DMR:兼容RISC-V架构的乱序超标量通用处理器核
2021-06-17孙彩霞隋兵才王永文倪晓强
孙彩霞 郑 重 邓 全 隋兵才 王永文 倪晓强
(国防科技大学计算机学院 长沙 410073)
(cxsun@nudt.edu.cn)
DMR是由国防科技大学计算机学院自研的一款兼容RISC-V架构的乱序超标量通用处理器核,主要面向高性能计算领域.
DMR支持用户态(user-mode)、特权态(supervisor-mode)和机器态(machine-mode)三种特权级模式,兼容RV64G指令集规范[1],并进行了自定义向量扩展,虚存系统支持Sv39和Sv48[2],物理地址为44 b.
1 微架构
DMR的微架构如图1所示.取指宽度为256 b,即8条32 b指令;译码宽度、寄存器重命名宽度和指令分派宽度都是4;寄存器重命名采用统一的物理寄存器文件方式,如果没有足够的空闲物理寄存器,重命名过程将会发生阻塞;分派后的指令根据指令类型进入相应的指令调度队列,同时也会进入重定序缓冲(reorder buffer,ROB);采用分布式调度队列,根据指令类型设置了整数调度队列、访存调度队列和浮点调度队列;调度队列中的指令就绪后,就会被乱序调度执行,每拍最多可以调度9条指令,其中3条整数指令、1条分支指令、2条load指令、1条store指令和2条浮点指令;指令被调度执行时读取寄存器文件获取源操作数,源操作数也可能来自旁路的数据;指令提交按序进行;指令Cache和数据Cache均为64 KB,4路组相联,Cache行大小均为64 B.

Fig.1 DMR microarchitecture图1 DMR的微体系结构
2 流水线
DMR的流水线如图2所示.单周期整数流水线共有12级,取指4拍,然后是2拍的译码.第1拍进行预译码并处理指令拆分和指令融合,第2拍译码出指令中的操作数信息,以供寄存器重命名时使用;REN为重命名站,DS为指令分派站,根据指令类型,将指令顺序分派到相应的指令调度队列;ISS为指令发射站,发射后进入RF站,读取寄存器文件,读出数据和旁路数据进行选择后送到执行站EX,执行结果在WB站被写回到寄存器文件.

Fig.2 DMR pipeline图2 DMR的流水线
数据Cache命中时的Load-to-use延时是4拍;为了实现较高主频,浮点流水线在读寄存器文件之后增加了一拍MUX用于数据选择.
3 分支预测
DMR采用TAGE(tagged geometric history length)[3-4]算法预测分支方向,所实现的TAGE结构包含5个组件(component),即除了基本预测器组件外,还包含4个具有标记的用不同历史长度生成索引的预测组件;2K项的BTB(branch target buffer)、48项的RSB(return stack buffer)和512项的IPB(indirect prediction buffer)分别被用于预测不同类型的分支的目标地址.
4 指令拆分和指令融合
DMR在译码阶段将整数和浮点之间的转换指令拆分成2个内部操作,转换操作在浮点单元完成,而读取整数寄存器文件或写入整数寄存器文件的操作在访存部件完成,使得浮点执行单元不需要读写整数寄存器文件,从而可以减少整数寄存器文件的读写端口数目、简化整数数据旁路网络的设计,同时也有利于物理实现.
DMR在指令译码阶段将某些指令组合融合成一条指令,然后进行重命名、发射和执行,从而提高指令实际发射宽度,并且可以减少指令占用的乱序执行资源数目和降低调度开销[5].
根据RISC-V架构手册的描述[1],结合DMR微架构的特点,DMR实现了指令组合的融合,如表1所示.auipc指令和load指令融合,可以实现PC(program counter)相对的32 b偏移寻址的数据加载,auipc指令和jalr指令融合,可以实现PC相对的32 b偏移的分支跳转.

Table 1 Instruction Fusion in DMR表1 DMR中的指令融合组合
5 处理器状态的恢复
当发生异常或分支误预测、需要清除前瞻执行的指令时,被清除指令对处理器有关状态的影响同样需要被清除,以恢复到前瞻指令未执行之前的状态.前瞻寄存器重命名映射表就是需要被恢复的处理器状态之一.
DMR维护了2个寄存器重命名映射表:前瞻映射表和体系结构映射表.指令重命名时更新前瞻映射表,指令提交时更新体系结构映射表.DMR在指令提交时才报告该指令触发的异常,所以发生异常时,异常指令之前的所有指令都已经完成对体系结构映射表的修改,直接使用体系结构映射表恢复前瞻映射表即可.而分支误预测一旦发生,需要立即清除后续前瞻执行的指令,这时前瞻映射表一般通过重建的方式进行恢复,重建完成前不能进行寄存器的重命名,从而可能造成流水线停顿.DMR在分支指令进行重命名时,会对当前的前瞻映射表进行备份,分支误预测发生时使用该分支对应的备份数据对前瞻映射表进行快速恢复,避免重命名映射表重建导致的流水线停顿.
6 自定义向量扩展
DMR面向高性能计算进行了浮点向量的自定义扩展,该扩展中浮点向量和浮点标量共用一套体系结构寄存器,标量占用寄存器的低位部分.如图3所示,其中D表示双精度浮点,S表示单精度浮点.
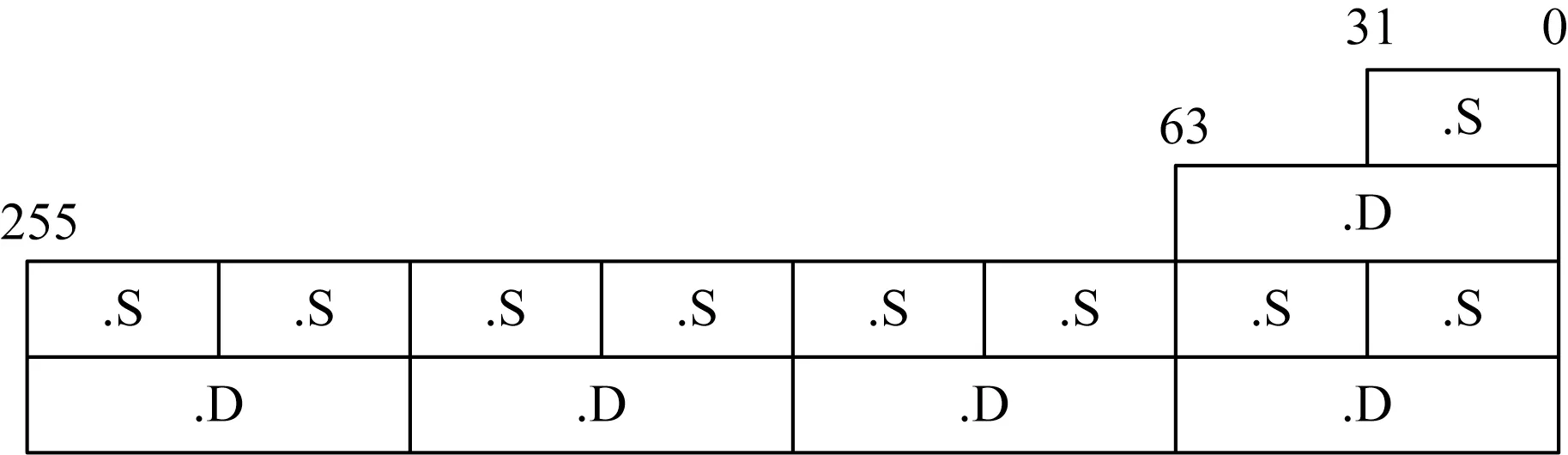
Fig.3 Vector formats图3 向量格式
除了基本的单、双精度浮点计算操作和访存操作外,自定义扩展指令集还支持单、双精度浮点向量乘加操作以及gather load/scatter store操作.
向量长度支持动态配置为128 b或256 b.DMR的浮点执行单元实现了2条256 b流水线,双精度浮点峰值运算性能可达到每个时钟周期16个操作.
7 功能验证和性能结果
DMR采用覆盖率驱动的多层次、多平台功能验证方法,如图4所示.
验证分为3个层次:单元级、核级和系统级.在单元级,针对不同的功能单元搭建了基于UVM(universal verification methodology)的软模拟平台和形式化验证平台,在核级,搭建了基于trace实时对比的软模拟平台,在系统级搭建了硬件仿真平台.对单元级的软模拟平台和形式化验证平台收集的覆盖率以及核级软模拟平台收集的覆盖率进行合并,统一管理.
DMR已经在FPGA原型系统下成功启动Linux OS,Core Mark分数为5.12 MHz,在14 nm工艺下主频可达到2 GHz.

Fig.4 Functional verification图4 功能验证方法
