基于卷积自编码器分块学习的视频异常事件检测与定位
2021-06-22李欣璐吉根林
李欣璐,吉根林,赵 斌
(南京师范大学计算机与电子信息学院/人工智能学院,南京210023)
引 言
视频异常事件检测是计算机视觉的重要应用之一,它可以将潜在的危险事件检测出来,并发出警报,从而提高有关部门和机构的响应效率。目前视频异常事件检测得到了广泛的研究,人们提出了针对各种场景和检测要求的异常事件检测方法,其中的关键问题就是视频前景中运动物体的特征表示。由于视频场景具有多样性,且异常的定义具有主观不确定性,异常事件检测任务存在一定的挑战。例如,为了发现跌倒或打架斗殴等指定异常动作,研究者通常以视频中的行人交互问题为中心,重点提取行人的姿态特征和运动特征[1⁃2],采用姿态估计[3]和动作识别[4]的方式检测视频中的行人是否存在异常动作。但是,在现实场景中发生的异常往往是不可预计的,而该类异常检测方法仅能检测出指定的人体异常动作,通用性不强。并且在人群密集的场景下,存在行人遮挡和视频分辨率低的问题,姿态估计和动作识别的准确度不高,直接影响了异常检测的准确性。本文针对基于姿态和动作的异常检测方法存在的不足,采用表观特征和运动特征共同表示前景物体的运动特征,将方向梯度直方图(Histogram of oriented gradient,HOG)作为表观特征,并选取深度神经网络提取出的光流作为运动特征。HOG特征的提取较为简单并且可以清晰表示视频画面中的纹理信息,能够检测出可疑物体。深度神经网络提取出的光流比传统光流法提取的光流更加准确且能够充分表示移动物体的运动状态,能够检测出运动异常。采用光流和HOG特征相结合的方式,不仅能检测出视频中的异常行为,还可以检测出非行人实体闯入视频区域的异常情况,增强了异常检测模型的普适性。
异常事件在现实场景中不常发生,因此正常样本的数量远大于异常样本的数量。针对正负样本数量不均的问题,本文采用卷积自编码器进行特征学习,仅用正常视频样本训练模型,无需对训练集和测试集进行重新划分。通过学习正常的行为模式,将与正常运动模式不匹配的情况设定为异常,可检测所有的非正常事件。异常检测的常用方法是将视频帧的特征提取出来之后,直接放入异常检测模型中进行特征学习。而本文考虑到在视频的不同区域,视觉信息和移动物体的运动状态差异较大,首先将视频帧均匀划分成互不重叠的图块,再对每一个图块进行特征提取。让卷积自编码器针对视频不同区域中的特征进行学习,在检测时判断视频某一位置上的图块是否存在异常事件,不仅使模型的学习内容更有针对性,同时能实现异常事件定位。
1 相关研究工作
视频异常事件检测可分为两个部分:视频特征的提取和异常事件检测模型的建立。视频特征提取对于异常事件检测的精确度起到关键作用,常用的特征主要分为手工设计的特征和深度模型提取的特征。Mahadevan等[5]利用混合动态纹理(Mixtures of dynamic textures,MDT)对人群中的局部异常进行检测。张俊阳等[6]考虑到异常事件通常发生在前景区域,利用自适应混合高斯模型进行背景分割,提取视频前景进行人群异常事件检测,减少计算量。光流可以较好地表示移动物体的运动特征,Cong等[7]改进光流直方图,利用多尺度的光流直方图(Multi⁃scale histograms of optical flow,MHOF)捕捉视频中物体的运动信息,Colque等[8]提出了基于光流场矢量的方向、模长、像素熵值的运动特征HOFME(His⁃togram of optical flow orientation and magnitude and entropy)。Mehran等[9]提取光流信息中更高层次的语义特征,利用社会力模型(Social force,SF)进行人群异常检测。另一种具有高层语义的特征是移动物体的轨迹,常用于交通异常事件检测[10],但是在存在遮挡时轨迹提取效果不佳。多种特征融合的方式比单一特征具有更强的表达能力,Xu等[11]对视频前景图像块与光流场块进行像素级别的融合,形成新的图块,再将其输入去噪自编码器,以学习融合图块的深度特征。近年来深度学习快速发展,研究者常用深度模型对视频进行特征提取。异常检测任务中常用的深度模型有:全卷积神经网络[12]、稀疏去噪自编码器(Sparse denoising auto⁃encoders,SDAE)[13]等。此外,双流卷积网络[14]可提取出人体的动作特征来对视频中行人的动作进行识别,可用于异常动作检测。人体骨架特征可以较好地表示行人姿态,Morais等[15]利用深度神经网络提取出视频中行人的骨架特征,通过单个行人的骨架序列进行异常行为检测,但是在人群密集的场景下异常检测效果不佳。
根据不同的建模角度,视频异常事件检测模型可以分为基于传统概率推断的模型和基于深度学习的模型。混合概率主元分析(Mixture of probabilistic principal component analysis,MPPCA)是基于概率推断的一种经典模型,Kim等[16]将MPPCA和时空马尔可夫随机场(Markov random field,MRF)相结合以检测人群异常行为。Sabokrou等[17]在将每个视频划分为立方块之后,计算相邻块的相似度值,并利用高斯分布对正常的视频块进行建模,在测试时计算提取的特征和正常特征的距离大于阈值的判定为异常。基于传统概率推断的建模方法常用高斯混合模型(Gaussian mixture model,GMM)和其他的模型进行组合,以提高异常检测的准确度,Feng等[18]将多个GMM堆叠起来对正常行为模式建模,Li等[19]首先假设正常事件的表观及运动特征的深度表示都服从多变量高斯分布,结合自编码器和生成对抗网络进行联合训练,对多变量高斯分布进行拟合。基于深度学习的模型中,常用的两种方法是重构和分类。Hasan等[20]利用传统的自编码器对HOG特征和HOF特征进行学习,并用卷积自编码器(Con⁃volutional auto⁃encoders,Conv⁃AE)来学习视频序列中的正常模式。Chong等[21]更关注视频帧在时间维度上的变化,利用时空自编码器(SpatioTemporal⁃AE)学习视频片段中的时空特征,在异常检测时利用重构误差计算异常得分,得分低的判为异常视频帧。袁静等[22]在SDAE中增加梯度差约束,以提升自编码器的异常检测效果。利用分类进行异常检测通常需要在训练时就对正常样本和异常样本进行标注,因此会面临正负样本不均的问题。Xu等[11]使用单类支持向量机(One⁃class support vector ma⁃chine,OCSVM)以生成决策边界,对深度融合表示后的特征进行分类。Sultani等[23]提出了弱监督算法框架,利用深度多实例排序方法训练分类网络,减少了异常样本少带来的问题。2020年,Nawaratne等[24]将模糊聚合与时空自编码器的异常检测方法结合起来,提出时空增量学习(Incremental spatio⁃tem⁃poral learner,ISTL)方法实现异常检测模型的更新,不断提高模型的性能。
2 视频异常事件检测与定位方法
2.1 处理流程
本文提出的视频异常事件检测与定位方法处理流程如图1所示。首先将视频样本拆分成视频帧序列{frame1,frame2,…,framet,…,framen},然后将视频帧均匀划分成M×N个互不重叠的图块,每个图块的大小均为S×S。由于运动特征可以反映出视频前景中的运动物体的运动状态,可检测出奔跑、抛掷物品等运动异常,而表观特征可以体现视频画面中是否存在异常物体,例如卡车、自行车等非行人对象,因此需要对视频图块中的运动特征和表观特征进行提取。
在提取运动特征时,将第t个视频帧中某一位置的图块patch(t,i)和第t+1个视频帧中对应位置的图块patch(t+1,i)共同输入到Flow Net2.0[25],可得到第t个视频帧中该图块的光流。Flow Net2.0是一个基于卷积神经网络的深度模型,对于两个视频帧的输入可以计算出前一帧相对于后一帧的光流。对光流的幅值和方向进行颜色编码,移动物体的运动方向用不同的颜色进行表示,而速度大小则用颜色深浅进行表示,最终可得到1个RGB三通道的彩色光流图。对视频帧中每1个图块计算HOG,可提取视频帧图块的表观特征。
对于训练样本和测试样本先进行视频帧的划分和视频帧图块的特征提取;对于某一图块的光流和HOG特征,分别设置一个异常检测卷积自编码器(Anomaly detection convolutional auto⁃encoders,AD⁃ConvAE)进行训练和测试。一个位置图块上的AD⁃ConvAE仅关注该视频位置区域里的人群运动情况,利用分块学习的方式可以更有效地学习局部特征。在训练过程中视频仅包含正常样本,AD⁃Con⁃vAE通过视频帧图块的光流和HOG特征学习某一区域的正常运动模式。在测试时,将测试视频中该区域图块的光流和HOG特征放入AD⁃ConvAE中进行重构,根据光流的重构误差和HOG特征的重构误差计算加权重构误差,若重构误差大,则说明该图块内存在异常事件。

图1 视频异常事件检测与定位方法处理流程Fig.1 Pipeline of video anomaly event detection and localization method
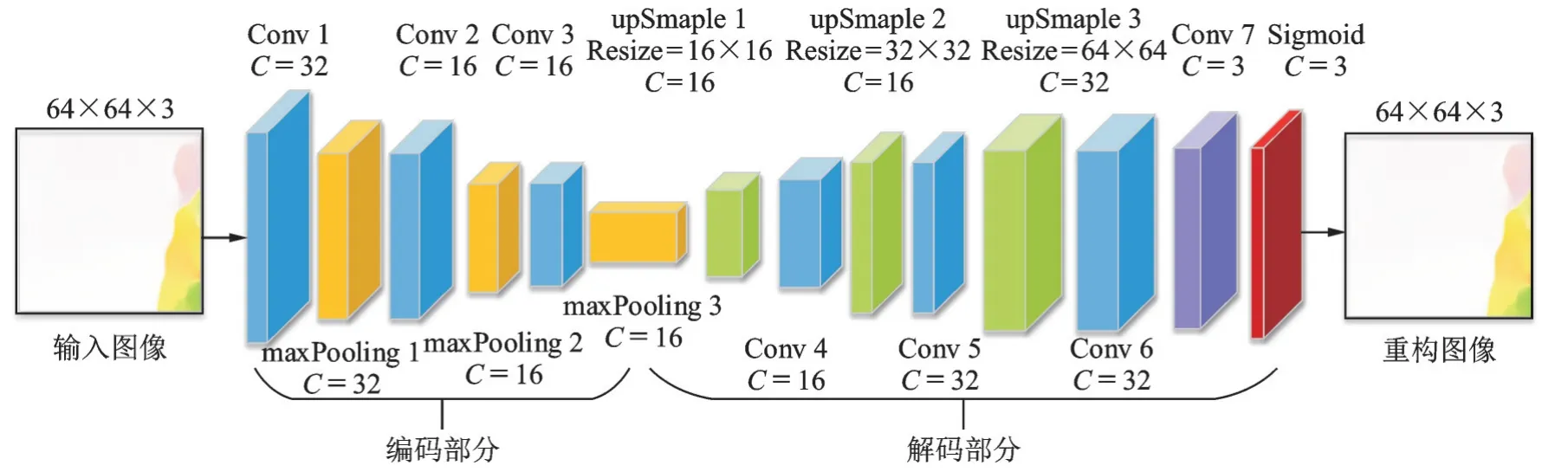
图2 AD-ConvAE的网络结构图Fig.2 Overview of AD-Conv AE structure
2.2 AD⁃ConvAE网络结构
在特征学习的过程中使用卷积自编码器作为特征学习模型,设计的异常检测卷积自编码器AD⁃Conv AE网络结构如图2所示。卷积自编码器和传统自编码器两者的区别在于卷积自编码器采用卷积方法对输入内容进行变换。传统自编码器一般使用全连接层作为网络的基本结构,但对于二维图像来说会丢失一定的空间信息,而卷积层可以更好地保留空间信息。不同于文献[20]中将HOG特征和HOF特征输入到传统全连接自编码器的方法,本文将光流和HOG特征分别输入到卷积自编码器中进行重构,模型在训练过程中学习正常运动模式,在测试时计算重构误差进行异常事件检测。AD⁃Con⁃vAE的网络结构由编码和解码部分组成,在编码部分,对于1个64×64×3大小的输入,经过3个卷积层和3个池化层,最终得到特征的深度表示。在解码部分,对特征的深度表示进行重构,采用卷积操作和上采样操作,输出一个和输入图像同样大小的图像。整个网络中使用到的池化核大小均为2×2,卷积核大小均为3×3,图中c表示通道数,在卷积层中使用n个卷积核就会得到n个通道的特征图。AD⁃ConvAE中使用交叉熵损失函数计算Loss值,其计算公式为
式中:x表示重构图像中某一点的像素值,y表示输入图像中该点像素值。经式(1)计算,可以得到单个像素点的Loss值。对每个像素点都计算Loss值后取平均,可得到图像的平均重构误差。在训练时重构出来的图像和输入图像越像越好,即平均重构误差越小越好。
2.3 异常事件检测与定位方法
在测试阶段,将第t帧的第(m,n)位置上的视频图块提取出来的光流和HOG特征分别放入已训练完成的AD⁃ConvAE中计算重构误差。重构误差大表示测试样本存在异常,重构误差小表示测试样本正常。根据得到的HOG特征重构误差Loss_hog(m,n,t)和光流重构误差Loss_optical(m,n,t),计算该位置上的总重构误差sumLoss(m,n,t)。第t帧的第(m,n)位置上的总重构误差计算公式为

式中:α为HOG特征重构误差的权重,β为光流重构误差的权重,且α+β=1。
通过设置重构误差阈值θ判断该图像块是否存在异常事件。F(m,n,t)=0表示不存在异常事件,F(m,n,t)=1表示存在异常事件,判定规则为
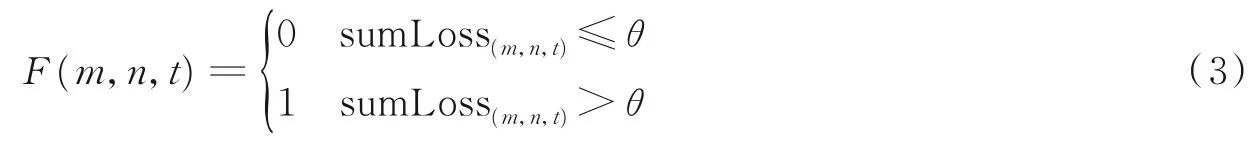
由于采用视频帧分块的方式,让异常事件检测模型针对视频帧中的某一区域判断是否存在异常,因此在异常事件检测的同时完成了异常事件定位。视频异常事件检测模型的训练过程如算法1所示。
算法1视频异常事件检测模型的训练算法

3 实验与结果
3.1 实验设置
本文在3个公开数据集(UCSD Ped1、UCSD Ped2和CUHK Avenue)上验证算法的有效性。UC⁃SD数据集中包含的异常情况主要为:非行人实体闯入人行道,例如卡车、轮椅、自行车等以及异常的行人运动模式,例如奔跑、玩滑板车、推车等。CUHK Avenue数据集中包含的异常情况有:行人奔跑、行人抛掷物品、行人行走方向错误、出现非行人物体,例如自行车等。本文实验部分使用的数据集中,训练集部分仅包含正常模式,而测试集部分包含正常模式和异常模式。
由于UCSD Ped1和UCSD Ped2两个数据集中的视频帧大小不统一,并且为了方便使用Flow Net2.0进行光流提取,在实验开始时首先对视频帧大小进行调整。在实验中,将UCSD Ped1和UCSD Ped2的视频帧大小统一调整为256像素×192像素,将CUHK Avenue的视频帧大小调整为640像素×384像素。在对视频帧进行均匀分块的步骤中,将UCSD Ped1和UCSD Ped2中的视频帧划分成互不重叠的48个图块,每个图块的大小为32像素×32像素。在CUHK Avenue数据集上,将视频帧划分成60个互不重叠的图块,每个图块的大小为64像素×64像素。
实验中使用的GPU型号为NVIDIA GeForce GTX 1060,在Tensorflow框架下实现。在使用卷积自编码器AD⁃ConvAE进行训练时,根据观察Loss值的下降速度,将迭代次数设置为50次。实验结果使用异常检测任务常用性能评价标准:帧级别AUC(Area under the curve)和等错误率EER(Equal error rate)。
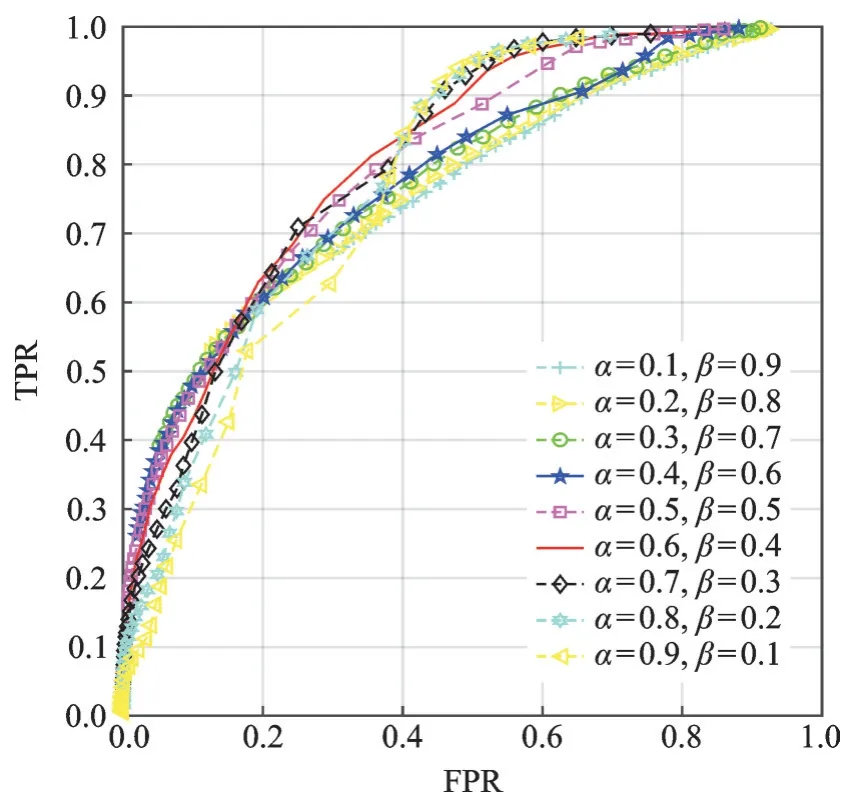
图3 α和β取不同值时的ROC曲线图Fig.3 ROC curves whenαandβtake different values
3.2 实验结果
首先对HOG特征的重构误差权重α和光流的重构误差权重β这两个超参数进行调整,图3给出了在CUHK Avenue数据集上绘制的ROC曲线。其中横轴表示假正例率(False positive rate,FPR),纵轴表示真正例率(True positive rate,TPR)。计算ROC曲线下面积可得到AUC,AUC在不同α和β下的值如表1所示。实验结果表明,当α=0.6,β=0.4时,AUC达到最大值,即表观特征的重要性要略高于运动特征,但是仅考虑移动物体的表观纹理信息或仅考虑移动物体的运动信息时,异常事件检测的效果欠佳。因此结合移动物体的表观特征和运动特征进行异常事件检测合理有效。
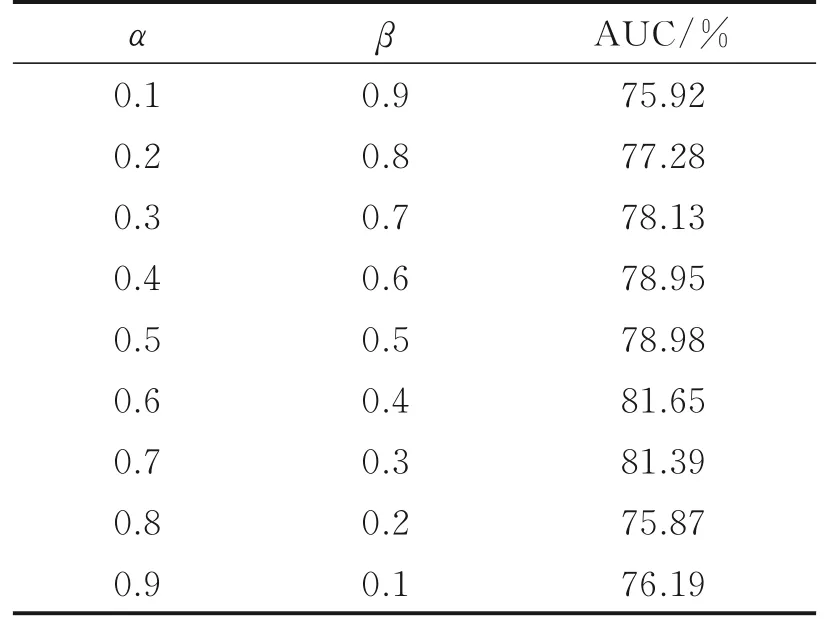
表1 α和β取不同值时AUC值的比较Table 1 Comparison of AUC with different val⁃ues ofαandβ
本文所提方法在UCSD Ped1、UCSD Ped2和CUHK Avenue三个公开数据集上,与基于传统手工特征的异常检测方法[5,8⁃9,16]和其他基于深度学习的异常检测方法[20⁃21,24]进行对比。由实验结果可知,基于深度学习的异常检测方法整体优于传统的异常检测方法。其中文献[20]中的异常检测方法没有进行分块学习与检测,由此可见针对视频的不同位置进行特征学习,可以有效地提升异常检测性能。本文所提方法在帧级别的AUC和EER与其他方法的对比如表2所示。

表2 本文所提方法与其他异常检测方法的比较Table 2 Compar ison of our method with other anomaly detection methods %
3.3 视频异常事件检测与定位结果可视化
实验最后将本文提出的异常事件检测与定位方法在3个实验数据集上进行检测结果可视化呈现,在UCSD ped1和UCSD Ped2数据集上的可视化异常事件检测结果如图4所示,图5给出了在CUHK Avenue数据集上的可视化异常事件检测结果。其中,红色的色块标识出视频帧中包含的异常。实验结果表明,本文提出的异常事件检测与定位方法可以有效地检测出视频中存在的异常事件,并给出准确定位。

图4 UCSD Ped1和UCSD Ped2数据集上的可视化异常事件检测结果示例Fig.4 Visualization of abnormal event detection results on the UCSD Ped1 and UCSD Ped2 datasets

图5 CUHK Avenue数据集上的可视化异常事件检测结果示例Fig.5 Visualization of visual abnormal event detec⁃tion results on the CUHK Avenue dataset
4 结束语
本文提出了一种基于卷积自编码器分块学习的视频异常事件检测与定位方法,将视频帧均匀划分成互不重叠的图块,并提取各个图块的光流和HOG特征。利用分块学习的方式,为视频不同位置上的图块分别设计卷积自编码器进行正常模式的特征学习。在异常事件检测时,根据图块中光流和HOG特征的重构误差大小进行异常判断,并实现异常事件定位功能。实验结果表明本文提出的异常事件检测与定位方法优于其他方法,并且可以准确地检测和定位异常事件。
