基于Python 的微信公众号信息采集系统设计与实现
2021-06-16夏玲玲通讯作者戴文韩旭钱怡吉
夏玲玲 (通讯作者),戴文,韩旭,钱怡吉
(1.江苏警官学院计算机信息与网络安全系,江苏南京,210031;2.如皋市公安局丁堰中心派出所,江苏南通,226500)
0 引言
自媒体时代,人们参与社会议题的方式更加灵活多样,微博、微信、抖音等新媒体平台逐渐成为社会热点事件中民意的重要宣泄口[1]。作为2020 年度十大好用到爆的App之一的微信,是目前国内最受欢迎也是用的最多的即时通讯软件了,而在国外微信的使用人群也是非常庞大的。微信的流行改变了传统的人际交往模式,在微信客户端上衍生出的各类功能应用包括微信公众号、微信朋友圈、微信群聊等,也影响了传统的信息生态。微信公众号由个人或企业组织机构申请,通过用户订阅的模式将消息直接推送给用户,成为近年来新媒体平台的“宠儿”[2]。越来越多的个体和商家选择开通微信公众号发布文章或商品销售信息,将公众号当做一对多的思想、观点、广告等信息发布平台,导致公众号出现虚假消息传播以及用户评论出现“水军”留言的现象。此外,某些突发事件发生后,微信公众号的文章和用户评论直接反映了最新的网络舆情动态。政府及相关监管部门有必要及时掌握微信公众号的文章和用户留言,了解最新的舆情动态,面对虚假消息的传播立即制止,针对网络舆情危机及时化解并科学引导[3]。因此本系统设计并实现了一个自动采集微信公众号文章及用户评论的系统,对于新媒体平台舆情管控工作的开展具有重要意义。
1 系统设计
■1.1 系统整体架构
微信公众号信息采集系统整体架构如图1 所示。
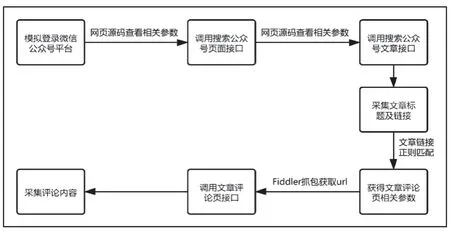
图1 系统整体架构图
■1.2 模拟登录模块
本系统利用Selenium 库中Webdriver[4]模块进行模拟登录。借助Webdriver 调用chrome 浏览器,通过get 请求直接转到微信公众号平台的登录界面,采用Webdriver的元素定位方式对账号框、密码框以及登录按钮进行元素定位,跳出的二维码选择手动方式进行扫描登录。
■1.3 获取文章标题及链接模块
文章接口的获取经过测试发现可以通过两种途径获取,一种是通过微信公众号平台开放的接口来获得文章列表及相关内容,另一种是通过中间人的方式抓取手机访问微信APP 的流量包,分析所得数据包的数据结构来获得文章的相关信息。
(1)通过微信公众号平台获取
微信官方在2017 年6 月6 号发布了一则消息:对所有公众号开放在图文消息中插入全平台已群发文章链接(消息的链接地址https://mp.weixin.qq.com/s/67skuKz9Ct4niT-f4u1KA)。也就是说至此以后公众号发布文章的时候可以直接插入其他公众号的文章。能够插入其他公众号的文章说明在微信公众号平台中有了所有公众号已发布文章的接口,通过这个接口可以获取到所需的公众号文章相关信息。
(2)通过Fiddler 抓包工具获取
Windows 下常用的中间人抓包工具有Fiddler、Wireshark、HTTPwatch 等[5]。其中Fiddler 是以代理服务器的形式工作,通过改写HTTP 代理,让数据从它那通过,来监控并且截取到数据,同时能够解析HTTP、HTTPS 加密的内容,比较适合本系统的需要。通过分析Fiddler 抓取到的访问公众号历史信息的数据包可以获得相应的文章接口以及所需的参数。
■1.4 获取文章评论模块
微信PC 客户端以及手机端因其自带浏览器,故而能够看到用户评论信息,因此评论接口和文章接口一样,通过访问文章获得其加载的评论信息数据包,然后解析该数据包的数据结构,获得所需信息即可。
2 采集系统实现与测试
■2.1 环境搭建及配置
(1)系统环境选择安装Python 3.7.0 以及Pycharm,以及需要下载安装Python 第三方库包括Selenium 库、time 库、json 库、requests 库、re 库、random 库 等。Selenium 库用于模拟自动登录,time 库用于设置等待时间避免爬取速度过快导致反爬,json 库用于解析网页返回的json 格式数据包,requests 库用于对目标URL 发起请求并解析,re 库用于正则匹配目标,random 库用于产生递交参数时所需要的随机数。
(2)Fiddler 的配置,Fiddler 需要安装HTTPS 证书才能对这类协议内容进行抓取。采集系统通过抓包手机端微信APP 来获得评论页的URL 时,需要对Fiddler 以及手机进行一系列的配置来达到电脑端的Fiddler 能抓取手机端微信数据流量的目的。在FiddlerOptions 的HTTPS标签中选择from remote clients only,这是为了防止PC端的流量干扰抓包。接着在Connections 标签中,由于是手机连接代理,所以选择allow remote computers to connect。配置完电脑端后,还需要对手机端进行相应的配置。首先保证手机与PC 在同一个局域网中,打开cmd,输入ipconfig,查看自己的IP 地址。将手机连入与电脑相同的局域网中,并开启代理。代理选项选择手动,在代理服务器主机名中填入刚才查看到的IP 地址,在代理服务器端口选择8888(Fiddler 默认端口为8888)。然后在手机默认浏览器中输入HTTP://IP 地址:8888,点击最下面的FiddlerRoot Certificate 下载安装证书。因为目标是微信的流量,可以对Fiddler 设置一下过滤。对手机端微信公众号文章浏览的抓包效果如图2 所示。

图2 微信公众号文章浏览抓包结果
■2.2 模拟登录模块的实现
模拟登录过程中,需要自动填入账号密码并点击登录,因此需要对账号框、密码框、以及登录按钮进行元素定位。定位完成后,通过清空账号框、密码框并递交自己预存的账号密码,完成自动登录部分。接下来跳出的就是二维码扫描界面,这里用手机微信的扫一扫。
■2.3 获取文章标题及链接的实现
(1)通过微信公众号平台获取
在对文章标题及链接的获取前,需要对爬虫进行一下伪装,即添加header 信息伪装成浏览器访问,如果不添加则会报错。这里只需要用到其中的user-agent 部分,将其与host 信息组成header 字典以备用。读取上一步获得cookies,登录之后的微信公众号首页URL 变化为:https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=XXX,可以从这里获取token 票据。爬取文章列表需要进行循环,在每次请求文章列表接口时都需要传入相关参数,每篇文章的相关信息都存储在app_msg_list 中,对其进行get 请求并存储到一个字典中,对该字典进行循环采集就能够将所需的文章标题及链接进行爬取,最后将采集到的文章标题及链接存储到本地就可以了。
(2)通过Fiddler 抓包工具获取
将手机配置好后,通过访问手机微信公众号的历史信息,Fiddler 可以截取到文章列表页的相关信息,可以发现是一个json 数据包。多加载几篇历史文章能够返回多个关于文章列表的json 数据包,对比发现这些json 的URL 发生变化的参数都为offset,即偏移量每次增加10,由此可以获得文章列表页URL 的变化规律。文章列表的具体信息都在general_msg_list 字典中,将其保存为本地的.txt 文件分析其数据结构。文章具体信息包含在app_msg_ext_info 以及multi_app_msg_item_list 中,其中前者是每个公众号的每日推送的第一篇文章,后者则是每日推送的附加文章,可能不止一篇。
■2.4 获取文章评论的实现
与调用微信公众号搜索接口以及文章列表接口一样,在调用文章评论接口时同样需要传入一些所需的参数。通过比对几次评论页链接的变化发现其中发生变化的有appmsgid、comment_id、appmsg_token、pass_ticket。_biz 是微信公众号的id 不会改变,前面已经做过相应的存储所以这里也可以直接传入。appmsgid、comment_id 以及appmsg_token 需要去网页中提取,可以在文章链接中通过正则匹配获得。pass_ticket 因为之前没有做过相应的存储,这里选择的是从抓包软件中直接复制进代码中。通过构建通用的评论页URL,传入所需参数,对该URL 进行get 请求并以json 格式解析即可获得评论页的内容[6]。
3 总结
自媒体时代,微信公众号的低门槛可能会带来虚假信息的传播以及“水军”留言的出现等问题。针对上述问题,对微信公众号的文章和评论内容进行自动化采集显得尤为重要。本文介绍了如何设计一个基于微信公众号的信息采集系统,并对系统的各个功能模块的实现做了简要说明。该系统的实现对于新媒体平台舆情管控工作的开展具有重要的现实意义。
