基于Viterbi 解码技术的智能语音交互算法研究
2021-06-14黄小奇陈光文许卓伟方志丹
黄小奇,范 晟,陈光文,许卓伟,彭 锴,方志丹,王 烁
(广东电网有限责任公司汕头供电局,广东汕头 515000)
语音交互作为最方便、易学的人机交互方式,已开始尝试应用于智能家居、车载系统、智能手机等电子产品领域[1-2]。然而,语音交互技术的真正成熟应用还需克服众多困难,尤其是在语音识别上。如实用与训练环境通常存在巨大的差异,导致实际使用过程中语音识别率较低;或者语用层、声学层和语言层的语音识别能力与人类相比仍有较大差距;亦或是人类通常在交流中存在笑声、咳嗽、哭泣等非正常语音现象与重复、停顿等不规则语言现象,导致语音识别误差较大[3-5]。因此,如何使用合适的语音交互算法准确识别实际环境下人类的语言,是提高语音识别率的关键。
实际上,在人类交流的过程中,通常只需要通过几个关键词就可以正确推断出谈话的核心内容,而不需要对连续语音进行辨析与识别,这为语音识别提供了思路[6-7]。目前,基于语音关键词的识别过程主要有基于垃圾模型、基于音素与音节识别、基于连续语音识别共3 类关键词识别结构[8]。3 类识别结构有各自的优势和弊端,因此,文中将音素、音节与连续语音识别相结合,将后者结构中的网格(词网格)用音素、音节的网格进行替代。基于核心的Viterbi 搜索解码技术,结合前端处理、声学与语言模型,设计了面向汉字的智能语音交互算法。该算法主要侧重于语音识别的关键词检测,并在交互平台上进行整合测试。测试结果表明,该算法具有一定的实用价值。
1 语音识别系统架构
语音识别系统通常包括语音输入、信号处理、信号解码以及文本输出4大部分,如图1所示。
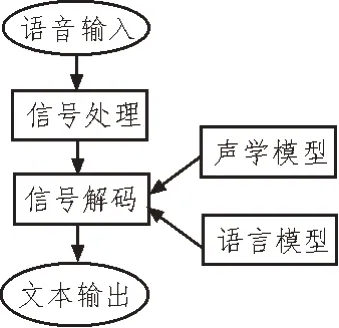
图1 语音识别过程框架示意图
语音输入主要是通过麦克风采集原始的语音信号,通过语音信号处理提取语音的特征,然后使用声学、语言模型进一步进行建模处理、概率计算和结果输出[9-10]。
1.1 语音信号处理
语音信号处理主要用于加工实际音频信号,去除次要部分,从而提高后续处理的质量与效率[11]。首先,采用端点检测来确定收集到的实际语音有效信号的头尾,即排除静音段和头尾部无用段,以此降低误判的可能,从而提高语音识别的性能。由于短时平均过零率Zn与短时能量En通常是语音信号的时域特征,所以文中选用上述时域特征的结合算法,对原始语音信号的端点进行检测。
然后采用预加重提高语音信号的高频部分。由于音频信号的高频部分能量少,直接传输会造成音频信号高频传输衰弱,因而需要预加重来提高音频的高频部分,从而弥补口唇辐射与声门激励的倍频跌落影响(6 dB/倍频),得到较为平坦的语音信号频谱。采用一阶高通滤波传递函数:

其中,a为预加重系数,且0.9<a<1.0。
声学特征参数如能量、频率等主要用于描述语音信号的特性及变化情况,通常为随时间变化的函数。提取声学特征参数主要有基于线性预估系数转换的倒频谱、感知线性预测和梅尔频率倒谱参数,也是文中选用动态帧长分析法提取的参数(24 维,由1 阶差分与前12 阶参数构成)[12]。
1.2 声学模型
声学模型主要有:1)HMM 隐马尔科夫模型,即统计模型,表现出双重随机过程,可用于描述非平稳信号中出现的短时平稳段和短时平稳段之间的动态特性;2)GMM 混合高斯模型,为常用的统计模型,由K个单高斯模型分量线性相加构成;3)SGMM 子空间混合高斯模型。
1.3 语言模型
语言模型用于对自然语言的结构和统计中存在的内在规律进行描述,在连续语音识别中尤其是在大词汇的情况下发挥着重要作用。该模型对候选序列能够起到声学特征的辅助决策作用,这在很大程度上能够降低搜索空间,从而提高搜索效率。语言模型主要分为基于文法(根据文法规则建立,包括正则文法与上下文无关文法)或基于统计(对文本资料中词汇的出现概率进行统计,通常与声学模型相结合,从而有效提高识别准确率)的语言模型[13]。文中选用的是基于统计的语言模型,具体为N-gram 语言模型。
1.4 Viterbi搜索解码
搜索解码主要用于在搜索空间中找到最佳的匹配结果,是语音交互算法的核心所在。
搜索解码主要有Viterbi 和A*算法,文中选用Viterbi 搜索解码算法设计智能语音交互算法[14],其具有典型的动态规划特性,能够对观察序列(长度为T)的最佳状态序列进行搜索与查找。此外,该算法实质上为递归算法,其最优解不会丢失,并可以较好地规避最优状态序列与声学观测序列间常出现的时间对准问题。图2 为Viterbi 搜索解码算法的一般过程示意图。

图2 Viterbi搜索解码算法的一般过程示意图
其步骤可描述为:对状态1 进行初始化,如式(2)所示;递归,得到式(3)、(4);对最佳状态进行搜索,得到式(5),S*与P*分别代表最佳状态序列和最佳分数;回溯路径如式(6)所示。
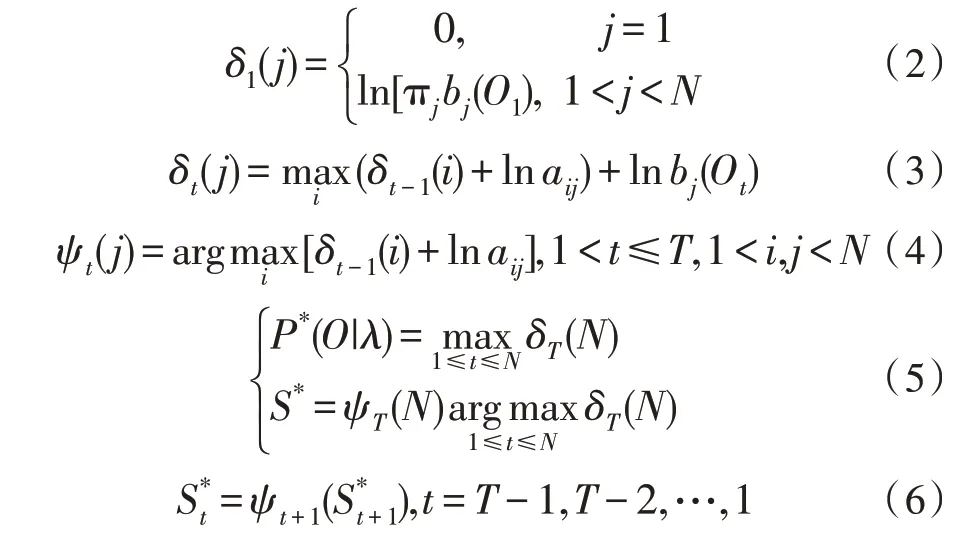
在语音识别过程中多次使用了搜索策略,通过知识源、语言/声学模型的高效循环使用,提高语音识别率。通常多次搜索的中间结果形式为Lattice 网格、N-Best 列表及混淆网络[15-16]。
2 语音识别系统设计
图3 为文中语音识别过程的框架示意图。将采集到的语音输入到连续语音识别器中,产生Lattice网格或N-Best 词格(存储为文本格式),借助关键词搜索器(基于关键词搜索算法)输出候选关键词。再经置信度和关键词确认,输出关键词。
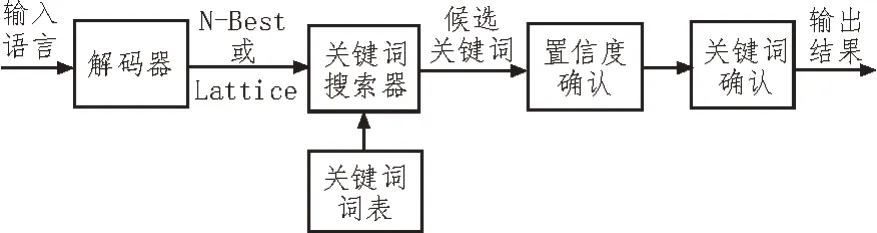
图3 语音识别过程的框架示意图
2.1 解码器设计
根据式(1),在预处理过程中将预加重系数选取为0.95;借助汉明窗进一步进行分帧处理(每帧定为20 s,帧移定为15 ms),从而得到上述3 种声学特征参数。
在预处理结束后的声学模型训练中,文中选用HMM-SGMM-UBM 模型作为声学模型对预处理后的语音信号进行训练。由于其算法面向的是大词汇量的汉语,因此选取声韵母基元作为基本的语音基元。
在语音模型的训练中,文中选用清华大学汉语库中的基于词的三元语音模型。该语音模型具备48 k 个字,总共包括772 000 句,总字数为1.15 亿,总词量为1 800 万,由SRILM 工具训练得到。
在最佳路径搜索中,文中利用Viterbi Beam 搜索解码算法得到音节与词网格。Viterbi Beam 算法能够按照一定的规则裁剪路径,使得搜索计算量大幅度减少,从而避免经典的Viterbi 搜索解码算法由于考虑所有路径而造成的计算量巨大的问题。其搜索步骤依次为:
1)路径初始化;
2)递推过程,为嵌套循环:

3)终止并确定路径。
值得注意的是,裁剪路径会根据实时情况忽略得分较低或可能性较低的路径,其标准为各路径与最优路径的得分差是否大于设定阈值。
2.2 Lattice网格确定
Lattice 网格由式(7)进行定义,其各边对应音节或词候选,包含了语言学与声学信息,如图4 所示(以语句“上海的工人师傅克服困难”为例)。


图4 词Lattice网格结构图
其中,P与S分别代表了全部节点和有向边的集合;pstart与pend分别代表了唯一起始和结束节点。
每一条边又可用式(8)进行表示:

其中,S(a)、E[a]分别代表了边a的起始与结束节点;I(a)为候选标识;lk(a)为权重。由语言模型得分(lm[a])和声学模型得分acc[a]加上权重系数λtm(λtm>0)计算得到[17-18],如式(9)所示。

2.3 关键词搜索设计
由于令牌传递算法具有查找关键词效率高、计算存储空间要求低的特点,文中选用该算法作为语音识别的关键词搜索算法,对关键词候选项进行逐步生成。
具体而言,关键词搜索的步骤为:
1)对长度为N的关键词进行搜索,起始于拼音格中的第一个音节节点w’,在达到某个音节节点Pt时的时刻记为t。若关键词W’与Pt的相似度超过了设定阈值,则输出候选Token。若前向节点此时已存在有激活的Token,则将该Token 复制到节点Pt,此时的候选音节串(长度为l)可表示为P=p1p2…pt;若l<[N+α·N],则对该Token 进行保留,以供后续扩展;若l=[N+α·N],则对相似度进行计算;若相似度并未超过设定阈值,则将该Token 删除,否则记录关键词信息并删除该Token。
2)若搜索过程已到达Lattice 尾部,则停止搜索,并将残留的Token 删除,最终可得到一个关键词候选序列。
2.4 置信度计算
由于关键词检测通常存在替代与插入现象,因此需要对常规的置信度算法进行改进。式(10)即为文中改进置信度算法引入的最小编辑距离字符串相似度函数:

其中,λ1(i=1,2,3,4)表示的是一个常数,Plat与Length(W)分别代表的是候选关键词W的后验概率得分和音节个数,Pmed表示的是音节串相似度。
2.5 关键词确认
同一语音段通常存在较多的候选关键词,因此文中引入两类关键词输出规则解决该问题,从而确定一个关键词的假象命中:
1)不限制关键词在语音段的数量与位置;
2)必须选择最优候选关键词作为假象的唯一有效命中而输出。
通常,针对语音识别输出的候选关键词,若在一定时间内与实际关键词相同,则表明检测正确;否则,表明检测失败。进一步,文中使用查准率(正确识别数/检测总数)、召回率(正确识别数/参考总数)和误识率(错误识别数/参考总数)对语音识别进行评价。
3 实验测试
该文的硬件部分为Intel Core i7 9700k CPU,32 GB 内存与2 T 硬盘的服务器,安装的系统为Centos 7,使用的软件为Kaldi 工具(基于C++),编写程序的脚本为Python、Perl与Shell。
该文的智能语音交互的语音识别实现界面如图5 所示。其包括批量关键词搜索和录音交互两个部分,支持关键词检测、创建现场录音及录音的保存与显示。

图5 文中语音识别的交互实现界面图
在对关键词词表进行预置后,通过“选择文件”按钮可对待检语音文件进行选取与显示;通过“执行检测”按钮可开始检测选中的语音文件,其运行结果在检测结果窗口输出。图6 为3 条语句的检测结果。可以看出,检测出的关键词总共耗时21.34 s。

图6 该文语音识别的运行结果界面图
此外,该文的智能语音交互还可以实现测试集的整体导入与检测,导入的所有文件列表、检测结果和性能统计将在界面上显示;若已含有测试集标注文件,还可输出查准率、召回率与误识率,如图7所示。

图7 测试集整体检测和结果输出界面图
经过多次、长期的测试,该智能语音交互的关键词语音识别效果较好,查准率能够稳定维持在90%以上,召回率也能稳定维持在95%以上,误识率一般低于13%,可以为相关智能语音交互算法设计提供借鉴和参考。
4 结束语
由于人类交流通常只需要通过几个关键词即可正确推断出谈话的核心内容,而不需要对连续语音进行辨析和识别。文中基于Viterbi 搜索解码技术,结合前端处理(语音信号)、声学和语言模型,设计了面向汉字关键词的智能语音交互算法。该算法依次通过连续语音识别器、关键词搜索器、置信度确认、关键词确认等过程实现对语音中关键词的搜索。经过人机交互软件的载入和测试,表明文中的算法具有较高的查准率、召回率和较低的误识率。
