人工智能在图书馆特藏文献资源建设中的应用
2021-06-22解登峰李靓宋相濡
解登峰 李靓 宋相濡


摘 要 我国每年出版图书50多万种,造成图书馆特藏文献资源建设工作面临信息过载的问题,基于人工智能的推荐系统可以有效缓解信息过载,解决特藏文献难发现、难收全的现实问题。本研究通过将深度学习技术融入推荐系统中,构建图书馆特藏文献需求模型,设计出特藏文献自动识别系统,通过介绍其工作流程与效果,为图书馆开发个性化、高性能的特藏文献推荐工具提供参考与借鉴。
关键词 深度学习 特藏文献 推荐系统 人工智能
分类号 G250
DOI 10.16810/j.cnki.1672-514X.2021.05.008
Artificial Intelligence Applies to Special Collections Acquisition of Library
Xie Dengfeng, Li Liang, Song Xiangru
Abstract In China, more than 500,000 books are published every year, which causes the problem of information overload in the construction of special collections. The artificial intelligence-based recommendation system can effectively alleviate the information overload and solve the practical problems of hard to find and collect special collections. This study integrates deep learning technology into the recommendation system, constructs the demand model of librarys special collection literature, designs the automatic recognition system of special collection literature, and introduces its workflow and effect, so as to provide reference for the library to develop personalized and high-performance special collection literature recommendation tools.Keywords Deep learning. Special collections. Recommendation system. Artificial intelligence.
0 引言
1957年,我国图书馆学的奠基人之一杜定友先生根据实践经验提出:“各馆藏书除供应一般读者的需要外,必须根据当地地理环境、建设需要、历史传统、藏书基础和读者的要求,做重点配备、重点发展。各馆应有若干专藏,每个专藏应配备专科研究员,为读者服务。”[1]在他的提倡下,高校图书馆越来越重视重点学科文献资源的建设,努力建设反映学科特色、结构完整的专题性的特色文献资源。美国研究型图书馆协会(Association of Research Libraries, ARL) 在《作为核心的特藏》报告中也指出:由于特藏(Special collections)的卓越特性,特藏的建设可以为研究型图书馆的发展提供丰富的机会,以实现其教学和科研任务[2]。在馆藏资源日益同质化的当下,特藏资源日益成为图书馆声誉、地位及核心竞争力的根本保障,建设特色鲜明的馆藏体系成为图书馆界的共识,加强特藏资源建设也成为图书馆资源建设的发展趋势。但文献数量迅猛增加带来了严重的“信息过载”问题,如何快速、有效地从纷繁复杂的信息中获取特藏文献信息成为了当前特藏文献资源建设的关键难题,利用人工智能技术提升特藏资源建设的必要性和重要性变得愈发突出。
基于机器学习技术的推荐系统作为解决信息过载问题的有效方法,已经成为学术界关注的热点并得到了广泛应用。推荐系统本质上是从一堆看似杂乱无章的原始数据中,抽象出用户的兴趣特征,挖掘用户的偏好。因深度学习技术具有优秀的自动提取抽象特征的能力,所以将深度学习与推荐系统相结合已成为近年来推荐系统发展的一个新方向[3]。以学科为标准的特藏文献书目数据具有鲜明的属性特征,基于机器学习的人工智能技术可感知和理解这些特征数据,从而实现从海量文献信息中自动识别特藏文献。
1 研究现状
图书馆一直都是信息技术应用的先行者,对于信息技术的发展有着高度敏感性,持续关注人工智能技术在图书馆领域的应用。Smith在1976年对AI在图书馆信息检索系统中扮演的角色和潜在作用进行了调查[4]。Burger在1984年讨论了四种与信息检索系统相关的AI概念——模式识别、表示、问题解决、学习,并将其应用于自动化编目中的权限控制领域[5]。Watsein在1986年回顾了自然语言处理、专家系统、机器人和传感系统在图书馆编目、在线信息和推荐咨询中的使用和限制[6]。Teodorescu在1987年比较了AI的自然语言理解和信息检索范式的进展,并概述了AI在问答咨询系统中的适用性[7]。Fenly于1988年报告了美国国会图书馆使用专家系统技术在其职能部门,例如采购、编目和期刊控制中的应用[8]。Hjerppe等人在1985年和1989年分别探讨了专家系統辅助编目特别是选择入口上的作用和AACR2作为专家系统的知识库与编目的关系[9]。《2017新媒体联盟地平线报告:图书馆版》将人工智能技术列为4到5年内重点关注的技术之一[10],Gartner将其列为“十大战略技术”之首[11],吴建中认为其是影响图书馆发展的十大热点问题之一[12],李晨晖等认为其是“未来十年图书馆颠覆性技术”[13]。不过,当前学界对于人工智能与图书馆的研究呈现出同质化的态势,绝大多数研究局限于从宏观层面讨论技术的应用[14]。在应用上还处于探索期和实践期,更多使用了一些具有人工智能作用的设备,如ATM自助图书、智能书架、仓储式图书馆、自动传送设备等,也包括一些具有智能化的服务类机器人的应用[15]。
笔者通过中国知网以关键词“机器学习、人工智能”“资源建设、特藏资源”进行搭配组合式检索,搜索出的文献少之又少,可见当前机器学习或人工智能在图书馆文献资源建设领域的研究极为有限。因此,本研究将从涉海图书这一特藏文献中提取相关文献特征,利用由监督学习方法构建、可随特藏文献建设同步变化的自适应智能识别系统,实现从海量图书出版信息中人工智能识别涉海图书,对业界研究人工智能技术在文献资源建设中的应用具有借鉴意义。
2 基于深度学习的推荐方法
传统的推荐方法主要包括协同过滤、基于内容的推荐方法和混合推荐方法,其中协同过滤是利用用户与项目之间的交互信息为用户进行推荐,需要大量的评分记录,因此存在评分数据稀疏的问题以及新项目的冷启动问题;基于内容的推荐方法是利用用户已选择的项目来寻找其他类似属性的项目进行推荐,但是这种方法需要有效的特征提取。随着互联网中越来越多的数据能够被感知获取,包括图像、文本、标签在内的多源异构数据蕴含着丰富的用户行为信息及个性化需求信息,融合多源异构辅助信息的混合推荐方法因其能够缓解传统推荐系统中的数据稀疏和冷启动问题,而越来越受到重视[16]。
近年来,深度学习在图像处理、自然语言理解和语音识别等领域取得了突破性进展,为推荐系统的研究带来了新的机遇。一方面,深度学习可通过学习一种深层次非线性网络结构,表征用户和项目相关的海量数据,具有强大的从样本中学习数据集本质特征的能力,能够获取用户和项目的深层次特征表;另一方面,深度学习通过从多源异构数据中进行自动特征学习,从而将不同数据映射到一个相同的隐空间,能够获得数据的统一表征[17]。基于深度学习的推荐系统研究的新进展,其越来越多地受到国际学术界和工业界的关注。ACM推荐系统年会(ACMRecSys)在2016年专门召开了第一届基于深度学习的推荐系统研究专题研讨会(DLRS16),研讨会指出深度学习将是推荐系统的下一个重要方向,基于深度学习的推荐系统研究目前已经成为推荐系统领域的研究热点之一。
深度学习包括有监督学习和无监督学习,其中有监督学习通过对数据的学习和训练,获得对应数据隐含规律的模型,对事实真相进行描述,并能够利用模型进行有效预测[18]。有监督学习是建立在人类先验的经验基础上,已经对事物进行一定的描述、概括、分类,让监督学习算法对数据进行训练和学习,获得可靠的描述模型。图书馆现有的数据,绝大部分为有标记数据,因此人工智能图书馆当前主要采用有监督学习技术[19]。特藏文献资源的识别就是基于已有馆藏特藏文献资源数据,并基于采访馆员工作经验构建特藏文献描述模型,从而实现特藏文献资源的自动识别。
3 图书书目数据特点与涉海图书书目数据特征
我国大陆图书在出版发行前就有CIP(Cataloguing In Publication)数据,是依据相关的国家标准《普通图书著录规则》(GBT 3792.2-2006)、《文献叙词标引规则》(GB/T 3860-1995)以及《中国图书馆图书分类法》和《汉语主题词表》对图书进行著录、分类标引、主题标引。数据项目包括书名与著作责任者项、版本项、出版项、丛书项、附注项、标准书号项、主题词、分类号等。图书发行后,各图书供应商、图书馆等机构都会编制各种图书书目数据,这些数据在结构上属于格式化数据,受控于中国机读目录(CNMARC)格式标准、《中国图书馆分类法》、《中国分类主题词表》等。这些书目数据原本就是满足机读要求的格式化数据,可以满足机器学习的需要,另外通过书目数据对图书的选题、基本内容做了基本描述,内容附注数据又进一步揭示图书的主要内容。特藏文献,尤其是以学科为标准的专题图书都有明显特征,并且集中体现在题名、提要、分类、主题词四个数据项目上。
涉海图书的筛选一直采用人工识别的方式,通过人工逐条浏览中标图书供应商提供的征订书目数据,发现涉海信息后作为特藏文献予以标记,其本质是根据书目数据中的题名、分类、主题、内容等多维度、多源化的数据项进行综合评价和判断。机器完全可以通过学习掌握涉海图书特征,对上述数据项目进行自动识别和判断,通过机器学习特藏文献特征来辅助或代替人工处理海量新书数据具有技术、工作逻辑可行性。在新书出版种类巨大,采访馆员无法收集更无法处理完整、全面的出版信息的情况下,机器自动识别无疑具有巨大优势。
为全面标记涉海图书特征,笔者十余年来分别对涉海古文献、民国时期涉海图书、2016年我国出版的涉海图书、中国海洋大学图书馆馆藏涉海图书等2万多种图书进行了分析,共整理出涉海图书中图分类号386个,其中,出现即可判定涉海图书的中图分类号103个,需要组配主题词、高频词才能识别涉海图书的中图分类号283个;涉海主题词2594个,其中,出现即可判定涉海图书的主题词1240个,需要组配高频词、分类号才能识别涉海图书的主题词1354个;涉海高频词471个。
4 涉海图书识别系统的模型设计及模块
涉海图书识别是一个明显的二分类任务,本研究选择将注意力机制引入模型中,更多地专注于提取文本序列中字与字之间的影响力,实现了基于BiLSTM-Attention的文本二分类命名实体识别模型,该模型由Embedding模块、BiLSTM模块及Self-Attention-CRF模块组成,其框架结构如图1所示。该模型首先对待分类的图书信息文本进行预处理,通过Embedding模块将经过分词处理后的输入文本表示成向量的形式,再将Embedding模塊对应的向量输入至BiLSTM模块中进行上下文特征的提取,然后将BiLSTM模块的输出输入至Attention模块中,最后得到涉海图书识别结果。
4.1 Embedding与BiLSTM模块
Embedding模块主要负责将输入的中文词语转换成向量的形式,每个词语对应的向量由预训练得到的词向量构成,中文词向量来源于词向量工具在中文语料库上的语言模型训练结果。BiLSTM模块的输入为Embedding模块的输出,使用双向LSTM结构提取输入文本的上下文特征,该模块由LSTM前向层、LSTM后向层和拼接层组成,其结构如图2所示。
BiLSTM模块组成一种网络,即长短期记忆网络(Long Short-Term Memory Neural Network),简称LSTM,在网络的每一层中都通过“门”向单元状态中移除或添加信息,每个“门”由sigmoid函数和逐點乘法运算组成,sigmoid函数输出0到1之间的数值,描述了信息可以通过门限的程度,0为不让任何信息通过,1为让所有信息通过。“门”通过权重参数和偏置参数对信息进行筛选,决定信息通过的多少,这些参数在网络训练过程中得到。每个LSTM单元通过遗忘门、输入门和输出门三个“门”来控制信息对单元状态的影响。设上一记忆单元输出为ct-1、上一隐藏层输出为ht-1、当前时序为t、输入为wt、当前候选记忆单元输出为c't、当前记忆单元输出为ct、当前隐藏层输为ht,用到的激活函数为sigmoid或tanh函数:
遗忘门(forget gate)主要负责控制有多少上一时刻记忆单元中的信息可以累积到当前时刻的记忆单元中,计算该门输出值ft:
其中Wfc、Wfh、Wfw分别为Ct-1、ht-1、Wt的权值参数,bf为偏置参数,选用sigmoid函数为激活函数。
候选记忆单元:计算输出值c't:
其中Wch、WcW分别为ht-1、Wt的权值参数,bC为偏置参数,选用tanh函数为激活函数。
输入门(input gate)主要控制有多少候选记忆单元的信息可以进入该时序的记忆单元,计算该门输出值it:
其中Wic、Wih、WiW分别为Ct-1、ht-1、Wt的权值参数,bi为偏置参数,选用sigmoid函数为激活函数。
记忆单元的值Ct来源于遗忘门调节的上一记忆单元输出以及输入门调节的候选记忆单元的输出:
其中ft、it为遗忘门与输入门的输出值。
输出门(output gate)主要控制有多少记忆单元的信息可以进入当前隐藏层的计算,计算输出门输出值Ot:
其中Woc、Woh、Wow分别为Ct、ht-1、Wt的权值参数,bo为偏置参数,选用sigmoid函数为激活函数。
当前隐藏层:当前隐藏层的值来源于输出门调节的经过非线性激活函数tanh的Ct:
遗忘门、输入门、输出门以及记忆单元的设计,使得LSTM单元有保存、读取和更新长距离历史信息的能力。
对于每个文本序列时刻t,Embedding模块对应的输出为et,LSTM前向层在时刻t的输出 可通过 以上各公式进行计算。LSTM后向层的计算也是类似,但其计算起始位置是从文本序列的末端开始,按照相反的顺序进行。因此, 、 可表示为:
其中 是LSTM单元的输出维度。
拼接层将LSTM前向层的输出 和LSTM后向层的输出 拼接起来得到当前时序t的输出 :
可知BiLSTM模块的输出H为:
其中n为输入文本序列长度。
4.2 Attention模块
Attention模块主要完成文本分类任务,其输入为BiLSTM模块的输出H,输出为该文本的分类结果。设W为输入文本的矩阵表示、n为文本长度、dim为Wt的维度(即 LSTM_dim*2)、S1为权值参数,计算权重矩阵α:
可知α为长度n的一维矩阵,α的值代表该词在整个输入文本中的权重信息。而后将原文本的表示矩阵W与权重矩阵α相乘,得到经过注意力矩阵赋予权重后的特征向量H:
该层选用tanh为激活函数。最后经过输出层得到预测的关系分类标签 y':
其中Wh为H的权值参数,bh为偏置参数,y'为最后输出的预测文本二分类结果。
5 涉海图书识别系统的实现
为了对模型进行充分的实验验证,先进行了词向量的预训练,然后基于TensorFlow框架实现了涉海图书信息识别模型,系统实现流程见图3。
5.1 词向量预训练与特征处理
通过随机采样,提取了2009—2020年每年2万条书目信息,共24万条书目信息,只标注了2440条数据,比例为0.01%,数据样本严重不平衡,考虑到样本严重不平衡会导致模型过拟合的问题,于是又从书目库中标注了6,069条涉海数据,扩充正样本总量,占比提高到3.42%。提取每条书目记录中的主题名、题名、出版题名、作者、出版社、出版地、读者对象、主题词、简介9个属性内容,经过预处理后,调用jieba库进行分词处理得到161M的中文分词文本;将分词文本作为Word2vec工具(gensim库)的输入,使用Skip-gram模型进行训练,得到中文词向量。另对书目记录中的中图分类号、出版社这种带有类别信息的字段进行One-Hot编码,离散化能提升模型的非线性能力。
5.2 模型实现及训练参数设置
模型的代码实现基于Google开源的机器学习框架TensorFlow,将数据集随机等分为10份,其中8份作为训练集,1份作为验证集,1份作为测试集。
由于涉海图书数量较少,在提取的书目数据中占比很低,造成数据集中正、负样本极度不平衡,为保证模型效果,对训练集中的负样本按照与正样本1:1的比例进行采样。模型参数设置如表1所示。
其中BiLSTM模块中的隐含层维度是指单向LSTM隐含层的维度,该模块输出是拼接了前向LSTM和后向LSTM的输出,输出维度为100*2,即200。
5.3 评价指标
在文本二分类任务中,根据测试集标注的正确结果与模型预测的结果可分为真正例(True Positives)、假正例(False Positives)、真负例(True Negatives)和假负例(False Negatives),以计算模型对预测输入条目为涉海图书的评价指标为例,得到其混淆矩阵如表2所示。
而评估模型在判断输入条目为涉海图书上的准确率(Precision)、召回率(Recall)和F1值(F1-Measure)是基于上述混淆矩阵中TP、FN、FP、TN四个类别的数量计算得来。
准确率是计算被预测为涉海图书的条目数量中,实际标注为涉海图书条目所占的百分比,衡量了模型“找准”的能力。召回率是计算实际标注为涉海图书的条目数量中,也被模型预测为涉海图书条目所占的百分比,衡量了模型“找全”的能力。在实际的实验结果评价中,使用以上公式计算涉海图书条目预测的准确率、召回率及F1值。
5.4 调参结果
按照表1设置的参数,按照验证集、测试集中正、负样本的比例,计算加权后的准确率、召回率及F1值,得到如表3的实验结果。
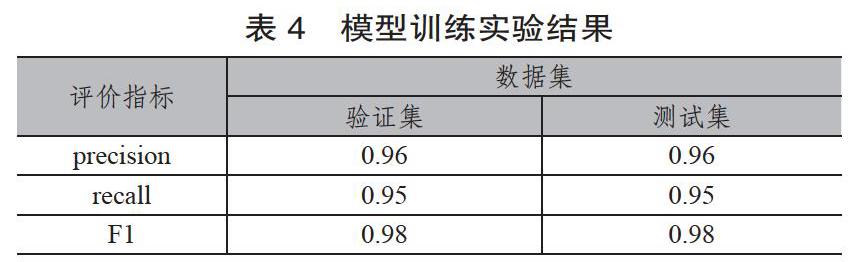
考虑到样本中的正样本偏少,实验结果会有误差,于是我们重新把数据集随机等分为10份,其中6份作为训练集,2份作为验证集,2份作为测试集,进行训练,得到如表4实验结果。
learning rate(学习率)作为最重要的超参数,调整该参数,一般取值在0.001~0.05之间,将其调为0.05后的结果如表5所示。
将learning rate(学习率)调为0.001,实验结果如表6所示。
根据评级指标以及模型的训练表现,考虑到模型的泛化能力,最终选择表3的参数作为模型的最终参数如表7所示。
6 涉海圖书自动识别系统效果与评价
目前,涉海图书自动识别系统支持ISO数据包及Excel文件的批量导入、批量识别,识别结果支持Excel输出。为验证该算法模型及涉海图书自动识别系统的有效性、人工识别与机器识别的差异,笔者在图书供应商的征订目录中随机抽取了2万条书目记录,分为10个书目数据包,每包均有2000条书目数据。在机器识别前,先由具有十余年涉海特藏建设经验的馆员按每天1000条书目数据的速度进行人工识别,后通过涉海图书识别工具进行机器识别,二者的识别结果对比如表8所示。
通过表8可以发现,在2万条书目记录中,共有300条涉海图书,占比为1.5%,人工识别率为88.7%、漏检率为11.3%、错检率为1.0%;机器识别率为83.3%、漏检率为16.7%、错检率为17.7%。通过上述数据可以得出以下结论。
6.1 机器识别较人工识别效率高、成本低
数量少是特藏图书之所以被称之为特藏的根本特征,这在涉海图书中表现得尤为明显,涉海图书占比仅有1.5%。目前我国每年出版50多万种图书,如果以人工识别的方式来发现这1.5%,需要投入大量人力及时间,这在图书馆的人力资源越来越紧张的形势下显得尤为困难。机器识别可以在几分钟内处理上万条书目信息,快速发现特藏文献,能够为图书馆特藏资源建设提供助力。
6.2 机器识别的正确率有待提高
机器学习工具是建立在书目文本信息基础上的,对自然语言的正确认知能力还非常有限,尤其是带有修辞性质的自然语言极易造成机器错检。表4中机器识别的错检率为17.7%,主要是由文本信息虽然涉海,但其本意却并非涉海造成的,比如内容简介中出现“从浩瀚的成语海洋中”“就像是一片智慧的海洋”“作者徜徉于文字的海洋里”时,机器识别直接将其归为了涉海图书。这一点还需要后期对其不断进行数据训练,以更好地应对这类特殊情况。人工识别的错检率虽然很低,只有1.0%,但也表明其在处理大量数据时也存在操作及判断失误的情况。
6.3 书目数据质量直接影响了人工及机器识别率
为准确判断人工识别与机器识别的差异,二者都在同样的书目信息基础上进行识别,馆员基于丰富的经验和知识积累,人工识别正确率达到88.7%,机器识别正确率为83.3%,二者相差5.4%,差距相对较小。机器识别漏检的图书多为年鉴、旧方志、旧史料、游记等,产生的原因主要是沿海地名、旧名不具有现代海洋语言特征,机器无法判断,而书目中的其他信息也没有体现出海洋相关信息。人工识别漏选的主要原因一方面在于原书目信息特别少,导致难以判断,另一方面在于书目信息杂乱,不易发现涉海信息。由此可见,书目数据质量直接影响了特藏图书的发现。
7 结语
人工智能等新一代信息技术被引入图书馆服务,将有效促进图书馆提升服务质量。目前,图书馆部分工作已经开始摆脱对图书馆员直接的依赖,逐渐能够利用计算机自动处理和完成大量的服务性工作,从根本上实现图书馆业务模式的转型发展[20]。在图书馆业务研究中也已有许多学者围绕人工智能技术开展了一系列理论研究与探索,相信在不断的研究实践探索中,人工智能技术会在图书馆的业务和服务中越来越成为图书馆人和读者的好帮手。从本研究的结果来看,基于人工智能技术实现特藏文献资源的自动识别,能够有效地缓解信息过载,提升了特藏文献资源建设工作的质量和效率,证实了人工智能应用理论、技术与算法的有效,在图书馆基础业务领域广泛应用人工智能值得继续深入研究与实践。
参考文献:
[ 1 ]杜定友.图书馆怎样更好地为科学研究服务[J].图书馆学通讯,1957(2):49-51.
[ 2 ]
Special at the core: aligning,integrating,and mainstreaming special collections in the research library[EB/OL].[2016-06-01].http://publications.arl.org/rli283 /1.
[ 3 ]王俊淑,张国明,胡斌.基于深度学习的推荐算法研究综述[J].南京师范大学学报(工程技术版),2018,18(4):33-43.
[ 4 ]
SMITH L.Artificial intelligence in information retrieval systems[J].information Processing and Management.1976,12(3):189-222.
[ 5 ]
BURGER R H.Artificial intelligence and authority control[J].Library Resources and Technical Services,
1984,28(4):337-45.
[ 6 ]WATSTEIN S,KESSEIMAN M.In pursuit of artificial intelligence[J].Library Hi Tech News,1986(30):1-9.
[ 7 ]
TEODORRESCU I.Artificial intelligence and information
retrieval[J].Canadian Library Journal,1987,44(1):29-32.
[ 8 ]FENLY C,HARRIS H.Expert systems:concepts and applications[J].Advances in Library Information Technology,1988(1):44.
[ 9 ]HIERPPE R,OlANDER B.Cataloging and expert systems:
[10]AACR2 as a knowledge base[J].Journal of the American Society for Information Science,1989,40(1):27-44.
[11]NMC Horizon Report (2017Library Edition)[EB/OL].[2018-07-12]. http://cdn.nmc.org/media/2017-nmc-horizon-report-library-EN.pdf.
[12]
PETTEY C. Gartner identifies the top 10 strategic technology trendsfor 2018[EB/OL].[2018-07-12].https://www.gartner.com/smarterwithgartner/gartner-top-10-strategic-technology-trends-for-2018/.
[13]
吳建中.再议图书馆发展的十个热门话题[J].中国图书馆学报,2017,43(4):4-17.
[14]
李晨晖,张兴旺,秦晓珠.图书馆未来的技术应用与发展:基于近五年Gartner《十大战略技术趋势》及相关报告的对比分析[J].图书与情报,2017(6):37-47.
[15]黄晓斌,吴高.人工智能时代图书馆的发展机遇与变革趋势[J].图书与情报,2017(6):19-29.
[16]傅云霞.人工智能在智慧图书馆建设中应用研究[J].图书馆工作与研究,2018(9):47-51,79.
WANG H,WANG N,YEUNG D Y.Collaborative deep learning for recommender systems[C]Proceedings of the 21st ACMSIGKDD International Conference on Knowledge Discovery and Data Mining.Sydney,Australia,2015:1235-1244.
[17]
PENG Y,ZHU W,ZHAO Y,et al.Cross-media analysis
and reasoning:Advances and directions. Frontiers of
Information Technology & Electronic Engineering,2017,18
(1):44-57.
[18]MEHRYAR M, AFSHINf R, AMEET T. Foundations of machine learning [M].Cambridge City the MIT Press,2012:7.
[19]王红,袁小舒,雷菊霞.人工智能:图书馆应用架构和服务模式的重塑[J].现代情报,2019,39(9):101-108.
[20]初景利,段美珍.从智能图书馆到智慧图书馆[J].国家图书馆学刊,2019,28(1):3-9.
