一种基于接口编程的高效通用数据访问层的设计与实现
2021-06-23徐照兴
徐照兴
(江西服装学院 大数据学院,江西南昌向塘经济开发区丽湖中大道103号 330201)
决定一个系统优劣最关键的是系统的架构,系统架构的优劣决定着系统具有的延迟与吞吐量、可用性与一致性、可扩展性、稳定性等[1]。系统经典架构主要有基于接口编程的三层架构,该架构可以很好地从整体上对系统解耦。经典三层通常分为数据访问层、业务逻辑层、表现层,大型系统通常会在经典三层架构的基础上对业务逻辑层进行再封装,使之形成新的一层,通常称为服务层,这样系统的架构就变成了四层,也就成为分布式系统架构[2]。不论几层架构,数据访问层是必须的,其功能主要是负责对数据库的访问。文中经过对多套开源框架分析,结合实战开发经验,给出一种基于接口编程思想,用Entity Framework技术实现数据访问层的方案,并给出核心代码,整个实现思路如图1所示。
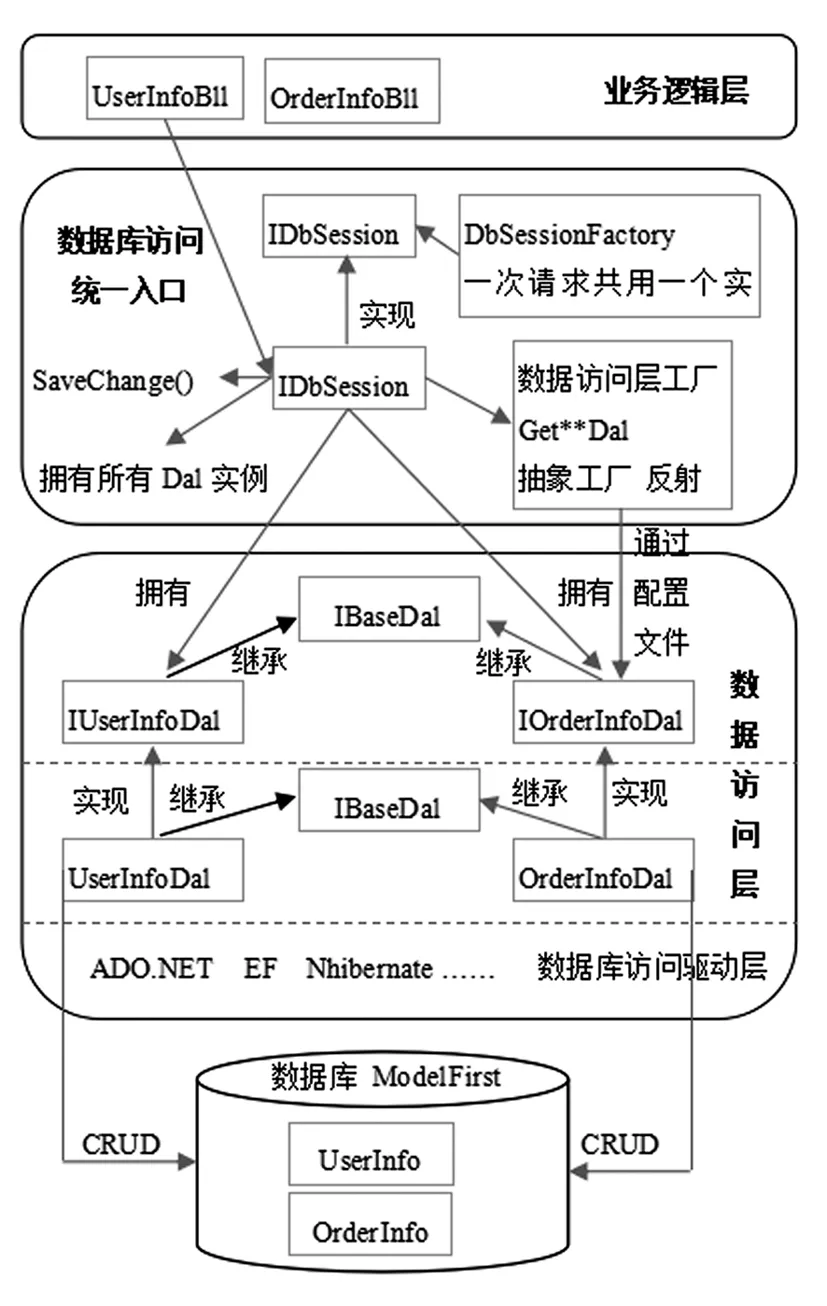
图1 数据访问层实现思路总图Fig.1 General diagram of data access layer implementation idea
1 数据访问层常用技术
在.Net开发平台下,数据访问层实现技术主要有ADO.Net,NHibernate,Entity Framework(以下简称“EF”)。ADO.Net是一种最基本的数据库访问技术,访问性能高,需要比较熟练掌握SQL Server数据库技术。EF是典型的一种实现了ORM(Object Relational Mapping,对象关系映射)框架的技术,它底层是对ADO.Net技术进行了封装,通过实体、关系型数据库表之间的映射,使开发人员可以通过操作表实体而间接地操作数据库,大大地提高了开发效率。EF与原生ADO.NET技术相比缺点是访问性能稍差,主要是因为在编译运行时有一个生成sql脚本的过程[3]。NHibernate也是一种实现了ORM框架的技术,它使用数据库和配置信息来为应用程序提供持久化服务,也即在使用时要进行更多的配置[4],总体来说与Entity Framework技术差不多,但是NHibernate与Visual Studio开发环境的集成不如EF,所以本文选择主要利用EF技术来实现数据访问层。
2 数据实体假设
系统采用Model First方式设计数据库,即先设计Model,然后根据Model生成数据库。为了方便后面给出实现代码及说明,假设系统有UserInfo(用户)和OrderInfo(订单)两个实体,UserInfo实体拥有UName(用户名)、Pwd(密码)、ShowName(真实姓名)等属性,OrderInfo实体拥有Content(订单内容)、UserInfoId(订单所属的用户Id)等属性,它们之间的关系为1对多,实体数据模型如图2所示。
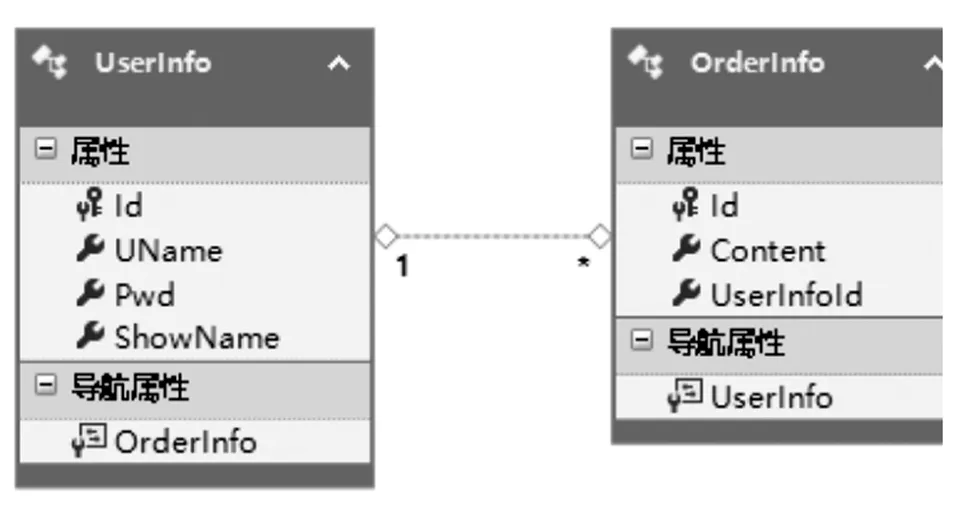
图2 数据实体模型Fig.2 Data entity model
3 关键技术分析与实现
3.1 用EF技术实现高效查询
数据访问层最基本职责就是封装对实体的增删改查方法,假设要对实体UserInfo进行封装,即创建UserInfoDal类,此类中用EF对实体进行增加、修改、删除方法都非常简单。下面重点分析阐述如何根据用户输入的任意条件高效查询数据。在ADO.Net数据库访问技术时往往会采用where拼接条件,这样写起来很繁琐,性能比较差,也不利于扩展。采用EF来实现,要考虑参数类型和返回值类型2个问题。
(1)方法参数类型
要能接受用户输入的任意条件是一个条件,它要么为真要么为假,其返回值是bool类型,因此用委托Func
(2)方法返回值类型
返回值是用户,但返回的用户个数是不确定的,因此不能用UserInfo,可以用List
该方法参数Func
用Expression
利用EF技术实现根据用户输入任意条件高效查询数据的代码如下:
Public IQueryable
{
Return
db.UserInfo.Where(whereLambda).AsQueryable();
}
3.2 EF+Lambda高效分页查询
Lambda分页查询需要的参数有pageSize(每页多少条记录)、pageIndex(查找的页码索引)、查询条件、排序条件、升序(asc)还是降序(desc),此外,一般还会输出查找到的记录数total。最关键的就是查询条件参数及排序条件参数如何表示。
查询条件与3.1节中的是一样的,重点分析排序条件。
排序条件是由用户传入,因此跟查询条件参数类似。但Func的返回值类型不是固定的bool,如果根据Id排序就是int,如果根据用户名排序就是string等,具体实现如下:
把分页查询方法写成泛型形式,也即泛型方法,这样在调用方法时由用户传入,也即排序条件参数为:Expression
分页查询返回值类型同样为延迟加载类型,因此返回值类型设置为IQueryable
3.3 封装数据访问层的基类关键技术
为了提高代码的复用性及系统的可扩展性,需要封装数据访问层的基类,取名为BaseDal,其功能就是封装所有Dal层类公共的增删改查方法。然后Dal层各实体类(比如UserInfoDal,OrderInfoDal等)只要继承基类BaseDal就拥有了增删改查方法。那么在基类下面所有方法就不能指明具体的类型,那如何处理呢?
子类UserInfoDal继承基类BaseDal时,可以通过子类传入类型给基类,因此,基类就要能接收子类传入的类型,也即基类要采用泛型类,同时约定传入的类型要为引用类型和具有无参构造方法。
3.4 通过接口隔离BLL层对DAL的依赖
通常采用new实例化对象,会导致BLL层与DAL层紧密耦合在一起,即DAL层发生变化BLL层就必须跟着变。而项目设计原则为模块内高内聚、模块间低耦合[6]。即当DAL层发生变化,BLL层不需要变化或者变化达到最小。
可以通过接口隔离BLL层对DAL的依赖,即让BLL层依赖接口,不要依赖于DAL层,因为DAL层是具体的实现(即不依赖于具体实现),而依赖于接口,接口是抽象的(里面的方法等都只有一个定义而已),可以用不同的方法来实现接口,因此,需要建立接口层。然而有多少个实体,就需要建立多少个实体对应的接口,且每个接口里都是定义类似的抽象的增删改查方法,因此,可以抽象出基类接口IBaseDal,同BaseDal一样,它也需要设置为泛型,以便接收子类传入的类型。
有了上面的基类接口后,具体的子类接口(如IUserInfoDal)只需要去继承基类接口IBaseDal,并传入对应的实体类型即可。
为了让实例化对象返回值类型为接口类型,还需要让对应数据访问层子类(如UserInfoDal)去实现对应的接口。具体数据访问层子类(UserInfoDal)的代码结构升级改为如下形式:
Public class UserInfoDal:BaseDal
{
}
然后,实例化具体数据访问层子类就可以用接口类型去接收(即返回值类型为接口)。
3.5通过抽象工厂实现BLL层与DAL层彻底解耦
通过接口隔离BLL对DAL的依赖,代码得到较大优化,但是还有不足之处。
因为业务逻辑层有很多BLL类,比如UserInfoBll,OrderInfoBll等,有多少个实体类就需要有多少个BLL类,而且UserInfoDal会用得非常频繁,因为很多业务BLL都需要与用户发生数据交互,如UserInfoDal()名称发生改变(比如数据访问驱动层实现技术发生改变,名称由UserInfoDal改为了NhUserInfoDal),那么所有用到UserInfoDal的BLL类都要做相应的更改,这样就非常麻烦,那么有没有办法改一个配置就可以呢?
这就可以用抽象工厂,其本质是使用反射方式来实现[7]。要使用反射就要获得当前程序集。数据访问驱动层的不同实现方法其实就是程序集名称不同,不过前提是不同数据访问驱动层封装同一个实体的DAL名称要相同,这实际也就是约定大于配置思想。在项目中新建一个静态的StaticDalFactory类,在该类下面创建GetUserInfoDal方法,返回值类型设置为接口类型IUserInfoDal。
由于变化点只有一个程序集名称,因此,可以把程序集的名称放到配置文件(web.config)中去。
对于静态工厂层(StaticDalFactory),首先添加对配置文件的引用,即添加对System.Configuratuion程序集的引用。
那么以后实现数据访问驱动层的技术发生改变,只要修改配置文件web.Config中的
3.6 保证线程内共享一个上下文实例
前面数据访问层BaseDal中上下文实例[8]是通过new产生的,只要执行到new所在代码就会产生一个上下文实例。可以用一个单独类来产生上下文实例,再新建一个DbContentFactory类,功能用来保证线程内共享一个上下文实例。
在此类下创建一个方法GetCurrentDbContent(),通过该方法用来创建上下文对象,返回值类型设置为DbContext,因为Model层中如果还有其他的上下文对象,那么只要把new后面的具体上下文对象名称更改就可以切换上下文对象。
3.7 封装数据访问层统一入口DbSession类
在数据访问层继续封装一个DbSession类,让它拥有所有DAL的实例和更新到数据库的方法,也即是让DbSession类为整个数据访问层与数据库的会话类,像EF上下文封装了所有表对应实体集合DbSet
接下来把数据访问层基类BaseDal.cs中所有Db.SaveChanges()代码全部删除,也即是不要在数据访问层每一个操作都去与数据库交互。这样做优点是数据提交的权利从数据库访问层提到了业务逻辑层。如果在数据库访问层每个方法都有SaveChanges()方法,那么每操作一次都会与数据库发生交互。而到了业务层来了就非常灵活,多个操作可以“积攒”一起提交,当然需要的话也可以一个操作结束了就提交,只要加上DbSession.SaveChanges()语句即可。
3.8 建立IDbSession接口,让业务层依赖接口
业务逻辑层中语句:DbSession dbsession=new DbSession();即DbSession所在层与BLL层之间紧密依赖,因此需定义一个IDbSession类,用来隔离DbSession所在层与BLL层之间的依赖,然后让DbSession去实现IDbSession。
但是这里还有问题,就是通过new实例化对象,只要执行,就会产生新的实例。因此需要封装成一次请求共用一个实例(比如封装为GetCurrentDbSession方法)。然后回到业务逻辑层改造获取dbsession实例代码,采用上面封装好的方法,这样系统就又进一步得到了优化。后续要得到userInfoDal等各个实例的DAL,可以通过统一的数据库访问入口DbSession来获取。
至此,数据访问层从可扩展性、可复用性及可维护性等方面均得到了非常大的优化。
4 结束语
系统具有可扩展性、可复用性及可维护性是一个基本要求,文中基于接口编程的思想,选择.Net平台,采用EF技术,一步步分析阐述了如何对数据访问层进行优化,并给出核心代码,从而加深加速软件技术开发人员更好地理解数据访问层常用的技术思想,为同行提供一种数据访问层的实现技术参考。数据访问层实现技术不是一成不变的,没有最好,只有更好,比如数据访问层实例对象可以通过依赖注入方式(Spring.Net)注入到业务逻辑层,读者可以在理解的基础上根据系统的实际业务需求作出选择或进一步优化。
