实体摘要系统的解释性评测
2021-06-09刘庆霞李俊宥程龚
刘庆霞,李俊宥,程龚
南京大学计算机软件新技术国家重点实验室,江苏 南京 210023
1 引言
知识图谱可描述实体属性及实体间关系,提供丰富的知识。这种结构化的知识表示有助于数据融合与推理,便于应用对信息进行智能化处理。知识图谱已成为大数据环境下一种常用的数据形式,有效支撑着各类互联网应用,在搜索、电商、社交网络[1]等领域发挥着重要作用。在知识图谱中,实体、属性及其取值构成了描述该实体的一条三元组,DBpedia和Wikidata等知名知识图谱中包含的三元组总量达到十亿级,一些实体被许多三元组描述,例如,DBpedia中描述实体Barack Obama的三元组有一千多条。然而,在基于知识图谱为终端用户提供信息服务的应用中,为了避免用户信息过载,信息呈现空间通常有限,例如谷歌的知识卡片仅能呈现少量三元组,描述实体的三元组数量往往超过应用允许的限制。
研究者将解决上述问题的方法称作实体摘要(entity summarization,ES),目标是从知识图谱中描述实体的所有三元组中选取一个最优子集作为摘要呈现,在给定的容量限制内为用户提供实体的最关键信息。实体摘要已为多种下游应用提供了支持[2-3]。现有研究已提出多种实体摘要方法,并实现了各类实体摘要系统。实体摘要系统通常是对多种实体摘要技术特征(以下简称摘要特征)的综合,不同摘要特征体现了实体摘要关注的不同方面,例如实体摘要系统FACES-E[4]综合了频度、信息度和多样度等摘要特征。参考文献[5]对现有实体摘要系统及其覆盖的摘要特征进行了较详尽的介绍。
相比于对实体摘要方法和系统的研究,与实体摘要评测相关的工作较少。评测对于实体摘要问题的研究具有长远意义,摘要系统效果的比较、摘要特征效用的评价等都亟须评测工作的支撑。近期开展的一项评测工作ESBM(entity summarization benchmark)[6]提供了目前规模最大的实体摘要评测集,并基于该评测集对9个实体摘要系统进行了评测和比较。ESBM以黑盒的形式评测实体摘要系统的效果,但未能解释设计复杂的摘要系统表现出的具体效果的深层原因。为了推动摘要系统不断改进,研究者需要深入分析摘要系统的效果,理解系统各组件的具体效用。因此,有必要以白盒形式解释摘要系统的效果,从细粒度分析各项摘要特征的有效性。
为此,本文在ESBM的基础上,提出对实体摘要系统进行解释性评测,这项尝试被称为iESBM(interpretive ESBM)。相关代码和数据已发布在GitHub,并基于ODC-By协议开源。本文仍以通用型实体摘要系统为研究对象,但关注更细粒度层面的分析,从摘要特征的角度对摘要系统的效果进行解释。具体而言,对于每种摘要特征,使用特征效用率(feature effectiveness ratio,FER)度量该摘要特征在标准摘要中的显示度,使用特征显著率(feature significance ratio,FSR)度量该摘要特征在系统生成摘要中的显示度。FER和FSR分别量化了标准摘要和摘要系统生成摘要的特点,将两者进行对比,便可从摘要特征的维度对摘要系统的效果进行一定程度的解释。
本文主要贡献包括以下3个方面。
● 提出实体摘要的解释性评测指标:本文提出计算摘要特征的FER和FSR,并具体应用于现有实体摘要系统常用的4种三元组级特征和两种摘要级特征。
● 细粒度分析3个评测集的标准摘要:本文分析标准摘要的FER,从不同的摘要特征维度刻画标准摘要具有的性质。
● 对11个实体摘要系统进行解释性评测:本文分析9个非监督实体摘要系统和两个有监督实体摘要系统生成摘要的FSR,将结果与FER对比,从摘要特征维度解释这些摘要系统的效果。
2 相关工作
2.1 实体摘要系统
对现有实体摘要系统的详细介绍可参见参考文献[5]。本文关注通用型实体摘要系统,这类摘要系统可被广泛用于各类场景,并非为特定领域、应用或用户定制。现有通用型实体摘要系统大多采用非监督方法,利用各种模型集成多种摘要特征。例如,RELIN[7]基于三元组间的随机游走综合信息度和相关度对三元组进行排序。DIVERSUM[8]基于属性的多样度和流行度生成内容多样化的摘要。FACES[9]及其扩展FACES-E[4]基于词袋模型计算三元组间的相似度,对三元组进行聚类,并从不同聚类中选择信息度和流行度较高的三元组。CD[10]通过构造并求解二次背包问题来选择高信息度和多样度的三元组。LinkSUM[11]对PageRank值和反向链接值进行线性组合。BAFREC[12]将三元组划分为两个层面,元信息层面的三元组根据其内容在本体中的深度进行排序,数据层面的三元组根据流行度进行排序。还有一些方法采用了更复杂的模型,例如,ES-LDA[13]、ES-LDAext[14]和MPSUM[15]等系统引入了主题模型隐含狄利克雷分布(latent Dirichlet allocation,LDA),而KAFCA[16]采用了形式概念分析(formal concept analysis,FCA)。还有一些工作[17-18]尝试了有监督的实体摘要方法,采用深度神经网络进行建模,从训练集中的标准摘要学习出摘要生成模型。
2.2 实体摘要评测集
实体摘要研究者已经构建了一些评测集[6,9,19-21],这些评测集为通用型实体摘要系统的评价提供了标准摘要。然而,对实体摘要系统的全面评测仍较为少见,近期的ESBM工作[6]对9个非监督实体摘要系统进行了评测,这些摘要系统由各类摘要特征综合而成,包括ESBM在内的现有评测仅以黑盒的方式对摘要系统进行总体效果的评测和比较,并未深入分析各摘要特征对总体效果所起到的作用。鉴于现有评测工作的这一局限性,本文提出新的评测指标,使实体摘要系统的评测不再局限于粗粒度的总体效果对比,而是更细粒度地从摘要特征维度对摘要系统的效果进行解释。
3 评测指标与实现
3.1 基本概念
知识图谱的一种典型格式是资源描述框架(resource description framework,RDF)[22],这类知识图谱又被称作RDF图。一个RDF图T是由形式为<主语, 谓语, 宾语>的三元组构成的集合,这些三元组描述的所有实体构成的集合记为E。对于一个实体e∈E,其描述Desc(e)⊆T由所有以e为主语或宾语的三元组构成。一个三元组t∈Desc(e)可写作
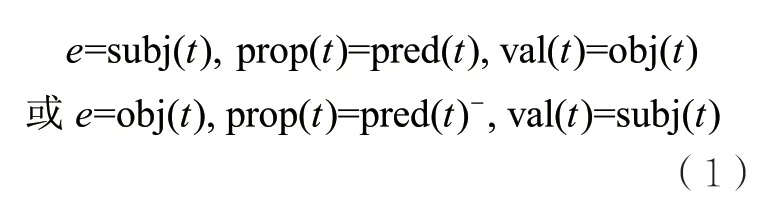
其中,pred(t)-表示pred(t)的反属性。由此,描述实体e的三元组t∈Desc(e)可简化表示为属性取值对
实体e的摘要S是e的描述的子集,即S⊆Desc(e),包含至多k个三元组。本文用Sc表示由摘要系统为实体e生成的待评测摘要,Sg表示e的一个标准摘要。需要注意的是,实体可能有多个标准摘要,因为评测集通常会提供多位专家独立标注的标准摘要,本文将e的所有标准摘要的集合记为SG。
3.2 评测指标
对于实体摘要系统中的一个摘要特征,本文计算两项指标:特征效用率和特征显著率,分别用于分析标准摘要和待评测摘要,再通过两者的比较来解释摘要系统的效果。本文将现有摘要特征分为两类:三元组级特征和摘要级特征。这两类特征的FER和FSR的计算方式略有不同。
(1)三元组级特征的评测指标
三元组级特征为每个三元组t∈Desc(e)计算一个打分,记作TScore(t)。例如,属性频度就是一种常用的三元组级特征,若该特征在摘要中确实有效,即高频度(或低频度)的属性确实更常被选入摘要S,则应观察到出现在S中的三元组的TScore(即属性频度)均值高于(或低于)实体描述Desc(e)中的三元组的TScore均值。具体而言,实体描述Desc(e)与摘要S在上述均值上的差异可表示为:
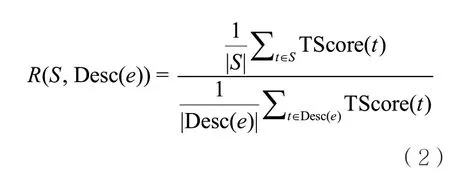
对计算结果R的观察主要在于其偏离1的方向(即高于或低于1)以及偏离程度。基于R,三元组级特征的FER和FSR的定义如下。
给定实体e的所有标准摘要的集合SG,三元组级摘要特征的FER定义为SG中各标准摘要相应R值的均值:
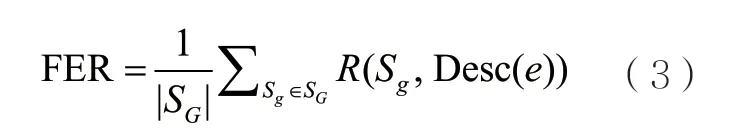
给定摘要系统生成的待评测摘要Sc,三元组级特征的FSR定义为Sc相应的R值:

(2)摘要级特征的评测指标
摘要级特征将摘要包含的三元组集合视作整体来计算一个打分,记作SScore。例如,摘要多样度就是一种常用的摘要级特征,若该特征在摘要中确实有效,即摘要S确实由较多样(或较相似)的三元组构成,则应观察到S的SScore值(即多样度)高于(或低于)实体描述Desc(e)的SScore值。具体而言,实体描述Desc(e)与摘要S在上述值上的差异可表示为:
摘要级特征的FER和FSR同样采用式(3)和式(4)计算,仅将其中R的计算方法替换为式(5)。
(3)FER与FSR的意义
FER与1的偏离情况体现了摘要特征在标准摘要中的显示度,可部分体现摘要特征的有效性。类似地,FSR体现了摘要特征在待评测摘要上的显示度。对于由多种摘要特征综合而成的摘要系统,这些摘要特征的FSR与相应FER间的差异能够为摘要系统的最终效果提供部分解释。
例如,某摘要系统以三元组属性频度为摘要特征,若该摘要特征的FER较高(远大于1),则表明标准摘要包含较多具有高频度属性的三元组,说明该摘要特征是有效的,使用该摘要特征有助于提高摘要质量。同时,若该摘要特征的FSR也较高(远大于1),则表明该摘要系统生成的摘要确实选取了较多具有高频度属性的三元组。若FER和FSR都较高且较为接近,则属性频度这项摘要特征可作为该摘要系统取得较好效果的解释之一。
3.3 具体实现
本文选取若干常用摘要特征实现上述评测指标。近期的评测工作ESBM[6]对9个非监督实体摘要系统进行了评测,参考文献[5]也全面介绍了现有实体摘要系统。本文从这些工作提及的实体摘要系统中选取摘要特征,包括4个三元组级特征和两个摘要级特征,它们涵盖了参考文献[5]中归纳出的三大类摘要特征,即频度/中心度特征、信息度特征、多样/覆盖度特征。
(1)三元组级特征
本文具体实现了4个三元组级特征,其TScore的计算方式互不相同,分别记为属性局部频度(local frequency of property,LFoP)、谓语全局频度(global frequency of predicate,GFoP)、取值全局频度(global frequency of value,GFoV)和属性取值对的信息度(informativeness of propertyvalue,IoPV)。
摘要系统DIVERSUM[8]和LinkSUM[11]采用三元组的LFoP作为摘要特征。对于实体描述中的三元组t∈Desc(e),该摘要特征计算了三元组属性在实体描述中出现的次数:
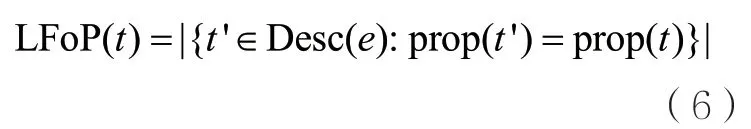
摘要系统LinkSUM[11]和BAFREC[12]采用三元组的GFoP作为摘要特征。对于实体描述中的三元组t∈Desc(e),该摘要特征计算了三元组谓语在RDF图T中出现的次数:

摘要系统FACES[9]、FACES-E[4]和BAFREC[12]采用三元组的GFoV作为摘要特征。对于实体描述中的三元组t∈Desc(e),该摘要特征计算了取值val(t)在RDF图T中出现的次数,即RDF图中顶点val(t)的度数,对该值取对数,以校正过于倾斜的度数分布,于是得到:
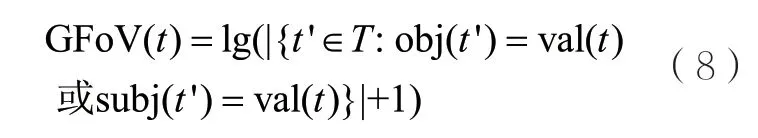
摘 要 系 统RELIN[7]、FACES[9]、FACES-E[4]和CD[10]采用三元组的IoPV作为摘要特征。对于实体描述中的三元组t∈Desc(e),该摘要特征考虑了RDF图描述的所有实体E,计算了“属性取值对

(2)摘要级特征
本文具体实现了两个摘要级特征,其SScore的计算方式不同,分别记为属性多样度(diversity of property,DoP)和取值多样度(diversity of value,DoV)。
摘要系统DIVERSUM[8]和MPSUM[15]通过避免选取属性相同的三元组来提高摘要多样性。本文将这一思路转化为摘要S的一种SScore值计算方式,定义S的DoP为S中三元组包含的独特属性的占比:
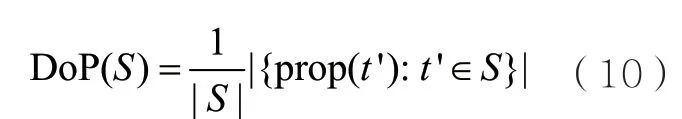
摘要系统FACES[9]、FACES-E[4]和CD[10]通过避免选取取值相似的三元组来提高摘要多样性,相似性计算通常基于取值的文本形式。本文将这一思路转化为摘要S的一种SScore值计算方式,定义S的DoV为S中两两取值的文本差异度的均值:

其中,ISub[23]是常用的字符串相似度度量,ISub(val(ti), val(tj))返回取值val(ti)和val(tj)文本形式的相似度,范围为0~1。具体到RDF图中取值的文本形式,对于字面量,取其字面形式(lexical form);对于非字面量,首先检索其rdfs:label值,若检索失败,则取其本地名称(local name)。
4 评测集设置
4.1 评测集
本文采用实体摘要领域常用且规模最大的两个评测集:ESBM和FED。
ESBM v1.2是目前最新的实体摘要评测集[6],分为两个评测子集:ESBM-D和ESBM-L。ESBM-D中的125个实体取自百科知识图谱DBpedia 2015-10,ESBM-L中的50个实体取自电影知识图谱LinkedMDB。该评测集为每个实体描述提供由不同专家标注的标准摘要,包括6个以k=5为容量限制的标准摘要和6个以k=10为容量限制的标准摘要。
FED是为评价FACES而专门设计的评测集[9]。该评测集中的50个实体来自百科知识图谱DBpedia 3.9。为了匹配FACES的处理能力,FED中的实体描述仅包含取值为实体的三元组,不包含取值为类型或字面量的三元组。FED为每个实体描述提供5~8个以k=5为容量限制的标准摘要(均值为7.32)和5~8个以k=10为容量限制的标准摘要(均值为7.16)。
ESBM v1.2提供了对数据的五等份划分,以支持统一的五折交叉验证,每折中60%、20%、20%的实体分别用于训练、验证、测试。本文采用同样方式对FED数据进行划分。
4.2 参评系统
本节对如下11个实体摘要系统进行评测。
● 9个非监督的实体摘要系统,这些系统也在ESBM[6]的评测范围内,即:RELIN[7]、DIVERSUM[8]、FACES[9]、FACES-E[4]、CD[10]、LinkSUM[11]、BAFREC[12]、KAFCA[16]和MPSUM[15]。
● 两个有监督的实体摘要系统:ESA[17]和DeepLENS[18]。
对于9个非监督的实体摘要系统,本文使用其在ESBM[6]中的实现及配置,具体而言:RELIN、CD和LinkSUM系统采用超参数对多种摘要特征进行线性组合,本文在0和1之间以0.01为步长调整这些超参数。对于两个有监督的实体摘要系统,采用其开源实现及配置,在模型训练时采用早停机制,根据验证集上的性能在1~50的范围内选择训练迭代次数。
5 评测结果
本节首先展现传统的非解释性评测结果,然后基于FER分析各摘要特征的有效性,最后对比FSR和FER,并解释各实体摘要系统的效果。限于篇幅,本节仅展现容量限制k=5时的评测结果,k=10时的结果请参见GitHub。
5.1 非解释性评测
本文沿用ESBM[6]采用的评测指标F值(F-score)对实体摘要系统的总体效果进行评价。具体而言,针对实体e,将待评测摘要Sc与各标准摘要Sg∈SG分别进行比较并计算F值,再对这些F值求均值,作为该待评测摘要的最终F值。这里采用以0.01为统计显著水平的双边双样本t检验,其零假设为:两个摘要系统在评测集上的平均F值相同。表1给出了各摘要系统在各评测集上F值的均值和标准差。表1还给出了两两系统间F值对比的t检验结果,若拒绝零假设,则用箭头标出,向上的箭头表示当前系统显著高于对比系统,向下的箭头表示当前系统显著低于对比系统,方块表示两者差异不显著。由于FACES和LinkSUM无法处理取值为类型或字面量的三元组,因此表1未给出它们在ESBM-D和ESBM-L上的结果。
可以看出,作为采用深度神经网络的系统,DeepLENS在3个评测集上显著优于其他系统。此外,BAFREC和ESA在ESBM-D和ESBM-L上取得了较优结果,而ESA和LinkSUM在FED上取得了较有竞争力的结果。
通过表1,可以对不同摘要系统的效果进行粗粒度的对比。然而,这些结果无法对每个摘要系统的效果进行具体解释。接下来,本文通过FER和FSR进行细粒度的解释。
5.2 摘要特征的有效性
对于第3.3节介绍的6个摘要特征,首先分别计算其在3个评测集上的FER。这里采用以0.01为统计显著水平的双边单样本t检验,其零假设为:摘要特征的FER均值等于1。表2给出了各摘要特征在各评测集上FER的均值和标准差。若t检验结果显示拒绝零假设,则用箭头标出,向上的箭头表示FER的均值显著高于1,向下的箭头表示FER的均值显著低于1。因此,箭头直接标记出了有效的摘要特征。
(1)LFoP与DoP
这两个摘要特征在3个评测集上的FER均值都与1存在显著差异,且差异的方向在各评测集上一致。

表1 各评测集上的F值(均值±标准差),均值显著高于或低于其他摘要系统的t检验结果(即p<0.01)分别用↑或↓标出;不具备显著差异的结果用▪标出;不适于比较的用-标出
DoP的FER均值显著高于1,表明标准摘要通常内容较为多样,包含不同属性。
LFoP的FER均值显著低于1,表明标准摘要包含较多低频度属性。然而,该结论可能是受上述属性多样度影响的结果。具体而言,局部频度高的属性通常在实体描述中涉及较多三元组,而标准摘要对多样度的倾向将导致这些具有相同属性的三元组中仅有一个被选入标准摘要,从而降低了LFoP的FER。为此,本文追加了一个实验,尝试消除多样度带来的影响。该实验在FER的计算中,对实体描述中具有相同属性的不同三元组仅计一次属性频度值,这样重新计算的FER在各评测集上都显著高于1,表明由于追求多样度而选择不同属性时,标准摘要实际上仍偏向于选择局部频度较高的属性,如rdf:type和dct:subject。
(2)GFoV与IoPV
这两个摘要特征在3个评测集上的FER均值都与1存在显著差异,但在不同评测集上的差异方向有所不同。
GFoV在ESBM-L和FED上的FER均值显著高于1,表明标准摘要倾向于选择取值全局频度较高的三元组。在ESBM-L的实体描述中,大部分取值是实体(83%);而FED中所有取值都是实体。因此,这些评测集上的高FER表明标准摘要更偏好流行度高的实体。然而,在ESBM-D上该摘要特征的FER均值显著低于1,这是由于ESBM-D的组成与另外两个评测集不同,其实体描述中大部分取值(63%)为类型或字面量,标准摘要倾向于选择全局频度较低的类型和字面量,以提供更具体的信息。
IoPV与GFoV截然相反,其FER均值在ESBM-D上显著高于1,而在ESBM-L和FED上显著低于1。这一结果是符合预期的,因为IoPV和GFoV在原理上通常起到相反作用:包含全局频度较低取值的三元组的信息量通常较大。
(3)GFoP和DoV
这两个摘要特征在一些评测集上的FER均值与1的差异不显著。
GFoP在ESBM-D上的FER均值显著低于1,表明标准摘要选入了较多全局频度不高的属性。类似于之前对LFoP的分析,GFoP呈现这一现象的原因同样是受到标准摘要倾向于选择多样属性的影响。通过追加实验消除多样度带来的影响之后,ESBM-D和ESBM-L上GFoP的FER均值显著高于1,表明由于追求多样度而选择不同属性时,标准摘要实际上仍倾向于选择全局频度较高的属性,如rdf:type、dct:subject、movie:director和movie:actor。然而,在FED上,重新计算的FER均值与1并无显著差异。
DoV在ESBM-D和ESBM-L上的FER均值显著高于1,在FED上略高于1,体现了标准摘要对取值多样度的偏好。但上述差异的绝对值并不大,这是由于实体描述中取值相似的情况本就不多见。
5.3 摘要系统效果的解释
本节尝试基于6个摘要特征初步解释11个实体摘要系统在各评测集上的摘要效果。对于各摘要系统在各评测集上生成的摘要,计算各摘要特征的FSR。对同一摘要特征的FSR与FER进行比较,采用以0.01为统计显著水平的双边单样本t检验,其零假设为:摘要特征的FSR均值和FER均值相等。表3、表4和表5分别给出了评测集ESBM-D、ESBM-L和FED上各系统各摘要特征FSR的均值和标准差。若接受零假设,则标记为方块,称为“相符”,即待评测摘要(对应于FSR值)与标准摘要(对应于FER值)在该摘要特征上的显示度一致。

表2 各评测集上的FER(均值±标准差),均值显著高于或低于1的结果(即p<0.01)分别用↑或↓标出
(1)非监督摘要系统
对于这些摘要系统,直接将其FSR结果与系统设计用到的摘要特征进行对照分析。
作为较早的实体摘要系统之一,RELIN在3个评测集上的F值都低于其他系统。从FSR可分析出该结果的两个原因。其一,RELIN的IoPV特征的FSR在各摘要系统中最高(同时GFoV的FSR最低),事实上RELIN在设计时便强调偏好属性取值对信息度高(取值全局频度低)的三元组。对于IoPV特征,RELIN在ESBM-L和FED上的FSR与该摘要特征的FER在1的两侧,即RELIN生成摘要的IoPV与标准摘要的倾向相反;而在ESBM-D上,其FSR过高,远超标准摘要对该摘要特征的倾向程度。例如,在ESBM-L上,RELIN常选择属性movie:filmid和movie:actor_actorid等来描述实体唯一标识的属性,这些属性信息度极高,但一般用户很少希望在摘要中看到,因此极少被选入标准摘要。其二,RELIN的DoV特征的FSR在各摘要系统中最低,且与FER分布在1值的两侧。这是由于RELIN的设计倾向于取值相似的三元组,造成摘要内容的冗余并降低DoV。CD系统作为对RELIN的改进,其F值略高于RELIN。从FSR结果可知,原因之一是:CD相对于RELIN在多样度上的效果更好,CD的DoV特征的FSR非常高,远高于RELIN的FSR,这得益于CD最大化取值多样度的设计。然而,由于同样倾向于选取属性取值对信息度高的三元组,CD的IoPV特征的FSR也显得过高。
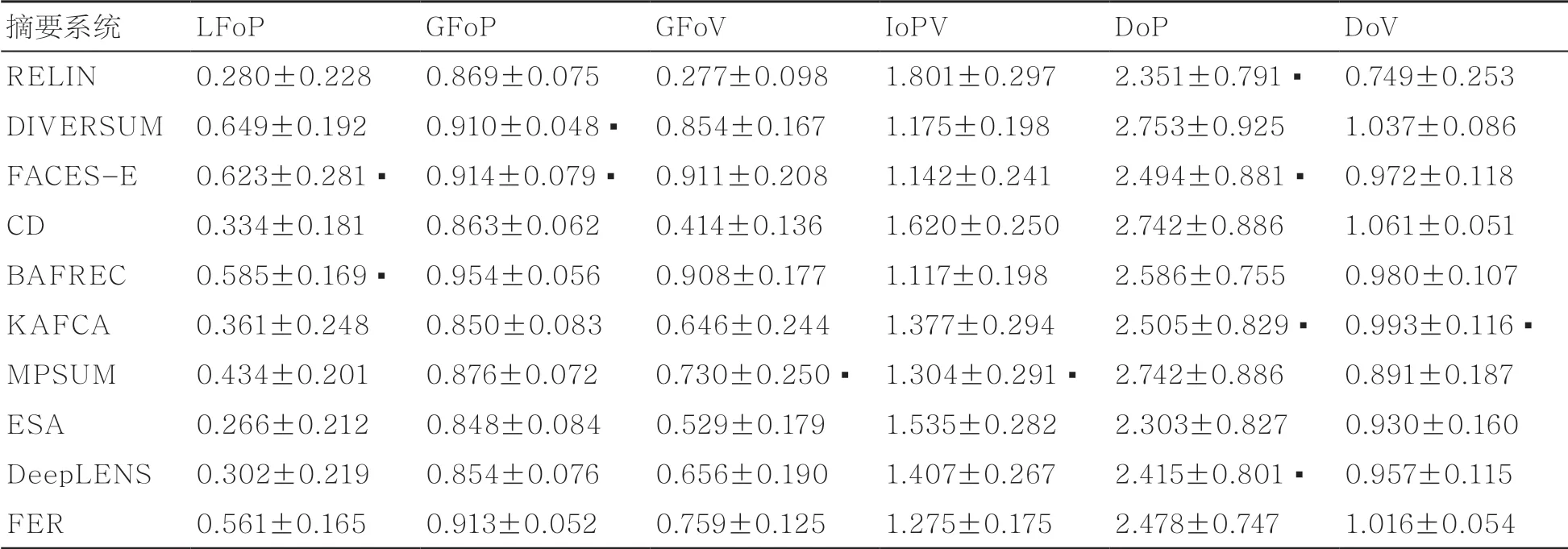
表3 评测集ESBM-D上的FSR(均值±标准差),与FER均值不存在显著差异的项用▪标记

表4 评测集ESBM-L上的FSR(均值±标准差),与FER均值不存在显著差异的项用▪标记

表5 评测集FED上的FSR(均值±标准差),与FER均值不存在显著差异的项用▪标记
FACES和FACES-E通常具有比RELIN和CD更高的F值。FACES-E在ESBM-L上的F值显著优于RELIN和CD,FACES-E的GFoV和IoPV特征的FSR与FER相符,这是由该系统在信息度和取值流行度之间相互平衡导致的。然而在ESBM-D和FED评测集上,FACES-E的GFoV特征的FSR过高,对取值频度的偏好过强。例如,FACES-E常选择以owl:Thing为类型取值的三元组,这种三元组意义不大。在FED评测集上,FACES和FACES-E的DoP和DoV特征的FSR与FER相符,这是由于这两个系统都通过三元组聚类有效提升了摘要多样度。三元组聚类技术在FACES中用于处理取值为实体的三元组,而FACES-E通过自动识别字面量类型将该技术扩展到取值为字面量的三元组。然而,对于ESBM-D和ESBM-L这两个包含取值为字面量的评测集,FACES-E的DoP和DoV特征的FSR有时与FER不完全相符,这说明FACES-E对FACES的扩展尚不够完善。
LinkSUM系统仅处理取值为实体的三元组。在FED评测集上,LinkSUM在非监督实体摘要系统中的F值最高,其IoPV的FSR最低而GFoV的FSR高于大部分系统,并且这两个摘要特征的FSR与1的偏离方向均与FER一致。LinkSUM主要设计原则为选择PageRank值较高的实体取值,这通常对应取值较高的全局频度和较低的自信息,其GFoV和IoPV的FSR印证了该设计原则在最终生成的摘要中起到了正面效果。然而,LinkSUM的DoP特征的FSR相对于FER偏低,这是因为其设计未考虑属性多样度。
KAFCA系统是ESBM-D上表现较好的非监督实体摘要系统之一。在ESBM-D评测集上,KAFCA的DoP和DoV特征的FSR都与FER相符,并且在其他摘要特征上的FSR与1的偏离方向均与FER相同。这是因为KAFCA是基于FCA的设计原理实现的。KAFCA优先选择局部频度低的属性,这些属性通常全局频度也较低,并对应局部频度较低的取值。KAFCA偶尔也选择包含局部频度较高词汇的取值,这有助于选入一些尽管携带高频度属性但仍描述具体信息的三元组,同时避免过于强调属性和取值多样度。然而,这种机制在ESBM-L上效果不明显,KAFCA的DoP和DoV特征的FSR相比于FER显得过高。例如,ESBM-L中局部频度较高的属性movie:actor及其反向属性movie:actor-被KAFCA完全摒弃,而标准摘要常选入这些属性。可见,由于缺乏对全局信息的感知,KAFCA无法对具体实体进行进一步区分。
BAFREC是非监督实体摘要系统中在ESBM-D和ESBM-L上F值最高的系统,在FED上的F值也较高。BAFREC将三元组分为两个层面,采用不同的排序选取策略,但都有多样度要求。对于元信息层面的三元组,BAFREC倾向于全局频度高的属性和全局频度低的取值(类型或字面量);对于数据层面的三元组,则倾向于全局频度高的取值(实体)。这些倾向与第5.2节分析的标准摘要的GFoP、GFoV、IoPV和DoP特征的FER较一致,因而印证了BAFREC的良好效果。然而,这些倾向并未充分体现在BAFREC的FSR上,这是由于本文实现的FSR尚未考虑对三元组的分层分析。
(2)有监督摘要系统
对于这些采用深度学习模型的摘要系统,其用到的摘要特征并不明显,尝试将其FSR结果与系统设计原理进行对照分析。
DeepLENS在3个评测集上都取得了高于ESA的F值。而在摘要特征上,DeepLENS的LFoP、GFoP、GFoV和IoPV特征的FSR在3个评测集上大多比ESA更接近FER,即DeepLENS比ESA更准确地拟合了标准摘要的这些三元组级特征。在模型设计上,ESA将属性和取值以符号的形式进行处理,而DeepLENS使用文本形式,并借助预训练词嵌入来理解属性和取值的文本语义。对这一外部信息的利用可能使DeepLENS取得比ESA更好的效果。
ESA和DeepLENS的DoP和DoV特征的FSR总体上低于FER,这一结果并不意外,因为它们的设计中都未显式考虑摘要级特征。在ESBM-D和ESBM-L评测集上,DeepLENS的DoP特征的FSR接近或高于FER,这是因为该方法在处理dct:subject和movie:actor等局部频度较高的属性时,由于包含这些属性的大量三元组只有很少被选入标准摘要,训练后的模型简单回避了这些属性。
5.4 案例分析
图1和图2给出了各摘要系统为两个实体描述生成的摘要,这两个实体分别来自ESBM-D和ESBM-L评测集。RELIN系统将信息度最高的属性filmid(三元组t1a)选入了摘要,然而该属性从未出现在标准摘要中。RELIN系统生成的摘要中还包含互相冗余的三元组(如三元组t11和t14,三元组t1b和t1c)。CD系统避免了这种冗余,但同样也将filmid(三元组t4e)选入了摘要。对于属性writer,CD选择了取值H. R. Christian(三元组t44),而FACES-E系统则在信息度和取值流行度的平衡下选择了更优的取值Leigh Chapman(三元组t33)。DIVERSUM系统重视属性多样度,却较忽视对取值的筛选,导致选入不理想取值(如三元组t2b)或冗余取值(如三元组t21和t23)。MPSUM系统同样重视属性多样度,但选择的取值更易理解,尽管依然存在冗余(如三元组t7a和t7b,t7d和t7e)。KAFCA成功选到属性为release date的三元组(t63),该三元组的属性局部流行度较低且取值中包含局部流行度较高的词汇“1981”。BAFREC系统通过设定超参数的方式固定从元信息层面的三元组中选择两个,从数据层面的三元组中选择3个。元信息层面三元组属性通常为rdf:type或rdfs:label,这些三元组(如t51和t55,t5a和t5e)也确实常出现在标准摘要中。有监督的两个实体摘要系统ESA和DeepLENS生成的摘要质量更高,尽管其中也存在一些冗余(如三元组t84和t85)。

图1 各实体摘要系统为ESBM-D评测集的实体dbr:King_of_the_Moutain_(film)生成的摘要

图2 各实体摘要系统为ESBM-L评测集的实体film:41408(即电影“The Spiral Staircase”)生成的摘要
6 结束语
本文尝试对实体摘要系统进行解释性评测,从摘要特征维度对摘要系统的效果进行分析。通过计算6个常用摘要特征的FER,对3个评测集上的标准摘要进行分析,总结出标准摘要的一些典型特点:标准摘要常包含较多样的属性和取值,并倾向于频度较高的属性;在取值为实体的三元组中,倾向于较流行的实体取值;在取值为类型或字面量的三元组中,倾向于信息度较大即较低频的内容。这些发现为未来实体摘要系统的设计改进提供了思路。本文通过计算11个系统的FSR,对这些系统生成摘要的效果进行了分析,将FSR与FER对比,细粒度地揭示了各系统的部分优缺点:非监督实体摘要系统在设计中显式固定一组摘要特征,往往在不同评测集上表现迥异,泛化能力不足,并且常缺失一些有用摘要特征;有监督实体摘要系统利用深度神经网络建模,在一定程度上克服了上述不足,避免了人工特征选择,但现有模型仍较简单,对多样度等摘要级特征的表示能力不足。
未来工作可对本文提出的评测指标及其实现进行扩展。首先,本文仅实现了6个常用摘要特征,增加新的摘要特征有助于开展更全面的分析。其次,由于本文提出的评测指标依赖于标准摘要,增加新的评测集有助于对摘要系统的泛化能力开展更全面的检验。
