基于贝叶斯网络的智能舆情分析监控技术研究
2021-06-14杨寒冰王春玲
杨寒冰,王春玲
(西安航空职业技术学院,陕西西安 710089)
随着各种智能移动终端设备的普及与移动无线技术的快速发展,人们可以随时随地使用各种类型的社交软件分享实时新闻、自身的情绪等信息,尤其是在校学生等年轻群体[1-2]。近年来,高校扩招使得学生人数逐年增多,热衷于网络社交的大学生也成为了网络舆情的主要传播者之一。这些社交软件的用户在发布信息时,会通过社会关系网络使信息得到快速传播。这些信息不可避免地会夹杂着用户对事件的感情倾向和政治倾向,一旦得到大多数人的关注便会形成舆情[3-5]。使用相关技术挖掘网络社交软件信息背后隐藏的情感倾向与政治倾向,对网络舆情分析和监控具有重要意义[6-7]。
舆情分析与监控的目的是对人们日常生活中的热点话题进行监督和检测。高校汇集了大量的年轻人,他们对事物的判断力有待提高,社会经验相对不足,相似的学习经历使得彼此之间具有极大的号召力。个别学生片面的评论和见解容易引发同龄人的追捧,甚至引发舆论。因此,高校成为舆情监控的重要环节之一。
舆情分析的关键在于分析网络信息背后的情感,情感分析是融合统计学、计算机科学、文学等多门学科的技术[8-10]。由于网络信息量较大,采用传统人工统计的方式存在效率低等问题。此外,社交软件上的信息主要为文本形式,对于文本数据的特征提取也影响信息挖掘效率[11-12]。近年来,机器学习技术被广泛应用在大数据分析的场景中。作为人工智能的一个分支,机器学习进一步提高了处理海量、异构数据的效率。基于机器学习的情感分析主要分为两种:有监督学习与无监督学习方法[13-16]。
针对该问题,文中首先对网络社交信息情感类型进行分析,将情感倾向分为负面贬义、中立与正面褒义3 类。并对社交网络的文本信息进行预处理,通过与情感词典对比进行分词操作;并使用朴素贝叶斯网络做情感倾向分词器;最终使用堆叠降噪自编码器来进一步降低词向量的维度,以提高舆情分析监控模型的运行速度和准确率。
1 技术总体框架
智能舆情分析与监控技术主要涉及两个方面:网络热点话题的识别和情感倾向分析及判定。热点话题被定义为在短时间内迅速成为公众关注的对象,并保持着讨论时间较长的话题。热点话题一旦形成,其事件走向会引发众多公众的讨论。当负面情绪积累到一定程度时,便会引发舆论。因此,智能舆情分析监控技术首先要将热点话题的相关文本信息进行情感倾向分析与判定。
基于贝叶斯网络的智能舆情分析监控技术总体框架如图1 所示。社交网络中的主要信息格式为文本,文本情感倾向性分析与判定则是对公众文本形式的评论进行分析,从而判定某些群体对热点话题的看法或情感倾向表达。首先,进行文本数据预处理;其次,进行特征提取并表达;最终,利用融合后的特征输入至朴素贝叶斯网络分类器中。针对舆情分析,文中将情感倾向分为负面贬义、中立与正面褒义3类。
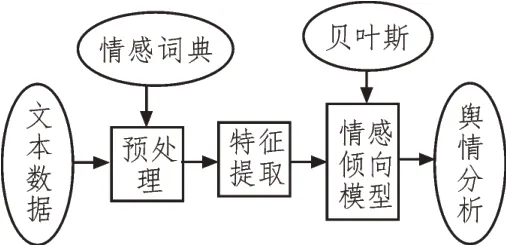
图1 基于贝叶斯网络的智能舆情分析监控技术总体框架
2 智能舆情分析监控技术
2.1 文本信息预处理
文本预处理要保证获取到的样本有效信息比例高,并有利于进行文本特征的提取。文本信息预处理主要分为文本清洗、分词、词性标注及停用词去除4 个部分。
文本清洗是指检查文本内容,删除无效、重复、错误的文本信息。在获得文本样本后,通常存在重复、无实际意义的文本、乱码字符以及繁体字与简体字混杂的现象。使用文本相似度计算算法来剔除重复的信息,通过正则表达式识别剔除无效的文字,调用Python 中的Opence 类库进行繁体、简体文本转换。中文文本中最小情感表示单元为词汇,因此,需要将每一个语句中的词汇进行剖分与识别。
由于同一个词汇在不同的上下文中有不同的词性,因此,需要对每个词汇进行词性标注,文中使用Jieba 分词器进行分词与词性标注。Jieba 分词器采用基于词典的字符串匹配分词方法,具体流程如图2所示。该方法对待分词的语句样本进行逐字扫描,扫描可分为正向与反向。将划分出来的词与词典里的词汇进行对比,匹配成功后汇入词序列,匹配失败则重新进行分词。
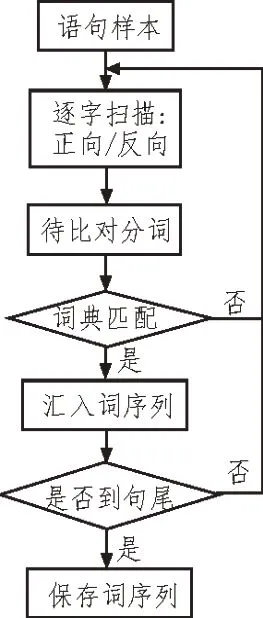
图2 基于词典的字符串匹配分词法流程
明确词性后,需要去除语句中介词、助词、代词及语气词,这些种类的词语并不具有情感倾向,去除后有助于降低文本特征的维度。
进过预处理后,即可进行文本特征的提取。通常字与词汇可构成语句最基本的特征,然而,此特征维数较高,不利于后面文本识别时运算与分类效率的提高。因此,需要将关键特征提取出来。文中采用互信息法来进行特征的提取,互信息被定义为某随机变量中含有另一个随机变量的信息量。根据概率学原理,当某个特征与分类为相互独立关系时,这两者的互信息为0。文中特征项x与分类c的互信息表示两者的关联程度,可用式(1)进行计算。
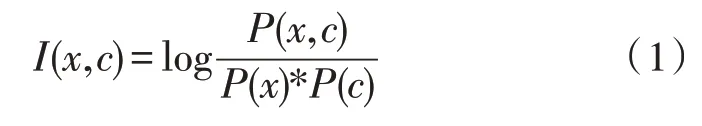
其中,I(x,c)表示x、c之间的互信息;P(x,c)表示x、c共同出现的概率;P(x)表示x出现的概率;P(c)表示c出现的概率。
使用互信息将关键特征提取后,还需要明确该特征对文本分类结果的重要程度,即特征权重。文中使用TF-IDF 算法来计算特征权重如式(2)所示。

式(2)中,tfik表示文档中特征tk出现的比例,idfk表示在所有文档中tk出现的比例倒数。
2.2 基于朴素贝叶斯的文本情感倾向分类器
为了适用于朴素贝叶斯网络,文中改进了情感词典的构建结构,如图3 所示。文中将词典情感分为3 类:褒义、中性与贬义。除了情感倾向的区分,还需考虑情感倾向的程度。对于待判断的词汇首先判断其是否属于已有情感词典,若存在,则直接计算情感均值;若不存在,则先判断情感极性,再计算情感权值,最终得到情感均值并更新至情感词典中。
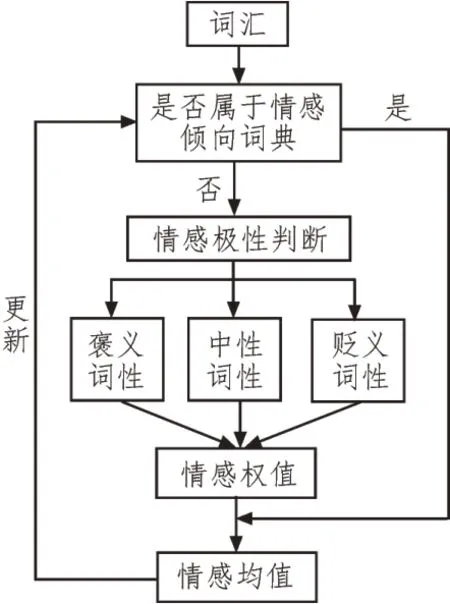
图3 情感均值计算流程
假设一段文本D的情感分类集合为{c1,c2,…,cn},将其中文本条件概率最大的情感分类定义为该文本的类。布尔值在DF向量法中作为文本向量的分量,其数值可表征某特征是否在文本中出现,1 表示出现;0 表示未出现。因此,某情感类别c出现的概率如式(3)所示。
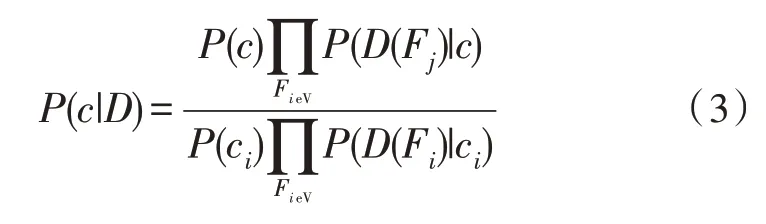
式(3)在计算时,若存在某个分类值在训练集合中未与某个分类同时出现的情况,则计算得到的概率值为0。而这种情况与现实情况相矛盾,因此需要进行平滑处理。文中使用拉普拉斯修正法进行朴素贝叶斯网络的平滑处理,如式(4)所示。
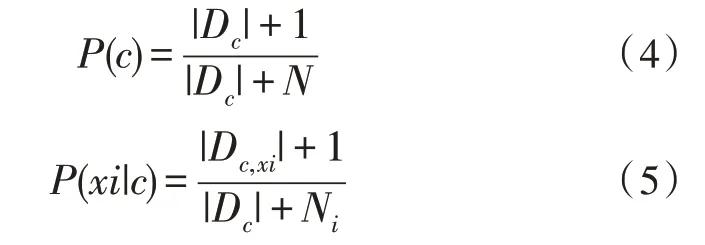
其中,N表示文本D中可能出现的情感分类总数,Ni表示第i个分类可能的概率取值。
2.3 舆情分析监控模型
上文利用朴素贝叶斯网络构建了情感倾向分类器,使用该分类器可进行各个词汇的情感倾向判断,进而判断舆情的走向,实现分析与监控。然而,若直接将文本中分好的词汇提取到的特征输入至分类器中,则会产生极大的计算量。因此,需要进一步构建舆情分析监控模型来降低特征的维度,并快速分析词向量特征与情感倾向之间的联系。
文中使用深度学习来降低词向量特征的维度,同时,融合朴素贝叶斯网络情感倾向分类器实现词汇情感分类。由于社交文本数据经过预处理后仍会存在一定量的口语词,即引入了一定的噪声,因此,文中使用堆叠降噪自编码器实现特征降维。降维后的数据被传输至朴素贝叶斯情感分类器中,通过将人工标注的数据传入该情感分类器中来修正朴素贝叶斯网络的权重参数,同时,通过反向传输来修正堆叠降噪自编码器的权重参数。具体框架结构如图4、图5 所示。
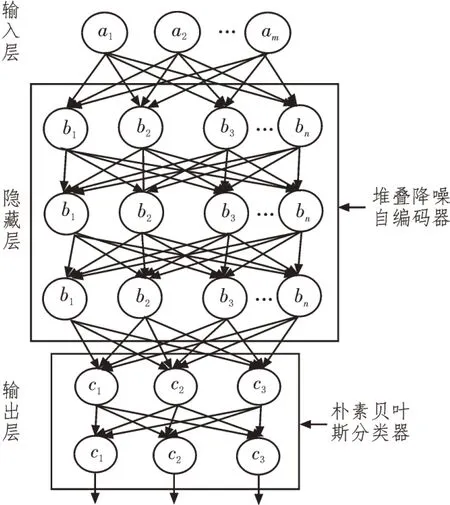
图5 融合堆叠降噪自编码器的情感倾向识别模型

图4 融合堆叠降噪自编码器的情感倾向识别结构
融合堆叠降噪自编码器的情感倾向识别模型含一层输入层、多层隐藏层及两层输出层。由于社交网络中信息量较大,需要多层隐藏层来深度挖掘词向量特征暗含的信息。然而,为了避免模型过于复杂,则降低计算量。文中隐藏层采用三层堆叠降噪自编码器的形式,即每一层隐藏层均是一个降噪自编码器。输出层融合了朴素贝叶斯情感分类器,有褒义、中性、贬义3 种情感极性输出。
3 测试与验证
为了验证文中所述方案的有效性与可行性,使用Eclipse 平台进行测试实验。实验采用的文本数据来自COAE-2020 微博数据测评集,其中情感倾向为褒义、中性与贬义的文本样本均为500 条。实验组设置成由文中所述的融合堆叠降噪自编码器与朴素贝叶斯分类器的舆情分析监控模型,对照组为融合堆叠降噪自编码器与Softmax 分类器的舆情分析监控模型。首先,验证文中所述方案情感识别的有效性与准确率,分别抽取褒义、中性与贬义文本各100 条,进行人工标注训练;另各抽取50 条文本做测试样本,检验模型预测结果与人工判定结果的差异。具体结果如表1 所示。

表1 情感极性测试结果
从图6 可以看出,文中所述融合堆叠降噪自编码器与朴素贝叶斯分类器的舆情分析监控模型的准确率整体上优于对照组。随着词向量维数的增加,实验组和对照组的准确率均有所下降;而维数增加到310 后,两者的准确率又逐步上升。但使用朴素贝叶斯分类器模型处理高维数的特征向量时,具有更高的准确率。
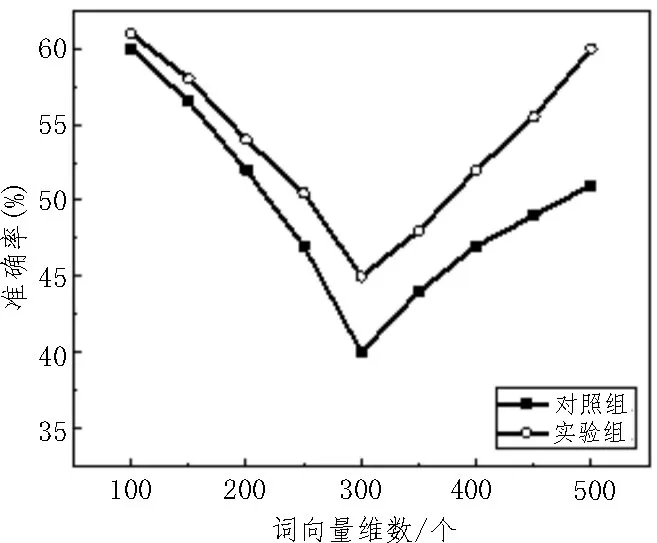
图6 文中所述朴素贝叶斯分类器与Softmax分类器不同词向量维数准确率对比
4 结束语
文中通过分析社交网络信息情感与舆情形成之间的关系,总结出当负面情绪比例较高时,容易引起舆论;利用朴素贝叶斯网络作为文本情感倾向极性分类器,并使用堆叠降噪自编码器作为词向量特征学习网络。经测试,文中算法有较高的准确率,证明了该方案的有效性。文中技术并不局限于微博,也可用于其他社交软件。对于研究大学生等年轻人对网络实时信息的情感倾向、政治态度均具有积极的参考意义,可用于高校舆情监督、稳定国内舆论环境。
