图数据库中基于GPU 的图分析计算方法
2021-06-18钱裳云邵志远陈继林
钱裳云,邵志远,郑 然,陈继林
(1.华中科技大学计算机科学与技术学院,武汉 430074;2.华中科技大学服务计算技术与系统教育部重点实验室,武汉 430074;3.华中科技大学 集群与网格计算湖北省重点实验室,武汉 430074;4.中国电力科学研究院有限公司,北京 100192)
0 概述
随着大数据时代的到来,用于存储、管理和分析图数据的图数据库应运而生。相较于传统的关系型数据库,图数据库使用了新颖的数据建模和存储方法,可使检索和分析效率提高一个甚至多个数量级[1]。图数据库系统对外一般支持联机事务处理(On-Line Transaction Process,OLTP)和联机分析处理(On-Line Analytics Process,OLAP)两类应用。OLTP 强调对数据的增、删、改、查,包括对图数据库所存储的实体、实体属性、实体间的关联和图结构等进行改动,并实现持久化存储。OLAP 强调对数据库内的图数据进行分析计算,如佩奇排序(PageRank)、广度优先查找(Breadth-First Search,BFS)等经典图算法在全局图上的分析操作。
虽然图数据库系统能够实现对多属性图数据的存储、检索、更新和管理,支持数据的在线事务处理,但在对数据进行在线分析计算时,往往利用CPU 计算资源,采用基于分布式集群的GraphX[2]等软件工具实现。CPU 有限的计算核心使其更适用于密集型算法,而与图分析算法单指令多数据(Single Instruction Multiple Data,SIMD)[3]计算模式相悖。此外,使用传统图数据库系统进行分析时会对数据进行重复读取,从而消耗大量系统资源,导致较长的执行时间,同时集群间的同步也会导致额外的通信开销。图计算问题同样是大数据时代的主流研究问题。目前,较新的思路是设计并使用专用的加速器,如采用图形处理单元(Graphics Processing Unit,GPU)对图计算进行加速。然而,这类研究考虑的对象往往是简单图(即只考虑图数据的结构性数据,不考虑顶点与边数据的属性等信息),其只考虑计算本身的高效,脱离了具体的应用场景和应用本身的需求。从国内外发展现状来看,现有的技术(图数据库和图计算加速器)呈平行发展的趋势,缺乏两者之间的融合。
虽然现实世界的多属性图具有实体的属性多、数据总量大、数据关系复杂等特点,但对图数据进行的分析计算往往是基于实体的单个或几个属性进行。经研究发现,可以通过对数据的简单查询过滤将问题转换为简单图分析,从而避免对大量数据的反复随机读取。基于此,本文提出在传统的图数据库中融合GPU 图计算加速器的思想,利用GPU 设备在图计算上的高性能提升整体系统联机分析处理的效率。在工程实现上,通过融合分布式图数据库HugeGraph[4]和典型的GPU图计算加速器Gunrock[5],构建新型的图数据管理和计算系统RockGraph。该系统通过子图提取功能从图数据库中提取出用户所需数据,转换格式后,利用JNI 工具把数据传输到GPU 进行在线分析,最后将得到的结果写回图数据库并反馈给终端用户。
1 相关工作
1.1 图数据库系统
图数据库普遍采用属性图作为数据模型。令一张属性图表示为G,其由顶点集合V、顶点属性集P、顶点间的关系集合E(边的集合)和边的属性集W组成。可以用四元组将G定义为:

以社交网络图为例,顶点V代表用户,边E代表用户间的好友关系,点的属性P代表用户的个人信息(如昵称、性别、年龄等),边的属性W代表关系的具体信息(如成为好友的时间)。
图数据库系统实现了对联机事务图的持久化存储,对外一般支持联机事务处理(如图的增、删、改、查)和联机分析处理(如佩奇算法)。在底层存储中,部分图数据库采用原生图存储,针对图数据模型的特点设计了专用的栈,提高了可扩展性和其他一些性能;而另一部分则将图数据结构化和序列化,保存到通用存储后端中。在处理引擎方面,图数据库提供了查询接口和查询脚本语言来访问图数据库。
Neo4j[6]是一种具有代表性的单机环境下的高性能图数据库,包含了专用于数据库的组件,如图查询语言和可视化界面。Neo4j 通过交叉链表形式来存储图数据顶点、边和对应的属性,每个顶点都通过属性链表和关系链表将图数据的其他点、边和属性进行连接。然而,Neo4j 存在扩展性差、图数据分析效率低等问题[7]。HugeGraph 是一种分布式图数据库,其支持多种后端存储系统。该数据库实现了Apache Tinker Pop[8]框架,能够与以Hadoop[9]/Spark[10]为代表的工业级大数据相融合。HugeGraph 采用了Spark GraphX 的分布式图计算模型,由于该模型利用CPU 计算资源且存在集群间同步开销,因此图分析算法执行性能受限于分布式系统的通信性能。
1.2 基于加速部件的图计算引擎
由于图数据集的扩大和图计算不规则访问的特性,在传统处理器(CPU)上执行图计算无法取得较高的效率,因此使用专门设计的加速部件(如图形处理器GPU)进行图计算成为了研究的热点。GPU 采用单指令多数据流(SIMD)架构且拥有众多的计算单元ALU,因此,能够以极高的并行度执行图算法。
基于加速部件(GPU)的图计算引擎一般采用以顶点为中心的编程模型,由程序员定义顶点对应的执行函数,并在每个顶点上迭代运行,直到完成整个图计算过程[11]。此外,GPU 的并行计算框架主要分为大规模同步并行(Bulk-Synchronous Parallel,BSP)模型和GAS(Gather-Apply-Scatter)模型。在使用BSP模型的GPU 加速图计算系统中,大规模图数据往往被划分成多个分区,各图分区对应执行用户自定义的同一个核函数。在一个超步中,同一个核中的线程全部并行运行。在同一个核中,每个线程从上一个超步接收到消息后进行本地计算,并按需发送消息给对应顶点的邻接点。最后,执行屏障同步,完成超步间的同步。在采用BSP编程模型的GPU 图计算引擎中,具有代表性的有TOTEM[12]、Medusa[13]和GunRock。在GAS 模型中,顶点上的程序可分为3个阶段,即收集邻接点消息的Gather阶段、调用用户定义的应用函数的Apply 阶段和将顶点新值传递到邻接点的Scatter 阶段。目前,常见的采用GAS 并行模型的GPU 图计算引擎有MapGraph[14]、VertexAPI2[15]和Cusha[16]等。
2 RockGraph 系统设计
本节首先介绍图处理系统RockGraph 的整体架构,然后具体描述主要模块的基本框架和功能。
2.1 整体架构
RockGraph 系统架构如图1 所示。该系统采用图数据库与图计算系统相结合的架构,以传统的大数据系统HDFS[17]和列式数据库HBase[18]为存储层,通过Gremlin[19]语言进行图数据的存储与查询,使用新型加速部件GPU 完成大规模图计算。RockGraph 系统可划分为3 个主要模块,即图存储模块、远程数据读写模块和基于GPU 的图分析模块。
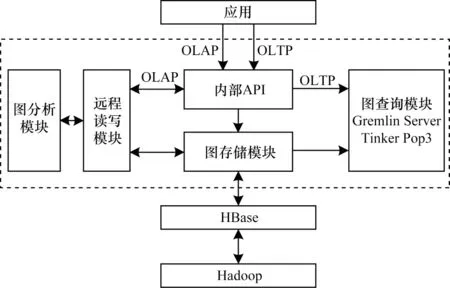
图1 RockGraph 系统架构Fig.1 Structure of RockGraph system
2.2 图数据存储模块
图数据存储模块的主要目标是实现图数据的高效存储,将图数据以多属性图的形式存储在图数据库中。该模块主要包含集群配置、数据处理、图模式创建和多线程数据导入等功能。在导入前判断数据库模式与索引是否建立,若已建立则进行图数据的导入,否则,先创建对应的图数据库模式与索引。为提高图处理系统的导入效率,RockGraph 利用多线程技术实现数据的增量导入。此外,为避免导入重复的顶点数据并减少导入前判断顶点是否存在的开销,本文采用“先导入点,后导入边”的方案。
2.3 图数据读写模块
图数据读写模块实现了对图数据库的远程读写功能,是RockGraph 系统中图数据库与图计算模块间的I/O 接口,为图分析模块提供服务。图数据读写模块具有子图提取和结果返回两大功能,其基本结构如图2 所示。在数据存储模块完成导入操作后,读写模块利用远程图数据库管理API 进行子图提取操作,完成后将子图文件提交给图计算模块。对子图的分析任务结束后,利用图数据读写模块的结果返回功能,将计算结果写回图数据库中。
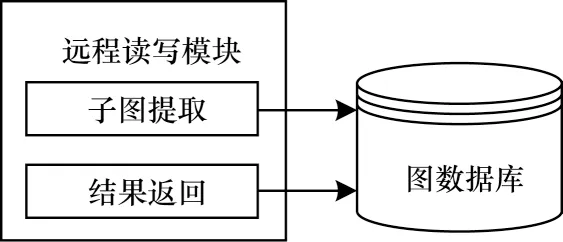
图2 图数据读写模块架构Fig.2 Structure of garph data read and writing module
在实现远程读数据时,用户感兴趣的往往不是完整的多属性大图,而是包含核心信息的子图,因此,如何将子图信息从庞大的图数据库中抽离出来便是远程读写模块面临的首要问题。本文在RockGraph 中添加了子图提取功能,根据用户需求提取核心子图并持久化保存在文本文件中。结果返回功能的实质是对图数据库的远程写入操作。得到图分析模块返回的结果数据后,根据结果文件中保留的数据信息在数据库模式中构建新的属性,将结果数据以属性的形式插入到图数据库中。最后,用户能够通过图数据系统中的Gremlin控制台实现对图计算结果的查询。
2.4 图数据分析模块
图数据分析模块是RockGraph 系统的重要组成部分,其实现了OLAP 分析功能。相较于利用分布式平台进行图分析的传统图处理系统,RockGraph将图分析任务交由加速部件GPU 处理。图数据分析模块架构如图3 所示,其中包括数据转换、JNI(Java Native Interface)管理和GPU 图计算框架三个部分。
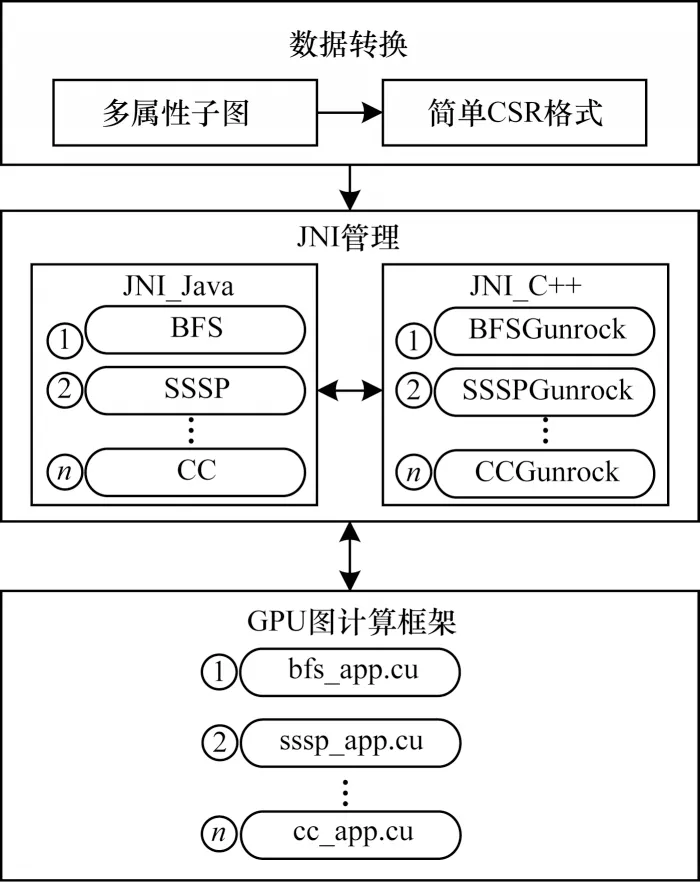
图3 图数据分析模块架构Fig.3 Structure of graph data analysis module
2.4.1 图数据预处理
在RockGraph 系统中,图数据分析模块将得到的子图信息转换成GPU 图计算引擎所需的压缩稀疏行(Compressed Sparse Row,CSR)格式。CSR 格式使用4 个一维数组存储邻接矩阵中的非零元素。其中:第1 个数组中存储的值代表对应下标号码的顶点的领接边在第3 个数组中的偏移量;第3 个数组根据第1 个数组的偏移量表示对应领接点;第2 个和第4 个数组分别代表图计算过程中顶点的属性值和边的权重。CSR 存储格式实现了紧凑的数据存储和常规内存访问。
2.4.2 JNI 管理模块
由于RockGraph 中对图数据库的交互操作使用Java 语言实现,而利用GPU 进行计算需要在Cuda 编程框架上进行,因此RockGraph 系统使用JNI 管理工具实现两者的衔接。首先,对基于Cuda 框架的GPU图计算引擎实现JNI 接口对应的函数,并编译生成为动态链接库。然后,利用JNI 管理工具将动态链接库导入到Java 模型中,以此完成Java 环境下对C 语言程序的调用。在读取数据时,Java 环境中的系统调用函数将数据从Java 堆传入内存中,以供GPU 图计算框架中的核函数使用。在写入数据时,先将GPU图计算得到的结果数据以数组的形式传输到Java 环境,再调用用户自定义函数完成进一步分析,最后通过图数据读写模块将结果写回图数据库中。
2.4.3 GPU 图计算框架
RockGraph 采用Gunrock 图计算引擎。然而,经由子图提取操作得到的图数据大小仍可能超过GPU 显存,因此,RockGraph 对Gunrock 图计算引擎进行扩展,使其支持超显存计算,超显存计算部分将在下文进行详细介绍。Gunrock 采用了以数据为中心的大规模同步并行(BSP)模型,并以CSR格式数据作为输入数据。在图计算框架中,RockGraph实现了Connected Component、Single Source Shortest Path 和BFS 等基本的图算法,因此,用户无需学习复杂的Cuda 编程技术,利用JNI管理模块即可调用所需的常见算法。
综上所述,在构建图计算加速器与图数据库相融的RockGraph 时,所面临的两个主要问题是提取用户感兴趣的核心数据和将超过显存大小的图数据传输到GPU 中进行图计算。因此,本文在RockGraph 中分别加入子图提取功能和超显存GPU 图计算框架。
3 子图提取
在RockGraph 系统中,远程读写模块的子图提取功能可删除冗余数据,同时提取并存储核心数据。下文将介绍子图提取的目的、优点和具体操作流程。
3.1 子图提取的目的与优点
在完成用户的图分析请求后,往往不需要对整张多属性图进行OLAP,而仅需要包含核心数据的子图,因此,本文在RockGraph 中加入子图提取功能。例如,对于某社交网络的人际关系图,教育部想分析标签为学生的用户间社交关系,利用子图提取功能便可得到属性为学生的顶点与其间的关系并组成新的子图,持久化存储后提交给图计算模块进行后续分析计算。如图4 所示,白色节点代表标签为学生的用户,黑色节点代表其他类型用户,连线代表用户间的好友关系。由于教育部对顶点的标签提出了筛选要求,子图提取操作便自动生成对应对Gremlin 语句。该语句能够实现对全图所有顶点和边的遍历,提取出所有标签为学生的点以及出点和入点均为学生的边,并组成新的子图。
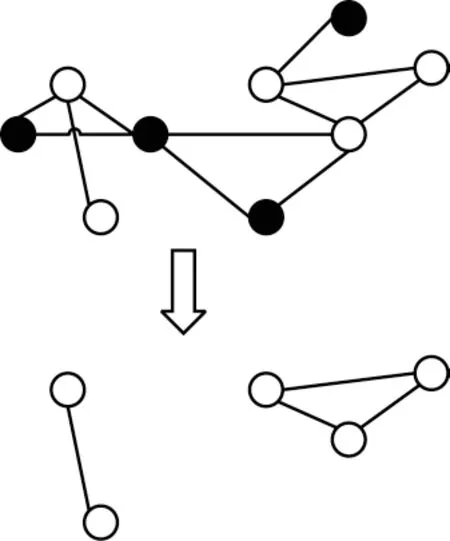
图4 子图提取示例Fig.4 Example of subgraph extraction
除了为用户提取感兴趣的信息,子图提取功能还能大幅减少后续图计算所需的数据量,使其满足GPU 有限的存储空间,提高系统计算效率。
3.2 操作流程
子图提取操作流程如图5 所示。首先根据用户需求检查子图名称列表,判断是否已生成过对应子图。若存在,则直接将相应子图导入到图分析模块;否则,将用户给出的条件信息转换为Gremlin 语言,调用远程读写接口,对图数据库中的顶点和边数据进行查询和筛选。然后将筛选后提取出的子图信息以边表的形式持久化存储在文本文件中。最后将包含核心信息的子图导入到图分析模块进行后续分析操作。
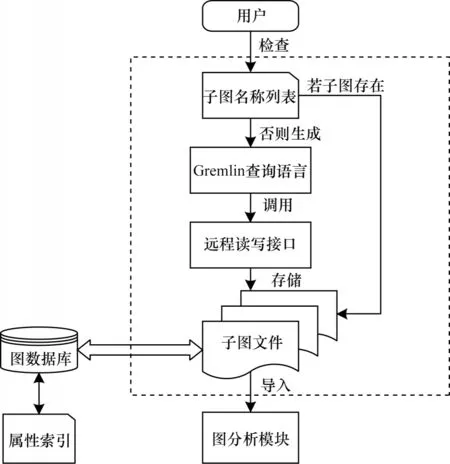
图5 子图提取操作流程Fig.5 Operation process of subgraph extraction
持久化存储子图信息使得对同一子图执行多次图分析算法时无需再次对图数据库进行子图提取操作,减少了冗余的全局遍历开销。此外,RockGraph 可根据用户需求在图数据库模式中为属性添加索引,从而提高子图提取时对全局图数据的遍历和查询速度。
4 超显存GPU 计算
由于GPU 中的存储空间有限,经过子图提取操作得到的核心数据仍可能超过GPU显存,因此RockGraph对图计算引擎Gunrock 进行扩展,使其支持超显存计算。RockGraph 实现超显存GPU 计算的基本思想是把无法完整存储到GPU 的大规模图数据划分为若干个适当大小的小图,再将小图依次循环从主存传输到GPU显存中执行图算法。每个小图都是大图通过一定的划分策略得到的分区,通过对一个分区的一次传输与处理组成一个超步,而对每个分区完成一次超步操作,组成对全图的一次迭代。通过多次迭代,直至所有分区收敛,最终完成图计算任务。
综上所述,RockGraph 实现超显存GPU 计算的过程可以分为两个阶段,即在CPU 端完成的分区阶段和由CPU-GPU 端协作完成传输并在GPU 完成计算任务的工作阶段。下文将详细阐释这两个阶段,并介绍分区动态调度的优化方法。
4.1 分区阶段
RockGraph 的超显存GPU 图计算引擎将数据分为3 种类型的数组,分别是拓扑数据(TD)、可读写属性数据(WA)和只读属性数据(RA)。例如,除了拓扑数据之外,PageRank 还要求顶点有两个属性数组,即代表前一个PageRank 值的只读属性数组(prevPR)和代表下一个PageRank 值的可读写属性数组(nextPR)。根据图计算引擎Gunrock 采用的CSR 格式图数据,拓扑数据对应CSR 格式中的行偏移量(row offset)和列索引(colume index)数组,以及属性数据对应点的属性值和边的权重数组,并由具体算法分为只读属性和可读写属性。
在分区阶段,CPU 端实现对拓扑数据和只读属性数据的分区划分,主要解决以下2 个问题:1)尽量减少预处理时间,从而减少最终端到端时间;2)划分成合适大小的分区,使得每个分区能够存储到显存中完成一次独立计算。因此,本文在RockGraph 系统中采用边分割和Range 分区法。本文使用一个简单例子说明该分区方案,如图6 所示。
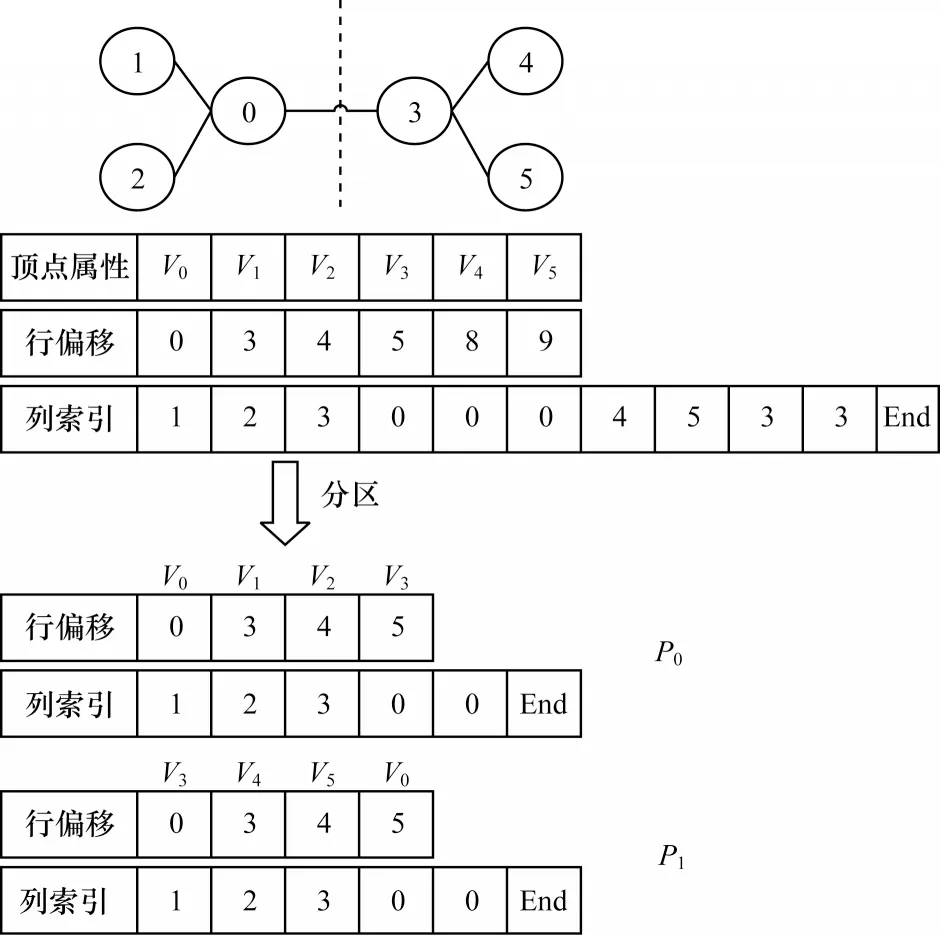
图6 分区方案示例Fig.6 Example of partition scheme
4.1.1 边切割
在CPU 端对拓扑结构数据进行分区时,RockGraph采用边切割的方法将顶点分为不相交的集合分别放入对应分区。边切割具有以下优点:
1)分割后对顶点的访问具有良好的空间位置。
2)易于将Gunrock 使用的CSR 格式数据进行划分,并得到CSR 格式的分区。
3)无需对分区内顶点进行重新编号,减少了预处理时间。
顶点的全局ID 与本地ID 的映射关系可以表示为:

其中,Pn代表分区编号,N代表分区内顶点数,Llocal_id和Gglobal_id分别代表局部和全局顶点号。
此外,用户也可以根据选择对分区内顶点进行重新编号,维护一个数组实现本地顶点号与全局顶点号的映射,从而灵活地选取分区方案。
4.1.2 Range 分区
Range 分区将图数据中的顶点根据编号分为若干个互不相交的区间。对于分区方案的选择,通常有减少预处理时间和减少邻接跨区点数目两个目标。Gunrock 图计算引擎通过顶点传递值,若多条跨界边指向同一个跨区点,则只需要传递一组关于跨区点的值。因此,性能提升的关键在于减少邻接跨区点的数目,而传统的图分区算法旨在减少跨界边数量,对RockGraph 系统性能提升不明显。因此,本文在系统中使用时空复杂度较小的Range 分区方法,从而减少最终端到端时间。
令GPU 显存空间为|GPU|,可读写属性数据大小为|WA|,为使每个分区都能在显存中完成一次独立计算,分区大小|Pn|应满足以下条件:

在GPU实现循环计算分区之初,将可读写数据WA从主机端拷贝到GPU,并在迭代图算法完成前在显存中实现属性数据的更新。因此,分区大小应当小于两者之差。此阶段的具体流程将在下文进行介绍。
4.2 工作流程
经过分区阶段的小图划分后,RockGraph 将分区循环传输到GPU 中执行图算法。超显存GPU 图计算工作流程如图7 所示,具体步骤如下:
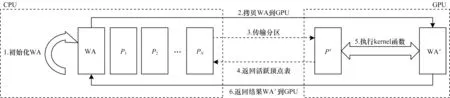
图7 超显存GPU 计算工作流程Fig.7 Workflow of out-of-memory GPU computation
步骤1在CPU 中对WA 进行初始化。
步骤2将全部顶点的可读写属性WA拷贝到GPU存储空间中。此后,WA 数据的更新操作均在显存中完成,这将减少每个分区将更新后数据写回CPU 内存的通信开销。由于现有的GPU 显存最高可达24 GB,可存储60 亿顶点的INT 类型属性值,因此完全满足现实世界图数据处理的需要。
步骤3使用动态调度法,根据活跃顶点表将活跃分区调入GPU 显存中。
步骤4调用Gunrock 计算引擎中的核函数,根据分区中的拓扑数据TD 和属性数据执行对应图算法,更新可读写属性WA,得到WA’。
步骤5根据步骤4 所得结果更新活跃顶点表。当一次迭代完成后,将新的活跃顶点表传输到主存中,并更新CPU 中对应的活跃顶点表。
若主机端检测到活跃分区,则重复步骤3~步骤5,将活跃分区循环传输到GPU 中进行计算。当检测不到任何活跃分区(即满足所有分区收敛)时,将顶点属性数据拷贝回CPU 主存中,得到最终结果。
4.3 动态调度
对于某些算法,一次迭代过程中只有部分点需要进行更新计算(如BFS 算法,每次迭代开始时只需要计算上次迭代中访问到的邻接点)。本文将本次迭代计算开始时所需要的点称为活跃顶点,将包含有活跃顶点的分区称为活跃分区。如果采用固定的调度顺序,每次迭代都将全部分区依次传输到GPU中,使得不活跃的分区也调入GPU,会造成多余的通信和计算开销。因此,RockGraph 采用动态调度策略,通过维护一个布尔类型的数组跟踪活跃顶点,每次迭代只向GPU 传输含有活跃顶点的活跃分区。
图8 展示了使用一个布尔数组判断活跃顶点和活跃分区的方法。该数组的大小为全图顶点数,活跃顶点的对应值置为1,否则为0。若分区含有活跃顶点,则该分区对应值为1,记为活跃分区。在每次向GPU 调入分区前,先检查CPU 端的活跃点数组,依次将活跃分区传输到GPU 执行图算法。对分区的计算完成后,更新GPU 中的活跃点数组。当一次迭代完成后,将新的布尔数组传输回CPU,更新CPU端活跃顶点表,并准备下一次迭代的分区传输。
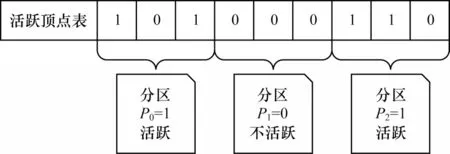
图8 活跃顶点表Fig.8 Table of active vertices
5 实验与结果分析
5.1 实验环境
在本实验中,RockGraph 和对比系统GraphX 部署在3 台服务器组成的集群系统中。每台服务器配备8 核Intel i7 处理器,内存为256 GB,磁盘空间为3 TB,操作系统为Ubuntu14。此外,RockGraph 使用GPU 作为图计算加速器,型号为Tesla-P100,显存为16 GB,Cuda 版本为10.0。
实验选取4 组公开数据集和2 组人工生成的随机数据集,以分布式计算框架GraphX 为对比,对广度优先算法(BFS)[20]、单源最短路径算法(SSSP)[21]和联通区间算法(CC)[22]这三种常用的图算法进行分析。
数据集的基本信息如表1 所示,其中,4 组公开数据集(WikiTalk、Topcat、Pokec 和LiveJournal)来源于真实世界社交网络,尺寸均小于显存,而两组随机数据集(RMAT1 和RMAT2)的规模则超出了显存容量,RockGraph 需要采用超显存GPU 计算框。本文使用以上两类数据分别分析图数据库中GPU 对图计算性能的影响和超显存GPU 计算框架的性能。

表1 数据集基本信息Table 1 Basic information of datasets
5.2 GPU 对图计算性能的影响
如图9~图11 所示,RockGraph 中3 种图算法的平均执行时间都大幅低于GraphX,性能平均提升了约5 倍。这是因为RockGraph 采用的图计算加速器GPU 拥有众多计算单元,且采用SIMD 计算模式,相较于仅使用3 台服务器上CPU 的GraphX 并行度更高,更适合对迭代算法的计算,因此其在执行3 种常见的图算法时,性能提升非常明显。同时,随着数据集规模的增长,GraphX 的执行时间急剧增长,而RockGraph 呈线性增长。数据集规模的扩大导致GraphX 集群间通信开销增大。此外,集群系统的并行度依旧维持相对较低的水平,数据集的扩大使得算法的串行执行时间也大幅增加。所以,GraphX 的执行时间随数据集规模扩大而大幅增加。然而,当数据集足够容纳进显存时,利用GPU 进行图计算没有分区划分与传输时间。同时,由于GPU 并行度更高,数据集规模的扩大对执行时间的影响较小。因此,数据规模越大,GPU 加速图计算的效果越明显。
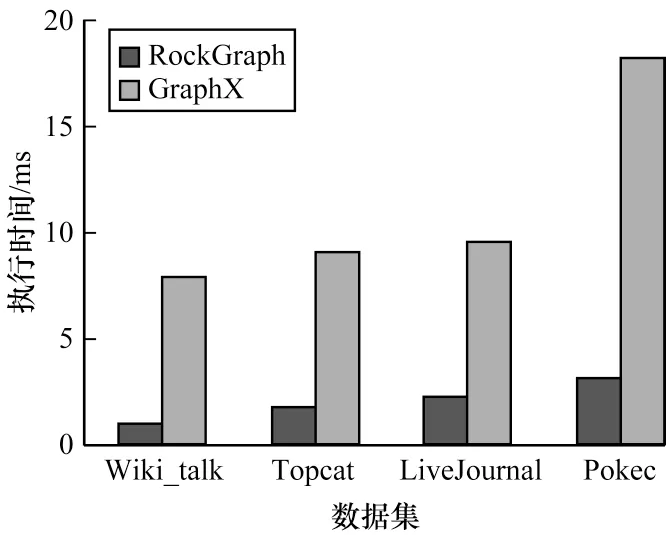
图9 BFS 算法执行时间Fig.9 Runtime of BFS algorithm

图10 SSSP 算法执行时间Fig.10 Runtime of SSSP algorithm
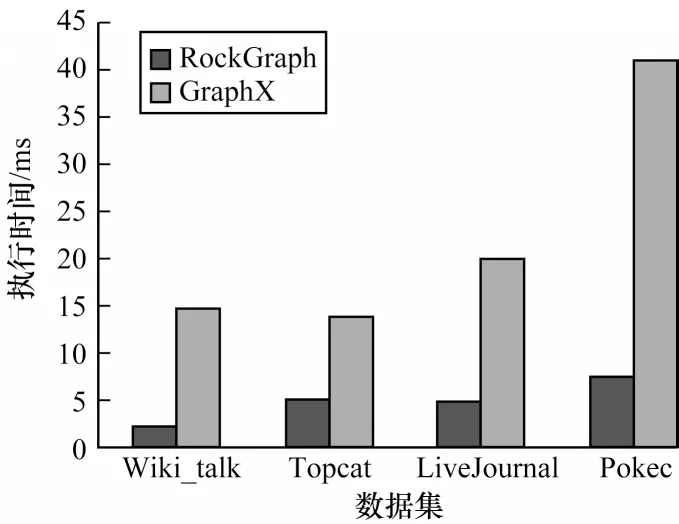
图11 CC 算法执行时间Fig.11 Runtime of CC algorithm
5.3 超显存GPU 计算框架性能分析
当数据集规模扩大到无法存储到显存中时,RockGraph 采用超显存GPU 计算框架,将数据划分为若干个分区后,依次循环传输到GPU 中执行图算法。因此,RockGraph 执行时间中增加了分区划分和传输时间,并且数据集越大,分区数量越多,导致分区划分时间增加,同时,完成一次迭代所需的传输时间占比也相应增加。
如图12~图14 所示,对于不同算法,GraphX 的执行时间约为RockGraph 的3 倍~5 倍。RockGraph图计算性能虽然仍高于GraphX,但相较于计算无需采用超显存的数据集时,提升幅度明显下降。同时还可以看出,RockGraph 对BFS 和SSSP 算法性能提升比CC 算法更加明显,这是由于BFS 和SSSP 算法每次迭代时无需所有顶点进行计算,因此可以使用动态分区调度策略进行优化,减少每次迭代过程中需要传输和计算的分区,从而减少执行时间。
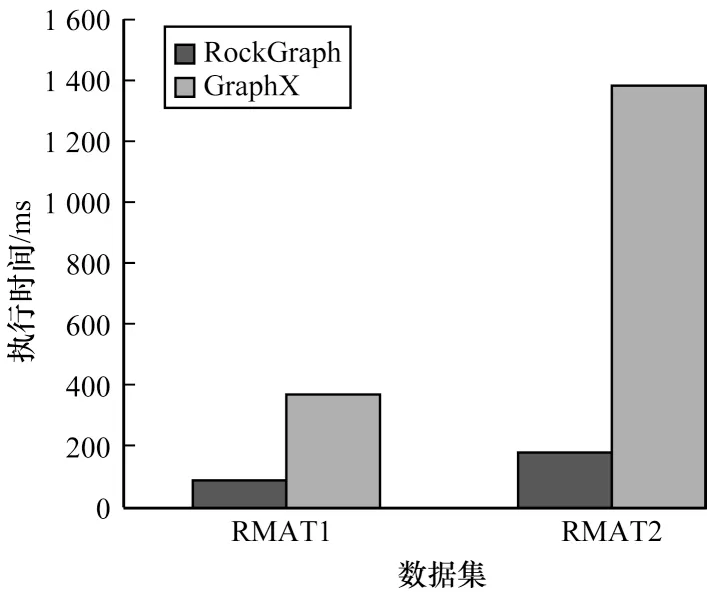
图12 BFS 算法执行时间(使用超显存计算)Fig.12 Runtime of BFS algorithm(using out-of-memory computation)
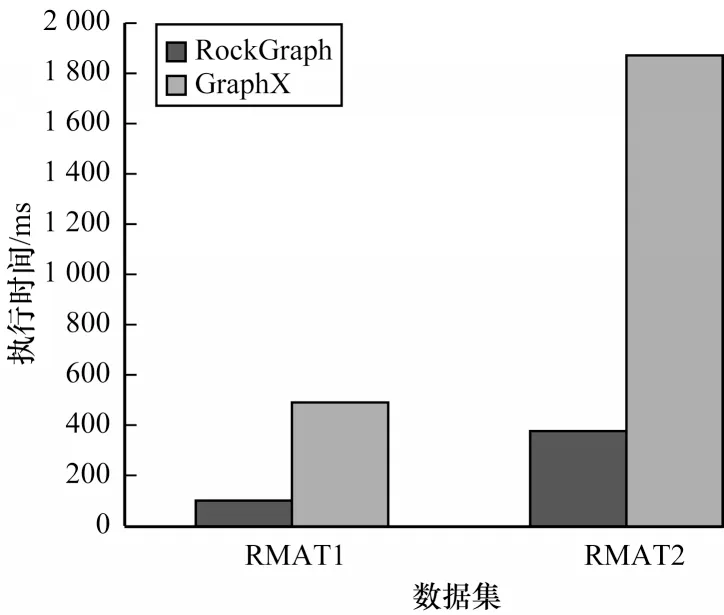
图13 SSSP 算法执行时间(使用超显存计算)Fig.13 Runtime of SSSP algorihm(using out-of-memory computation)
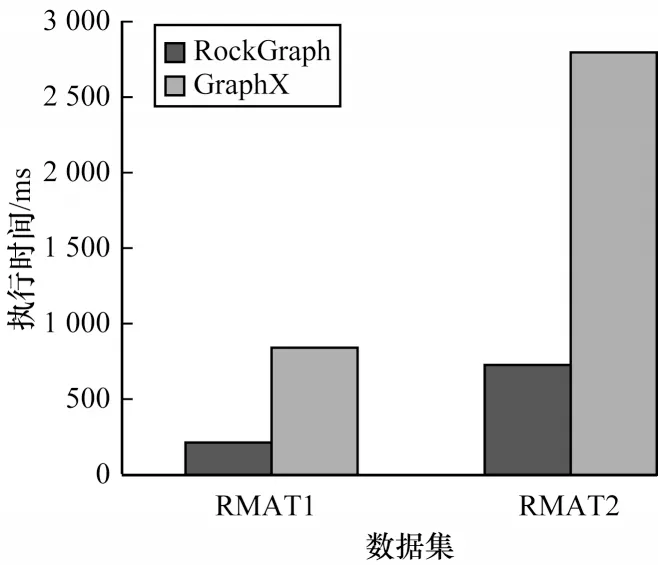
图14 CC 算法执行时间(使用超显存计算)Fig.14 Runtime of CC algorithm(using out-of-memory computation)
上述实验结果表明,在普遍情况下,无论是否采用超显存计算框架,GPU 都能大幅提高图数据库的图分析算法速度。
6 结束语
为提高图数据在线分析性能,本文设计并实现了利用GPU 加速图计算的图数据库系统RockGraph。该系统配置子图提取功能,能够从图数据库中提取出用户感兴趣的核心信息,从而减少计算量。在对提取出的数据进行格式转换后,其利用JNI工具将数据传输到GPU,并采用超显存图计算框架进行在线分析,最后把得到的分析结果写回图数据库中。实验结果表明,相较于传统图数据库系统采用的计算引擎GraphX,基于GPU 进行图计算的RockGraph 速度大幅提升。下一步将利用异步多流方式提高超显存GPU 的计算性能。
