基于麒麟980芯片的安全帽佩戴检测系统设计*
2021-06-21李欣宁陈雪松李秀滢胡浩通陈星汉
李欣宁,陈雪松,李秀滢,胡浩通,陈星汉
(北京电子科技学院,北京100070)
在工程建设过程中,对于工人的人身安全保护始终是不容忽视的问题,安全帽的佩戴则是保护生命安全最基础的防线。但在实际施工过程中,由于工地占地庞大、内部结构复杂、人员流动量大,单纯依靠人力难以实现对施工现场工人佩戴安全帽情况的实时监控。
当前,随着嵌入式技术和人工智能(AI)技术的深度融合,端侧人工智能得到了广泛的发展,与人工智能相结合的智慧化监测系统应运而生。从前瞻产业研究院整理的数据[1]可以看出,“AI+安防”一直是现阶段人工智能的主要赋能领域。但是,以施工现场为核心区域的“AI+安防”却少之又少。
随着物联网技术的飞速发展,在为数不多的高端施工现场,也部署了安全帽佩戴检测设备。从整体上看,其监测模式一般有两种,一种是在工地门口与门禁系统相结合,对进入工地的人员进行正确佩戴安全帽的检查;另一种是通过工地的监控摄像头进行视频的录制,并将影像传送给后台的管理服务器进行视频处理,进而检查安全帽佩戴情况。
以上两种模式虽然能实现对特定施工现场佩戴安全帽情况的监测和报警,但对于临时搭建的工地来说成本较高,且不可避免地存在监控设备无法部署的死角。
针对上述情况,本文以端侧AI技术为依托,提出了一款与手机端相结合的安全帽佩戴检测应用系统。利用手机这个人人必备的无线端侧平台,协助施工现场的管理人员进行流动式、定点式、抽查式的安全帽佩戴监测工作。
1 相关技术基础
近年来,随着深度学习技术的突破,第三次人工智能的浪潮汹涌而来。现在,通过模拟大脑的神经网络结构,直接从案例和经验中就可以进行算法的学习[2]。结合着算力的芯片化,在智能终端上搭载AI技术,已成为业界共识。
1.1 麒麟980芯片与HiAI2.0平台
麒麟980芯片是华为第二代人工智能芯片,更加擅长处理视频、图像类的多媒体数据。
980芯片性能卓越,内含CPU(中央处理器单元)、GPU(图形处理器单元)和NPU(神经网络处理器单元)。其中,CPU采用ARM Cortex-A76架构,属于多核CPU,由包含了2个超大核、2个大核和4个小核(Cortex-A55)的三档能效架构组成。超大核用于处理急速任务,大核用于处理持续时间长的任务,小核则用于日常功能的使用。GPU采用ARM Mali-G76架构。在图像处理加速方面,麒麟980采用了自主研发的双ISP4.0技术,使得图像处理能力显著提升。NPU采用寒武纪1 M的人工智能芯片,可显著提升图像识别效率。麒麟980芯片内部具体结构如图1所示。
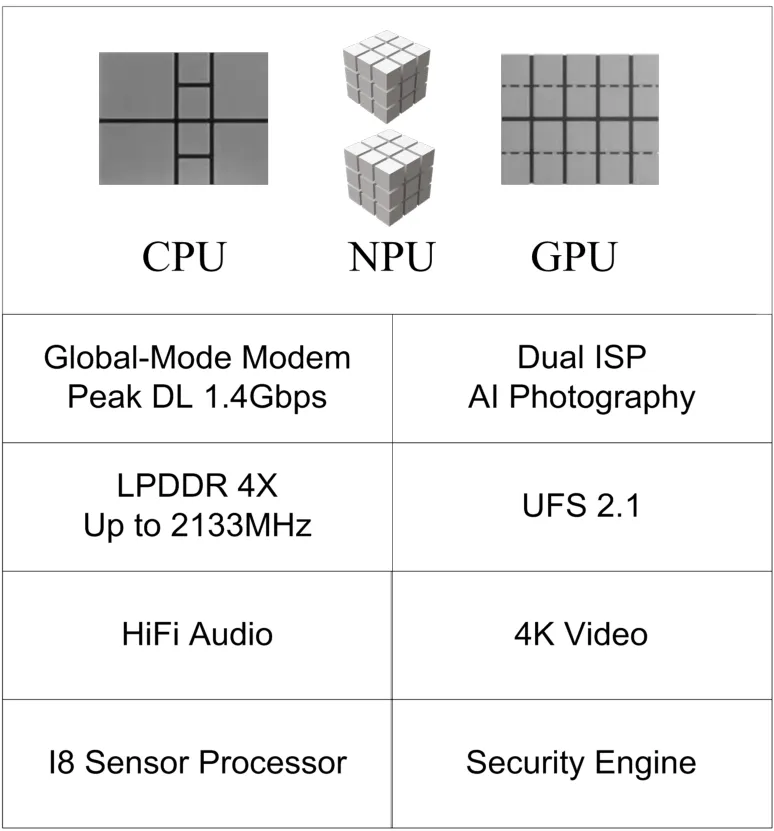
图1 麒麟980芯片结构
HiAI2.0是华为于2018年发布的人工智能开发引擎,包括了HiAI Foundation芯片能力、HiAI Engine应用能力和HiAIService服务能力。支持在麒麟980(及其以上版本)芯片上,为开发者提供开放的AI平台生态。
本设计使用HiAIFoundation提供的芯侧计算接口,能够借助麒麟980芯片中的双核NPU,提高图像识别能力,每分钟可识别4 500张图片。并且支持大量的AI开发模型和算子,让手机AI应用程序运行更快,体验更好[3]。
另外,本设计使用HiAIEngine提供的应用能力开放接口[4],借助其人脸检测模块检测图像中的人脸,返回结果中包含人脸特征点坐标、位置坐标和人脸数量等参数。该功能可作为关键模块,通过对人脸特征的提取、分析及位置的定位,广泛应用于各类涉及人脸识别的场景[5]。此模块已经被华为进行了封装和集成,开发者使用时需要去官网下载对应的开发包。
基于HiAI2.0引擎开发具有AI能力的安全帽佩戴检测系统,需要在华为DevEco Studio集成开发环境下设计实现软件,最后将应用系统(APP)部署到麒麟980芯片(或以上版本)的手机中[6]。使用时,APP会调用手机芯片中AI计算模块进行处理,底层会使用搭载的NPU加速运算,最终利用GPU加速显示输出结果。
1.2 MobileNetV2模型
华为HiAIFoundation提供的Model Creator功能,可为开发者提供图像分类、文本分类、表格分类、物体检测等迁移学习能力。通过训练深度学习模型,让应用者对图像、文本等进行精确识别。本课题的图像识别功能就是利用HiAI Foundation深度学习算法的良好泛化能力,针对大量图像数据进行分钟级的学习训练,自动生成安全帽佩戴图像分类识别的AI模型。本系统在图像分类时使用到的机器学习模型算法是深度级可分离卷积神经网络算法——MobileNetV2。
1.2.1 深度级可分离卷积神经网络
MobileNets网络结构的特点在于采用了深度级可分离卷积单元以达到模型压缩的目的,采用这种卷积方式可以减少参数数量、提升运算速度,是一种小巧而高效的卷积神经网络。
深度级可分离卷积算法是将标准卷积运算分成两步:Depthwise convolution和Pointwise convolution。Depthwise convolution与标准卷积运算的不同之处在于,标准卷积是将卷积核用在所有的输入通道上,而Depthwiseconvolution是针对每个输入通道采用不同的卷积核,也就是说一个卷积核对应一个输入通道。Pointwise convolution就是普通卷积,其采用1×1的卷积核[7]。
1.2.2 相比于MobileNetV1的优点
MobileNetV2模型与MobileNetV1相比,进行了两方面的改进:采用倒置残差结构和线性瓶颈[8]。两个模型简易对比如图2所示。

图2 MobileNetV2与MobileNetV1对比
从图2可以看出,算法模型使用了先“扩张”再“压缩”的方式,即倒置残差结构;将原有的ReLU激活函数(非线性),改为线性激活函数,即线性瓶颈。
倒置残差结构与MobileNetV1网络结构的不同在于添加了Expansion layer和 Projection layer[9]。Expansion layer的目的是将低维特征映射到高维空间,即维度扩展功能。本设计采用默认参数,即扩展6倍。Projection layer可以将高维特征映射到低维空间,即压缩功能,这样就形成了一个中间胖两头窄的纺锤形模型结构。MobileNetsV2网络结构可以满足各种图像识别的需求。先通过Expansion layer运算扩展特征维度,之后用深度可分离卷积算法提取特征,最后使用Projection layer运算来压缩数据,让网络重新变小。
在MobileNetV1中使用的ReLU激活函数是非线性的激活函数,当计算低维度数据时极有可能会使得激活空间坍塌,丢失信息,因此,MobileNetV2使用Linear bottlenecks线性变换函数替换了原本的非线性激活函数,以防止非线性方式破坏太多信息,同时又可以保证在低维度使用。
2 系统设计
本系统基于华为麒麟980芯片的HiAI 2.0平台开发,主体设计包括两部分:AI模型训练和应用软件(APP)设计。
2.1 AI模型训练
通过手机平台采集来的图像数据,要进行AI模型的图像识别和分类的处理。而AI模型应用之前需要做好两件事情:一方面是选择或构建合适的AI深度学习算法模型;另一方面是在指定数据集上进行算法模型的参数训练,以期AI模型具有超强的泛化识别能力。
2.1.1 数据集分析
训练所用到的数据集需要先进行图片分类,即打标签。这里需要在每个分类的目录下,放入大小合适的、对应类别的清晰图片。我们将收集来的图片先进行数据格式和大小的处理,然后分为戴安全帽(has_helmet)和不戴安全帽(no_helmet)两类,前者129张,后者103张,均为.jpg格式,数据集大小约为24 MB。
2.1.2 模型训练
利用HiAIFoundation中的“模型创建”功能来训练所需的AI模型。首先启动华为DevEco Studio,从以下路径Tools→EMUIKit→Kit Assistant,打开HiAIFoundation中的Model Creator功能,选择操作类型为Model Created。将分好类的训练集放入该模块中,设置好训练参数,选择输出模型的路径,点击Create Model开始训练模型。之后,该模块会利用迁移学习算法在基座分类模型MobileNetV2的基础上,进行安全帽图像分类模型的参数训练。模型训练完成后,可以查看模型学习的结果,主要为训练精度、验证精度、学习参数和训练数据等信息。最后放入测试集,进行训练模型的测试,以确定安全帽识别模型的应用效果。本系统的模型参数和测试结果如图3所示。
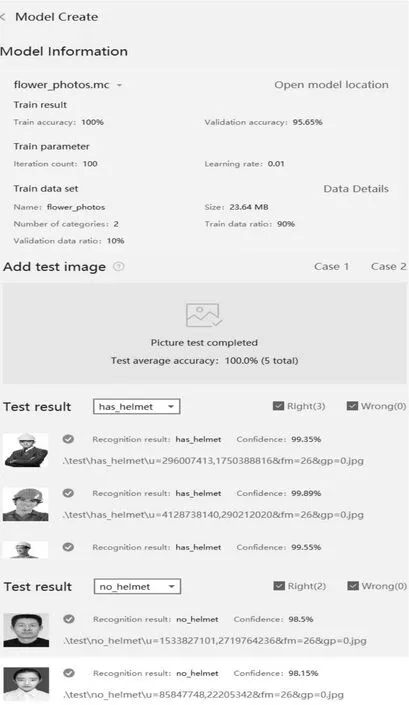
图3 模型参数和测试结果
由返回结果可知,模型的预测正确率达到了98%以上,精确度可以满足本设计的需求。
将训练好的模型生成API,为模型应用到系统作准备。在模型训练结果中点击“Generate API”,DevEco Studio开发工具就会将训练模型的依赖包、模型文件、API接口示例源文件自动添加到工程的相应目录中,并且在模块的“build.gradle”文件中自动增加依赖信息。之后可以通过调用图像分类识别模型对应的API接口,将图像分类识别的能力集成到APP中。
2.2 APP软件设计
2.2.1 系统的逻辑流程
APP的功能逻辑流程如图4所示。当用户采集图像后,系统先判断图像中是否存在人脸,如果不存在人脸,则输出“没有人脸(no get face)”;如果存在人脸,则先框出人脸,再判断图像中人脸是否佩戴安全帽,对应输出结果:“戴安全帽(has_helmet)”或“没戴安全帽(no_helmet)”,并显示结果准确率。

图4 APP的功能逻辑流程
2.2.2 系统的GUI界面布局
系统界面上设计了“SELECTAN IMAGE”和“TAKEA PHOTO”两个按钮,分别用于实现从图库中选择图像和拍照获取图像两种操作:一个图像显示框,用于显示采集或选取的图像;一个文本显示框,用于以文本形式显示检测结果,即说明是否有人脸、是否戴安全帽。APP的GUI布局如图5所示。
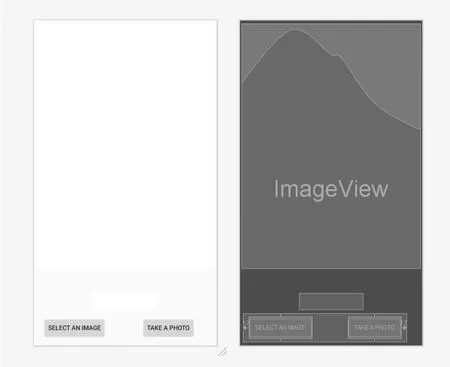
图5 APP的GUI布局
2.2.3 安全帽检测实现
参照华为官方发布的人脸检测开发指南和DevEco Studio使用指南,向开发工程文件中添加需要的软件依赖包,并通过调用HiAI的API接口函数和相关类函数,实现人脸检测和图像分类的功能。APP程序基本流程如图6所示。

图6 程序流程图
根据流程图,首先调用requestPermissions()函数进行权限申请,包括图库、相机的使用权限;获得权限后,按照华为HiAI的要求,将应用VisionBase静态类进行初始化,得到服务连接的结果,为之后调用人脸检测API做准备。
调用onActivityResult()函数获取图像,并将其转换成位图的形式保存在变量中;之后进入FaceDetectTask进程,调用人脸检测API,实现detect接口,使用检测算法获取结果。同时,使用ImageClassifierDetector类调用训练好的AI模型,执行模型预处理、申请CPU、模型装载、图像识别、模型卸载和释放CPU的功能,最后将检测结果返回。
最后,onTaskCompleted()函数会对结果进行处理和输出。当返回结果表明“没有人脸”时,会在界面下端的文本框中输出“not get face”。
当返回结果表明“有人脸”时,根据图像分类的结果,在GUI界面的文本框中输出“no_helmet”或“has_helmet”以及预测正确率,同时会用绿色矩形框框出图像中人脸的部分。
3 结果分析
3.1 系统运行测试
系统的运行效果如图7所示,会有3种输出结果,分别为“has_helmet+正确率”“no_helmet+正确率”和“not get face”。从图7中可以看到系统检测安全帽佩戴情况的3种输出结果的效果,系统能正确运行。
3.2 准确率测试
为了测试APP的准确率,这里选取8张戴安全帽与8张不戴安全帽的图片。测试结果如表1所示。
由测试结果的标签值可知,该APP能准确分辨出安全帽佩戴情况,预测正确率在90%以上。
经过大量测试研究,影响预测正确率的因素主要有以下3方面:①图像场景的复杂程度。场景越复杂,预测正确率越低,因此在较为简单的场景中能提高预测正确率。②图像中的人脸占比。图像中的人脸占比越大,预测正确率越高,因此采集图像时应尽可能提高人脸占比。③训练算法模型所用到的数据集大小。训练所用的数据集越大,预测正确率越高,因此在训练AI模型时应尽可能扩大数据集。

图7 系统运行结果
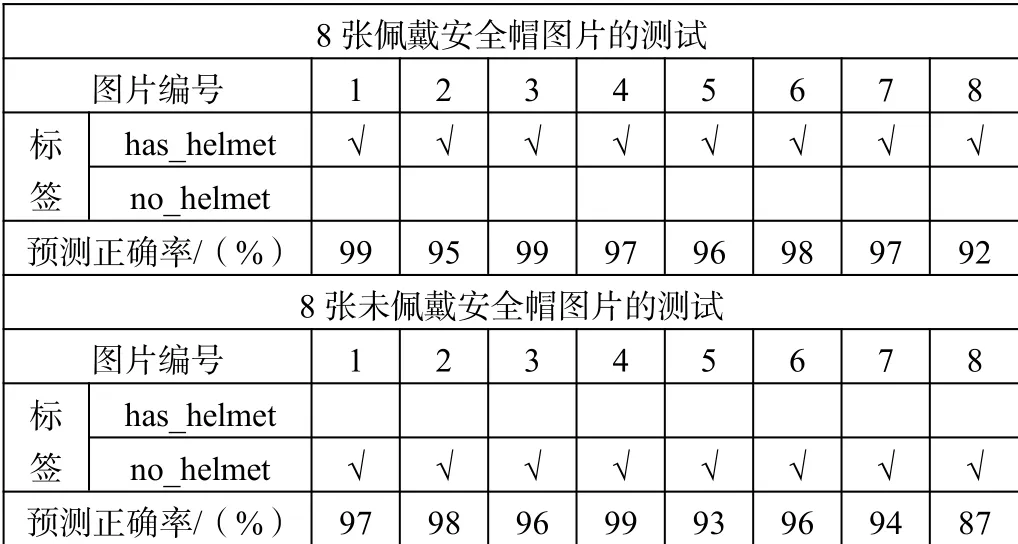
表1 正确率测试结果
4 结束语
本文介绍了基于麒麟980芯片的安全帽检测系统的设计实现方案。系统设计重点部分为:人脸检测模块与安全帽图像分类模块。人脸检测模块调用华为HiAI中的Huawei HiAIEngine接口实现。图像分类模块是利用DevEco Studio平台的迁移学习工具,训练生成图像分类模型,并封装成API接口实现。本系统充分利用了华为HiAI引擎和麒麟980芯片的优点,全面提升了检测速度和准确率。系统方案的实施成本低、可行性强,为解决临时工地中安全帽佩戴的监管问题提供了实用的解决方案。
