跨模态行人再识别的协同学习方法
2021-06-23陈坤峰潘志松王家宝焦珊珊
陈坤峰,潘志松,王家宝,施 蕾,张 锦,焦珊珊
陆军工程大学 指挥控制工程学院,南京210007
行人再识别是计算机视觉中的一项热门技术,其目的是实现多个不重叠摄像头场景下的行人搜索[1-2]。得益于模式识别和深度学习技术的蓬勃发展,近年来研究者们提出一系列优秀的行人再识别方法,并且在理想仿真条件下达到了较高的性能[3-5]。但是,目前大部分方法关注的是可见光摄像头产生的图像,而在实际应用中可见光摄像头只能满足部分场景的需求。在夜间条件下,可见光摄像头就无法完成对行人外貌的精准描述。因此,为了更好地满足夜间监控的条件,可根据温度成像的红外摄像头成为夜间监控的首选,与日间监控的可见光摄像头一起形成全天候的监控闭环。若要实现这样一个全天候智能视频监控系统,其中存在的主要问题就是如何将可见光模态下的行人图像与红外模态下的行人图像进行同身份匹配,即跨模态行人再识别。
跨模态行人再识别是一个多源细粒度图像检索任务,两种模态的行人图像如图1所示。该任务所要匹配的是日夜长时间跨度下红外与可见光两种不同模态的图像,所以要比传统单模态行人再识别的实现更加困难。这些困难主要体现在两个方面:(1)类内变化:首先,跨模态行人再识别任务也面临单模态情况下光照、遮挡、姿态、视角等因素造成的同身份行人图像类内变化较大的现象;其次,红外图像和可见光图像体现的信息量不对等,很可能出现类内变化大于类间变化的情况。(2)模态差异:跨模态行人再识别要解决的是两种异质图像的相互检索,特征对齐是图像正确匹配的基础。然而,两种图像由于成像原理不同,二者在特征空间的分布有较大不同。所以,跨模态行人再识别需克服一项额外挑战就是模态间存在差异的问题。

图1 跨模态行人再识别所要处理的图像示例
对于类内变化问题,大部分工作常常使用图像的整体特征作为最终的行人表示,也有文献提到用水平方向平均分块的策略。然而仅考虑整体特征或者某一特定尺度的局部特征,都是片面的。此外,现有工作只考虑了从特征提取器的网络最深层提取出的高级特征,没有考虑浅层网络得到的低级特征。低级特征可以体现图像的细节信息,对行人身份判别同样有着重要意义。所以,若要得到更有判别能力的跨模态行人再识别模型,可考虑多尺度多层次的精细化特征提取策略。
对于模态差异问题,目前多数研究常采用共享网络参数的方式将两种图像的特征映射到同一特征空间,以模态共有特征作为最终行人表示。但是,两模态图像的特征可以分为模态共有和特有特征,如果仅考虑共有特征,直接丢弃了特有特征,就没有充分利用图像中蕴含的的所有信息。一些研究发现采用模态转换的思路,识别率明显优于传统的方法。其中GAN方法可以有效地利用风格迁移等手段实现两个模态之间的转换,有效缓解模态间的差异。然而,GAN网络对任务性能虽有一定提升,但这些方法在重建图像或生成特征的过程中破坏了原始的空间结构信息,引入了额外的噪声。同时GAN带来的较大计算量和难以收敛的训练难度也不容忽视。所以,在处理模态间差异的问题上,需要充分考虑同一人两种模态来源图像间的特征互补性,提高异质信息利用率。尽量做到在缩小模态差异的过程中既不损失信息又不增加噪声。
在跨模态行人再识别中,从同一行人的图像中提取而来的各种特征尽管分布不同,但是共同体现了该行人的身份信息。这样则可以借助协同学习方法把各特征间的互补性利用起来,通过信息融合来提高网络的学习能力。因此,本文首次综合考虑增强特征判别能力和提高多源异质信息利用率两个方面,使用了协同学习方法提出一个精细化多源特征协同网络。
本文的主要贡献如下:
(1)为了增强特征的判别能力,本文提出了针对精细化特征的协同学习方法,即在设计用于提取特征的卷积神经网络时,综合考虑多尺度和多层次的行人特征。实验表明,精细化特征协同学习是一个简单而有效增强特征判别能力的方法。
(2)为了提高多源异质信息的利用率,本文提出针对多源特征的协同学习方法。首先,鉴于可见光图像和红外图像的异质信息互补性,利用双流网络提取跨模态图像共有特征和特有特征进行协同学习;其次,本文首次考虑将人体各部位相对位置关系的先验判别作为辅助任务,提出一个人体语义自监督方法;最后,在多个有针对性的损失函数联合监督下达到多源特征协同学习的目的。
(3)在跨模态行人再识别相关数据集上进行了充分实验。验证了本文提出的精细化多源特征协同网络的性能优于当前最好的相关工作,具备较高的可靠性和先进性。
1 相关工作
1.1 单模态行人再识别
一般来说单模态行人再识别是指仅考虑可见光模态的行人再识别,意即解决在不重叠的可见光摄像头之间匹配行人图像的问题[6-7]。该技术的关键挑战主要在于摄像头视角不同,行人姿态变化、光照强弱以及遮挡与否等因素引起的同身份行人图像的类内变化[8-13]。现有的单模态行人再识别方法大致可分为表征学习方法和度量学习方法。表征学习方法主要是利用行人身份标签进行判别性特征表示学习[14]。度量学习方法的目的通常是学习不同样本特征间距离,进而达到增大类间差异和减小类内差异的效果[15]。早期的研究中常常利用人体测量学数据、空间时间数据、运动学数据、动力学数据和视频流数据等,采取特定方法描述行人特征[16]。最近,在深度卷积神经网络的帮助下,单模态行人再识别的工作取得了优秀的成果[9],在一些广泛应用的公开数据集上甚至超过了人类的识别水平[3,17]。但是,现有的单模态行人再识别方法所处理的仅是白天光照良好条件下可见光摄像头采集的行人图像,在夜间跨模态行人再识别任务[18]中往往不能很好地应用,限制了该技术面向实际全天候监控场景的适用性。
1.2 跨模态行人再识别
跨模态行人再识别需解决的是不同成像源的行人图像之间的匹配问题,本文研究的跨模态行人再识别即为可见光图像和红外图像间的行人再识别[19-21]。Wu等[18]首次发布了一个大规模跨模态行人再识别数据集SYSU-MM01,分析了三种不同的网络结构并提出一个Deep Zero-padding方法。Nguyen等[22]发布了另外一个相关数据集RegDB。Ye等[23]设计了一种双流网络来学习多模态共享特征,同时利用双约束Top-Ranking损失来处理模态间和模态内的变化。此外,cmGAN[24]首次使用生成对抗网络(GAN)来实现跨模态行人再识别,取得了比之前更好的性能,也为后面的研究工作提供了新的思路[25-26]。后来,Zhu等[27]首次在跨模态行人再识别中考虑了人体局部特征,并且引入了异质中心损失,大幅提升了识别精度。本文充分考虑了同身份行人图像间的类内变化和模态差异,提出了一个精细化多源特征协同网络。利用精细化特征协同学习方法增强特征判别能力,以应对类内变化。利用多源特征协同学习方法提高异质信息利用率,以解决模态差异。而且,在SYSU-MM01和RegDB数据集上验证了该方法的有效性。
1.3 协同学习
文献[28]为解决分类问题引入了协同学习(Collaborative Learning)的方法理论。协同学习是指在同一批训练数据上训练出同一网络的多个特征学习器。利用多种特征间的信息互补性进行协同融合,在不增加推理成本的情况下提高模型的泛化能力和对标签噪声的鲁棒性,使网络达到更优的学习效果。协同学习具备辅助训练[29]、多任务学习[30-31]和知识蒸馏[32]等方法的优点,但不需增加过多的额外训练网络且可以实现端到端训练,是一个值得探索的方法思路。本文针对跨模态行人再识别这一任务,考虑深度卷积神经网络多尺度多层次特征的判别能力,以及多源异质图像数据的信息互补性,提出了针对精细化特征的协同学习方法和针对多源特征的协同学习方法。
2 本文方法

图2 本文方法的整体网络架构
设计了精细化多源特征协同网络,其整体网络架构如图2所示。对于可见光和红外这两种模态的图像,如何增强特征判别能力以及提高异质信息利用率,进而有效克服类内变化和模态差异这两大问题,是本文所提方法的研究目的。骨干网络中两个并联的ResNet50[33]组成双分支网络,分别作为可见光和红外图像的特征提取器。网络的前面若干阶段(Stage1至Stage4)用来提取各模态特有特征,后面若干阶段采用共享网络参数的方式提取跨模态共有特征。特别的是,本文设计的网络中包含了精细化特征协同学习模块(多尺度特征协同和多层次特征协同),以及多源特征协同学习模块(模态共有与特有特征协同和人体语义自监督)。以下各节对网络的各个关键模块展开详细介绍。
2.1 精细化特征协同学习
2.1.1 多尺度特征协同
目前大部分跨模态行人再识别工作都是提取图像的整体特征作为最终的行人表示[18,34-35]。然而,由于有些不同身份的行人之间外观差异较小,或者受到遮挡以及跨模态图像间其他噪声影响,仅使用整体特征往往不能对行人身份进行有效判别。最近,研究者们在单模态和跨模态行人再识别任务都证明了采用图像水平分块获取局部特征的有效性[27]。不同位置的局部特征会关注不同的人体细节,细节更具有区分性,使得模型能够辨别不同的行人身份。然而,由于多样化的行人姿态变化,摄像头的距离和角度等因素,用水平均分方法有时候很难学习到对齐和鲁棒的局部特征。所以,单独使用整体特征或者特定尺度下的局部特征都是不周到的。
考虑到整体特征和局部特征各自的优缺点,本文提出了一个多尺度特征协同学习的策略,利用水平多尺度切分的做法来处理跨模态行人特征。如图3所示,对ResNet50的第四阶段得到的特征图,采用多尺度分块池化的方式获得行人图像的多尺度特征向量。为了在不增加较多计算量的前提下获取合适尺度行人局部信息,则需要确定合理的分块尺度。根据对人体关节构造和穿衣习惯的认知,以及实验的验证,本文选择了整体、一分为二、一分为三这三种分块方式,由此就可用多尺度特征协同学习的方式获得更有判别力的行人信息。本文的工作是首次综合考虑多个尺度下的整体和局部特征来解决跨模态行人再识别问题。
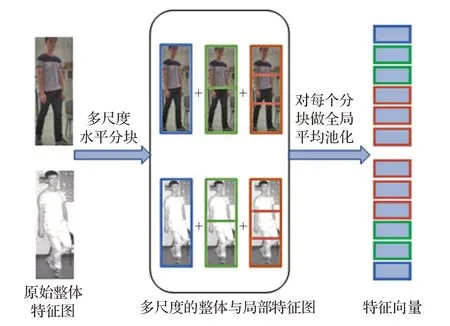
图3 多尺度特征划分方式
2.1.2 多层次特征协同
行人图像输入进特征提取器后,在卷积神经网络由浅到深各个阶段都可以学习到对应级别的特征。为了直观地反映卷积神经网络中各层特征的差异,以ResNet50作为特征提取器,可得网络各阶段特征分布热力图如图4所示。在热力图中,不同颜色的分布代表特征显著性的分布,红色表示特征最显著的区域,蓝色表示特征最分散的区域。从图4中可以发现,随着网络不断加深,不同阶段的卷积层在学习过程中所关注的区域发生了明显的变化。如图Stage1中,第一阶段卷积层的所关注最分散,主要从整个行人图片中提取细节的特征;而在图Stage4中,第四层卷积层的注意力则集中于具有区分性的区域,主要提取关键的语义信息。因此,从卷积神经网络的底层到高层,注意力越来越集中,且提取的信息从分散的空间结构信息转向集中的语义信息。

图4 行人图像在ResNet50中各层次特征分布热力图
目前流行的行人再识别模型通常使用卷积神经网络的深层特征来识别行人。但是,在学习深层特征时,由于在训练阶段进行了大量的填充和合并等操作,会丢失一些原本存在于浅层特征中的重要空间信息,如形状、纹理等。此外,红外图像包含信息量较少,这就造成了同身份的两个模态的图像的语义表达能力的巨大差异。因此,仅使用深层特征实现跨模态行人再识别是不妥的,很有必要使用浅层网络提取到的特征补充判别。所以,本文提出了多层次特征协同学习方法。为了避免增加较大的计算量和特征维度,对于浅层信息仅考虑了Stage3阶段获取的特征图,使用1×1卷积将此特征图的通道数从1 024提升至2 048,然后将此浅层特征与Stage4阶段的深层特征级联一起送入后面的网络。利用这样一个多层次特征协同的策略,可以有效使用到不同粒度的图像特征,从而获取更有判别力的行人表示。
2.2 多源特征协同学习
2.2.1 模态共有与特有特征协同
跨模态行人再识别的目的是实现两种模态图像的相互检索。由于不同模态存在差异,所以在跨模态图像的特征学习过程中,行人表示的描述和使用是一项很具挑战性的工作。为了解决这个问题,研究者们通常会利用共享网络参数的方式得到两种图像共同体现的特征作为最终的行人表示。然而,一个人的两种不同模态的图像中包含有模态共有特征,也有模态特有特征。如图5所示,模态共有特征可以用两集合的交集表示。如果只考虑共有特征而忽略特有特征的话,就意味着图像信息的不充分利用。文献[36]提出了一个共享和特有特征迁移网络(cross modality Shared-Specific Transfer Network,cm-SSTN),充分考虑了模态间共享特征和模态内特有特征。他们的工作取得了当前最好的识别效果,也以此验证了共享特征和特有特征的互补作用。但是cm-SSTN也有模型复杂和计算量较大等不足之处。

图5 跨模态行人图像特征关系图
考虑跨模态图像特征的异质信息互补性,提出了一个简单有效的模态共有与特有特征协同学习方法。在跨模态双分支网络的基础上,利用参数共享的全连接层提取模态共有特征,同时通过参数不共享的全连接层提取模态特有特征。然后,在监督学习中分别训练模态共享特征和模态特有特征,进而达到异质互补的效果,提高图像信息的利用率。
2.2.2 人体语义自监督
模态间的信息交互是减小模态差异的一个有效手段。现有工作的做法通常是利用GAN网络实现图像的风格迁移或特征迁移来实现模态间的信息交互。但是,GAN网络基于生成的思路会有引入新的噪声的可能,且会面临训练时的收敛困难等局面。所以,如何在不引入噪声且容易训练的情况下,学习到不受模态特点约束的知识,进而实现模态间信息交互,是一个值得探索的思路。
本文提出了一个人体语义自监督模块,旨在采用人体结构的语义信息作为先验知识,将两个模态图像在不利用身份标签的情况下一起送入共享参数的自监督学习网络,学习到一些不受模态和身份限制的人体基础特征。也就是说,客观视角下,无论行人图像属于哪个身份,来自哪种模态,一张行人图像中人体各个身体部位的相对位置都是确定的。换言之,每个人的图像从上到下都是头部、肩部、胸部、腹部、腿部和脚部等这样的语义结构。这些语义信息是行人图像和其他自然图像的一个明显区别,也是重要的先验知识。恰好可以利用这个先验知识,设计了一个跨模态参数共享的人体语义自监督模块,具体做法如图6所示。把不同模态的每张图像中人体各部位分成小块并打乱顺序,然后在各个分块位置标签的监督下对分块重新排序得到原始顺序。这样,可以利用人体各个部位的相对位置关系学习到与图像的模态来源无关的人体基础信息,达到缩小模态差异的效果。实验证实这个简单的操作可以得到较好的效果提升。而且该自监督模块使用的是上文多尺度协同学习方法中提及的单张行人图像的多尺度特征分块,因此并没有引入很多计算量。
2.3 损失函数设计
以往的跨模态行人再识别网络[34-35]常采用交叉熵损失(Cross Entropy Loss,CE Loss)和三元组损失(Triplet Loss)来监督学习特征。交叉熵损失用于行人身份的分类,三元组损失是为了缩小类内距离并且增大类间距离。后来,Zhu等[27]提出一个异质中心损失(Hetero Center Loss,HC Loss),设计该损失函数的目的是缩小不同模态同类样本之间的差异,该工作同时使用了异质中心损失和交叉熵损失,实现了较好的效果。

图6 人体语义自监督模块示意图
本文方法中引入了一个混合模态三元组损失(mix-Modality Triplet Loss)[37],并将其结合交叉熵损失和异质中心损失一起使用。文献[38]证明了交叉熵损失和三元组损失作用在同一特征空间的情况下会出现收敛困难的状况。同样的道理,交叉熵损失和异质中心损失之间也存在这样的问题。因此,利用一个批标准化层(Batch Normalization Layer,BN Layer)层和一个全连接层(Fully Connected Layer,FC Layer)将特征向量映射到两个特征空间上来解决冲突。
把输入图像的每个批次大小记为N,则N=2×P×K,意即每个批次的N张图片里有P个行人身份,其中每个身份有K张可见光图像和K张红外图像。对于模态共有特征,类似于文献[27],以每张图片的行人身份信息作为监督标签,使用交叉熵损失和异质中心损失的组合作用来学习每个特征分块。每个特征分块上的交叉熵损失计算方法为:

其中,x i指第i张图像的某一特征分块,p(x i)指的是期望输出,即真实标签。q(x i)是网络中每张特征分块的提取到的特征向量经Softmax层之后得到的预测标签。对每个特征分块计算异质中心损失如下:

所以,在共有特征上的损失函数计算方法如公式(3)所示:

其中,λ是平衡交叉熵损失和异质中心损失的权重参数。f从1到7指的是计算7个特征分块损失的总和,7个特征分块即为浅层的一个特征分块和深层的6个多尺度特征分块。
对于模态特有特征,首先用交叉熵损失对每一个样本做身份判别,如下:

这里用g i表示从单模态分支中取得的整体特征向量。此外,用三元组损失实现类内差异缩小,类间差异增大。三元组损失在进行计算时需要三张输入图像,分别为固定图像(Anchor)a、正样本图像(Positive)p和负样本图像(Negative)n。图像a和p是正样本对,图像a和n是负样本对。考虑到网络其他部分已经起到了缩小模态差异的作用,在此使用的是一个混合模态三元组损失函数,也就是将两个模态样本特征放在同一集合中进行三元组采样。那么一个批次里的图片数量则为2PK张,记一个批次里所有图片的集合为batch,固定图像a的正样本集为A,负样本集为B。那么混合模态三元组损失的计算方法如公式(5)所示:

公式中的α指三元组损失的边界值参数,[]+的意思是方括号里的计算结果若小于0,就记为0。其中,A和B皆为batch的子集。
那么,应用于模态特有特征的损失函数即为:

对于人体语义自监督模块,目的是在自监督训练的过程中对打乱的分块特征向量重建排序,具体做法是:对6个多尺度特征分块打上位置标签,然后在训练的过程中预测标签,进而学习到6个分块特征向量的原始空间相对位置。所以,可用预测特征分块标签的交叉熵损失函数作为自监督学习的损失函数,记S i,s为第i个样本的第s个分块,可得此自监督学习模块的损失函数计算如下:
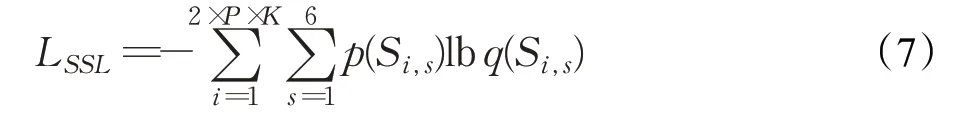
公式中p(Si,s)为每个特征分块的真实位置标签,q(S i,s)为每个特征分块的预测标签。
综上,此精细化多源特征协同网络在端到端训练过程中总的损失函数为:

3 实验及结果分析
3.1 实验设置
3.1.1 数据集
目前有两个公开的数据集(SYSU-MM01[18]和RegDB[22])可以用于测评跨模态行人再识别方法的实验结果,数据集中的图像采集自可见光摄像头和红外(近红外和远红外)摄像头。
SYSU-MM01数据集是由室外和室内环境下6个不同摄像头采集而来的大规模数据集,包含4个可见光摄像头和2个近红外摄像头。该数据集包含395个行人身份的训练数据,包括22 258张可见光图像和11 909张近红外图像。测试集包含另外的95个行人身份的图像,以及两种测评模式和两种测试集构建方式。在两种测评模式中,查询集(Qurey set)是相同的,包含3 803张从两个红外摄像头捕获的图像。在All-search模式下,图库集(Gallery set)包含了从所有4个可见光摄像头捕获的所有可见光图像。在Indoor-search模式下,图库集只包含两个室内可见光摄像头捕捉到的可见光图像。一般来说,All-search比Indoor-search模式更具挑战性。两种测试集构建方式分别为Single-shot和Multi-shot,二者的做法也就是在构建图库集时随机选取同一行人身份的1张或10张图片。评估方案的详细描述可以在文献[17]中找到。使用最困难的实验设置,也就是All-search的测评模式和Single-shot的测试集构建方式,进行了10次测试并记录了平均检索性能。
RegDB数据集是一个由双模摄像头系统(一个可见光摄像头和一个远红外摄像头)采集的小规模数据集。在RegDB数据集中可见图像与红外图像轮廓非常相似,跨模态行人再识别难度较小。这个数据集总共包含412个行人身份,每个行人身份有10张可视图像和10张红外图像。按照文献[22]的评价协议,随机选取206个身份(2 060张图像)用于训练,其余206个身份(2 060张图像)用于测试。评估了可见光图像检索红外图像(Visible to Thermal)、红外图像检索可见光图像(Thermal to Visible)这两种不同检索设置的性能,采用10次随机分割训练集和测试集的方式记录平均准确度。
3.1.2 评价指标
为公平起见,参照现有工作的做法,本文实验同样以累积匹配特性(Cumulative Matching Characteristics,CMC)和平均精度均值(mean Average Precision,mAP)作为评价指标。CMC中的Rank准确率测量的是在前k个检索结果中出现正确跨模态行人图像的概率。mAP指标可以体现方法的平均检索性能。
3.1.3 实验设计细节
实验采用Pytorch框架实现工程代码,在1块NVIDIA GeForce 1080Ti GPU上进行训练和测试。数据集中的行人图像的大小被调整为384×128。在训练阶段,随机选择4个行人身份,然后再每个行人身份随机选择8张可见光图像和8张红外图像。因此在每一轮的训练中,batchsize为64。为了均衡交叉熵损失函数和异质中心损失函数的作用,参照文献[27]的公式(1)中异质中心损失的权重被设置为0.5。三元组损失的边界值被设置为0.3。训练过程采用动量为0.9的随机梯度下降(SGD)优化器。包括前10轮采用的热身学习率(Warm Up Learning Rate)策略的训练过程,该精细化多源特征协同网络被训练了80轮。学习率lr(t)随训练轮次t的变化如公式(9)所示:
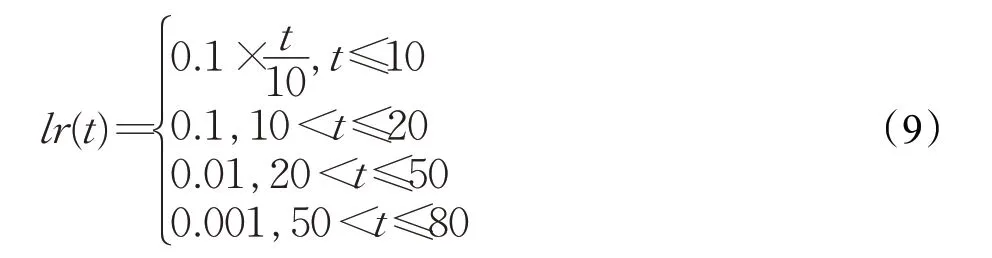
此外,在训练过程中,利用模态共有和模态特有特征来优化网络。在测试推理时,仅使用模态共有特征来评价查询图像与图库图像之间的相似性。原因首先是在模态特有特征的影响下,最终通过端到端协同学习完成训练后提取的模态共有特征能够有效地描述图像,这在本文的实验中得到了证明。另一个原因是,单独使用共享特征可以加快测试过程特征推理速度。
3.2 本文方法性能分析
3.2.1 与其他方法的对比分析
在SYSU-MM01和RegDB数据集上,将本文方法与当前跨模态行人再识别任务的一些流行方法在同样的实验设置方式下进行了对比,这些方法包括Zero-Padding[18]、HCML[39]、cmGAN[24]、HSME[40]、D2RL[25]、AlignGAN[26]、HPILN[41]、eBDTR[23]、Hi-CMD[35]、JSIA[26]、MSR[42]、AGW[43]、XIV[44]、HAT[45]、SIM[46]、EDFL[47]、TSLFN+HC[27]和cm-SSFT[36]。实验结果如表1和表2所示。
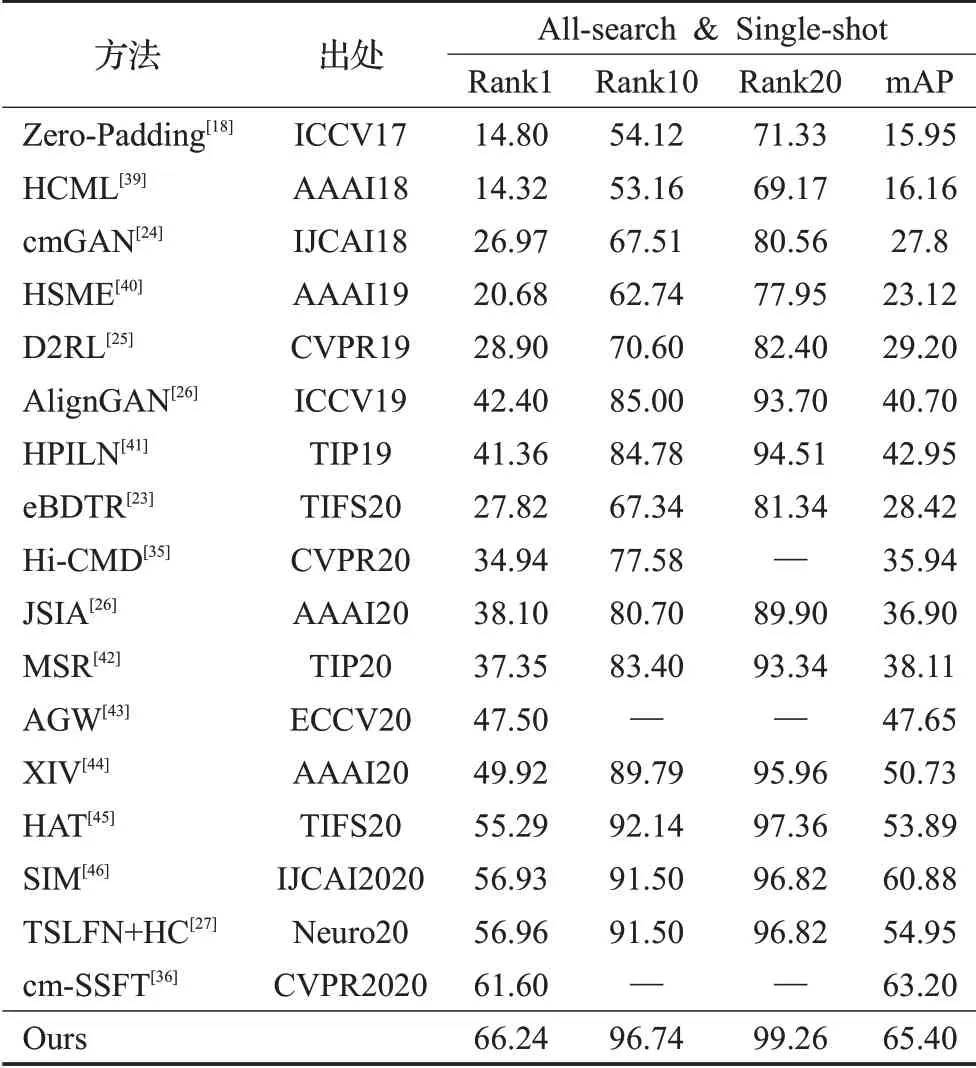
表1 在SYSU-MM01数据集上本文方法与其他方法的对比%
在表1中,精细化多源特征协同网络与TSLFN+HC相似,但本文方法在Rank1指标上领先了9.28个百分点,在mAP上领先了10.45个百分点。此外,注意到cm-SSFT是所有对比方法中最好的一种。虽然cm-SSFT在Rank1和mAP中分别达到了61.60%和63.20%,但本文方法实验结果的Rank1和mAP比cm-SSFT分别高了4.64和2.20个百分点。而且,cm-SSFT具有更复杂的网络结构,带来了更多的参数和计算量。
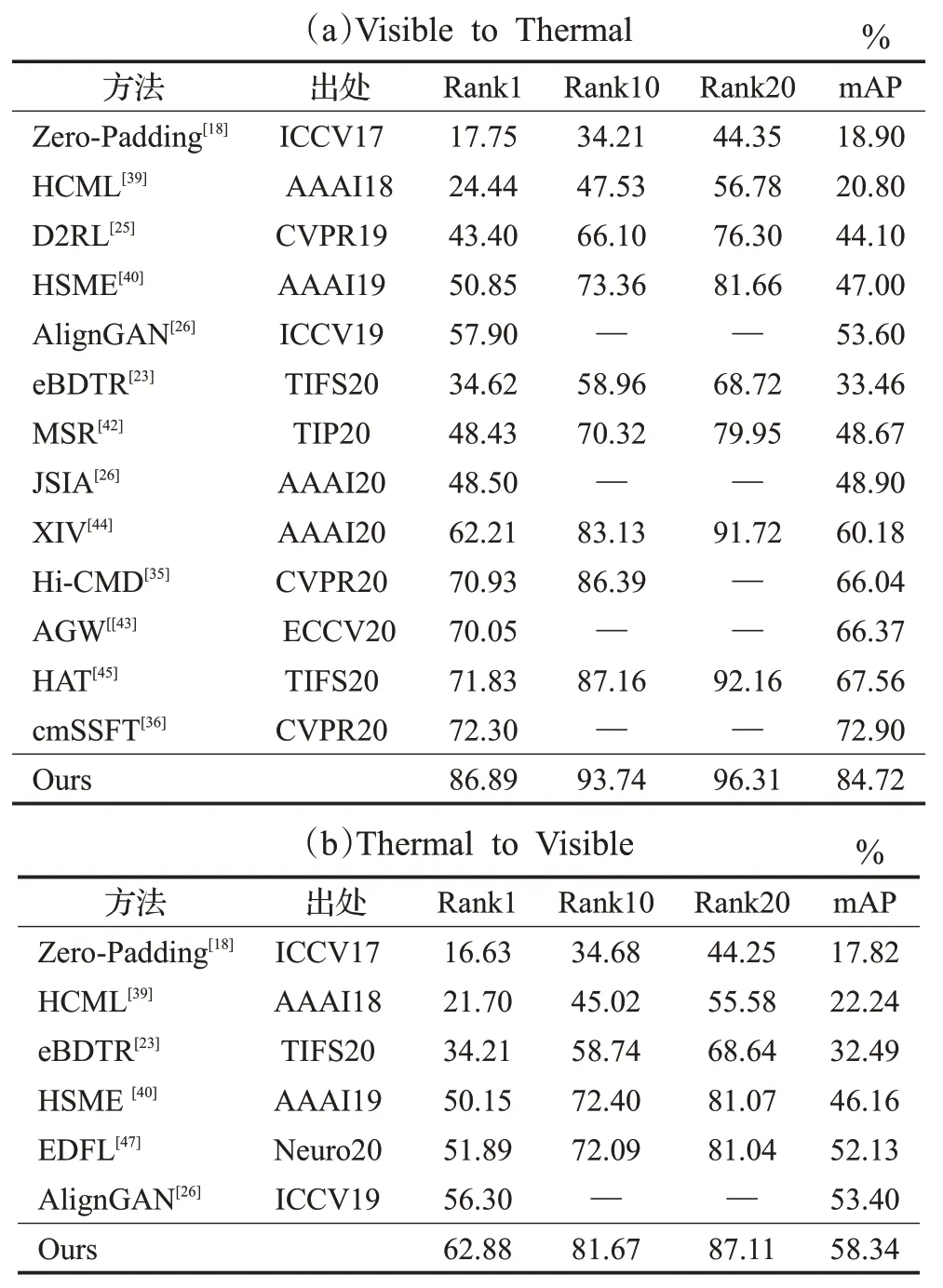
表2 在RegDB数据集上本文方法与其他方法的对比
从表2中可见,本文所提方法在RegDB数据集上同样具有竞争力,而且识别精度要比在SYSU-MM01数据集上的高。这很大程度上是因为RegDB数据集的图像采集自双模摄像头,得到的可见光图像和红外图像中的行人的姿态轮廓类似,因此跨模态类内差异较小。此外,表2中实验数据显示可见光图像检索红外图像模式下的识别效果要比红外图像检索可见光图像模式的识别效果要高。这是由于红外模态的行人图像的信息量较小,对行人身份的判别能力不强,该特点与前文所述的观点也是一致的。
3.2.2 检索结果可视化分析
为了直观分析本文所提方法的再识别效果,选取了SYSU-MM01数据集中的若干样本进行了检索结果可视化分析,如图7所示。图中的前三行是使用红外图像检索可见光图像的结果,后三行是使用可见光图像检索红外图像的结果。图中的第1列为检索目标行人图像。其余列为检索结果中排名前10的行人图像,图片从左到右是根据模型计算所得的相似度从大到小的排序。图中绿框为检索正确的样本,红框为检索错误的样本。
如图7所示,可见光行人图像的上下身衣服颜色虽差异较大,在红外模态中却无明显区别,如需正确配对这样的样本,则需要模型更加关注行人的动作,体型和一些细节纹理特征。从检索结果可见,本文方法可有效提取精细化的行人特征。

图7 本文方法在SYSU-MM01数据集上的再识别效果
从图7中可见,模态间的共有特征,如包、衣服标志依然会成为识别过程中信息匹配的关键,而这些模态共有特征可能对正确结果的判别有所帮助。所以,采取多源特征协同学习的方式,促进模态间的信息交互,提取更有辨别力的特征十分重要。
此外,当颜色无法为作为身份判别信息时,深度网络便会学习到行人的体型,姿态等特征作为区别行人的重要依据。如图7的第6行,尽管第1列和第2列、第4列是不同身份的行人,但由于他们都有交叉双腿的体态动作,因而被误判为同一人。可见,提取可靠的辨别性特征,依然是一个重要挑战。
3.3 消融实验
为了验证本文所提的精细化多源特征协同网络各个模块的有效性,对网络进行了消融实验。在SYSUMM01数据集上,以TSLFN+HC[27]方法作为基线模型,依次向网络中加入本文提出的几个模块,由此则可以清晰地量化体现各个模块对任务的提升效果。
可见,本文方法提出的各个模块对于跨模态行人再识别任务都有一定的帮助。对于表3中的每一个实验,在以下章节进行了模块设计分析。
3.3.1 多尺度特征协同
如表3中的实验2,通过几种水平划分策略得到不同尺度的局部特征,并将其与整体特征级联在一起,即得到了本文所提的多尺度特征模块。为了确定多尺度特征协同模块的最佳尺度,比较了几种不同级别的水平分块组合策略。使用TSLFN+HC作为基线方法(Baseline)来分析模块设计效果。也就是说,在此实验中只是更改了TSLFN+HC方法的特征水平六等分方式,其余网络结构和实验设置均不变。采用的组合如下:Scale1(全局特征+2个水平等分块),Scale2(全局特征+2个水平等分块特征+3个水平等分块特征),Scale3(全局特征+2个水平等分块特征+3个水平等分块特征+4个水平等分块特征)。如图8所示,最佳的特性是Scale2。而且根据客观认知,人体结构水平均分为两部分或者三部分,都可以理解为独立的语义单元,所以Scale2适合于人称表征。

表3 加入不同模块后的性能对比

图8 跨模态行人再识别所要处理的图像示例
3.3.2 多层次特征协同
如表3中的实验3,在已经选择了最佳多尺度特征后,还进行了实验,以寻找最佳的多层次特征。提取不同层次的特征,分析不同的组合:Level2、Level3和Level2+Level3。Level2和Level3代表了基于Resnet50骨干网的Stage1和Stage2提取的不同特征图。结果如表4所示,最好浅层特征的是Level3。注意,从Level2中提取的特征在任何组合中都会降低性能,例如Multi-Scale+
Level2的性能低于Multi-Scale,Multi-Scale+Level2+Level3的性能也低于Multi-Scale+Level3。可见Level2提取的特征信息层次过低,对语义分类没有明显贡献。
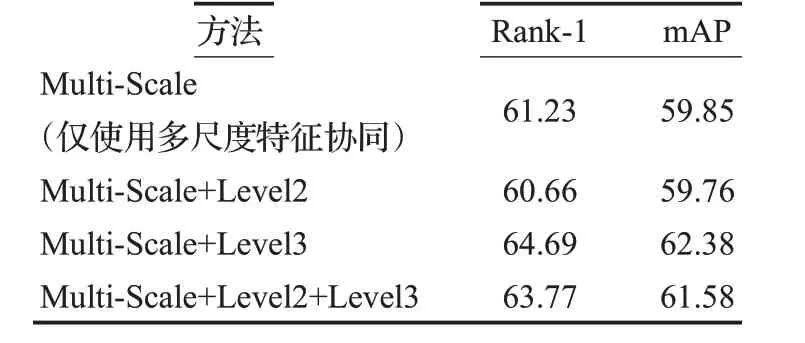
表4 各种层次组合方法的性能分析%
3.3.3 模态共有与特有特征协同
如表3中的实验4,利用多尺度和多层次方法实现了精细化特征协同学习后,设计了模态共有与特有特征协同学习模块。混合模态三元组损失函数是所提的模态共有与特有特征协同学习模块的重要组成部分。之所以使用这样一个损失函数,是因为要通过将一个训练批次中两个模态图像混合在一起进行三元组采样,这样可以在进行度量学习的过程中,更好地实现模态间信息交互。为了验证混合模态三元组损失函数的功能,以及相对于单模态三元组损失的优势,在网络其他设计部分不变的情况下,对二者进行了对比实验,其结果如图9所示。

图9 不同条件下的三元组损失函数性能对比
3.3.4 人体语义自监督
如表3中的实验5所设计的人体语义自监督学习模块对跨模态行人再识别任务性能有所提升。从逻辑上分析,该模块的输入数据为两个模态的特征,可以实现克服模态差异的效果。但是,该模块同样可以起到局部特征学习的作用。所以,该模块带来的性能提升的原因是实现了克服模态差异还是实现了局部特征学习,是下面要讨论的问题。
首先进行了相关对比实验。在网络其他设计不变的前提下,用无自监督、单模态自监督、跨模态自监督三种设置做了对比,如表5所示。可见,跨模态的人体语义自监督不仅具有局部特征学习的作用,也可以很好地实现克服模态差异的效果。
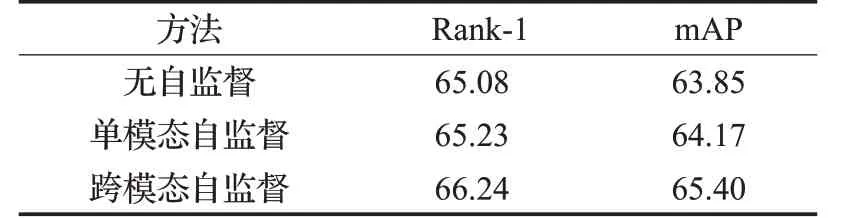
表5 人体语义自监督模块性能分析%
4 结束语
本文综合考虑了增强特征的判别能力和提高多源异质信息的利用率,在协同学习方法的指导下,提出了精细化多源特征协同网络。利用多尺度和多层次特征实现精细化特征协同学习,并通过模态共有与特有特征协同和人体语义自监督达到多源特征协同学习的目的。本文所提方法在两个相关数据集上明显优于其他方法,并为本领域的进一步研究提供了一个简单而有效的思路。
