基于有限状态自动机的藏文音节组织研究
2021-06-08更桑吉安见才让
更桑吉 安见才让

摘 要: 通过对藏文的字形特征、拼写规律,以及文法规则的分析和研究,实现藏文词语的实时检错。借助形式语言有限状态自动机的方法,对藏文字结构中的基字、前加字、上加字、下加字、后加字、再后加字之间的搭配规则设计了状态图和邻接矩阵。该方法提高了藏文文本质量,使原本复杂的书面语法规则变得简单直观,从而使符合现代藏文音节组织结构的词语能实时检错。该研究为实现藏文的自动校对提供了基础。
关键词: 藏文; 文法规则; 有限状态自动机; 校对
中图分类号:TP391.1 文献标识码:A 文章编号:1006-8228(2021)01-65-03
Research on Tibetan syllable organization using finite state automata
Geng Sangji, Anjian Cairang
(School of computer, Qinghai University for Nationalities, Xining, Qinghai 810007, China)
Abstract: By analyzing and studying the characteristics of Tibetan character, the spelling rule and grammar rule, the real-time error detection of Tibetan words is realized. With the help of finite state automata of formal language, this paper designs the state diagram and adjacency matrix for the matching rules among the basic characters, prefix letters, superfixed letters, subjoined letters, suffixed letters and up-adding characters in the Tibetan character structure. This method improves the quality of Tibetan text, makes the complex original written grammar rules simple and intuitive, so that the words in line with the modern Tibetan syllable organization structure can be error detected in real time. This research provides a basis for the realization of Tibetan automatic proofreading.
Key words: Tibetan; grammar rules; finite state automata; proofreading
0 引言
隨着藏区人民对信息数字化需求的提高,学习和利用信息数字化的技术手段来记载和传承民族文字显得非常重要,而人工智能领域对藏语信息研究发展有着不可忽略的重要性。通过研究藏文音节和字形结构[1-2],判断基字所在位置、特殊音节的处理等步骤解决藏文构件元素的识别[3];基于规则和CNN模型、基字定位等方法实现检错[4-6],这些方法都各有利弊,因此本研究提出基于有限状态自动机的藏文音节组织结构的研究方法处理检错。
研究藏文或文本校对的主要对象是语言单位,在藏语言中最小的语言单位是字母,其次是音节,音节由字母组成。而字形是字的形状和结构,藏文字形以一个辅音字母为核心其余字母以此为基础前后附加和上下叠加组合成一个字的结构,因此人们都说藏文是由字母组合而成的一种拼音文字。藏文字母包括30个辅音字母和四个元音字母,藏文的音节分为七个构件,核心的辅音字符称为基字,其余的字符按照相对于基字的位置来分别命名,加在基字前面的称为前加字,基字的上方和下方的分别称为上加字和下加字,基字后面的称为后加字和再后加字,元音位置在基字的上或下、上下加字的上方或下方[7]。藏文音节的组合形式比较多样化,但是总体的组合规则相对固定,藏文音节可以只包含一个辅音字母,也可以包含多个辅音字母(最多六个),由此可知藏文音节中基字是必不可少的一个构件,其他位置的构件都可以空缺。
1 藏文字形结构特点
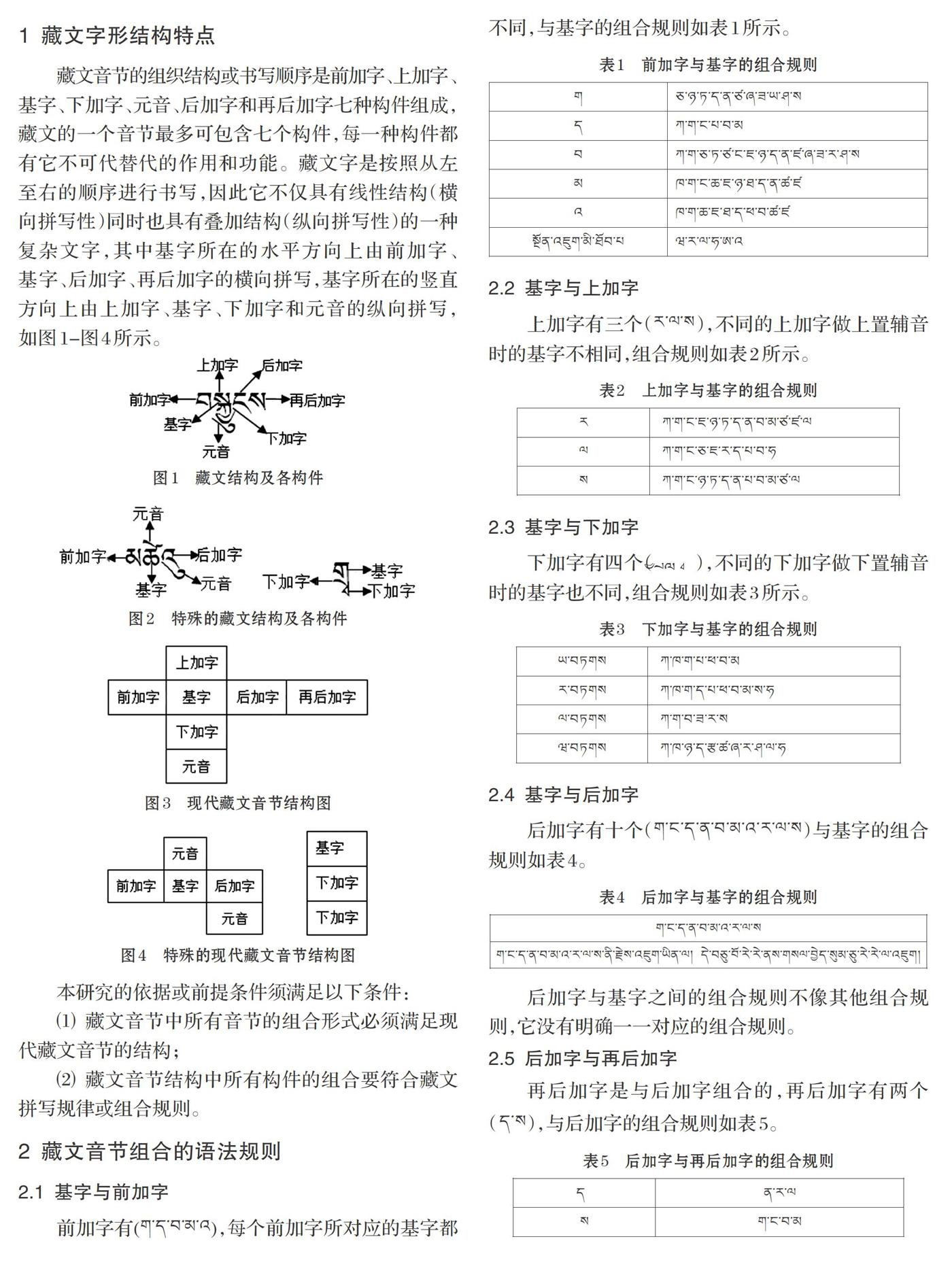
藏文音节的组织结构或书写顺序是前加字、上加字、基字、下加字、元音、后加字和再后加字七种构件组成,藏文的一个音节最多可包含七个构件,每一种构件都有它不可代替代的作用和功能。藏文字是按照从左至右的顺序进行书写,因此它不仅具有线性结构(横向拼写性)同时也具有叠加结构(纵向拼写性)的一种复杂文字,其中基字所在的水平方向上由前加字、基字、后加字、再后加字的横向拼写,基字所在的竖直方向上由上加字、基字、下加字和元音的纵向拼写,如图1-图4所示。
本研究的依据或前提条件须满足以下条件:
⑴ 藏文音节中所有音节的组合形式必须满足现代藏文音节的结构;
⑵ 藏文音节结构中所有构件的组合要符合藏文拼写规律或组合规则。
2 藏文音节组合的语法规则
2.1 基字与前加字
2.2 基字与上加字
上加字有三个(?????),不同的上加字做上置辅音时的基字不相同,组合规则如表2所示。
2.3 基字与下加字
下加字有四个(? ? ? ? ),不同的下加字做下置辅音时的基字也不同,组合规则如表3所示。
2.4 基字与后加字
后加字有十个(???????????????????)与基字的组合规则如表4。
后加字与基字之间的组合规则不像其他组合规则,它没有明确一一对应的组合规则。
2.5 后加字与再后加字
再后加字是与后加字组合的,再后加字有两个(???),与后加字的组合规则如表5。
3 基于有限状态自动机的规则表示
3.1 状态图
有限状态自动机也称为有限状态转移网络,通常采用状态图表示,图中的每一个结点表示不同的状态,其中一个圆圈(○)的代表开始状态,双圆圈(◎)的代表终止状态即结束标志,状态之间用有方向的弧线链接表示转移状态,弧线上的标记表示转移的条件,也可看作是输入符号,转移也可以是无条件的,即标记为空字符(N)。从状态转移网络的起始状态开始出发,根据弧线上的条件决定向哪一个状态转移,这个过程一直持续下去,直到当前状态是终止状态(双圆圈结点),则状态过程可以结束[8-9],如图5所示。
3.2 邻接矩阵
邻接矩阵是表示顶点之间相邻关系的矩阵,用一个二位数组存放顶点之间关系(弧)的数据,邻接矩阵分为有向图邻接矩阵和无向图邻接矩阵。
有向图邻接矩阵的特点是,矩阵中第i行非零元素的个数为第i个顶点的出度(下一个状态),第i列非零元素的个数为第i个顶点的入度(开始状态),直至遇到双圆圈的顶点时结束,用邻接矩阵表示图,很容易确定图中任意两个顶点之间是否有边(弧)相连,如表6所示。
4 实验分析
藏文音节组织结构的检错研究在精度方面已经达到一定的程度,本文主要在检错速度上做研究。选用900个常用的藏文词语对此方法进行测试,符合现代藏文音节组织结构的词语能达到实时的检错速度,以下是检错的流程。
选()字做实例讲解,邻接矩阵最左边的列为状态,最上面的行为弧(转移条件)。
⑴ 首先从S0开始,S0的下一个状态有六个,分别是S1、S2、S3、S4、S5、S6本实验所选例子第一个字母是(?)也是第一个转移条件,寻找行为S0,列为S3。
⑵ 列S3做下一个开始状态变为行S3,下一个状态有四个,分别是S15、S16、S17、S18第二个转移条件是上加字(?),行为S3,列为S17。
⑶ 以此类推最后一个转移条件是再后加字(?),行为S119,列为S131,双圆圈结束。
5 结束语
音节是构成藏文字最基本的单位,也是文本校对的依据点,藏文音节具有独特的构造方法,根据不同的组合方法构成了千变万化的现代藏文,本文以音节为研究对象,借助语法规则描述和分析了音节结构,组成成分及组合规则,采用有限状态自动机的方法对藏文音节的传统搭配规则设计了状态图和邻接矩阵,这不仅起到减小人、物力资源的作用,同时提高了文本质量和工作效率,而且书面语法规则变得更加简单直观,使得文本校对技术不断的提高,这对进一步处理藏文文本校对的研究具有重要的意义。但该方法还存在图形复杂,邻接矩阵偏长的问题,这在未来工作中仍需不断优化和改进,不断突破新技术使得文本校对在精度和速度上得到进一步改善。
参考文献(References):
[1] 陈小莹.现代藏文音节结构分析研究[J].智能计算机与应用,2019.9(2).
[2] 才智杰,才让卓玛.藏文字形结构分布研究[J].中文信息学报,2016.30(4).
[3] 边巴旺堆,卓嘎,陈延利,武强.藏文构件元素识别算法研究[J].中文信息学报,2014.28(3).
[4] 王文玲,王双成.藏文基字定位实现方法与过程[J].中国藏学,2019.4.
[5] 才让叁智,关白.基于规则的现代藏文音节字检错研究[J].西藏大学学报(自然科学版),2017.1.
[6] 色差甲,贡保才让,才让加.藏文音节拼写检查的CNN模型[J].中文信息学报,2019.33(1).
[7] 毛尔盖·桑木旦.藏文语法明悦[M].青海民族出版社,2005.[8] 俞士汶.计算语言学概论[M].商务印书馆,2003.
[9] 安见才让.藏文信息处理原理与技术实现[M].青海民族出版社,2017.
收稿日期:2020-09-02
基金项目:國家自然科学基金项目(61862054); 青海省应用基础研究项目(2019-ZJ-7066)
作者简介:更桑吉(1994-),女,藏族,青海同德人,硕士研究生,主要研究方向:藏文信息处理及应用。
通讯作者:安见才让(1969-),男,藏族,青海西宁人,教授,主要研究方向:藏文信息处理及应用。
