结合注意力机制与BIM特征的电力能耗预测
2021-06-21田英杰郭乃网徐东辉周向东施伯乐
田英杰 郭乃网 徐东辉 庞 悦 周向东 施伯乐
1(国网上海市电力公司电力科学研究院 上海 200437)2(复旦大学计算机科学技术学院 上海 200433)
0 引 言
随着中国经济的飞速发展和城市化的快速推进,社会对电力能源的需求日益增加[1]。为保障能源利用可持续发展,提高发电和配电效率,减少资源浪费,我国电网系统正向智能化电网发展[2-3]。智能化电网要求电力系统能够根据用户需求动态调整发电与分配方案。因此,准确预测未来电力能耗需求对智能电网的推动起至关重要的作用。
电力能耗预测属于时间序列预测问题,其主要预测方法是通过回归机器学习模型。无论是对基于统计学的传统模型还是深度神经网络,模型的输入特征对预测结果都有着决定性作用。劳伦斯伯克利国家实验室(LBNL)的研究[4]显示,引入与目标序列相关联的外因序列进行辅助预测将有效提升预测精度。但是在现实应用中,由于获取与耗电单位直接相关或显著相关的外界因素数据成本高、难度大,且同一时间戳往往记录了多种不同类型的时间序列数据,通过人工挑选和目标序列强相关的外界序列效率低、拓展性差,而直接将多序列作为特征输入则为目标序列引入噪声,使预测精度下降,导致多数用电能耗预测仅通过用电序列自身作为特征,根据目标序列自回归性做出预测,精度有限。因此,倘若模型能从相对容易获取的外界序列中自动挖掘序列间关系并用以辅助预测,将有助于提升目标序列预测精度。如图1所示,两条序列分别为某大型医院医疗设备I号与医疗设备II号,尽管两条序列在背景知识下无直接关联,但两条序列在部分区段存在明显的迟滞相关性。倘若模型可以对此加以识别并利用其相关性,将有助于提升预测精度。

图1 序列间存在隐含相关性
注意力机制(Attention Mechanism)[5]在深度学习中有着重要地位。在多序列预测问题中,通过注意力机制可以根据序列间相关性为目标序列自动选取相关性强的外因序列。因此准确刻画序列间相关性将决定注意力机制是否能正确对多序列选取。然而仅通过不同序列各自的数值信息无法描述各序列的真实背景,语义模糊,进而使注意力机制难以发挥作用。
建筑信息模型(Building Information Model,BIM)是建筑领域一种新兴的建筑设计技术[6]。BIM超越了传统的二维CAD技术,将信息的表达方式由二维转换为三维,记录了整个建筑从项目方案到建筑设计、施工的所有数据信息与特征。图2为BIM技术建模示例。BIM具有高度的集成性,贯穿在建筑项目的整个生命周期内为设施的所有决策提供可靠依据,支持不同利益相关方协同工作。由于BIM模型中包含丰富的数据特征,通过用电单位的BIM特征将完善用电单位对应时间序列的语义信息,使得不同时间序列间的数字化、离散化描述更加清晰、准确。

图2 BIM三维建模示例
针对以上问题和设想,本文提出BIMAttenNN模型,结合注意力机制与BIM特征的深度神经网络模型对多外因能耗序列进行预测,该模型具备自动选取外因序列能力。结合真实多序列电力能耗数据进行预测,实验表明BIMAttenNN模型提升了预测精度。
1 相关工作
电力能耗预测是时间序列预测问题。时间序列预测多年来一直是专家学者研究的热门领域。在众多预测模型中,最经典的是由Whittle[7]在1951年提出的自回归移动平均模型[8](Autoregressive moving average model,ARMA)及其变种自回归差分移动平均模型(Autoregressive Integrated Moving Average model,ARIMA)等基于统计学的传统模型。但是此类模型只能由时间序列的线性自回归做出预测,并且无法对多序列建模。循环神经网络(Recurrent Nerual Network,RNN)作为神经网络中序列模型的代表,由于其强大的非线性建模能力与灵活的建模方式[9],越来越受到人们的关注。Gao等[10]使用RNN模型对多序列问题建模,该模型可以自适应地学习复杂序列间的关系。而传统的RNN存在梯度消失的问题[11],为改善此问题,诸多带门控的RNN被提出,如Hochreiter等[12]提出的长短记忆网络(Long Short-term Memory Units,LSTM)和Cho等[13]提出的门控循环网络(Gated Recurrent Units,GRU)。此后研究多在LSTM或GRU的基础上建立。Gensler等[14]利用自编码器对时间序列进行特征抽取并结合LSTM进行预测。Yan等[15]利用卷积神经网络(CNN)和LSTM搭配的结构对电力能耗进行时间序列预测,用CNN选取特征,LSTM进行数值预测。Li[16]将编码-解码网络用于风能时间序列预测任务中,证明了编码-解码网络在时间序列预测问题中的价值。
注意力机制具备学习权重的能力,Bahdanau等[17]使用带注意力机制的编码-解码网络,令机器翻译效果获得大幅提升。Vaswani等[5]根据注意力机制强大的权重学习能力提出了Transfomer模型,在机器翻译领域大获成功。Song等[18]将Transformer结构应用于时间序列预测领域,验证了注意力机制和Trasfomer模型的价值。Qin等[19]提出了两步注意力模型,除了将注意力机制用在时间步选取外,还用于外因选择中,大幅提升目标序列预测精度。注意力机制的有效性为多序列学习任务提供了有效指导。
BIM对电力能耗的预测国内外已有一定研究。张先锋[1]通过BIM技术对建筑模型进行参数化,并通过小波神经网络对电力负荷预测,验证了BIM对能耗预测的可行性。Kim[20]将BIM特征与决策树结合,搭建了预测建筑能耗支出的模型。Alshibani等[21]利用BIM特征和多层感知机构建了电力支出预测模型。上述研究均直接建模了BIM与电力总能耗的关系,未利用BIM对耗电单位语义描述丰富的特点,因此本文结合注意力模型并使用BIM特征更加清晰地定义序列间相似度,进而提升预测精度。
2 模型设计
2.1 符号与问题定义
给定n个目标序列以外长度为T的耗电单位时间序列X(简称外因序列)以及长度同样为T的目标序列Y和总计n+1个耗电单位的BIM特征Z:
X=(x1,x2,…,xn)′=(x1,x2,…,xT)∈Rn×T
(1)
Y=yT=(y1,y2,…,yT)∈RT
(2)
Z=(z1,z2,…,zn+1)∈R(n+1)×q
(3)
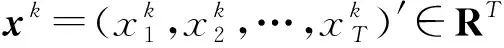
V=(v1,v2,…,vn+1)=(x1,x2,…,xn,y)∈R(n+1)×T
(4)
本文研究的问题为:给定全电力时间序列V的历史T个值和BIM特征Z,如何准确预测目标序列Y的下一时刻值yT+1:
(5)
式中:映射F(·)即为模型学习目标。
2.2 BIM特征选用
BIM特征建立在工业基础类(Industry Foundation Class,IFC)数据结构上,IFC结构定义复杂,容纳信息量庞大,通过建立类对象实例来描述具体的建筑信息[6]。IFC中的类根据集成关系分为资源层、核心层、共享层、领域层四个层次,每个层次中都使用EXPRESS语言建立了对应的类来描述对象。在IFC文件中将类实例化为对象来存储建筑信息。IFC层次结构如图3所示。

图3 IFC类层次结构
合理选用BIM特征对模型建立有重要意义。BIM特征可以分为IFC类结构信息与建筑描述信息。其中IFC类结构信息主要描述了IFC类之间的继承关系与类结构属性等;建筑描述信息则是面向BIM开发人员的建筑、建造单位的显式建造特征。由于显式特征的直接相关性,本文使用BIM特征中显式的建筑描述信息进行建模。以本文使用的数据集为例,选用的BIM特征描述见表1。

表1 BIM特征详情
其中,数值型特征将直接作为特征使用,类别特征使用独热编码[22]方式转化为向量形式,多个向量化的类别特征、实数特征拼接构成第k个序列的BIM特征向量zk,即zk=[b1,b2,…,b41,s]′,b1,b2,…,b41∈{0,1},s∈Z。不同数据集可以用同样的方法构造BIM特征向量。
2.3 模型建立
Qin等[19]在股价预测问题中使用两步注意力机制的结构,并验证了注意力机制对外因序列的选择作用。受此启发,本文采用两步注意力机制与编码器-解码器结构进行预测。此外,Lai等[23]指出,神经网络对时间序列建模可能会缺乏对时间序列的线性自回归部分建模。因此本文在模型中添加线性自回归预测分支以确保模型对线性映射部分的学习能力。模型由BIM-Attention编码器、解码器和自回归部分组成。整体结构如图4所示。

图4 模型整体结构
2.3.1 BIM-Attention编码器
在机器翻译领域,编码器本质上是对输入序列进行特征抽取,在每个时间步生成对应输入的编码向量。在本文研究的多变量时间序列问题中,因各外因序列与目标序列相关程度不明了,故编码器输入为全电力序列V=(v1,v2,…,vT),其中vt∈Rn+1,n是外因数目。编码器可以学习从vt到ht的映射关系:
ht=f(ht-1,vt)
(6)
式中:ht是输入序列在t时刻编码后的编码向量,ht∈Rm,m为编码长度;f(·)是编码器学习到的从输入向量到编码向量的映射关系,可以由RNN模型习得。由于LSTM具备克服梯度消失的能力,故本文使用LSTM作为编码单元。LSTM在每个时间步保持一个细胞状态和多个门控部分。其中细胞状态se,t用来记录长时间步中隐含的信息,遗忘门fe,t控制对历史信息的舍弃程度,更新门ue,t控制对候选细胞状态的更新程度,oe,t控制细胞状态ce,t多大程度转化为编码隐状态ht。具体计算如下:
fe,t=σ(We,f[ht-1;vt]+be,f)
(7)
ue,t=σ(We,u[ht-1;vt]+be,u)
(8)
oe,t=σ(We,o[ht-1;vt]+be,o)
(9)
(10)
(11)
ht=oe,t⊙tanh(se,t)
(12)
式中:[ht-1;vt]∈Rm+n+1是上一时间步ht-1和当前输入vt的拼接运算;We,f、We,u、We,o、We,s∈Rm×(m+n+1)和be,f、be,u、be,o、be,s∈Rm是模型学习的参数;σ和⊙分别代表逻辑斯蒂运算和逐元素相乘运算。
在编码阶段的LSTM部分前,使用BIM-Attention对输入的全电力序列重构,对重构后的序vt←BIM-Attention(vt)编码。注意力机制是学习分配权重的一种方法。本文利用BIM特征与各序列历史值计算目标序列对各外因序列的注意力分数,从而获得更加准确的权重向量。在t时刻对第k个外因序列的权重计算公式如下:
(13)
(14)


(15)
通过BIM-Attention编码器,模型利用BIM特征与序列历史值学习目序列与全序列的相关程度,从而使模型关注全序列中对目标序列预测真正有帮助的部分,进而达到自动选择外因序列的目的。
2.3.2 解码器
为生成未来时刻的预测值yT+1,用另外一支LSTM做解码器,对编码器的输出解码。并根据目标序列与外因序列间潜在的时间上的迟滞相关性,在每个解码时刻t,利用解码器LSTM的p维隐状态dt-1∈Rp对T个编码向量利用注意力机制进行权重计算,即:
(16)
(17)

(18)

(19)
(20)
(21)
(22)
(23)
dt=od,t⊙tanh(sd,t)
(24)

2.3.3 自回归部分
相关研究[23]表明,LSTM等神经网络模型在时间序列预测问题中,由于其强大的非线性建模能力,可能会造成模型对输入序列的线性自回归部分难以学习的问题。因此本文在模型最后的预测部分加入目标序列的线性自回归部分以克服这一缺陷。
在模型最终的预测部分,将目标序列的T个历史值Y=(y1,y2,…,yT)和解码器最终解码输出dT拼接,通过一层全连接网络生成预测值,即:
(25)

2.3.4 训练过程
模型训练方法采用小批量随机梯度下降,优化器为Adam。参数使用标准的反向传播学习,使用平均平方误差(Mean Squared Error,MSE)作为优化目标O,N是训练样本数:
(26)
3 实 验
3.1 实验数据
实验使用的数据集来自国家电网电力公司与华东建筑设计研究院。数据包含电力数据和BIM数据两部分,采集于中国上海市某大型医院。电力数据包含类别有医疗设备、电梯、照明插座、空调等13个类别,共415个不同的用电设备,每个设备的电力数据采样率为24点/天,共计一年,每条序列8 605个计数值。BIM数据为整座医院的BIM模型,包含了415个用电设备的各项BIM参数,实验中使用的BIM特征为设备所在楼层、设备类别、科室类别、所在楼宇类别。
3.2 实验设置
实验对比方法包括以下5种。
Lasso回归:经典的单变量线性自回归模型,输入为目标序列的历史序列。
LSTM:输入为目标序列的历史序列。
LSTM-Multi:与LSTM方法结构一致,但是模型输入为全部电力序列。
InputAtten:在LSTM-Multi输入前加入普通的注意力机制,输入为全部电力序列。
AttenNN:将BIMAttenNN中的BIM-Attention替换为普通的注意力模型,输入为全部电力序列。
本文方法的输入为全部电力序列。
对比实验中除不同模型的输入与模型结构不同外,其他参数均保持一致,如优化目标均为MSE,优化算法均为Adam,实验均用过去24小时的历史序列预测未来1小时的电力能耗值。实验中所有对比方法采用统一训练集、测试集,其中训练集占数据集比例为80%,BIM特征使用独热编码。
对比指标包括均方根误差RMSE,平均绝对误差MAE,计算公式分别如下:
(27)
(28)
3.3 实验结果
实验对比结果如表2所示,指标均在测试集上计算。

表2 对比实验预测精度
以综合楼2层检验科医疗设备为例,预测表现优秀的LSTM、AttenNN、BIMAttenNN方法在测试集前144点(一周步长)的预测效果如图5-图7所示。

图5 LSTM预测结果

图6 AttenNN预测结果

图7 BIMAttenNN预测结果
3.4 实验结果分析
表2的实验结果表明,本文提出的基于BIM与注意力机制的BIMAttenNN模型在各目标序列预测上均取得了最优表现,相较于不使用BIM特征,预测表现同样优秀的AttenNN在MAE指标上平均提升13.26%,RMSE指标上平均提升20.27%,验证了BIM对多序列融合预测的价值。
对比LSTM与LSTM-Multi模型的预测结果可以看出,对多序列建模时,倘若对多序列输入不添加任何选取机制,对所有外因序列一视同仁,则会为目标序列预测引入噪声,带来干扰。而InputAtten与LSTM-Multi和LSTM的实验对比说明,同为多外因序列输入的InputAtten和LSTM-Multi由于InputAtten加入了注意力机制对外因进行了一定程度的区分,其效果要优于LSTM-Multi,证明了注意力机制引入的必要性。但是由于InputAtten的单层结构,导致对目标序列自身信息关注不足,因此在精度上逊于单序列输入的LSTM。AttenNN则在InputAtten上改善这一缺陷,在解码阶段输入目标序列历史值,并且在最后加入目标序列的线性自回归部分,预测效果得到了改善。
BIMAttenNN与AttenNN模型差别在于AttenNN没有使用结合BIM特征的注意力机制。BIMAttenNN根据BIM特征清晰地定义了序列间关系,使输入序列的权重分配更加合理。从而获得了对比实验中最高预测精度。本文将两种方法中的注意力分数绘图,以直观的方式阐述结合BIM特征的注意力机制的价值。
绘图以综合楼二层检验科设备用电序列预测为例,外因序列有25条,预测任务是过去24小时预测未来1小时电力能耗,计算了测试集上1 716条测试数据对25条外因序列在24小时上的平均注意力分数并绘制分布图。AttenNN的注意力分数分布如图8所示;BIMAttenNN的注意力分数分布如图9所示。

图8 AttenNN注意力分数分布图

图9 BIMAttenNN注意力分数分布图
可以看出,AttenNN对外因序列输入虽然使用了注意力机制,但是普通的注意力机制对各外因无法有效计算对应的注意力分数,目标序列对各外因序列一视同仁。而BIMAttenNN则有效地结合BIM特征学习到了目标序列与外因序列之间的关联程度。图8中,BIM-Attention注意力分数较高的17~25号序列正是和目标序列同为同楼宇的检验科或者同一层的医疗设备,而相关性较低的1~16号序列则是同楼地下一层放射科设备或者其他楼的用电设备。
综上所述,本文提出的BIMAttenNN模型结合注意力机制与BIM特征对电力能耗序列建模预测合理且有效,并且提升了预测精度。
4 结 语
针对电力时间序列预测中多外因序列预测的问题,本文总结了现有方法的不足,提出了一种结合注意力机制与BIM特征的电力能耗预测方法。使用BIM特征与注意力机制对外因序列准确提取,通过编码器-解码器网络结构预测,并在模型中补充线性回归分支来弥补神经网络对时间序列线性部分建模能力不足的问题。实验结果表明,BIMAttenNN能结合注意力机制与BIM特征自动捕捉序列与序列间的关系,具备对输入外因自动选取的功能,相比于传统模型具有更高的预测精度。
