基于知识图谱的金融新闻个性化推荐算法
2021-06-18陶天一王清钦付聿炜
陶天一,王清钦,付聿炜,熊 贇,俞 枫,苑 博
(1.复旦大学计算机科学技术学院上海市数据科学重点实验室,上海 201203;2.国泰君安证券股份有限公司,上海 201201)
0 概述
在移动互联网时代,人们的阅读需求呈现出碎片化、多场景的特征,个性化新闻资讯推荐逐渐成为移动资讯行业的主流。面对信息爆炸的冲击,人们越来越习惯于浅阅读的阅读模式,即读者没有明确的阅读目标,更倾向于被动接受资讯推送。这些资讯对于整个读者群体而言是最为热门的,而对于读者个体而言并不总是能对应到他的兴趣,这也使得读者个体的阅读体验碎片化。因此,研究人员提出个性化新闻推荐算法[1-3],提供“千人千面”的资讯,有效解决用户碎片化阅读的问题。
知识图谱是由Google 公司于2012 年提出的一个具有语义处理能力与开放互联能力的知识库,以“实体-关系-实体”三元组(h,r,t)的形式表示事物间的关系,其中h、r和t分别代表一个三元组的头实体、关系和尾实体。研究人员发现,结合实体间的关系信息学习到的表示特征,在搜索引擎[4]、推荐系统[1]、关系挖掘[5]等问题中都取得了良好的效果。因此,知识表示学习得到了人们的广泛关注[1,4-6],其中,基于翻译机制的知识表示学习TransX 系列模型成为具有代表性的模型[7-9]。
为了将新闻处理为结合文本信息与金融行业知识图谱实体信息的向量表示,研究人员引入知识图谱与自然语言处理技术。一方面,在金融知识图谱的辅助下,从新闻文本识别出一系列实体,可以通过知识表示学习得到低维空间的向量表示。另一方面,将新闻文本本身的嵌入表示、新闻中识别到的实体表示、以及新闻中识别到的实体的上下文表示进行对齐,并利用基于词的卷积神经网络[10]、层次注意力机制[11-12]等方法,最终处理为目标向量表示。复杂类型的用户行为序列可以用来建模用户特征[13],并进一步被用于优化推荐算法的性能[14]。
目前已有研究人员提出结合知识图谱的推荐算法。文献[15]通过搜索数据和百科数据构建一个求职技能图谱,并提出一个基于知识图谱的面试问题推荐系统。文献[16-18]将用户和物品看作图中的节点来进行特征的学习,并最终用于推荐任务。但是,上述方法不能很好地适应资讯推荐场景下常见的冷启动问题等。
本文提出一种基于知识图谱的金融新闻个性化推荐算法。利用基于知识图谱的层次卷积神经网络提取新闻特征,并通过用户交易行为描绘用户特征,最终结合两方面特征,实现个性化金融新闻推荐。
1 问题定义
假设用户u的历史新闻点击行为记为,其中,是用户u点击的第i条新闻,Nu是用户u点击过的新闻数目。对于一条新闻,通过分词、去除停用词等处理转成一个词序列t=[w1,w2,…],而每个词wj可能对应知识图谱中的某一个实体e。例如句子“交通银行2018年第一季度利润增速放缓总体形势保持上升趋势”中的“交通银行”对应“中国交通银行”这一实体,对应在知识图谱中有“交通银行-所属行业-银行业”、“交通银行-股票概念-大蓝筹”和“交通银行-所属指数-沪深300”等关系。此外,结合用户的历史新闻点击行为、交易行为(如用户挂单和成交记录、用户自选股票、用户持仓股票)等数据,可以为每个用户生成一个特征表示向量。最终通过对以上信息的层次化建模,预测用户对于给定的未点击过的新闻及点击阅读的概率大小。
2 基于知识图谱的新闻个性化推荐
本节主要介绍KHA-CNN 算法模型。针对金融资讯即时性强、待推荐资讯多为冷启动资讯(即被阅读次数较少)的特点,在设计时摒弃了采用基于协同过滤的思路,使用基于内容的方法,从物品和用户两个角度分别去设计和建模。由于金融资讯中含有大量领域实体,结合金融领域知识图谱的知识提取能够使得物品侧的建模更为准确。此外,金融领域中存在大量用户和股票间的行为,可以将其用于用户侧的建模中。
2.1 KHA-CNN 模型框架
KHA-CNN模型由左、右两部分组成,如图1所示。
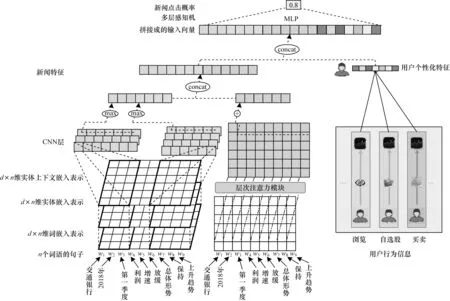
图1 KHA-CNN 模型整体框架Fig.1 Overall framework of KHA-CNN model
如图1左侧所示,对于一篇新闻,首先通过预训练的词向量得到其词嵌入表示,然后根据知识图谱提取其实体信息和实体上下文信息,随后采用卷积神经网络学习新闻中不同实体之间的关系作为最后新闻特征表示的知识特征,并且采用注意力模块关注重要的单词。如图1右侧所示,从历史新闻点击行为和交易行为(具体为持仓股票信息和自选股票信息两类)挖掘用户潜在的兴趣点,得到用户行为特征,最后利用新闻文本特征和用户行为特征,学习并预测用户对新闻的点击概率。
2.2 知识提取
对于每篇新闻首先根据金融知识图谱G 识别新闻中出现的各类实体,根据不同的关系ri构造其相关的实体e对应的上下文实体集合context(e):
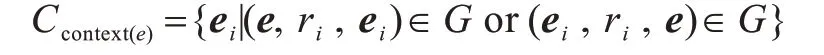
以“格力电器”为例,在知识图谱G 中考察与它有关的节点和关系:如“格力电器-所属概念-大消费”、“格力电器-上游供应商-信力科技”等关系,构造“格力电器”在G 中对应的上下文实体集合。“格力电器”在“上游供应商”关系下对应的上下文实体集合就是{“华英包装”、“信力科技”、“天意有福”}。对实体e在关系ri下对应的上下文实体集合context(e)中的所有实体特征向量取平均,作为其在这种关系下的特征表示:
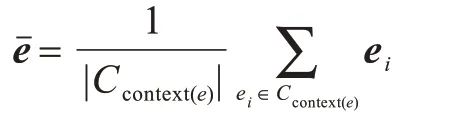
其中,ei是context(e)集合中的成员ei根据知识表示学习TransX 模型得到的相应实体特征向量。
TransX 是知识表示学习领域的代表性模型,包括TansR[5]、TransE[6]、TransH[7]和TransD[8]等。在TranX 模型中,对于每一个三元组(h,r,t)都有一组与之对应的d维向量表示(h,r,t∊Rd),且有近似关系h+r≈t成立[6]。定义三元组的损失函数为fr(h,t),正确的三元组关系对应的损失应较小[6]:
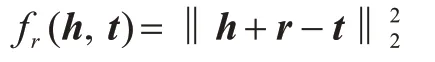
考虑到现实中头尾实体存在差异,在模型中采用TransD[8]模型分别将头实体和尾实体投影到两个独立的向量空间,然后再考虑三元组的损失函数。
为使模型能更准确地区分正确的三元组和错误的三元组,在训练时都采用带间距的损失函数[6-8]:

其中,γ是设定的间距参数,Δ、Δ′分别是正确的三元组(即存在于数据集中的三元组)的集合和错误的三元组(即数据集中不存在的三元组)的集合。
2.3 基于知识的卷积神经网络
对于一个由n个词组成的文本,首先通过预训练好的d维词向量,把n个词横向拼接起来得到文本的矩 阵表示x1:n∊Rd×n:
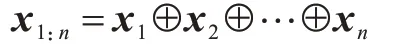
其中,xi∊Rn表示第i个词xi对应的d维词向量表示,⊕表示向量的横向拼接操作。在此基础上定义一个窗口大小为h的卷积核w∊Rd×h操作,通过学习h个相邻词的词向量得到输入文本的新特征表示[10]。例如通过卷积核w将xi:i+h-1这h个词对应的矩阵表示得到卷积操作后的特征ci:
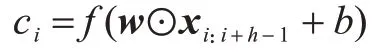
其中,b∊R 是偏置量,f是一个非线性激活函数,⊙是逐元素积。一个卷积核会作用在所有可能的窗口序列上{x1:h,x2:h+1,…,xn-h+1:n}来产生新的特征[10]:
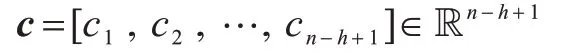
其中,[˙]表示由若干标量拼接而成的向量,进行池化操作[19]得到最大特征=max{c}作为这个卷积核的输出。
如图1 左侧所示的新闻标题“交通银行2018 年第一季度利润增速放缓总体形势保持上升趋势”,进行分词后查找预训练词向量得到词嵌入表示矩阵。分别用3 个窗口为3 的卷积核和4 个窗口为4 的卷积核在输入的词嵌入表示矩阵上进行卷积操作,通过池化得到7 维的向量表示,最后根据全连接层得到输入句子相应的新特征表示。
用w1:n=[w1,w2,…,wn]表示输入的原始新闻文本,w1:n∊Rd×n=w1⊕w2⊕…⊕wn为相应的词嵌入表示矩阵。经过2.2 节中所描述的知识提取操作后,在知识图谱G 中有对应实体的词wi对应着一个实体表示ei和一个实体上下文表示,而对于知识图谱G 中没出现的实体用零向量补全。此时,类似w1:n这一词嵌入表示矩阵,构造两个矩阵,即实体表示矩阵e1:n和实体上下文表示矩阵
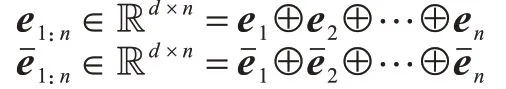
为利用金融知识图谱中实体的各种关系信息,首先对实体表示、实体上下文表示做一个线性变换g:g(e)=Me。如图1 左侧所示,最终组成的新闻特征表示为一个具有3 个维度的张量W∊R3×d×n:

与文献[10]卷积核直接作用在词嵌入表示上不同,KHA-CNN 同时将卷积核作用在实体表示以及实体上下文表示上,即卷积核k除了对应的d维宽度、h维长度外,还具有一个3 维的深度,即k∊R3×d×h。接着在卷积核kj的作用下进行卷积操作,得到每次卷积结果为:

通过一个时间上的最大池化,可以得到该卷积核作用下的最终特征:
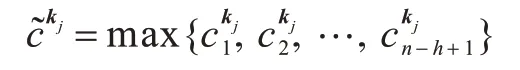
在m个卷积核的作用下,最终可以得到这条新闻的基于知识的特征表示:
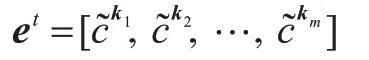
2.4 词级注意力模块
新闻标题是对新闻文本的概括性描述,对于用户是否点击该条新闻至关重要,为有效地学习标题的特征,本文采用词级注意力机制[20]对新闻特征进行处理。假设输入的新闻t的标题w1:n包括n个单词:
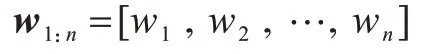
首先使用一个双向LSTM[21]作为输入词的编码器,然后输入词对应的词向量,得到编码器输出的隐状态表示:
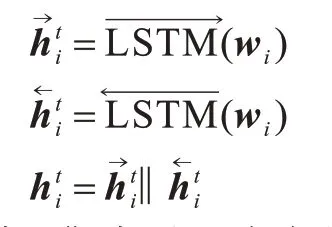
其中,‖表示两个向量拼接为一个向量。
得到每个词的隐状态后,根据上文所述的词级注意力机制聚合标题中每个单词的特征,得到标题的整体加权特征表示st:
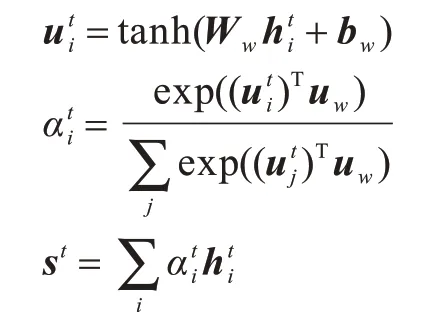
其中,uw是注意力机制中的权重向量,Ww是注意力机制中的线性变换参数矩阵,bw是该线性变换的偏置量,这3 个参数是模型中可学习的参数。
2.5 基于用户行为的特征学习
收集用户的“历史新闻点击数据”、“股票持仓数据”和“用户自选股票”作为用户行为数据。假设用户u拥有N只持仓股票信息,拥有M只自选股票信息,K条历史新闻点击数据,可分别表示成:
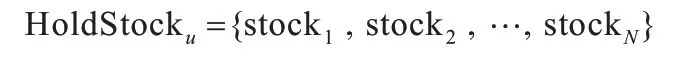

用户的个性化特征(F)表示成“股票持仓特征”和“历史新闻点击特征”的平均值:
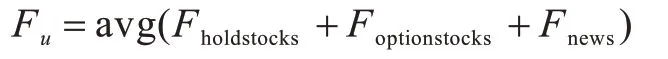
在用户持仓股票和用户自选股票特征中引入金融知识图谱:将股票作为每一个目标实体节点,把金融知识图谱中和目标节点相关的点(K-阶邻居)都作为它的上下文。如上文基于知识的卷积神经网络所述,学习融合目标节点相关邻居的特征信息来丰富目标节点特征:
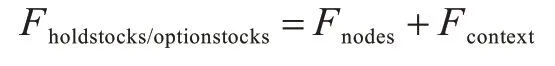
3 数据与实验分析
本节通过实验验证KHA-CNN 模型的有效性,分析讨论实验中的场景数据、相关的参数设置。
3.1 数据来源
KHA-CNN 使用的数据主要有金融知识图谱数据和用户行为相关的数据。金融知识图谱数据由国泰君安公司提供,而用户行为相关的数据来自于国泰君安的兼具资讯和投资功能的手机软件“君弘APP”,分为新闻数据、用户数据和埋点数据3 个方面,时间区间为2018年11月6日—2018年12月13日。其中,11 月6 日—12 月6 日数据作为训练数据,12 月7 日—12 月13 日的数据作为测试数据。基本信息如表1 所示。

表1 测试数据基本信息Table 1 Basic information of test data
3.2 新闻数据分析
通过新闻数据分析获取到新闻数据的ID、标题、摘要、文本内容及曝光时间等基本信息,新闻数据格式如图2所示。

图2 新闻数据格式示意图Fig.2 Schematic diagram of news data format
“时效性”是金融领域新闻的重要特征之一,用户一般只关心最新时刻发生的事件。如图3 所示,把新闻第一次与最后一次被点击的时间间隔作为新闻的生存周期,统计所有新闻生存周期。可以看出,多数新闻生命周期只有1 天,即只在新闻发布的当天被用户阅读,少量新闻生存周期为2 天~5 天,而生存周期大于5 天的新闻极少。
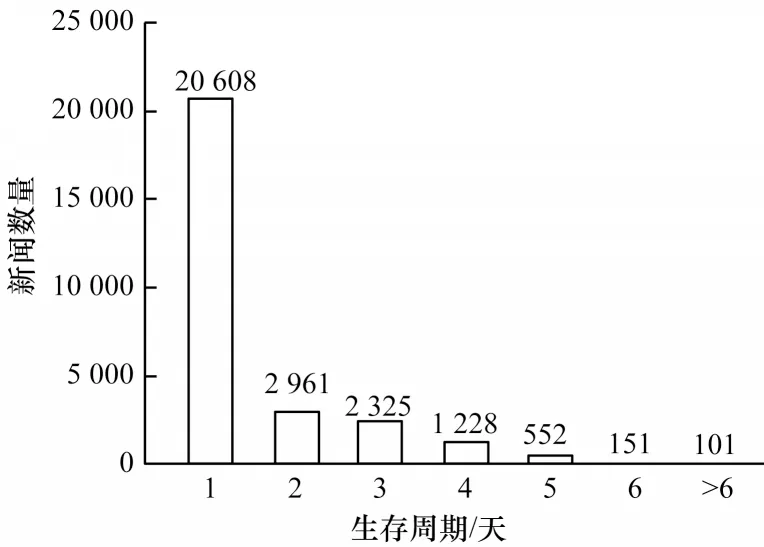
图3 新闻生存周期统计Fig.3 Statistics of news life cycle
3.3 埋点数据分析
用户新闻阅读行为来自APP 中新闻资讯页面埋点数据。模型所关心的主要为资讯曝光和资讯阅读两种埋点数据。资讯曝光表示资讯被推送到列表中,资讯阅读表示用户点击并阅读了该资讯。在模型训练时,曝光且阅读的资讯被认为是正样本,而曝光但未被阅读的资讯则被用作负样本。类似地,测试集中用于预测的正例也是曝光且阅读的资讯。由于埋点数据中90%以上的数据都是资讯曝光数据,远超资讯阅读的数量,为维持正负样本的平衡性,对于每个正样本,随机采样1 个负样本构造数据集。
3.4 用户数据分析
用户数据分析主要存在两类用户,即手机注册用户和资金账户用户,其中资金账户用户除新闻阅读行为外,还具有自选股票和持仓股票的数据。
训练集存在新闻阅读行为的有43 608 个资金账户用户和24 517 个手机注册用户,资金账户阅读数为3 983 447 个,手机注册用户交互阅读数为982 170 个,大部分新闻阅读交互记录来自于手机注册用户。
3.5 实验设置
本文采用的对比算法主要有如下4 种:
1)随机森林(Random Forest)[22]算法。该算法是一种基于分类树的集成方法,被广泛地应用于广告点击率(Click-Through Rate,CTR)预测及推荐中。在3.2 节、3.4 节数据分析的基础上,选择新闻ID、新闻标题、新闻首发时间、新闻曝光时间、新闻近1 天~2 天阅读数、用户ID、用户类型、用户近1 天~3 天阅读数、用户自选股特征和用户持仓股特征等作为模型的输入。
2)DKN[1]算法。该算法采用了知识图谱和CNN 来建模新闻特征,但没有用户行为特征。
3)ATRank-like 算法。该算法使用了用户行为特征,但未使用知识图谱,是针对金融新闻对ATRank 算法[13]的一个变种版本。因为新闻生存周期较短,用户较少重复点击同一新闻,所以将点击行为序列看作集合,不采用原算法中的时序编码。针对被点击新闻本身的特征,还增加了基于词嵌入表示的卷积神经网络以得到点击的新闻的特征表示。
4)KHA-CNN 算法。本文提出算法既使用了知识图谱,又考虑了用户的行为特征。
3.6 实验结果
不同算法的F1 及AUC 值如表2 所示。
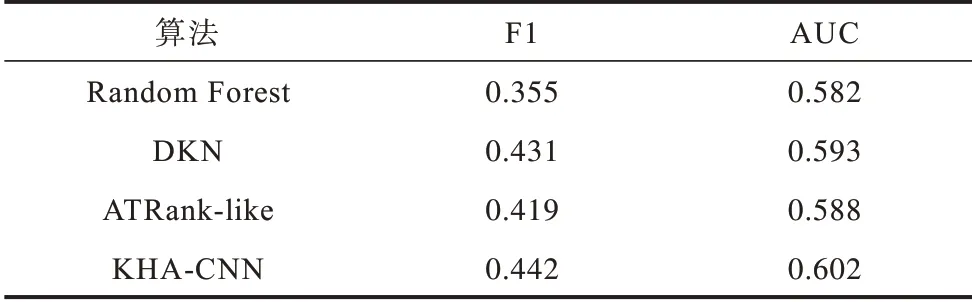
表2 KHA-CNN 及基准算法实验结果Table 2 Experimental results of KHA-CNN and benchmark algorithms
从表2 可以看出:
1)与Random Forest 算法相比,KHA-CNN 算法在F1 值和AUC 两个评价指标上都取得了更好的结果,且各变种算法也均能得到比Random Forest 算法更优的结果。这表明KHA-CNN 算法基于金融知识图谱,同时考虑了新闻的文本特征和用户行为特征,可以有效提升个性化推荐的性能。
2)与DKN 算法相比,KHA-CNN 算法取得了较优的结果,这表明基于用户行为数据用户画像能够提升新闻个性化推荐的性能。
3)与ATRank-like 算法相比,KHA-CNN 算法表现更好,进一步表明知识图谱在个性化推荐中的重要性。
3.7 参数比较
本文通过对比不同TransX 算法对KHA-CNN 性能的影响,具体使用的TranX 算法有TransE、TransH、TransR 与TransD 4 种。本文默认采用的TransX 算法为TransD,实验结果如表3 所示。
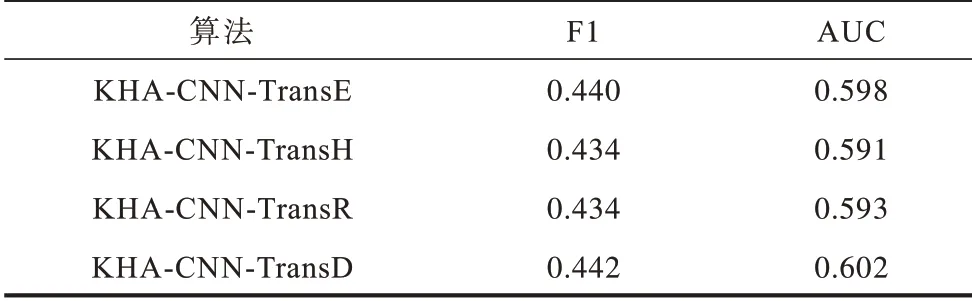
表3 不同TransX 算法识别实体时的实验结果Table 3 Experimental results when different TransX algorithms recognize entities
从表3 可以看出,算法基于TransD 的嵌入取得了最好的实验结果,因为该算法能够更好地捕获图谱中实体与实体间、实体与关系间的非线性关联。
3.8 消融实验分析
本文主要从CNN 维度和注意力机制两个方面进行实验。
1)CNN 维度的影响分析
考虑不同CNN 维度时的影响,主要包括:
(1)KHA-CNN-w/o-context-emb.,采用词语嵌入表示和实体嵌入表示,不采用实体上下文表示。
(2)KHA-CNN-w/o-entity-emb.,采用词语嵌入表示和实体上下文表示,不采用实体嵌入表示。在默认的KHA-CNN 中,词语嵌入表示、实体嵌入表示和实体上下文表示都被采用,实验结果如表4 所示。
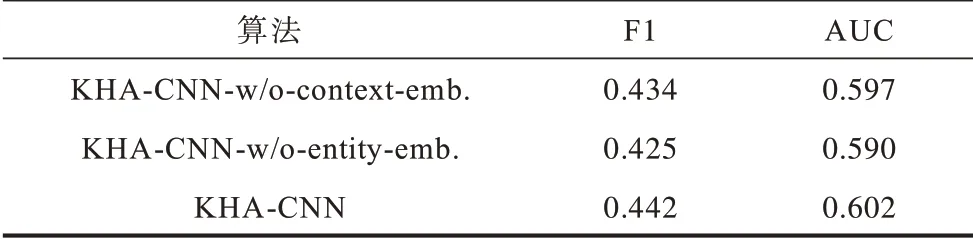
表4 不同CNN 维度识别实体时的实验结果Table 4 Experimental results when different CNN dimensions recognize entities
从表4 可以看出,在不使用实体上下文表示和不使用实体嵌入表示时,与KHA-CNN 相比,F1 值分别下降了1.8 个百分点、3.8 个百分点,这表明了在KHA-CNN 算法中使用基于知识的卷积神经网络引入知识图谱的有效性。
2)词级注意力机制的影响分析
不采用词级注意力机制时的变种算法为KHA-CNNw/o-attn.,实验结果如表5 所示。

表5 KHA-CNN 与KHA-CNN-w/o-attn.算法的实验结果Table 5 Experimental results of KHA-CNN and KHA-CNN-w/o-attn.algorithms
从表5 可以看出,与KHA-CNN-w/o-attn.算法相比,词级注意力机制的F1 值和AUC 值分别提高1.1 个百分点和0.9 个百分点。
4 结束语
本文提出一种基于知识图谱的金融新闻推荐算法KHA-CNN,通过知识表示学习得到知识图谱中实体的向量表示,并学习新闻上下文中实体的关系特征,使用层次注意力模型学习新闻标题中重要的上下文信息,同时通过用户的行为特征实现个性化的新闻推荐。实验结果表明,KHA-CNN 在F1 和AUC 这两项指标上都有较好的性能表现。
