网络众源地理信息获取与整合方法研究
2021-06-21唐天琪
谈 帅,唐天琪,高 雅
(江苏省测绘研究所,江苏 南京 210013)
0 引 言
大数据资源的快速增长以及数据挖掘和地理信息技术的逐步成熟为高效、智能化的网络众源地理信息获取提供了数据和技术支撑[1]。时空大数据蕴含丰富多样的地理信息,本文研究对象主要是政府公开数据和互联网地理信息数据,但是政府公开数据并非都是完整的数据集,而互联网数据更新周期短,数据信息量更加庞大,因此,迫切需要相关策略解决因数据结构复杂、数据保护措施等原因导致的互联网地理信息数据获取问题。
目前,网络爬虫工具层出不穷,但面对复杂的网页结构、严格的API调用制度或需求不断更新等问题,亟需一条完整的技术路线。黄文杰以标讯快车项目为研究目标,使用广度和深度优先策略[2]。高波针对文本、栅格等不同类型的地理信息数据提出了不同的获取方法[3]。刘石磊[4]、郭丽蓉[5]探讨了一些常见的反爬虫措施以及对应用了该类机制的网站进行爬虫活动的手段和策略。虽然不少学者针对网络爬虫技术进行了研究,但是侧重针对互联网地理信息数据获取的研究较少。
本文着重从数据获取方式中的两种类型——网页型和API型[6]入手,从两种渠道分别详细阐述相关技术路线,为时空大数据的获取提供思路,为地理国情监测工作提供数据方面的支撑,有利于促进新型基础测绘实践的快速开展。
1 互联网地理信息数据特点
网络地理信息服务与桌面地理信息系统软件相比,前者存在明显的限制:① 带宽限制,地理信息通过互联网、移动网络传输的速率低于本地存储设备以及稳定的内部网络;② 客户端处理能力限制,作为网络地理信息的客户端——网页、移动设备,前者运行于浏览器内,出于安全考虑,浏览器中的网页一般不能取得直接调用本地计算资源的能力,而移动设备在处理器、内存、存储方面都不及桌面计算机;③ 客户端的多样性,不同浏览器支持Web与JavaScript标准存在差异、不同移动设备操作系统应用程序开发接口(API)与开发语言存在差异。
上述限制给互联网地理信息数据带来了复杂多样的格式,并且需要具备独立于应用程序或供应商、独立于开发语言和环境、带宽占用少等特点。常见的互联网地理信息数据格式如下。
(1)JSON格式
JavaScript Object Notation(JSON)是一种浏览器/服务器之间传输的、公开的网络数据传输数据标准,由键值对组成。目前在网络地理信息服务领域,常用的JSON格式有GeoJSON和ArcGIS Server JSON 2种。
(2)XML格式
可扩展标记语言(XML)是一种用于标记电子文件使其具有结构性的标记语言。它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。主要包括GML、Profile、Application schema、KML、GeoRSS和WKT 6种。
直接可用的互联网地理信息并非显而易见,往往需要进一步分析和挖掘。尤其是网页中信息数据较为分散,其中蕴含的规律并非直观可见,需要设计规则进行挖掘。本文根据互联网地理信息的特点,将获取数据的类型分为网页型和API型。API型主要指通过调用API可以获取并且需要处理格式的数据。网页型主要指地理信息散落在网页上,需要通过分析、挖掘网页背后的结构和规律才能获取的数据。
2 互联网地理信息数据获取技术路线
本文技术路线分为4大阶段,即设计获取规则、互联网信息获取、解析地理信息和数据整合(图1)。设计获取规则是基础,有助于了解网站的架构及确定爬取URL、参数的设置。互联网信息获取的核心是有效地避开不同网站的保护机制,一是利用程序构建HTTP请求,可利用爬虫伪装技术或调用特定API把程序请求伪装为浏览器请求,将互联网信息获取工具伪装成普通浏览器规避爬虫限制,并通过动态代理切换技术,自动更换代理,规避同一IP地址访问频率限制;二是浏览器自动化,借助验证码自动获取等技术,利用Selenium工具,针对需要交互式验证(比如输入验证码)的情况,配合计算机视觉识别验证码并自动登录。解析地理信息和数据整合为后期并行计算、分布式存储提供有力的数据支撑。

图1 互联网地理信息数据获取总体技术路线
3 关键技术内容
3.1 获取规则分析
本文详细阐述两种互联网地理信息数据爬取方式:① 通过访问网页的HTML代码,从中抓取所需节点上的数据;② 通过网站提供的API调用获取所需数据。实际运用过程中,网络爬虫系统一般是几种爬虫技术相结合实现的。
3.1.1 信息架构分析
首先分析网站的信息架构,整理HTML源文件[7],结合后期数据需求,建立目标数据集与互联网站点信息架构之间的映射关系,找出可以用于匹配的特征,选择合适的获取方式并设计对应的获取规则(包括URL规则、网络信息爬取层次规则)。
以分析链家(南京)官网二手房页面为例,打开“Chrome浏览器开发者工具”中的Elements,查看网页结构如图2所示,网页中“位置”选项被层层包裹在div、d1等标签中。网页按照“城市→区域/地铁→房屋属性组合(售价、面积、房型等)”的架构进行设置,如图3所示。

图2 网页架构代码

图3 网页架构组织
3.1.2 URL结构分析
研究目标路径的规则。由于不同城市情况的差异,URL的设置如下:https://{城市}.lianjia.com/ershoufang/{区域或地铁} /{房屋属性,分页组合} /。
3.1.3 URL参数收集
通过勾选不同条件,查看上方地址栏中显示网址,总结出标签与URL路径之间的关系(表1)。
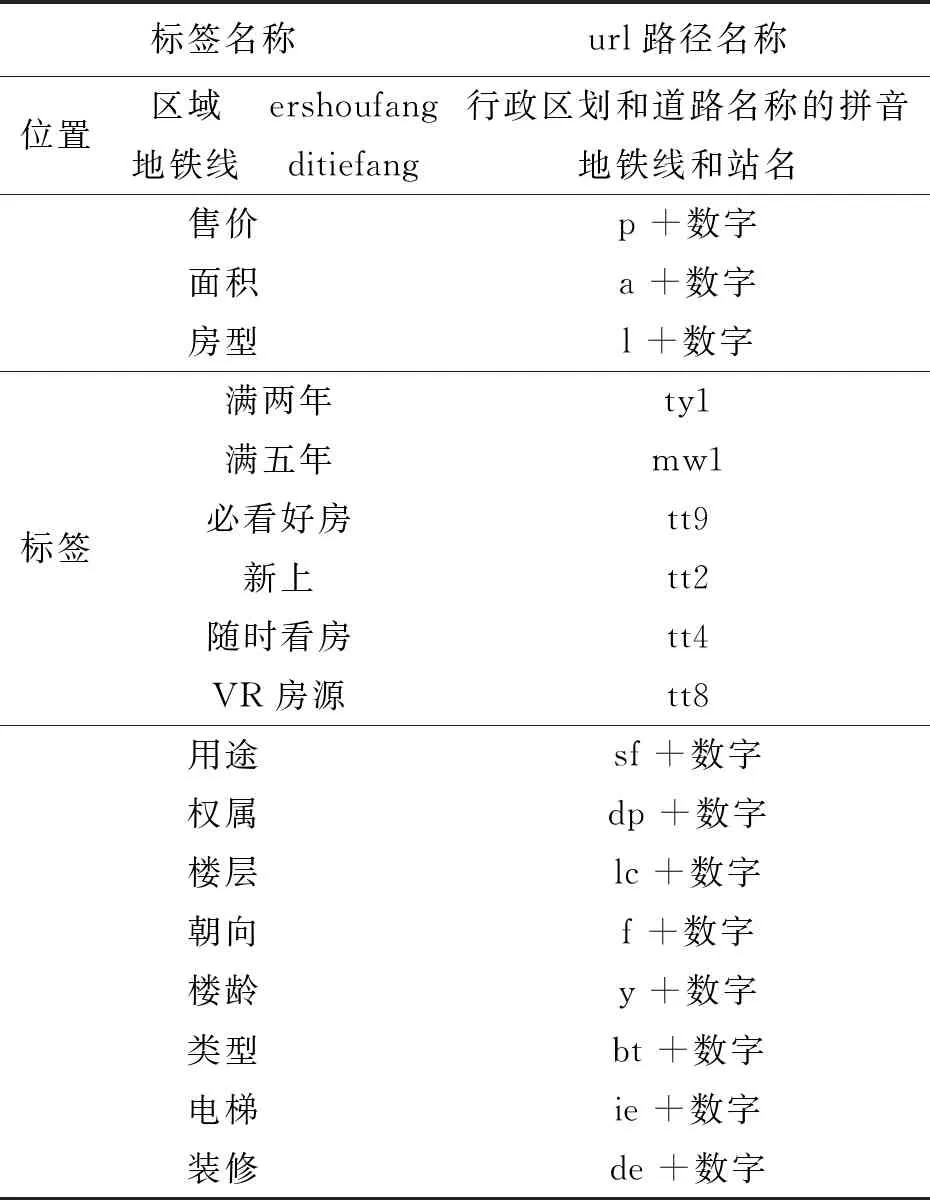
表1 链家(南京)官网二手房网址解析
3.1.4 URL构建
以查找“位于鼓楼区草场门大街,60~90 m2的二室朝南,有电梯,售价在200~300万元之间的普通住宅”为例,网址如图4所示。选择条件先后与url中路径顺序无关。

图4 网址解析
3.2 互联网信息获取
虽然在绝大多数情况下用户使用互联网服务是免费的,但是几乎所有的互联网信息提供商都采取了数据保护措施[8],例如,识别数据爬虫发出的请求并拒绝访问、拒绝来自同一IP的频繁访问、限制查询返回的记录数、对频繁请求要求重新登录并输入验证码等,或隐藏数据真实页面URL,只能通过脚本交互方式打开数据页面等等。本文采用2种规避数据保护策略,即利用程序构建HTTP请求(包含爬虫伪装和特定API调用2种方法)和浏览器自动化(验证码自动获取技术)。
3.2.1 利用程序构建HTTP请求
(1)爬虫伪装技术
User Agent中文名为用户代理,是Http协议中头域的一部分。它是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核等信息的标识[4]。通过该标识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计。一般网站通过分析用户请求的Headers信息,利用服务器查看Headers中的User Agent来判断是谁在访问。如果是互联网信息工具则会被禁止访问,因此,为了隐藏身份,需要手动设置User Agent,伪装成浏览器进行访问。在创建Request对象的时候,传入Headers参数,有如下2种方法设置User Agent:① 在创建Request对象的时候,填入Headers参数(包含User Agent信息),这个Headers参数要求为字典;② 在创建Request对象的时候不添加Headers参数,在创建完成之后,使用add_header()的方法,添加Headers。
User Agent设置好后,还应考虑一个问题,程序的运行速度快,如果利用爬虫程序从网站爬取东西,一个固定IP的访问频率远高于实际人为操作。所以一些网站会设置一个IP访问频率的阈值来判断是人还是程序在访问。因此,需要动态设置代理IP来规避访问频率的限制。
(2)特定API调用
通过调用API获取网站数据的方式较为简单直接,根据相关说明文档可以快速了解网站架构,便于规则的制定和代码的编写。但在调用过程中,网站会对调用的频率、次数进行限制,需要根据网站规定进行设置,如申请多个访问服务的依据(Key)或采用间歇性、适当休眠的模式进行访问。
以调用百度地图开放平台的WEB服务API(路线规划API v2.2.1)为例,分为3个步骤:① 申请密钥ak(类似于Key)作为访问服务的依据;② 拼写发送HTTP请求的URL,需使用上一步申请的ak;③ 接收HTTP请求返回的数据(JSON或XML格式),根据返回值说明解析数据。根据规定,未认证用户(一个普通ak)每日只可访问2 000次,每秒并发20次,认证用户每日可访问30 000次,每秒并发50次,因此,要想多次调用API需要申请多个ak进行访问。此外,还可以通过生成随机数作为等待时间,以达到降低访问频率的目的。
3.2.2 浏览器自动化
目前,不少网站在用户提交信息等登录和输入的页面上使用了验证码技术,其实现的方法一般是在页面上显示一幅图片,要求用户肉眼识别图片中的信息并将该信息作为输入的一部分进行提交。页面上显示的这幅图片一般是一串随机产生的数字或符号,并且被添加了用于防止识别的背景。验证码的主要目的是防止恶意用户利用自动工具(机器人)对用户口令进行暴力破解、恶意注册,或是向网站发布令人厌烦的广告信息等。但与此同时,该技术的使用使得网络爬虫面临了较大的困难。本文利用Selenium工具截取页面(Java环境),定位验证码元素位置,借助在线OCR服务,在百度AI中识别验证码图片中的文字,具体步骤如下。
(1)获取HTML标签元素
在WebDriver中定位元素可以在WebDriver实例本身或WebElement上完成[9]。每个语言绑定都会显示“查找元素”和“定位元素”方法。前者返回与查询匹配的WebElement对象,如果找不到这样的元素,则会抛出异常提示。后者返回WebElements的列表,如果没有DOM元素与查询匹配,则可能为空。“查找”方法采用名为“By”的定位器或查询对象。常见的定位方法主要有:按ID、按类名、按标签名称、按名称、通过链接文本、通过CSS、通过XPath、使用JavaScript和通过标签中的文本。例如,按ID定位是selenium定位方式中最有效、首选的方法,利用HTML元素上类的ID查找效率较高,示例代码如图5所示。具体还要根据实际情况进行组合使用。

图5 按ID定位
(2)模拟用户进行操作
在从互联网爬取数据时,除了获取网页上的数据,还有一个重要的步骤是模拟用户进行操作。比如刷新、前进、后退、文本输入、点击“搜索”按钮、勾选查询条件、下拉菜单等。例如,模拟“用户输入+填写表单”操作,WebDriver包含一个名为“Select”的支持类,它提供了处理SELECT元素有用的交互方法,示例代码如图6所示。

图6 模拟“用户输入+填写表单”操作
(3)访问频繁出现验证码
当进行频繁访问时,网站会出现验证码验证保护的情况,因此,通过Selenium截取页面传入百度AI进行识别。
(4)将截取的图片传到百度AI中进行识别
利用通用图像分析功能,POST方式请求服务,用于通用物体及场景识别,即对于输入的一张图片(可正常解码,且长宽比适宜),输出图片中的多个物体及场景标签,返回数据为JSON格式。
3.3 解析地理信息数据
将前文获取到的地理信息数据进行分类,对XML、HTML、JSON 3种格式的数据进行解析。
XML文件解析方法有DOM解析、SAX解析、JDOM解析、DOM4J解析4种。其中前2种属于基础方法,后2种属于扩展方法,是在基础方法上扩展出来的,只适用于Java平台。DOM4J是JDOM的一种智能分支,也是一个开放源码的文件,它合并了许多超出基本XML文档表示的功能,可处理XML、XPath和XSLT,性能优异、灵活性好、功能强大。
利用Beautiful Soup工具解析HTML文档,可将复杂文档转换成一个复杂的树形结构,从而更加快速、准确地获取标签的内容。每个节点都是Python对象,所有对象可以归纳为4种:Tag类、Beautiful Soup类、NavigableString类和Comment类。
JSON数据解析主要有2种思路,一是针对单一格式的JSON数据采用原生解析的方法;二是针对嵌套复杂的JSON数据采用第三方工具解析。JSON主要有以下3种基本类型:① “大括号{}”类型;② “中括号”类型;③ “组合{…}”型。通过遍历字符串中的字符,并根据特助字符,比如{},,:号等进行区分,{}是字典,表示的是数组,:号是字典的键和值的分水岭,最后是将JSON数据转化为字典,然后使用KVC将字典转为model。如果看到是{},使用JSONObject;如果看到的是,使用JSONArray解析。Gson是Google提供的用来在Java对象和JSON数据之间进行映射的Java类库。可以将一个JSON字符串转成一个Java对象,或者反过来。Gson提供了fromJson()和toJson()两个直接用于解析和生成的方法,前者实现反序列化,后者实现了序列化。通过获取JsonReader对象解析JSON数据,把JSON数据映射成一个对象,使用Gson对象的fromJson()方法获取一个对象数组进行操作。
3.4 数据整合
在获取数据并进行解析之后,面对后期不同应用需求,需要对数据进行整合,包括数据清洗、空间化、一致性处理等操作。
3.4.1 数据清洗
其核心内容是查漏、补缺、去重,对照数据要求,查找缺失属性值的数据,通过关联信息抓取的方式补充属性值,如果缺失的属性值是必要属性则补充打上标记。进行去重处理是检查是否存在重复的记录,删除重复的记录。
3.4.2 空间化
对通过互联网获取的XML、JSON、HTML数据进行解析,对有坐标的数据直接构建几何对象,对不包含坐标的数据,通过抓取关联信息获取相应坐标信息或者地名地址匹配等空间匹配方法的方式构建几何对象。对于有坐标的数据来说,根据坐标值对非空间数据直接空间化。例如,在EXCEL或CSV格式中存储了大量X、Y坐标,利用一个或多个2DPointAdder转换器,添加2维坐标点,可以是折线或构造多边形。
3.4.3 一致性处理
一致性处理包括属性一致性与空间一致性,根据实际需求,有针对性地将数据进行“重命名、复制、增加、删除”等操作。① 属性一致性:对照数据字典的要求,在编码、属性赋值等方面处理为符合要求的数据。如在获取链家(南京)官网数据的过程中,对“日期属性”进行格式转换和属性筛选。② 空间一致性:主要体现在几何类型和空间参考的一致性上。空间参考一致性主要针对坐标进行变换,为保证转换前后数据图层、要素一致,提高生产效率,先对数据进行接边检查,在进行坐标转换后,进行接边融合和重新分幅剪裁。
4 应用实例
根据上述技术路线及内容,本文开发了互联网房产数据整合工具(图7)。用户通过页面提交感兴趣的区域范围,系统自动爬取链家、房天下等互联网房产网中二手房信息,爬取完成后生成shapefile文件供用户下载。获取的房产信息可以为地理国情分析评价指标设置提供支撑,为分析城市住区规模时空特征与演化规律提供依据。

图7 房产数据整合工具
5 结 语
本文详细阐述了互联网地理信息获取的技术路线,将数据获取分为两种类型——网页型和API型,从设计获取规则、互联网信息获取、解析地理信息、数据整合4个方面阐述了如何根据需求设计相应爬取数据的路线,为地理国情监测提供数据方面的支持,有利于进一步开展时空大数据挖掘方面的研究。
