科技评价指标权重分类及对评价的影响研究
2021-06-07曾强俞立平
曾强 俞立平


关键词:科技评价;自然权重;数据分布权重;非线性评价;线性评价
在科技评价中,人们往往都比较重视权重问题。通常意义上的权重是根据主观或客观评价方法确定的设计权重.而对于隐含在科技评价指标中的权重问题较少关注。如南京大学CSSCI期刊引文评价.采用他引影响因子和总被引频次两个指标进行评价,权重分别为0.8和0.2,假设暂不考虑评价赋权,两个指标是等权重相加,数据经过标准化处理后,两个指标的极大值都是100,但是均值并不相等。比如他引影响因子的平均分数为80,总被引频次的平均分为40,那么在实际评价中,他引影响因子明显占据比较重要的地位。或者说,从指标数据角度,他引影响因子的实际权重就是0.667.而总被引频次的实际权重就是0.333.这种由于指标均值差异带来的权重称为自然权重。
以上例子是对于线性评价方法而言,其实在非线性评价中,指标隐含权重问题更为复杂。非线性评价方法的特点是评价指标与评价结果之间并非简单的线性关系,其种类繁多,原理各不相同,比如主成分分析、因子分析、TOPSIS、VIKOR、ELEC.TRE、灰色关联、DEA效率分析等。为了简捷起见,暂不考虑非线性评价中赋权问题,也就是说假定非线性评价都是等权重。那么,即使在这种情况下,指标权重真的相等吗?俞立平等针对这个问题提出了模拟权重的概念.就是对于非线性评价方法,将评价得分与评价指标进行回归,回归系数大小实际上就反映了各指标的重要性,将其归一化处理就是模拟权重,或者称为实际权重。很明显即使在不赋权的情况下,非线性评价方法各指标的实际权重也不可能相等.其原因有待深入研究,隐含在科技评价指标中的数据权重问题非常复杂。
在科技评价中.评价指标权重特性对评价产生着较大影响。指标权重特性既包括了标准化后指标数据均值不同带来的影响.也包括指标数据分布带来的影响。其中指标均值不同带来的自然权重某种程度上是可以通过优化数据标准化方法进行修正,在排除自然权重后,剩下的就是指标数据分布对权重的影响。研究评价指标权重特性对线性评价与非线性评价的影响,分析其作用机制,找到消除自然权重的数据标准化方法.进一步总结指标数据分布对实际权重的影响特点和影响大小,不仅可以丰富科技评价方法和技术,减少评价系统误差,提高评价质量,在实践上也有利于保证评价的公平、公正,提高评价的公信力。
关于指标数据与权重的关系.学术界从权重与评价方法角度进行了一些研究。邱东认为当采用乘法合成时,权重作用不如加法合成时明显。覃森等在复杂网络研究中.采用分配常数的边权重、服从指数分布的边权重、节点度乘积函数的边权重3种权重方式.从静态与动态加权视角研究了加权网络强度分布的不同特性。张耀天等提出自适应层次分析法,能够根据被评价对象在科研评价指标上的数据分布特征,对评价指标的权重进行动态调整.从而在评价过程中充分体现稀缺性指标的导向作用,实现更为合理的绩效分配。周杨等设计了一种基于自适应权重的粗糙K均值聚类算法.基于自适应权重的粗糙聚类算法在每一次迭代过程中,根据当前的数据划分状态,动态计算每个样本对于类的权重,降低了原有算法对初始权重的依赖。郭亚军研究了动态综合评价中权重与时序数据的“隐式”关系。
关于指标数据分布与评价的关系,Glanzel w、Bornmann L等认为用算术平均值来反映引文的非正态分布的集中趋势是不合适的.可能歪曲数据的真实分布。Raan V指出过去按照个人经验,将引文数据看作一个单一平均值的做法,使得評价结果远高于或低于国际引文影响标准。Seglen PO发现引文分析数据具有幂律分布特征,属于典型的偏态分布。Adler R等也发现引用数据分布是右偏的,服从幂律法则。胡永宏认为权重发挥作用的大小还取决于评价指标之间相关性的大小以及后面合成所采用的方法.当指标之间相关性较大时,权数几乎不起什么作用。肖峻等研究了AHP权重的概率分布规律,当判断矩阵元素为平均分布和正态分布时,所求得的权重均为正态分布。俞立平等认为指标数据偏倚会影响评价指标的数据标准化.指标数据右偏会导致期刊评价值偏低,最好选取数据偏倚情况相对较好的指标来评价期刊平均水平。
从现有的研究看,学术界关于权重问题的相关研究.更多集中在权重确定方法与评价方法中涉及的一些赋权问题,关于指标数据分布对评价的影响,也有少量的研究。在多元统计的早期研究中,由于评价指标均值不同产生的自然权重思想有所涉及,但并没有进行进一步研究,总体上,关于评价指标数据的权重特性问题学术界尚缺乏研究,在以下几个方面有待深入:
第一,指标数据对权重的影响有几种类型?它们对线性评价与非线性评价会产生何种影响?其影响规律与影响特征如何?
第二,如何对由于指标均值不同导致的自然权重进行修正?
第三,如何对指标数据分布对实际权重的影响大小进行评估?这种评估对于评价方法选择有什么意义?
本文在理论分析的基础上,以JCR2016数学期刊评价为例,评价方法除了线性评价外,还选取主成分分析与TOPSIS两种非线性评价方法,并提出一种消除自然权重的数据标准化方法,在自然权重消除前后进行比较,最后得出结论并进行讨论。
1指标权重特性分析
1.1指标权重的分类
第一,设计权重。也称为传统权重,就是评价时为了管理的需要,通过主观、客观或主客观结合的方法确定的权重。传统权重体现了评价为管理服务,体现了评价主体的主观或客观要求。至于在实际评价中传统权重有没有得到很好的体现,体现的程度如何,是个非常复杂的问题。在评价技术层面,努力在评价结果中实现设计权重是重要目标之一。
第二,实际权重。也称为模拟权重,在非线性评价中表现尤为突出。根据俞立平等提出的回归模拟权重估计法,用评价结果作为因变量,评价指标作为自变量进行回归,为了防止多重共线性的影响,回归方法可能要用岭回归或偏最二乘法,回归系数经标准化处理后就是评价指标的实际权重,它是真正发挥作用的权重。
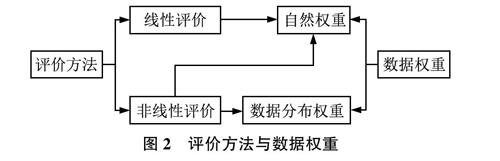
第三,自然权重。这是由于指标标准化后均值不相等引起的,均值越大的指标,在线性评价中的隐含权重越高,自然权重越大。当然自然权重是可以测度的,其测度方法就是计算标准化后各指标均值占所有均值的比重。如果通过某种标准化方法,使得各指标均值相等,那么自然权重是可以消除的。自然权重问题是隐含的,而且没有得到应有的重视,在实际评价中,自然权重问题是普遍存在的。
第四,数据分布权重。数据分布权重是一种隐含权重,在非线性评价中表现突出。在等权重非线性评价时,即使解决了自然权重问题,那么通过回归得到的模拟权重一般也不相等.产生的原因是评价指标数据分布引起的.这里将其称为数据分布权重。不过指标数据分布权重难以测量,因为情况太复杂了,一切取决于各指标的数据分布,它的存在影响实际权重。数据分布权重是不可以消除的,或者说不能消除,因为改变原始指标的数据分布会严重影响评价结果,导致评价偏倚,何况会破坏原始数据包含的大量信息。当然,除非不采用非线性评价方法评价,这是解决数据分布权重的终极方法。
界定以上4种权重后可以发现.通常情况下,实际权重受设计权重、自然权重与数据分布权重的影响,为了进一步分析可以采取逐步排除法,首先通过等权重方法消除设计权重的影响,在进一步消除自然权重后,实际权重就是数据分布权重。
1.2指标权重与评价方法
为了使研究得到简化,暂不考虑设计权重,在此假设下分析自然权重、数据分布权重与评价方法之间的关系。
多属性评价方法大致可以分为线性评价与非线性评价两大类.所谓线性评价,就是传统的加权汇总类评价方法,如专家赋权法、熵权法、概率权法等;所谓非线性评价,就是采用一定的评价模型进行评价,评价指标与评价值之间是非线性关系,如因子分析、TOPSIS、VIKOR、灰色关联等。在线性评价中,只有自然权重会对评价产生影响,而在非线性评价中.自然权重和数据分布权重会同时产生影响。
如果采取某种方法能够消除自然权重,那么非线性评价方法中,就可以单独评估数据分布权重产生的影响,并对这种影响大小进行综合评估。
需要说明的是,传统意义上的评价赋权(设计权重)无论在线性评价与非线性评价中均占据重要地位,只有部分非线性评价方法不需要赋权。为了简化起见,同时也是为了研究更加深入,本文暂不考虑传统权重(设计权重)对指标权重的影响,也就是说,无论是线性评价还是非线性评价,均采用等权重进行,这样可以更好地評估自然权重与数据分布权重的作用及其规律,以及对最终实际权重的影响。
2研究方法与数据
2.1实际权重的测度——偏最小二乘法
评价指标之间往往相关性较高,这样在回归时会产生多重共线性.所以采用传统的最小二乘法进行回归往往是不可以的。偏最小二乘法(PartialLeast Squares,PLS)是Wold S等提出的.它结合了多元回归、主成分分析、典型相关分析优点,采用信息综合与筛选技术,特别适用于解释变量存在多重共线性、数据数量过少等问题,一般认为比主成分回归、岭回归解决多重共线性更好。
2.2自然权重的消除一动态最大均值逼近标准化
在科技评价中,由于评价指标数据特性,使得即使标准化后各指标的均值也不相等,从而带来自然权重问题,本文提出动态最大均值逼近标准化方法,如图3所示,试图进行修正,主要步骤如下:
第一,确定评价目的、评价原则,选择评价指标,这里有个基本前提.就是所有评价指标都是结构化数据,不存在半结构化和非结构化数据。
第二,对所有评价指标进行标准化,其方法是所有正向指标除以极大值然后乘以100(以百分制为例),所有反向指标用极大值减去该指标先转为正向指标,然后视同正向指标再做一次标准化。接着计算各指标标准化后的均值,并找到最大均值K。
动态最大均值逼近标准化方法有4个特点:第一,需要循环标准化多次,是动态的;第二,理论上标准化后指标的均值绝对相等,但极大值会大于100,永远不可能等于100。理论上它可以无限逼近第一步的极大值,但永远也无法达到;第三,这是线性标准化方法.不会破坏原始指标的数据分布特征,能保留原始指标的大量信息;第四,容易实现,借助计算机编程,可以非常方便地进行处理。
下面对动态最大均值逼近标准化方法中,每循环一次均值就会增加进行证明。进行二次标准化前,需要增加均值:
本文选择主成分分析与TOPSIS两种比较常用的非线性评价方法为例来进行研究,之所以选择两种评价方法,是为了提高研究的稳健性,避免单一评价方法研究可能产生的偏倚。此外,主成分分析一般不要给指标赋权.是不加权非线性评价方法的代表,TOPSIS评价方法可以加权,是加权非线性评价方法的代表。当然,本文重点研究评价指标数据的权重特性.为了减少来自评价赋权的影响,TOPSIS评价也不进行赋权,即均不考虑设计权重问题。
2.4研究数据
本文以JCR2016数学期刊为例,选取8个评价指标为例来进行说明,分别是:总被引频次、影响因子、他引影响因子、影响因子百分位、5年影响因子、特征因子、论文影响分值、即年指标。JCR2016数学期刊共有期刊310种.删除了部分数据缺失期刊,最后还有294种期刊,指标标准化后数据的描述统计如表1所示。
从标准化后指标均值相差很大,最大的是影响因子百分位47.073,最小的是总被引频次7.252。从Jaque-Bera正态分布检验看.所有指标均不服从正态分布。所以选择JCR2016数学期刊来研究评价指标的权重特性具有代表性,是比较好的样本。
3
实证结果
3.1线性评价中数据权重特点
首先对表1中的除了影响因子百分位外的其他7个指标.采用动态最大均值逼近标准化方法进行处理,以消除自然权重的影响,经标准化后,数据的描述统计量如表2所示。
影响因子百分位因其均值最大无需做消除自然权重处理,除该指标外,其余所有指标的极大值均超过100,但小于101,即在最大许可阈值范围内。离散系数也有所减小,但是偏度和峰度变化不大,偏度和峰度值也非常接近.正态分布检验结果相同,均没有通过正态分布。说明动态最大均值逼近标准化方法能够消除自然权重,降低指标数据波动程度,但并没有改变指标数据分布。
为了分析消除自然权重后评价结果的差异,假设采取等权重法进行线性加权汇总,结果如表3所示,由于篇幅所限,本文仅公布消除自然权重后前30种期刊的评价结果对比。消除自然权重后,所有期刊评价值的均值为47.07.即原来标准化后的最大均值,要比消除自然权重前的评价均值17.30大。从评价结果排序看,消除自然权重前后排序相差较大,说明自然权重对线性评价结果影响较大,可见如果不考虑自然权重问题,评价结果相差很大,造成较大的评价系统误差。
3.2主成分分析消除自然权重前后比较
首先采用原始标准化数据进行主成分分析评价,其KMO检验值为0.816,Bartlett检验值为3507.662,相伴概率为0.000,说明适合进行主成分分析。第一主成分方差贡献率为67.82%,第二主成分方差贡献率为16.86,合计84.68%,采用方差贡献率加权汇总,得到评价值,然后以评价值为因变量.评价指标为自变量,采用偏最小二乘法进行回归,结果如表4所示。
类似地,采用消除自然权重后的评价指标进行主成分评价,其KMO检验值为0.862,Bartlett检验值为3328.847,相伴概率为0.000,说明适合进行主成分分析。第一主成分方差贡献率为67.20%,第二主成分方差贡献率为16.99,合计84.19%。以上各参数和消除自然权重前比较接近,说明消除自然权重对这些参数影响不大。继续采用方差贡献率加权汇总,得到评价值,然后以评价值为因变量.评价指标为自变量,采用偏最小二成法进行回归,结果如表5所示。
由于无论消除自然权重与否,均采用两个主成分进行分析,因此偏最小二乘法的回归系数取潜在主成分数量为2的结果.将其归一化处理后得到消除自然权重前后的实际权重.并进行比较.结果如表6所示。
无论自然权重是否消除,主成分分析的实际权重结果基本类似,8个指标权重绝对变化平均值为1.014%,排序也基本相同,只是消除自然权重后总被引频次与影响因子百分位的排序有微小变化。这充分说明,决定主成分分析实际权重的是数据分布,而自然权重消除与否对其影响不大。
需要说明的是,消除自然权重后由于实际权重毕竟发生了微小的变化.因此对评价结果排序肯定会产生一定的影响,限于篇幅不一一公布了。
3.3 TOPSIS消除自然权重前后的比较
同样首先将原始指標标准化后采用TOPSIS法进行评价,然后将评价结果作为因变量,评价指标作为自变量,采用偏最小二乘法进行回归,结果如表7所示。
同样消除自然权重后采用TOPSIS法进行评价,然后将评价结果作为因变量.评价指标作为自变量,采用偏最小二乘法进行回归,结果如表8所示。
同样取潜在因子为2的偏最小二乘法回归结果进行实际权重的比较分析,结果如表9所示。无论是否消除自然权重.TOPSIS相同指标的实际权重大小虽然有所差别,8个指标绝对权重变化6.131%.但是消除自然权重前后权重大小排序的次序相同,同样说明决定TOPSIS实际权重的是数据分布,而不是自然权重。
需要说明的是,消除自然权重后由于实际权重毕竟发生了较大变化,因此对评价结果排序肯定会产生影响,限于篇幅不一一公布了。
3.4主成分分析与TOPSIS实际权重的比较
为了比较不同评价方法对实际权重的影响,将消除自然权重后主成分分析与TOPSIS的实际权重结果进行横向比较,结果如表10所示。在都消除自然权重后,主成分分析与TOPSIS相同指标的实际权重还有差异,8个指标平均权重变化为14.166%.这是非线性评价方法不同带来的影响。至于两者权重大小排序也比较接近.这难以从理论上加以证明,有待进一步研究。
4结论与讨论
4.1科技评价指标具有隐含权重特性
在科技评价中,由于标准化以后不同指标的均值不等,导致评价指标数据天生就具有自然权重,自然权重是可以测度和消除的。此外不同指标由于数据分布不同也具有数据分布权重,它不可以测度。自然权重与数据分布权重一起.对评价产生隐含的影响,可能会导致评价结果偏离管理需求,产生误差。此外,实际权重也是一种隐含权重,它是非线性评价中各指标重要性的真实体现,实际权重受设计权重、自然权重、数据分布权重的综合影响。
4.2动态最大均值标准化方法能够消除自然权重
本文提出的动态最大均值标准化方法通过多次标准化逼近的原理,使得标准化后指标的均值相等,极大值控制在允许的阈值范围内。由于是一种线性变换,因此不会改变原指标的数据分布,可以保留原始数据中蕴含的大量信息.同时降低了评价指标的离散系数,因此是一种较好的消除自然权重的方法。
4.3自然权重影响线性评价结果
在线性加权汇总评价中,由于自然权重的存在,它会影响评价结果.并且标准化后评价指标的均值相差越大,它对评价结果的影响越大,必须进行消除,以提高评价的精确性。数据分布对线性评价没有影响,因为评价时不存在非线性运算。
4.4数据分布权重对非线性评价影响较大
本文通过主成分分析和TOPSIS评价的实际权重比较表明,数据分布权重是影响非线性评价实际权重的主要因素,自然权重对非线性评价的实际权重影响较小。不同非线性评价方法也会影响实际权重,至于具体的影响特征.可以根据本文的方法进行进一步的研究。
4.5数据分布权重对评价方法的选择具有深远的影响
在消除自然权重后,决定非线性评价结果的主要是数据分布权重和评价方法.数据分布权重一般是不宜消除的,因为会破坏原始指标中的大量信息,在这种情况下,如果某种评价方法的实际权重中,由于数据分布的影响,导致不同指标的权重相差较大,此时就要冷静分析是否应该选取这种评价方法,要看权重大小是否符合管理实际,是否符合评价目的。而线性评价方法在消除自然权重后,反而没有相关问题,从这个角度,线性评价方法更为合理。
4.6设计权重与实际权重力求一致是选择评价方法的重要依据
设计权重体现了评价目的和管理要求,而实际权重是检验具体评价是否达到设计权重的重要手段。由于数据分布权重对线性评价方法没有影响,在消除自然权重后,线性评价的设计权重和实际权重完全一致,从这个角度,线性评价方法具有天然的优势。
