图计算中遍历类图框架的特性
2021-06-18邓军勇赵一迪
邓军勇,赵一迪
(西安邮电大学 电子工程学院,陕西 西安 710121)
大数据背景下,真实世界图数据的规模爆炸式增长,处理图数据的图计算被认为是新兴数据驱动市场的支撑技术[1-3]。与此同时,随着社交网络分析、生物信息网络分析、传染病防治和自然语言处理等应用领域的发展,不同领域图计算应用的实际需求以及大量图数据的独特特征都对传统计算架构提出了挑战,高性能图计算加速器研发备受关注[4-7]。
为了高效实现图计算任务,研究人员开始设计并实现各种框架来促进应用的程序开发,并通过硬件设计提高图计算加速器的性能[8-10]。图框架Ligra[11]可以根据图的疏密情况自适应地切换其计算方法,但是其适用于单机计算,计算能力和内存空间有限。图框架Gemini[12]是以计算为中心的图框架体系,对整体集群图数据处理性能比较显著。图框架GraphBIG[13]利用动态的以顶点为中心的数据表示形式,基于当前主流图框架并涵盖了所有主要图计算类型和数据源。这些主流的图框架从不同角度对算法的实现进行了优化。遍历类应用作为图计算中常见的算法应用非常广泛,是图数据路径/流分析、网络理论以及网络通信重要性等许多实际问题的处理基础[14-15]。目前,没有适用的准则判断遍历类算法处理、图框架的设计和性能之间的关联关系,研究并获得相关特定算法在各种不同实现方式下的性能的详细信息和数据至关重要[16]。
拟通过对当前主流的图计算框架Ligra、Gemini和GraphBIG中遍历类应用的单源最短路径算法(Single Source Shortest Path,SSSP)算法和介数中心性(Betweenness Centrality,BC)算法的实现进行特性分析,分析各个图框架在处理不同数据集时的每一时钟周期内执行的指令数(Instruction Per Clock,IPC)、数据移动量(datamovement)、计算量(compute)功耗(energy)和各级cache每千条指令的平均未命中数(Misses Per Kilo Instructions,MPKI)等性能指标,并通过Pearson相关系数分析性能/能耗与各个评估指标之间的关系,据此对图计算框架及算法选择提出建议。
1 图框架及算法介绍
1.1 典型图计算框架
1)Ligra框架。Ligra框架是一种经典的单机内存图计算系统,其根据图的疏密情况自适应地切换其计算模式的方法,并提供了一种基于边映射、顶点映射以及顶点集映射的并行编程算法,可以通过调用两个原语分别对所有活动顶点和所有活动顶点的出边进行处理,使图遍历算法易于编写。Ligra框架的图计算单机运行,可以直接将图数据完全加载到内存中进行图计算操作。但是,由于单机的计算能力和内存空间有限,所以该框架只能计算和处理一些规模较小的图数据。
2)Gemini框架。Gemini框架是一种以计算为中心的图框架体系,其在单机内存图计算系统的高效性和分布式内存图计算系统良好的伸缩性之间找到一种平衡[6]。Gemini框架针对图框架的稀疏或稠密情况,采用与Ligra图框架一致的自适应推/拉处理方式,在内存中采用基于Chunk的图划分操作,进行更细粒度的负载均衡调节。Gemini框架对整体集群的图数据处理性能的改善较为显著。
3)GraphBIG框架。GraphBIG框架是一组CPU/GPU基准测试,其利用动态的以顶点为中心的数据表示形式,采用当前主流图框架并涵盖所有主要图计算类型和数据源,以确保数据表示和图计算负载的代表性,改善之前基准测试工作的不足,并实现通用的基准测试解决方案。
1.2 基本遍历类算法
1)SSSP算法。SSSP算法是一种计算从源顶点到所有其余顶点的路径上边权值之和的最小值的算法[17-18],广泛应用于网络理论、地图路径查询和线路安排等实际生产和生活中[19]。SSSP算法使用松弛算子函数寻找最短路径,直到找不到更短的路径为止。松弛算子函数的表示式为
D(v)=min[D(v),D(u)+w(u,v)]
(1)
其中:u表示源顶点;v表示顶点u的邻居顶点;w(u,v)表示顶点u到顶点v的边缘的权重。
2)BC算法。BC算法中的介数中心性指的是一个顶点担任其他两个顶点之间最短路径的桥梁的次数[20-21],一个顶点充当“中介”的次数越高,该顶点的中介中心度就越大[21]。BC算法能够揭示网络结构中具有桥连接作用的顶点,从而控制整个网络结构的连接以及通信能力,找到网络传播过程中的最关键点或者最脆弱点。BC算法在网络研究以及传染病防治等领域得到广泛应用。BC算法计算网络中任意两个顶点的所有最短路径,如果这些最短路径中有多条都经过了某个顶点,那么这个顶点介数中心性较高,顶点x的BC值计算表达式为
(2)
其中:σst表示顶点s和t之间的所有最短路径数;σst(x)表示经过顶点x的最短路径数。
2 实验环境建立与性能指标
2.1 硬件平台
性能分析在基于Skylake架构的4核8线程Intel(R) Core(TM) i5-8250U CPU上运行,其中,CPU具有6 MB的3级缓存,以1.6 GHz的时钟频率运行,平台具有8 GB内存和1 TB外存,运行系统为4.15.0的linux内核,Ligra、Gemini和GraphBIG等3种图计算框架的编译配置如表1所示。

表1 3种图框架的编译配置
2.2 数据集选取
性能分析数据集选自斯坦福大学的Stanford Network Analysis Project (SNAP)中Internet peer to peer networks的p2p-Gnutella31(p2p)、Networks with ground-truth communities的com-DBLP(com)、Signed networks的 soc-Epinions1(soc)以及Road networks的 roadNet-PA(PA) 4种数据集,4种数据集顶点个数、边数如表2所示。本文将对这些真实世界图数据进行处理。
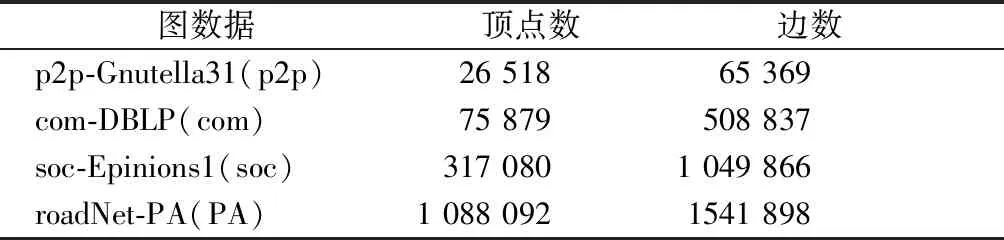
表2 实验所选的数据集
2.3 性能评测工具
为了对处理器和操作系统相关性能指标进行性能分析,采用内置于Linux内核源码树中,基于事件采样原理,以性能事件为基础的perf[22]作为分析工具。采用perf 4.15.18版本,通过分析器收集性能指标数据来计算不同图框架处理SSSP算法及BC算法时的IPC、数据移动量、功耗、计算量、L1、L2以及L3数据缓存MPKI。
2.4 性能指标
根据统计的硬件性能事件,分析的性能包括IPC、数据移动量、功耗、计算量、L1、L2以及L3数据缓存MPKI等。由于输入图数据规模差别较大,将性能指标统一到每一条边的处理上。
1)执行时间。任务的执行时间是指目标任务真正占用处理器的时间,可直接显示图计算的性能。使用C++系统库记录任务的执行时间。
2)IPC。IPC表示平均每一时钟周期所执行的指令数,能够直观的表示指令级的并行性。IPC越大,说明程序充分利用了处理器的特征。
3)数据移动量。数据移动量衡量移动操作的次数而不是移动操作的数据量。实际测量中,记录不同图框架在SSSP算法及BC算法实现过程中每条边的数据移动量。其定义为
(3)
式中:Nload和Nstore分别为加载和存储指令总数,用来表示数据移动;Nedges表示边的总数。
4)功耗。功耗是衡量图计算加速器性能的重要指标。功耗与所分析图的大小成比例。使用每条边的能量消耗来表示功耗,将功耗定义为
(4)
式中,Rpower_all表示消耗的总能量。
5)MPKI。MPKI指每千条指令的平均未命中数,即缓存cache缺失率。各级cache的MPKI为
(5)
式中:Cm表示缓存缺失数;Iinstructions表示指令数。
6)计算量。计算量是分析图计算加速器性能的重要指标,通过分析每条边计算量来表示完成图计算所需的计算量。定义计算量
(6)
式中:Dload表示加载指令数;Dstore表示存储指令数;Dbranch表示分支指令数。
7)皮尔逊相关系数。为了分析各指标参数对性能及能耗的影响,采用皮尔逊相关系数(Pearson Correlation Coefficient,PCC)方法计算参数实测结果与性能/能耗指标之间的影响系数,其参数范围介于+1和-1之间,正值表示正相关,负值表示负相关,0表示不相关。
3 特性化结果与分析
通过对4种数据集采用不同的图框架进行处理,根据其处理结果以及性能参数进行分析比较。
3.1 特性化分析概述
在3种图框架中实现SSSP和BC算法处理4种数据集的性能指标如图1所示。图1以雷达图的形式显示了分别在Ligra、GraphBIG和Gemini等3种图框架下实现的SSSP和BC算法处理4种不同数据集的性能指标值。雷达图以对数刻度表示的归一化值按顺时针方向从顶部开始显示每条边的执行时间(exec.time)、IPC、数据移动量(MV)、L1、L2和L3三级数据缓存的MPKI(L1_MPKI、L2_MPKI和L3_MPKI)、计算量(compute)以及每单位的功耗(energy)等8个指标值。其中,每个度量标准的最大值视为100%,其他数据以最大值作为标准进行归一化处理。
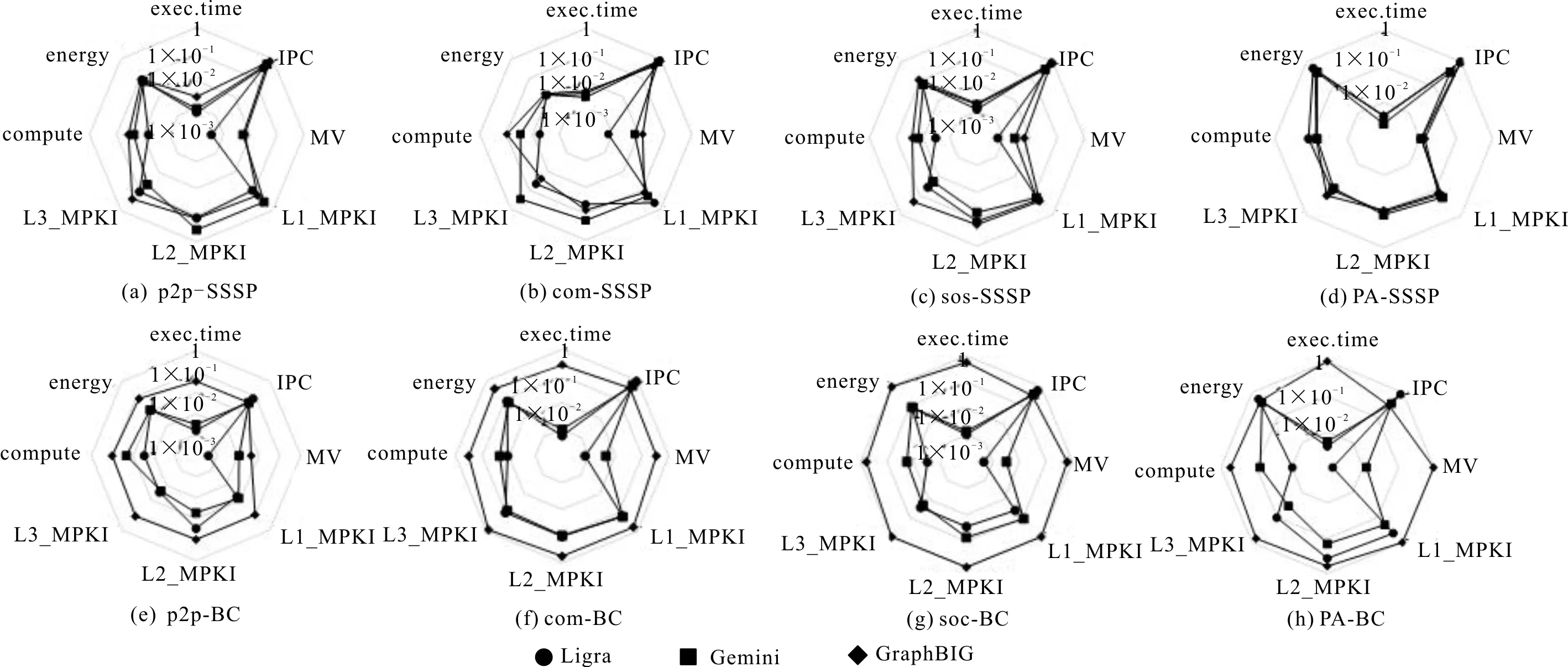
图1 3种框架实现SSSP算法和BC算法的性能指标
由图1可以看出,当图框架在进行算法处理时,若高速缓存MPKI越大且IPC越小,则会增加其边的执行时间;若数据移动量较小,则会在减少其执行时间的同时减少功耗。这是由于MPKI越大则缓存缺失率越高,IPC越小则每时钟周期内处理的指令数越少,从而导致执行时间越长。在SSSP算法和BC算法的3种实现框架中,Ligra框架表现出的性能最佳,具有较低的执行时间和数据移动量,这是由于Ligra框架的单机内存系统把图数据直接加载到内存中进行计算,在处理过程中没有外部输入/输出延时,从而减少了数据的读取时间;而在BC算法的3种实现框架中,GraphBIG框架的功耗最大,是Ligra框架的6.07倍,这是由于GraphBIG框架的数据移动量为Ligra框架的数据移动量的近100倍。Gemini框架采用了块式划分的策略,能够进行更细粒度的负载均衡调节,相比于其他图框架,Gemini框架的执行时间较短,这种方式让每台机器负责一段连续区间的顶点,从而尽可能减少分布式的相关开销,从而在每条边的计算方面也节省了大量资源。同时,图计算加速器可以从减少数据移动次数的硬件技术(例如存内计算)中受益。
3.2 具体测量数据
雷达图显示了每个性能指标的相对数据,下面详细给出各指标的具体测量数据。
1)执行时间。执行时间的大小与图计算加速器的性能好坏直接相关。为了更好地表示可扩展性,分别对3种图框架进行多线程处理。
3种框架实现算法处理p2p-Gnutella31数据集的各边执行时间如图2所示。可以看出,随着线程数的增加,SSSP算法和BC算法各边的执行时间均呈下降趋势,这是由于多线程执行任务时,系统对可以同时执行的部分进行并行处理的原因。在硬件设计中,可通过增加处理单元使算法并行执行的方法减少执行时间,从而提高加速器性能。
另外,从图2中还可以看出,GraphBIG框架由于IPC较低导致执行时间偏高。当线程数小于4时,Gemini框架的执行时间小于Ligra框架的执行时间;当并行处理线程数大于4时,随着线程数的增加,Ligra框架的执行时间下降较快,且逐渐优于Gemini框架。当硬件条件受限制时,应该优先考虑在Gemini框架中实现算法。
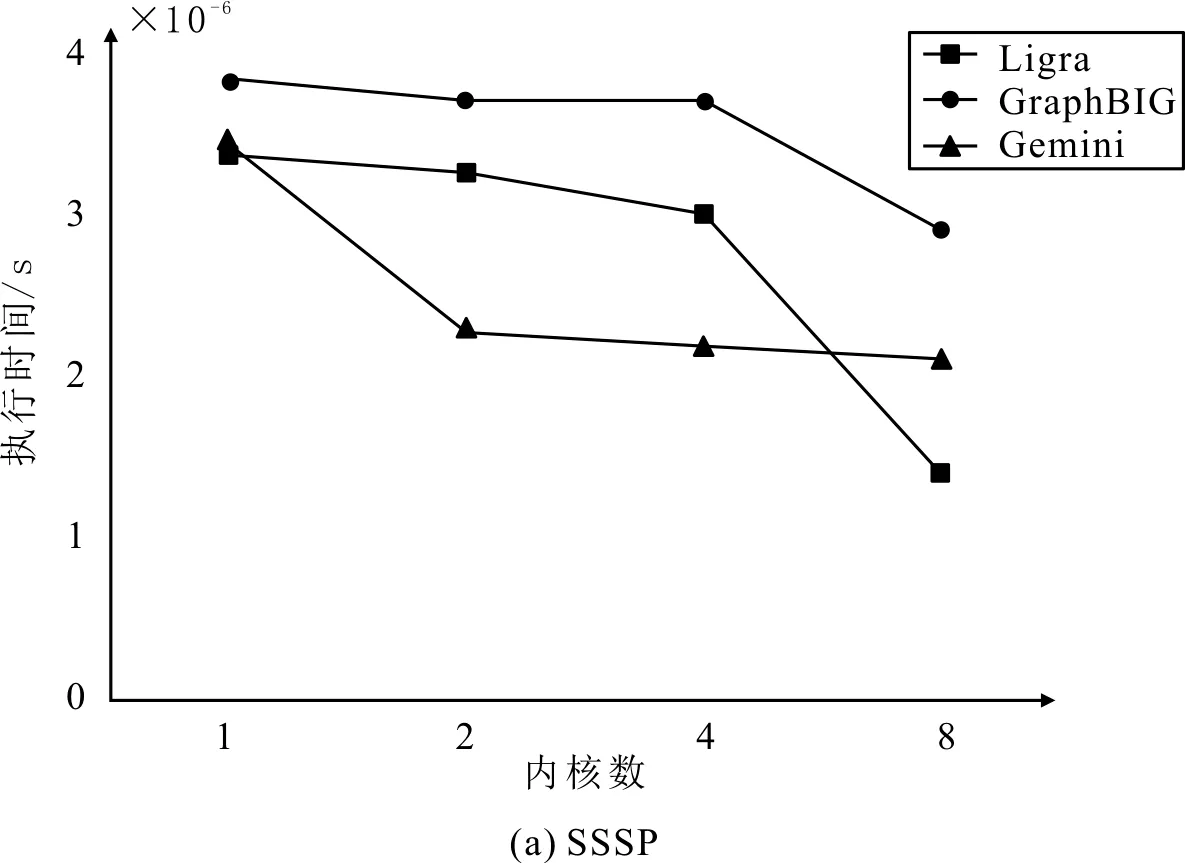
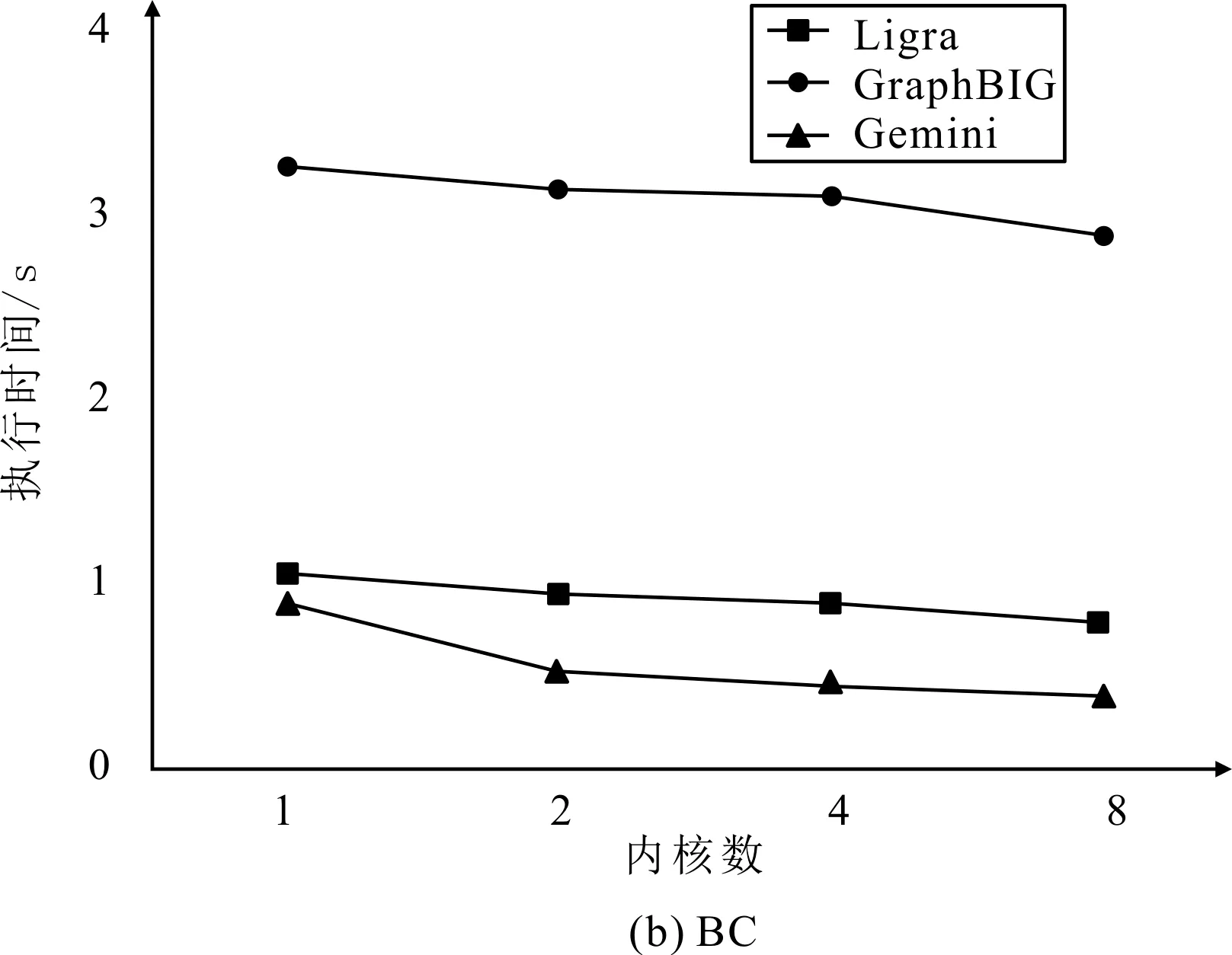
图2 3种框架实现算法处理p2p-Gnutella31
2)数据移动量。数据移动量受延迟和带宽的限制,在高性能计算程序中很难实现并行处理。分别对在3种框架实现SSSP算法和BC算法每条边的数据移动量进行测量,其结果如表3所示。可以看出,Ligra框架下实现算法的边数据移动量较少,然而GraphBIG框架的相对偏大甚至达到Ligra框架的数十倍,这是由于Ligra框架是基于单机内存的图计算系统,其在运行时可以直接将图数据完全加载到内存中进行计算,从而减少了访存计算比。然而真实图数据符合幂律分布,GraphBIG框架遵循以顶点为中心的数据表示方式,在进行数据处理时的局部性较差。因此,对于规模较小的图数据,可以将其全部存储到内存以减少数据移动量,以减少带宽浪费。
3)功耗。3种框架实现SSSP算法和BC算法处理4种数据集的每边功耗如表4所示。可以看出,GraphBIG框架下实现算法的功耗较大,这是因为各边执行的功耗与数据移动量成正比,数据移动的次数越多其功耗就越大,由于GraphBIG框架的数据移动量远大于Ligra框架和Gemini框架,从而导致GraphBIG框架的功耗相对较高,由于Ligra框架数据移动量较小,因此功耗较小。

表3 3种框架实现SSSP算法和BC算法每条边的数据移动量

表4 3种框架实现SSSP算法和BC算法的每边功耗
4)MPKI。3种框架实现SSSP算法和BC算法的每边L1、L2和L3级cache 的MPKI如表5、表6和表7所示。可以看出,由于缓存技术的进步,使得所有图应用程序的缓存性能都较好。另外,除了GraphBIG框架外,Ligra框架和Gemini框架的L1级cache的MPKI都小于11,L2级cache的MPKI和L3级cache的MPKI均远小于L1级cache的MPKI,因此,在分析各级缓存缺失与命中率时,应该将注意力集中在不同图框架算法实现的L1级cache MPKI上。

表5 3种框架实现SSSP算法和BC算法的每边L1级cache 的MPKI

表7 3种框架实现SSSP算法和BC算法的每边L3级cache 的MPKI
5)计算量。3种框架实现SSSP算法和BC算法的每边计算量如表8所示。可以看出,在处理较密集的图数据集p2p和PA时,Gemini框架每边的计算量明显小于基于单机式图计算加速器Ligra框架每边的计算量,而处理较稀疏的图数据集com和soc时,单机式图计算加速器的平均计算量是Gemini框架的25%。这是由于Gemini框架采用图划分操作进行更细粒度的负载均衡调节,在图数据相对密集时通过图划分操作减少其计算量,同时也降低了内存访问延迟。因此,当处理稀疏数据时,选择Ligra框架实现算法实现能够有效地减少计算量,提高处理性能。

表8 3种框架实现SSSP算法和BC算法的每边计算量
6)PCC。不同指标性能和能量的PCC相关性如表9所示。
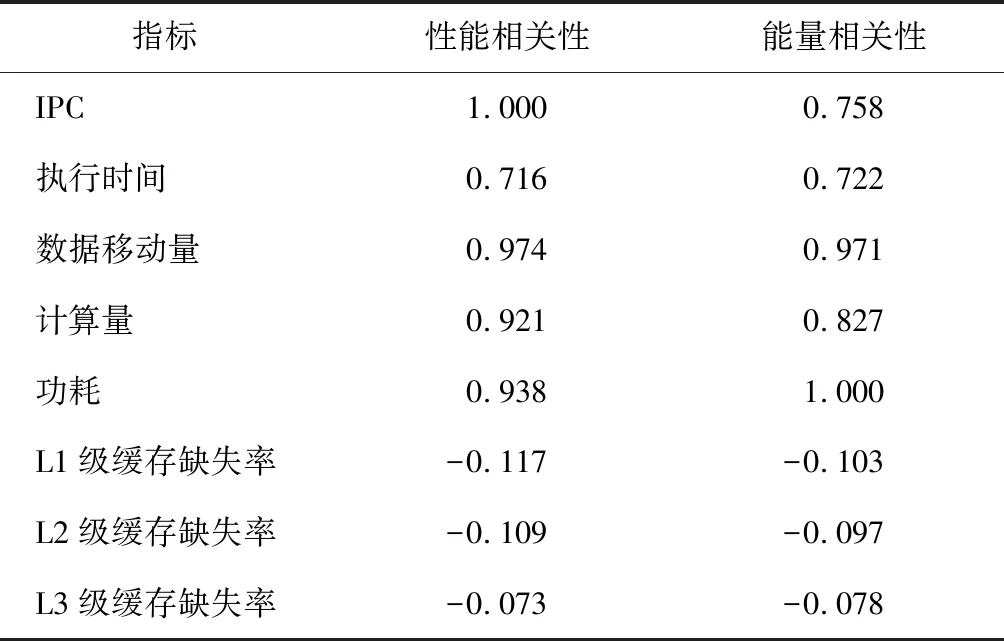
表9 不同指标性能和能量的PCC相关性
可以看出,每边的数据移动量和功耗之间的相关度高达0.97,表现出二者直接具有很强的相关性;另外,计算量和功耗在某种程度上与性能/能耗相关,相关度大于0.8。因此,在对图框架及图计算加速器进行优化时,应重点从数据移动量和功耗着手,减少数据的移动次数以提高图计算效率。
4 结语
通过对当前主流的图计算框架Ligra、Gemini和GraphBIG中SSSP及BC算法的不同实现进行特性化分析,得到如下4个结论。
1)在算法处理过程中,如果缓存MPKI较大且IPC较小会增加其执行时间,若数据移动量较小则会在减少其执行时间的同时减少功耗。
2)随着系统处理任务的线程数增加,图数据边的执行时间明显减少,可以通过增加处理单元个数的方式提高硬件加速器的性能。另外,当硬件环境受限时,如处理器内核数小于4,则优先选择框架Gemini实现算法;而当内核数大于4时,选择图框架Ligra能够有效减少执行时间。
3)数据移动量和功耗与性能/能耗表现出极强的相关性,将图数据全部加载到内存中进行计算可有效减少数据移动的次数,但其计算能力有限。除此之外,可以通过建立计算容量可伸缩的处理单元或者对图数据进行划分的方法缓解幂律分布所导致的“水桶效应”。
4)在处理较稀疏的图数据时,单机内存系统具有较低的计算量,选择Ligra框架能够减少计算量。
当对硬件设计进行优化时,一方面,可以通过增加容量可伸缩的计算处理单元,对算法能够同时执行的部分进行并行处理;另一方面,可以对图数据进行图划分操作,从而减少功耗。对于较小的图数据,可以直接将其存储到内存中处理以减少数据移动的次数;对于较大的图数据,则可以借助外部存储器对数据进行存储,从而更高效地进行图计算处理。当执行时间为优先考虑因素时,若硬件环境受限制,处理器内核数小于4时,选择Gemini框架实现算法;当并行处理内核数大于4时,可以选择Ligra框架实现算法。当以数据移动量或计算量为优先参考考虑因素时,应选择基于单机内存系统的Ligra框架实现算法。
