基于ResNet网络的东巴象形文字识别研究
2021-06-08谢裕睿董建娥
谢裕睿 董建娥


摘 要: 东巴象形文字是古代纳西族创造的文字,是世界文明的瑰宝。针对东巴象形文字传播的局限性,提出了基于图像处理和深度学习识别东巴文字的方法。文章通过构造恒等残差块和卷积残差块来搭建20层ResNet模型,采用随机梯度下降算法反向调整下一轮迭代的卷积层权值,经过训练自动得到图像相关特征参数并进行识别。实验结果表明,该算法识别东巴文字的平均准确率达93.58%,具有较高的识别精度,取得了较好的识别效果,本研究可为东巴文字的保护工作提供参考和方法支持。
关键词: 东巴象形文字; 二值化; relu激活函数; ResNet; 随机梯度下降; 特征提取
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2021)01-06-04
Research on Dongba hieroglyph recognition using ResNet network
Xie Yurui, Dong Jian'e
(College of Big Data and Intelligent Engineering, Southwest Forestry University, Kunming, Yunnan 650224, China)
Abstract: Dongba hieroglyph, created by the ancient Naxi minority, is a treasure of world civilization. In view of the limitation of Dongba hieroglyph communication, a method of recognition of Dongba characters based on image processing and deep learning is proposed. In this paper, the 20-layer ResNet model is built by constructing the identity residual block and the convolution residual block, and the convolution layer weight of the next iteration is reversely adjusted by the stochastic gradient descent algorithm. After training, image related characteristic parameters are automatically obtained and identified. The experimental results show that the average accuracy of the algorithm in identifying Dongba characters is 93.58%, which has high recognition accuracy and achieves a good recognition effect. This study can provide reference and method support for the protection of Dongba hieroglyph.
Key words: Dongba hieroglyphic; binarization; relu activation function; ResNet; stochastic gradient descent; feature extraction
0 引言
東巴象形文字在唐朝初期开始出现,主要刻在木石上,属于古老的文字体系。现如今,世界上仅有这一种象形文字仍在使用中,被誉为文字中的“活化石”。东巴文字是古代纳西族社会历史发展的缩影,具有重要的人文价值[1]。由于时代变迁、社会环境等因素的影响,现在能翻译东巴经典文学的仅有少数东巴祭司和研究学者,东巴文字的传播存在局限性[2]。因此,研究利用现代信息化技术识别东巴文字的方法具有重要的意义。
王海燕、王红军等人针对东巴文字的五个拓扑特征(孔数、块数、三叉点数、四叉点数、端点数)进行统计,结合TTF字库文件进行文字的录入和显示[3]。徐小力、蒋章雷等人结合拓扑特征与投影法,对东巴文字进行特征提取[4]。杨玉婷、康良厚等人在离散曲线演化算法的基础上,提出了适用于东巴文字特征曲线的二次简化算法[5]。目前在计算机识别领域中,对东巴文字的研究大多集中在特征提取,针对不同的数据集需要重新构造不同特征,不具有通用性。本文基于深度残差网络(Deep Residual Network,ResNet)[6],以图像处理技术为主要手段,建立了东巴象形文字识别系统。
1 数据集构造及预处理
1.1 数据集构造
由于东巴文字没有形成统一标准的数据集,本文使用的图像数据集均来自人工整理,共整理出536个单字,并进行人工标注注释,将其分为家畜、动作、植物、称谓、方位、时令、用具、形态、天文、饮食共十大种分类。在经过图像预处理后,扩充得到最终实验数据集,随机取其中的80%作为训练集,剩下的20%作为测试集。部分东巴文字数据集如图1所示。
1.2 图像预处理
在进行图像采集的过程中,由于纸张表面的磨损程度不同及光照因素的影响,导致采集得到的图像有部分干扰噪声,需要对图像进行二值化预处理,以减少孤立的黑色像素点。本文使用的方法是最大类间方差法,从最小灰度值遍历到最大灰度值,计算图像的前景和背景的灰度分布均匀方差,寻找最佳分割阈值[7]。经过二值化处理后,东巴文字字符与图片背景对比明显,消除原背景的干扰噪声,更便于后续深度学习的训练,效果如图2所示。
2 基于ResNet网络的东巴文字识别
2.1 残差模块
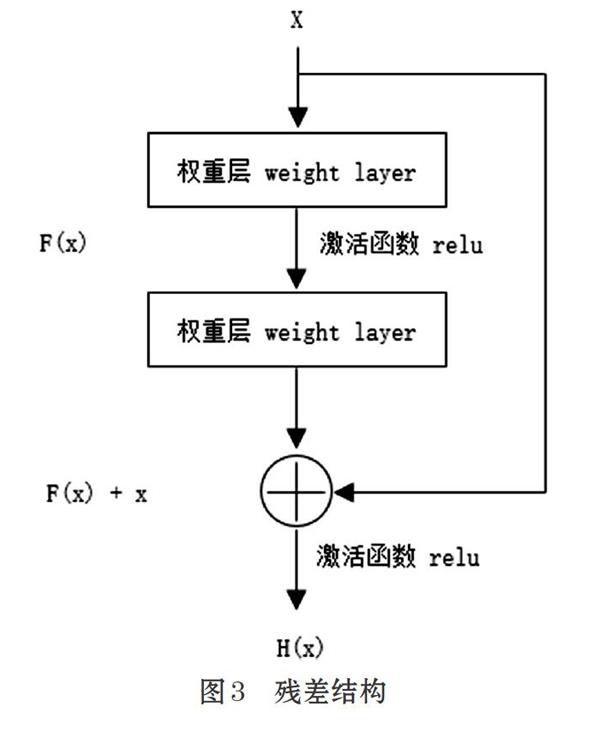
本文所采用的的深度学习算法为残差神经网络,残差(即残差单元)是指包含一个快捷连接(shortcut connection)的多层网络,网络的优化变得更容易[8]。假设x被作为初始数据直接从输入传到输出,H(x)表示预期输出,根据图3所示的残差结构可知输出H(x)=F(x)+x,那么实际学习目标F(x)=H(x)-x,F(x)表示残差映射单元。
残差模块可以分为恒等残差块与非恒等卷积残差块,在做卷积操作时,若输入数据维度与输出数据维度相同,则可以直接使用如图3所示的恒等残差块进行学习。若输入与输出数据的维度不匹配时,快捷连接上需要增加一个1*1的卷积,其作用是进行维度匹配,不参与网络层数运算。
2.2 relu激活函数
激活函数在一个感知器中起着重要作用,为了增强网络的学习能力,使用的激活函数通常是一个连续并可导的非线性函数。同时为了使得训练的效率和稳定性不受到影响,激活函数的导函数的值域要合理地控制在一个合适的区间内,不能过大或过小。常见的激活函数有:sigmoid函数、logistic函数、tanh函數、relu函数等[9],本文使用的是relu函数。
relu(Rectified Linear Unit,修正线性单元)函数,也叫rectifier函数,在当前阶段的深度学习领域使用占比最多[10]。因为ReLU函数的图像特性导致该激活函数的收敛速度比其他激活函数快得多,其在整个正无穷区间都是单调递增的线性函数,不存在梯度消失的问题。使用relu函数的网络学习速度更快,训练的时间更短,只需要一个阈值便可以得到激活值,不需要对输入进行归一化处理来防止梯度饱和。
2.3 随机梯度下降算法
为使神经网络的误差尽量小,损失函数要取到最小值,这个过程可以近似看作求取损失函数最优解的过程。对损失函数最小值的寻找方向一定是其下降幅度最大的方向,即损失函数初始点位处梯度向量的方向。在训练轮数进行不断迭代的过程中应用随机梯度下降法,得出最小化的损失函数以及训练模型的参数值,反向调整卷积核的输入权值[11]。随机梯度下降算法的相关计算公式如式⑴、⑵、⑶所示,公式的参数意义如表1所示。
[g(?)=j=0n?jj] ⑴
[h(?)=12mi=1m(yi-g?(xi))2] ⑵
[?:=?-η??h(?)] ⑶
首先给网络参数权重设置一个初始值,让损失函数向着最大变化方向更新权重。学习率取值太小会使得网络收敛速度过慢,反之会导致迭代过快而错过最小值。合适的学习率能使得网络快速收敛,并稳定找到最优解。本文经过多次实验,最后将学习率设置为0.01。
2.4 ResNet模型构建
ResNet可以解决随着网络层数加深出现的网络饱和、识别率下降的问题,在网络达到最优性能时,多余的网络层做恒等映射来解决梯度消失问题[12]。本文构建ResNet网络的层数为20层,由五大部分组成,结构组成如图4所示。
⑴ 第一部分将输入数据通过一个卷积层进行特征提取,批量归一化固定每层训练的均值和方差,从而稳定训练,激活函数通过数值优化学习网络参数,采用最大池化突出输入图像所包含的纹理特征。此时网络层数为1层,通道数为64。
⑵ 第二部分是由3个恒等残差块组成,输入和输出的维度没有变化,网络层数为6层,输出通道数仍为64。
⑶ 第三部分先经过一个卷积残差块进行升维的处理,再经过两个恒等残差块,网络层数为6层,输出通道数变为128。
⑷ 第四部分与第三部分结构相同,升维处理后通道数为256;
⑸ 第五部分使用全局平均池化,将数值平均成标量,使用局部连接提取的图像特征将在全连接层中失去原有的三维结构,被展开成一维的特征向量输出。
3 实验结果与分析
3.1 实验参数
设置初始学习率为0.01,权重衰减为0.0001、迭代次数为79次。在训练过程中,使用交叉熵作为损失函数,反向传播通过随机梯度下降算法调整下一轮迭代的卷积层权值,保存模型在此过程中性能最好的参数权重。
3.2 实验结果
通过训练验证,本文构建的ResNet模型识别准确率曲线如图5所示,损失函数曲线如图6所示。
从图5可以看出训练刚开始时识别准确率提高的很快,且验证数据集与训练数据集同步上升,随着迭代次数的加深,准确率逐渐趋近于98%。由图6损失函数曲线图可看出训练数据集和验证数据集的损失函数随着训练次数加深在逐渐变小,并逐渐趋近于0,由此可以得出:模型训练结果较为理想。获取文字标签,选择非训练数据集中的图像对训练完成的模型进行随机测试,最终输出识别结果,部分识别率统计如表2所示。
据表2中的随机测试错误样本数可知识别错误率较低,本文通过对536个单字中的94个东巴文字(共385个测试样本)进行测试,统计最终平均识别准确率为93.58%,验证了残差神经网络的良好性能。
4 结束语
本文研究了基于深度学习的东巴象形文字识别方法,描述了对东巴文字印刷体的图像预处理、残差神经网络识别的过程。与传统机器学习方法相比,本文使用的算法可以自动提取图像的特征参数,具有更客观的训练与识别过程,识别效果较好。在实际应用中,东巴文字图像复杂度高,故本研究需要继续扩大东巴文字的数据库,在东巴文字不同复杂组合等方面做进一步深入研究。
参考文献(References):
[1] 胡静.甲骨文与东巴文指事字比较研究[J].现代语文(语言研究版),2017.3:79-81
[2] 李四玉.纳西族非物质文化遗产研究综述[J].文山学院学报,2018.31(4):57-63
[3] 王海燕,王红军,徐小力.基于拓扑特征的纳西东巴文象形文字输入方法研究[J].中文信息学报,2016.30(4):106-109
[4] 徐小力,蒋章雷,吴国新等.基于拓扑特征和投影法的东巴象形文识别方法研究[J].电子测量与仪器学报,2017.31(1):150-154
[5] 杨玉婷,康厚良,廖国富.东巴象形文字特征曲线简化算法研究[J].图学学报,2019.40(4):697-703
[6] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C] //Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:770-778
[7] 刘丽霞,李宝文,王阳萍等.改进Canny边缘检测的遥感影像分割[J].计算机工程与应用,2019.55(12):54-58,180
[8] 王晓红,刘芳,麻祥才.基于深度残差学习的彩色图像去噪研究[J].包装工程,2019.40(17):235-242
[9] 安丽娜,蒋锐鹏.基于卷积神经网络的手写数字识别研究[J].无线互联科技,2019.16(20):31-32
[10] Bjarne Grimstad,Henrik Andersson. ReLU networks as surrogate models in mixed-integer linear programs[J]. Computers and Chemical Engineering,2019.131.
[11] 王功鵬,段萌,牛常勇.基于卷积神经网络的随机梯度下降算法[J].计算机工程与设计,2018.39(2):441-445,462
[12] 段祎林,马儇龙,贾端.基于ResNet验证码混淆风格的迁移学习方法[J].西安石油大学学报(自然科学版),2019.34(6):121-125
收稿日期:2020-08-25
基金项目:云南省农业基础研究联合专项青年项目(2018FG001-101);云南省农业基础研究联合专项青年项目(2017FG001-074)
作者简介:谢裕睿(1998-),女,江苏淮安人,本科生,主要研究方向:图像处理。
通讯作者:董建娥(1983-),女,陕西汉中人,硕士,讲师,主要研究方向:信息安全、信号与信息处理。
