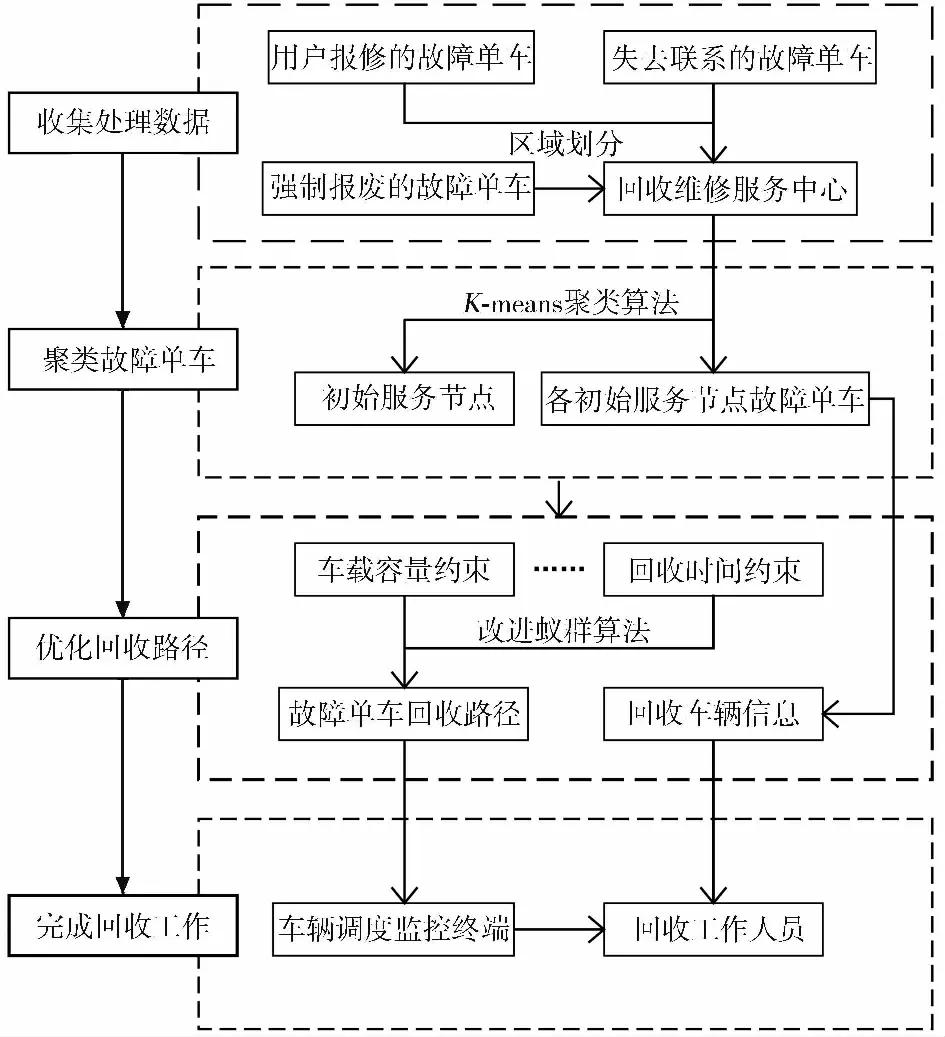
图 2 故障共享单车回收流程图Fig.2 Flow chart of unusable sharing bicycles recycling
步骤一收集处理数据。主要针对类型一和类型二的故障共享单车数量和位置信息进行收集,其中类型一在用户报修时即时登记报备车辆位置信息;类型二在运营企业系统中会自动记录其投放市场的起始时间,待超过规定使用年限时,及时纳入回收范围;而针对类型三需查找该种车辆上一次停放的地址,并据此在邻近范围追踪其数量和位置。当管辖区域内三种类型故障共享单车的数量和位置确定后,即可进行统计分析。
步骤二聚类故障单车。图 2中,上层平面网络就是故障共享单车的聚类环节。根据步骤一统计处理的结果,把回收维修服务中心管辖区域中的故障共享单车利用K-means算法实行聚类处理,算出的聚类中心就是根据每次回收情况可进行调整的初始服务节点,保障回收车辆能充分地访问遍历回收空间。搬运工人把节点区域的所有故障共享单车移送至初始服务节点。
步骤三优化回收路径。图 2中,下层平面网络就是规划设计出执行回收任务时,回收车辆从回收维修服务中心出发,遍历所有初始服务节点,最后返回至回收维修服务中心的最佳行驶线路。依据聚类处理的结果,设立故障单车回收总成本最小的优化目标,综合考虑回收车辆的车载容量限制、回收时间限制等约束因素的影响,规划设计出每辆回收车辆的最优回收路线。
步骤四完成回收工作。当确定初始服务节点和优化回收路径后,把回收工作分派给各车辆的工作人员,把聚类信息及回收线路传送至车辆调度监控终端,回收工作人员根据终端分配的任务按照优化方案逐一完成。
2 故障共享单车空间聚类
2.1 基于K-means算法的故障共享单车聚类模型
K-means算法适用于处理小中等体量的数据集,运算耗时短,复杂程度低。考虑到在选取初始服务节点时,需满足各故障共享单车到初始服务节点的距离总和最小化,以距离作为前提条件,同时收集的数据规模属于小中等体量,所以选取K-means 聚类算法进行初始服务节点的聚类分析,确定其数量及位置。
首先,假定由N个二维随机变量即x1,x2,…,xn组成样本数据集X={x1,x2,…,xn};其次,根据用户指定需要的聚类簇数K,把样本数据集X={x1,x2,…,xn}划分成K个类簇;再次,引进P={pk,k=1,2,…,K}的二维向量组,其中pk指的是第k个聚类中心;最后,计算样本数据点x1,x2,…,xn分配到各聚类中心pk的欧式距离,并保证最小化其距离的平方和。两次计算各个聚类中心的位置误差平方和公式为
(1)
s.t.
(2)
式中: SEE为各个聚类中心的位置误差平方和;tnk为0~1的整数变量。回收车辆的工作服务地点是各个聚类中心,需要利用K-means空间聚类算法进行聚类中心数量的求解[4]。
2.2 故障共享单车聚类步骤
使用K-means聚类算法对故障共享单车进行聚类处理,实际上就是在回收问题中选取初始服务节点[5]。求解流程步骤如下。
步骤一依据回收维修服务中心的管辖区域中故障共享单车的数据信息,输入用户指定的初始服务节点数量K以及故障共享单车样本数据集合(X={x1,x2,…,xn})。
步骤二在N个故障共享单车数据点中任意选取K个样本数据作为初始服务节点。
步骤三计算各故障共享单车数据点到初始服务节点的二维空间直线距离,并把故障共享单车数据点逐一分配给与之相距最近的初始服务节点上。
步骤四待分配完所有故障共享单车数据点后,再次运算确定K个初始服务节点在聚类后的中心位置。
步骤五对比分析聚类前和聚类后K个初始服务节点的位置信息,判断各初始服务节点位置是否有改变;若已经改变,重新回到步骤二;若前后两次各初始服务节点的位置均无改变,则进入步骤六。
步骤六输出聚类结果P={p1,p2,…,pk}。
3 故障共享单车回收路径优化模型
3.1 模型假设
由于回收过程相对烦琐,需要考虑的影响因素和涉及的参数数量都比较庞大。因此,为使后续研究更加方便以及所建模型的可操作性更强,在构建故障共享单车回收路径优化模型[6],需要提出以下假设。
(1)无法定位或定位不准的故障共享单车(即类型三)的地理位置信息是精确无误的。
(2)回收车辆在城市网络中每个初始服务节点之间的往返距离是固定的,行驶时间也是已知及相同的,不受道路条件、实时车流等因素影响。
(3)搬运工人在装卸搬运故障共享单车时,平均每辆所花费的时间一样。
(4)执行回收任务过程中,回收车辆的行驶速度保持匀速且已知,不需考虑交通拥堵。
(5)在一次回收任务中,各初始服务节点管辖范围内的故障共享单车数量及位置不变,是静态的。
3.2 符号说明
根据上述对故障共享单车回收问题的描述及模型假设,现对其模型中的参数符号作出详细定义,如表 1所示。

表 1 故障共享单车回收模型具体参数符号及详细定义Table1 Specific parameter symbols and detailed defini- tions of the recovery model of unusable sharing bicycles
3.3 模型建立
在传统车辆路径优化模型的基础上,考虑以执行一次回收任务的总成本最小为优化目标,构建故障共享单车回收路径优化模型,即
(3)
s.t.
(4)
(5)
(6)
(7)
Hj≤Lw+S(1-yjw),∀j∈R{O},w∈W
(8)
Hj≥0,∀j∈R{O}
(9)
xijw∈{0,1},∀i∈R,∀j∈R,w∈W
(10)
yiw∈{0,1},∀i∈R,w∈W
(11)
(12)
(13)
|V|≥2,w∈W
(14)
在所建模型中目标函数式(3)表示进行一次回收工作的总成本最小,即包括两部分成本最小化:①回收车辆运输故障单车的行驶成本最小化;②人工搬运故障单车到各服务节点的劳动力成本最小化。约束条件中,式(4)表示各个初始服务节点均能被回收车辆访问且只可访问一次;式(5)表示回收车辆从回收维修服务中心驶出时所要求的数量;式(6)及式(7)表示初始服务节点i和j只可由同一辆回收车辆访问,即在先后到达和离开节点i和j的都是同一回收车辆;式(8)表示回收车辆访问完节点j离开时所装载的故障单车数量不能超过额定容纳量;式(9)表示回收车辆在访问完任意初始服务节点时所装载的故障单车数量为非负数;式(10)及式(11)表示决策变量的0~1取值类型和范围。式(12)表示每辆回收车辆装载故障单车的数量不得小于规定最低的装载率;式(13)表示进行一次回收工作时每辆回收车辆花费的总用时上限;式(14)表示以防回收车辆在行驶过程中出现闭合子回路的情况。
3.4 改进蚁群算法设计
考虑到蚁群算法在求解性能上有很强的鲁棒性和全局搜索能力,其编码易于实现和理解;同时参考以往大量的车辆路径优化问题研究文献,发现蚁群算法模型的主要参数的取值范围比其他算法更加清晰明确,有利于对解决方案进行优化处理,但传统蚁群算法的收敛时间长、易陷入局部最优[7]。因此,将设计改进蚁群算法对故障共享单车回收路径优化模型进行求解。算法的关键参数定义如表 2所示。

表 2 改进蚁群算法关键参数定义Table2 Definition of key parameters of improved ant colony algorithm
(1)初始化蚁群系统。开始先将信息素浓度进行初始化处理,输入蚂蚁数量q(q=1,2,…,z)。在t时刻,蚂蚁q遵循状态转移规则从回收维修服务中心出发,任意选取符合满载率和回收时间限制的初始服务节点准备执行回收工作。倘若蚂蚁q无法找到符合条件的初始服务节点,那么将返回至回收维修服务中心。当把故障共享单车运送到回收维修服务中心后,需使所有蚂蚁逐一用相同的方式访问完每个初始服务节点[8]。

(15)
Aq={f-Tq}
(16)
在式(15)中,信息启发式因子ω≥0,当ω越大时,蚂蚁根据信息素浓度选取将要爬行的线路可能性越大,相互之间的交流配合更加密切;期望启发式因子λ≥0,当λ越大时,其状态转移规则就会越靠近贪心概率。下面将以启发式信息ηij(t)作为初始服务节点i到j之间距离的倒数,具体如公式为
(17)
为了取得更大概率的最优解,在其中添加2-opt搜索运作机制,使得当前最优解在搜索路径回路中进行多次更新[9]。
(3)改进的信息素更新。为了加快收敛速度以及避免陷入局部最优解的情况,只选择进行全局更新的方法,在每次迭代计算后进行全局更新,寻找最短路线上的信息素浓度[10]。先将t时刻连接初始服务节点i与j之间的路径(i,j)信息素浓度进行初始化,公式为
σij(t)=σmax
(18)
在每次迭代计算后,只对最短路径上的蚂蚁信息素进行更新,使得最优的解得以加强,全局信息素更新规则公式为
σij(t+1)=τσij(t)+Δσij
(19)
(20)
(21)
(22)
式中: avg=f/2;g为进行一次搜索能够寻找到全局最佳路线的概率。
另外利用所设计的改进蚁群算法寻找最优路径的流程如图 3所示。

图 3 利用改进蚁群算法寻找最优路径的流程图Fig.3 Flow chart of finding the optimal path using improved ant colony algorithm
4 上海市摩拜单车回收实例分析
4.1 故障摩拜单车聚类
以上海南站为中心,选取2km的方形区域内的摩拜单车作为研究对象,并把上海南站假定为所在区域的回收维修服务中心。从摩拜公司2019年4月某日的原始订单数据中随机选取238辆摩拜单车作为待回收的故障车辆,制作其分布的热力图如图 4 所示,红色部分代表故障摩拜单车密度高,黄色次之,亮绿色适中,蓝色代表其数量较少,这些颜色部分组成了回收维修中心所要管辖的区域。

图 4 故障摩拜单车分布的热力图Fig.4 Heat map of malfunctioning Mobike distribution
设定K-means算法参数进行求解,得到聚类结果。K-means聚类算法在选取数量不同的聚类点运算过程中,迭代次数通常不超过20次,其迭代运算效率相对较高。K-means算法误差平方和收敛图如图 5 所示,当设置聚类点个数为12时,位置误差平方和值为51.96km2,数值变化曲线趋于稳定,代表算法进行了收敛,由此该案例设定聚类点数量为12个,将其代入求解初始服务节点的位置[11]。

图 5 不同聚类点试验下误差平方和收敛图Fig.5 Squared error and convergence plots under different clustering point tests
经过求解出各聚类中心的位置信息,具体如表 3 所示。将上海南站设置为回收维修服务中心(O点),以深蓝色文字显示,将各聚类中心所在位置用气球形的红点进行地图标记(图 6),使得位置分布更加直观。
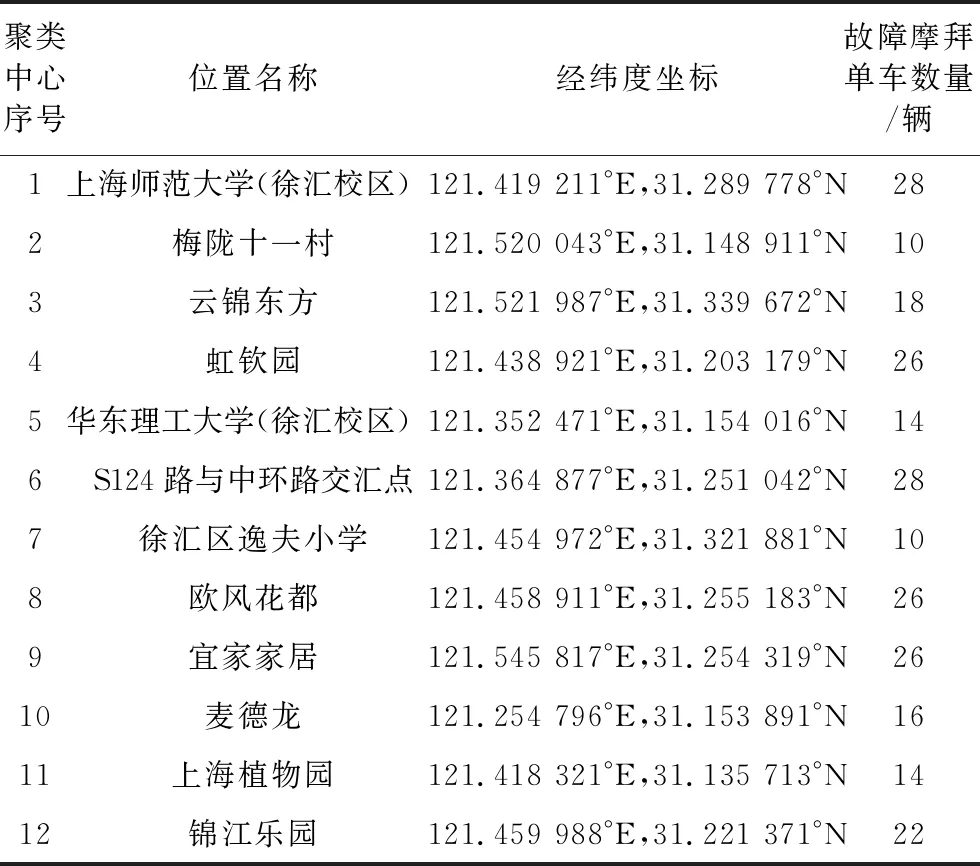
表 3 K-means算法得到的12个聚类中心信息表Table3 12 Cluster center informationTable obtained by K-means algorithm

图 6 标记聚类中心所在位置的地图Fig.6 Map marking the location of cluster centers
4.2 优化模型参数设置
本实例给回收维修服务中心配备4辆类型一致的回收车辆,规定每辆回收车辆最多能够装载70辆故障摩拜单车。利用百度地图进行测距,确定回收车辆在各初始服务节点以及回收维修服务中心每两地之间的行驶时间[12],列出具体时间矩阵(表 4),优化模型的主要参数设置如表 5所示。
4.3 路径优化结果分析
在计算机型号为intel core i7-8565U,处理器主频为2.6GHz,内存为4GB,操作系统为Windows10的MATLAB R2019b计算软件上进行运算求出每辆回收车辆对应行驶的路径,并根据结果分析车辆的装载情况、行驶花费的时间[13],从而进一步求出执行回收任务所需的总成本,改进蚁群算法具体求解优化结果如表 6所示。

表 4 12个初始服务节点的行程时间矩阵Table4 Travel time matrix of 12 initial service nodes

表 5 优化模型的主要参数值Table5 Optimize the main parameter values of the model
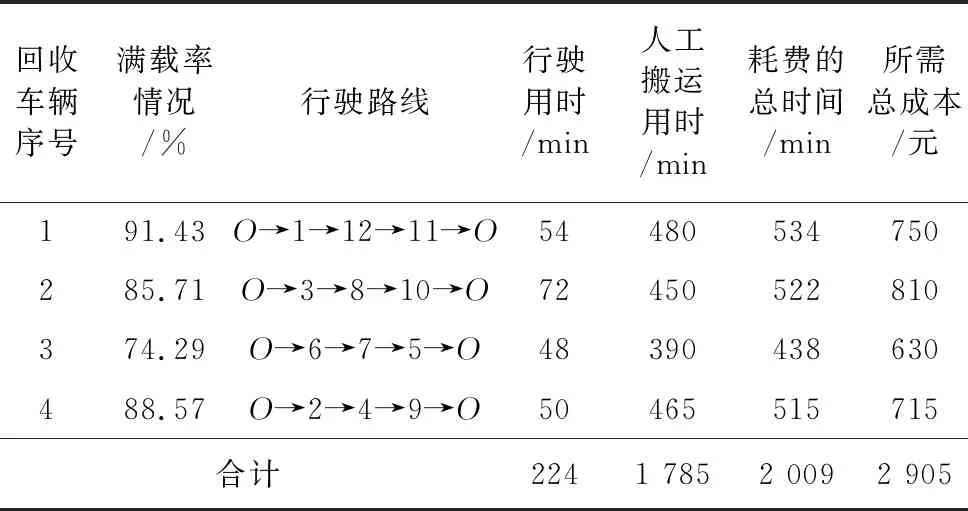
表 6 运用改进蚁群算法求解案例模型所得的优化结果Table6 The optimization results obtained by using the improved ant colony algorithm to solve the case model
在案例得出的最优结果中,回收故障摩拜单车所需花费的总成本为2905元,即可得知平均每回收一辆故障摩拜单车需要花费12.21元。从表 6可知,在4条回收路径中,每辆回收车辆的行驶用时与人工搬运故障摩拜单车用时的总和,即每辆回收车辆进行回收工作耗费的总时间在438~534min,花费时间相差比较少,这说明了本案例中故障摩拜单车的聚类处理结果和规划出来的回收行驶路径均是科学合理的。除此之外,4辆回收车辆装载故障摩拜单车数量分别为64、60、52、62辆,4辆回收车辆的满载率均在74.29%及以上。因此,结合所建的回收路径优化模型判断得出,4辆回收车辆在符合满载率约束、回收工作时间约束等限制条件下,均实现了回收行驶路径最优化的目的。
4.4 算法性能验证分析
文章应用MATLAB进行有效的目标函数值优化处理,其中图 7表示在10次计算迭代中最快、平均以及最慢的爬行搜索路径过程,该算例中4辆回收车辆运输行驶完全部路程的总时间为224min,改进蚁群算法在迭代计算时最快在72代收敛求得最佳路径,10次计算平均收敛所在代数为82,最慢的在236代收敛求得最佳爬行路径。
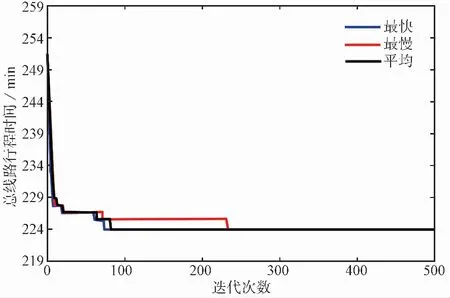
图 7 改进蚁群算法迭代计算收敛图Fig.7 Improved ant colony algorithm iterative calculation convergence graph

图 8 3种算法最快收敛情况对比图Fig.8 Comparison of the fastest convergence of the three algorithms
为了对比验证提出的改进蚁群算法的有效性,根据所构建的路径优化模型分别对传统蚁群算法和模拟退火算法进行修改,选取3种算法的最快收敛情况进行对比分析,如图 8所示。提出的改进蚁群算法最快在72代收敛,蚂蚁爬行总时间为224min;传统蚁群算法最快在187代收敛,搜索总时间为231min;模拟退火算法最快在216代收敛,总行程时间和传统蚁群算法一样。对比结果表明,改进蚁群算法能够显著降低回收车辆行驶路径总时间,比两种传统算法计算收敛的速度更快,从而有效降低运输总成本,并证明了该算法的合理适用性。
4.5 灵敏度分析4.5.1 满载率不同情况下对比分析
为进一步验证所建回收路径优化模型和改进的蚁群算法的正确性与合理适用性,只改变回收车辆满载率系数μ,保持其他主要参数不变的情况下,设计进行多组对比验证实验,从而探究满载率系数μ的改变对求解优化结果产生的影响。其中: 在设置的4种满载率约束条件下,4辆回收车辆进行回收工作时分别装载故障摩拜单车的数量如图 9所示。
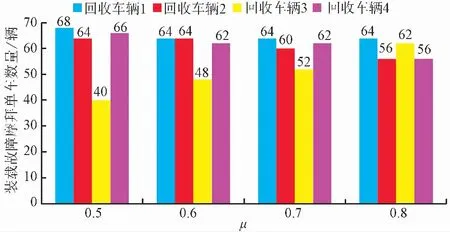
图 9 不同满载率情况下各回收车辆装载故障摩拜单车的数量Fig.9 The number of failed Mobike bikes loaded on each recovered vehicle under different full load rates
根据对比实验求解得出的优化结果能够看出,当设置的回收车辆满载率系数μ越大时,每辆回收车辆最终装载故障摩拜单车的数量更加均衡,这表明了选取不同满载率进行限制对最终优化结果会产生一定的影响[14-15]。

表 7 不同满载率情况下的最优求解结果Table7 Optimal solution results under different full load ratios
根据表 7可知,满载率系数μ与回收车辆行驶用时呈现正相关性,就是说当满载率系数越小时,则回收车辆行驶用时越短,执行回收任务所需总成本越少。在设置的4个系数中,0.5的满载率系数值最小,因而在该系数下,回收车辆行驶用时最短仅需212min,最后所需回收总成本最少仅为2845元;0.8的满载率系数值最大,其回收车辆行驶用时最长为230min,最后所需回收总成本最多为2935元。其中对比分析图 9中各组优化结果能够得出,当选取较大的满载率系数时,4辆回收车辆装载故障摩拜单车的数量极差相距较小,所以当回收路线相同的情况下,首先选择较高的满载率系数来代入模型求解得出的结果最优。综上所述,选取不同的满载率系数不仅会直接影响各回收车辆装载故障摩拜单车的效率,还会体现回收工作量分配的合理公平性。因此在实际回收任务安排中,上层决策者需要结合实际回收情况的工作量,考虑在故障共享单车回收路径优化数学模型原有的目标函数基础上增加最大满载率系数,使得模型更加贴合实际规划需求[16-17]。
4.5.2 聚类服务点个数不同对比分析
针对聚类服务节点数量进行设置,对比分析其个数差异对最后求解得到的优化结果产生的影响。从表 8中可知,当回收车辆满载率系数不同时,选取聚类服务节点个数为10的情况下,回收工作所需的总成本最高;当回收车辆满载率系数相同时,选取聚类服务节点个数为14的情况下,回收工作所需的总成本最高[18-20],所以能够得出以下两方面的结论。
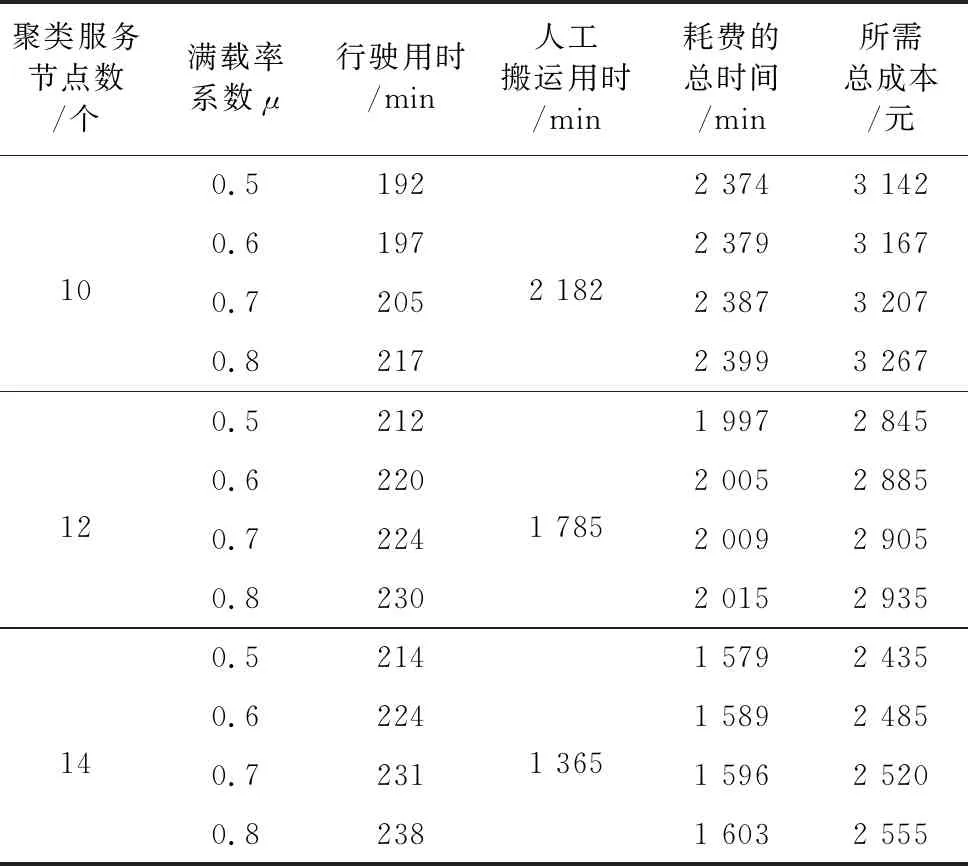
表 8 不同聚类服务节点个数对优化结果的影响Table8 The Influence of the number of different clustering service nodes on the optimization results
(1)若选取数量较少的聚类服务节点,则将增加人工搬运故障摩拜单车所需的时间,从而提高了整个回收工作最终花费的总成本。
(2)若选取数量较多的聚类服务节点,则将增加回收车辆行驶所需的时间,从而提高了车辆运输成本,导致增加了执行回收任务耗费的总成本。
因此,对比分析说明了所建模型和设计的算法能够应用到实际故障共享单车回收任务中,而在进行实际回收工作前,应综合考虑回收车辆每分钟产生的运营成本Cw以及搬运故障摩拜单车每分钟产生的劳动力成本Ce的数值变化,从而制订合理的回收计划。
5 结论
以上海市徐汇区部分区域的故障摩拜单车作为研究对象,利用K-means聚类算法对故障摩拜单车进行聚类处理,找出初始服务节点所在位置,接着建立路径优化模型并设计改进蚁群算法对其进行求解,得到回收路径优化结果,并结合优化后的行驶路径对进行回收工作花费的时间及总成本进行分析。针对满载率系数大小和聚类服务节点个数进行对照实验,分析几种选择下对算例结果产生的影响,研究发现满载率系数与回收车辆行驶用时呈现正相关性,以及服务节点个数同时影响着人工搬运时间和行驶时间,从而对回收总成本产生较大影响。同时验证了所建模型和方法能够应用在实际回收工作中,回收系统流程可以为共享单车企业在选择最佳回收路径方案时提供良好的参考。但由于数据获取过程中的回收维修服务中心以及各初始服务节点两地之间的行程时间矩阵数据是使用百度地图测距获取的,过于理想化;同时设置回收车辆在各自的优化路径中运输行驶速度一致且保持匀速,没有充分考虑实际城市交通道路架构、高峰拥堵以及突发事件等方面的因素;另外规定故障共享单车在回收工作进行时是保持静态的,但实际车辆状态和位置是动态变化的。因此,在后续研究中需要着手分析动态情况下故障共享单车的回收优化,开展系统全面的实地调研工作,紧密联系研究区域的实际交通网络情况来处理模型计算数据,使案例分析结果更加贴合实际。
