基于轻量级模型的隧道岩性快速识别方法
2021-06-06夏毅敏李清友邓朝辉
夏毅敏 ,李清友 ,邓朝辉 ,龙 斌 ,姚 捷
(1. 中南大学高性能复杂制造国家重点实验室,湖南 长沙 410083;2. 中南大学机电工程学院,湖南 长沙 410083;3. 中铁第四勘察设计院集团有限公司,湖北 武汉 430063;4. 中国铁建重工集团股份有限公司,湖南 长沙 410100)
随着山区地下工程[1]的发展,隧道施工过程中精准、快速地进行岩性识别可以为采用正确围岩支护[2]方式减少时间消耗,避免造成隧道塌方,是施工安全方面关注的重点. 目前施工现场依据现场施工人员经验、实验室力学实验、理论分析与现场声波测试等方法对围岩特性进行检测识别[3],其中岩石岩性是支护时机与支护方法选取的影响因素之一[4],因此,有必要对岩石岩性快速准确的识别方法开展研究.
目前,学者们针对岩石特征的提取方法开展了大量研究,其中采用图像处理技术提取隧道岩石表面特征的方法被大量应用:Wei等[5]提出了一种将K均值聚类与概率神经网络相结合的方法应用于岩石薄片图像中,实现岩石孔隙纹理识别自动化;罗佳等[6]利用裂缝具有方向性与连续性等特征,提出了一种基于自适用阈值和连通域标记的隧道裂缝提取方法;刘烨等[7]提出一种结合图像颜色空间与形态学梯度进行岩石自动分类方法.
近些年来,随着卷积神经网络在图像识别领域的使用[8],深度学习的优越性也逐渐体现,其利用多层网络处理数据从而达到提取特征的目的[9]. 在语义识别、图像识别[10]、物体检测等方面,深度学习识别模型都得到广泛应用:侯进等[11]提出一种基于深度学习的多特征复合神经网络框架. 基于深度学习进行岩石图像自动识别的研究越来越多:白林等[12]基于卷积神经网络构建岩石识别深度学习模型,有效提取岩石的矿物成分特征,说明了深度学习方法对于岩石识别的有效性;徐述腾等[13]设计有针对性的Unet卷积神经网络模型,提取了矿相显微镜下矿石矿物的深层特征信息,实现镜下矿石矿物智能识别与分类;Imamverdiyev等[14]通过研究岩石的岩性特征,开发一种基于深度学习的井中地质相分类的有效模型来进行岩相分类;Zhang等[15]采用了5种方法对含有12个标签的2206张地质图片进行了识别对比,表明基于深度学习模型的迁移学习方法可以有效地提取小地质结构数据的特征,在地质结构图像分类中具有较强的鲁棒性;结合深度学习模型与迁移学习方法[16]能够在保证准确度与速度的情况下大幅度减小研究难度[17],使用迁移学习方法扩大了图像识别的应用领域,张野等[18]将迁移学习应用于岩石图像的自动岩性识别和分类,并有效识别了花岗岩、千枚岩和角砾岩;Li等[19]通过迁移学习训练了砂岩的显微图像,并获得了砂岩薄切片的高精度显微图像分类模型;Wang等[20]采用模型迁移方法实现了对野外岩石图像的识别与分类.
本文以隧道中常见的片麻岩、花岗岩、石灰岩、大理岩、凝灰岩、砂岩等6类主要岩石为研究对象组建图像数据集,基于轻量级深度卷积神经网络模型MobileNet V2[21]进行改进,采用模型迁移学习训练方法,得到一种适用于隧道岩石岩性识别模型,具有识别速度快、模型小等特点,能在离线条件下对施工过程中采集到的岩石图像进行岩性快速识别.
1 卷积结构与迁移方法
1.1 深度可分离式卷积
深度卷积神经网络模型的核心卷积结构在图像特征提取能力上具有强大的优势,为了提高识别精度,深度卷积神经网络模型的结构设计总体往更深、更宽的趋势发展,随着模型深度与宽度的扩增,模型参数与体积也大幅度地提升. 在隧道施工中,为了满足离线条件下有限资源的移动端设备中使用深度神经网络模型对岩石岩性进行识别,必须优化网络结构,降低网络参数量以减少对计算和存储资源的占用,深度可分离式卷积[22](depthwise separable convolution)结构能够在保证精度的情况下大幅度降低卷积计算参数量.
深度可分离式卷积结构将标准的卷积网络分解成深度卷积和逐点卷积,深度卷积将滤波器(卷积核组)应用于每个输入通道,使用大小为1 × 1的卷积核进行逐点卷积来组合深度卷积的输出.
假设模型输入图片尺寸为Dk×Dk,通道数为M,输出通道数为N,采用尺寸大小为Df×Df的卷积核进行卷积,如图1所示为标准卷积结构,参数计算量为Lt,经计算可得

如图2所示为深度可分离式卷积结构,参数计算量分为两部分,深度卷积Ld与逐点卷积Lp,经计算可得

两部分参数计算量进行求和可得深度分离式卷积结构的参数计算量为


图1 标准卷积结构Fig. 1 Standard convolution structure

图2 深度可分离式卷积结构Fig. 2 Structure of depthwise separable convolution
将标准卷积与深度可分离式卷积的参数计算量比较可得

由于图片尺寸Dk×Dk远大于输出通道数N,可近似认为深度可分离式卷积结构相比标准卷积结构参数计算量减少了N倍.
1.2 迁移学习方法
传统的机器学习模式如图3(a)所示,给定的不同任务之间具有相似性情况下,也必须针对不同的任务建立相应的学习系统,迁移学习模式如图3(b)所示,学习系统将从源任务中学习到的知识迁移到目标任务的学习系统中,极大地减轻了模型训练难度,并发挥了不同数据之间的相似性[23]. 在实际深度神经网络模型训练中,由于大量隧道岩石数据的收集与标定难度、硬件设施条件等问题,使得无法从零开始训练岩石岩性识别模型,通过使用模型迁移训练方法,对MobileNet V2模型进行改进,并在所建岩石数据集上进行训练,得到适用于隧道岩石数据集的识别模型.

图3 传统学习与迁移学习Fig. 3 Traditional learning and transfer learning
2 模型训练与识别方法
图4是识别模型训练与识别过程的整体框架,首先,准备隧道岩石数据集,并在训练前进行数据增广处理;其次,改进预先训练过的基础模型,并在岩石数据集上进行迁移训练,得到岩石识别模型;最后,加载识别模型,对未参与训练的测试图像数据进行识别,得到识别结果. 该方法突出了基于轻量级网络模型MobileNet V2进行改进后并训练得到岩石识别模型,以及完成岩石识别的各个过程.

图4 模型训练与识别流程Fig. 4 Model training and identification process
2.1 岩石图像数据集及预处理
基于课题组在隧道施工工程方面的研究基础,前往多个隧道工程进行实地调研与现场拍摄取材,对隧道围岩主要岩石类型花岗岩、片麻岩、大理岩、凝灰岩、砂岩、石灰岩的图像样本共采集1860张,为了避免训练过程中出现样本不均衡现象,每种岩石类型样本数量上保持一致性,为310张,确保样本数量均衡,其中每类岩石训练集为195张,验证集65张,测试集50张,样本分布均为随机抽取分布.
实验中为提高模型训练效果,在训练前采用图像旋转、水平偏移、竖直偏移、图像剪切、图像缩放、翻转等处理方式进行了数据增强,同时对每张图像样本的像素值除以自身标准差以完成样本标准化,原始数据图像大小都在5 MB以下,部分样本图像如图5所示.

图5 岩石样本图像示例Fig. 5 Rock sample image examples
2.2 基于特征提取的迁移训练方法
岩石类图像数据集与大型数据集相比,类之间的差异性较小,岩石岩性识别是岩石细粒度分类的一个实例. 在本文岩石识别分类研究中,以轻量级网络模型MobileNet V2为基础模型,模型结构如表1所示,主要包括17个可分离式卷积模块,结构如图6所示,首先通过逐点卷积提升输入数据维度,减少数据丢失,之后进行深度可分离式卷积,最后采用逐点卷积进行数据降维输出,同时使用残差网络[24]处理,减少卷积过程中梯度消失问题,并在每次卷积后都进行了归一化与激活处理,整个卷积过程数据维度呈现中间宽,两端窄的形式,用较少的计算量得到较好的性能.

表 1 MobileNet V2基础结构Tab. 1 MobileNet V2 basic structure

图6 MobileNet V2深度可分离式卷积结构Fig. 6 MobileNet V2 depthwise separable convolution structure
基础模型在ImageNet数据集上进行预训练得到了预训练权重后,移除可分离式卷积模块后密集连接分类器部分,根据岩石数据集种类搭建新的密集连接分类器进行代替,改进的模型结构如表2所示.
表2中,虚线框内为新建分类器,添加了输出维度为1024的Dense层与Relu激活函数fRelu(•),其函数表达式如式(6)所示,具有使数据收敛快的优点. 并在Dense层之后添加了Dropout层,设置参数为0.5,意味着在训练过程中每次进行参数更新时会随机关闭50%的神经元,使得一个神经元的出现不依赖另一个神经元,防止数据过拟合,提高模型泛化能力. 最后添加一个输出维度为6的Dense层与Softmax分类函数,让输出结果类别与实际数据集类别相统一.

式中:x为模型上一层参数的计算输出值.

表2 改进的模型结构Tab. 2 Improved model structure
训练过程中以本文研究的岩石数据为模型输入,基础模型其他所有层进行冻结不参与训练,仅作为特征提取器对输入图像进行特征提取,并将提取的特征作为新密集连接分类器的输入,迭代次数设置为10,优化函数采用随机梯度下降法,学习率为0.001,每次迭代随机选择32张图像,每迭代36步进行模型评估,通过交叉熵验证损失,同时在训练过程中对精度进行监测,先通过特征提取的迁移训练,训练分类器部分的参数权重,使基础模型适应新的岩石数据集. 训练过程在存储容量为24 GB的NVIDIA Quadro P6000显卡上进行,单步训练时间为3 s.
2.3 基于fine-tune的迁移训练方法
基于fine-tune的迁移训练方法在模型结构上与特征提取的训练方法一致,但参与训练的层数更多,如表3中虚线框所示. 在本文研究中,在对新建密集分类器参数进行训练后,为了提取不同岩石的类别特征,开放基础模型的bottleneck17部分,并在训练过程中对学习率(learning rate)、批样本数量(batch size)、优化器参数、权重衰减系数等超参数进行选择与微调,根据训练效果对比,迭代次数设置为1000,一个迭代循环训练36次,采用随机梯度下降法,学习率降低至0.0001,衰减系数为10−6,动量参数设置为0.9,每次迭代随机选择32张样本数量,每迭代36步进行模型评估,通过交叉熵验证损失,同时在训练过程中对精度进行监测,训练结束后获得岩石岩性识别模型.

表3 基于fine-tune的迁移训练Tab. 3 Transfer training based on fine-tune
3 识别结果分析与讨论
3.1 训练集识别结果分析
图7显示了训练过程中1000次迭代中的损失和精度变化趋势. 损失在400次迭代后开始收敛,并在800次迭代后开始稳定,损失接近于0,训练精度在200次迭代后开始收敛,在迭代600次后呈现稳定状态,接近99%,验证数据集精度在82%~87%波动,训练结果模型大小仅为28.3 MB.

图7 训练中训练精度、验证精度及损失变化Fig. 7 Training accuracy,verification accuracy and loss changes during training
为了验证训练模型的鲁棒性及性能,在训练数据集中对每类岩石随机选取30张图片共180张图片作为测试对象,每次从中挑选30张,共测试6次,同时采用精确率(P)、召回率(R)、综合评价指标(F1)作为测试结果评估指标对各类岩石识别情况进行评估,计算方法如式(7)~(9).

式中:Tp为属于某类岩石同时识别为该类岩石的样本数量;Fp为不属于某类岩石同时识别为该类岩石的样本数量;Fn为属于某类岩石同时未识别为该类岩石的样本数量.
各项评价指标计算结果如表4所示,训练集每类岩石图片识别结果中各项评价指标都达到了93%以上,均值都达到97%以上,说明模型具有很好的鲁棒性.
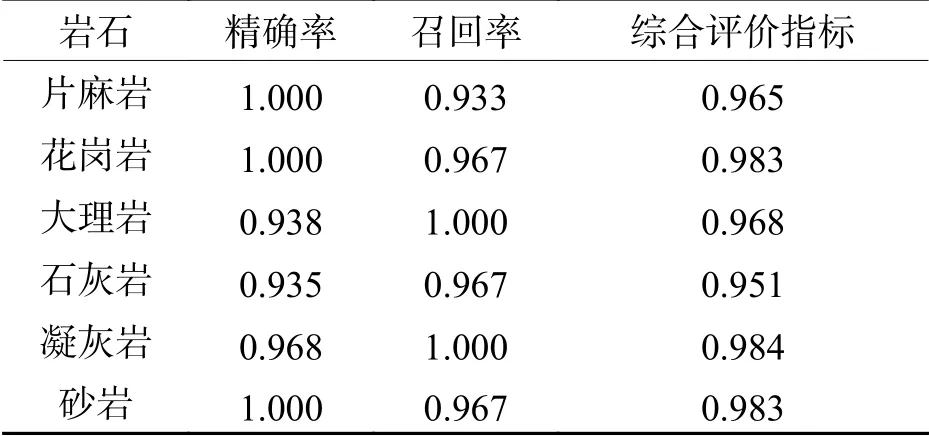
表 4 训练集各项评价指标Tab. 4 Index values for training set evaluation
3.2 测试集识别结果分析
训练过程中验证集的精度在82%到87%之间波动,为了更好地验证模型的泛化能力,使用未参与模型训练的测试数据集中的图片样本来进行测试,即测试模型对全新的图像是否具有良好的识别能力,测试集样本数量每类岩石各50张,识别结果如表5所示,为了更全面地评估测试集识别结果,对精确率、召回率与综合评价指标等参数进行计算,结果如表6所示.
根据表中数据,片麻岩、石灰岩、砂岩3类岩石的精确率与召回率呈现相反的趋势,说明在所有正负样本数据中,模型对砂岩正样本的识别准确程度高,对石灰岩与大理岩的正样本识别准确程度低,凝灰岩岩与大理岩的召回率较高,说明模型能够对实际为正样本的凝灰岩、大理岩识别为正样本的概率高. 为了能综合评估模型对各类岩石的识别效果,得出综合评价指标值,明显得出凝灰岩识别效果最佳,大理岩、花岗岩识别效果好,石灰岩识别效果最低.

表5 测试集图片识别结果Tab. 5 Recognition results for testing set images 张

表 6 测试集各项评价指标Tab. 6 Index values for testing set evaluation
虽然对各个类别的精确率、召回率与综合评价指标进行了测试计算,但由于本文分类类别属于多分类,因此采用机器学习理论中的宏平均(macroaverage)作为总体评估指标对测试结果进行评估. 宏平均是先对每一个类别计算指标值,然后再对所有类求算数平均值,计算如式(10)~(12).

式中:Pi、Ri、F1i和Pmacro、Rmacro、F1macro分别为精确率、召回率、综合评价指标的类别值和宏平均值.
根据表6结果,由式(10)~(12)计算得精确率、召回率、综合评价指标的宏平均值分别为0.868、0.853、0.853.
整体来看,模型对测试集识别结果各项评估参数均值均在85%以上,说明模型具有较好的泛化能力,对实际围岩类岩石图像具有极好的识别能力.
3.3 不同分类方法对比分析
为了验证采用轻量级深度卷积神经网络模型进行岩性识别分类方法的优势,采用卷积神经网络VGG16模型和机器学习方法中SVM (support vector machine)分类模型[25]对相同岩石数据集进行识别分类,以平均识别精度与单张识别时间为对比指标,实验结果比较如表7所示.

表7 实验结果对比Tab. 7 Comparison of experimental results
经对比测试可知,SVM模型平均识别精确率低于0.8. 此外,相比于SVM模型,改进的MobileNet V2模型无需进行单独的图像预处理与特征提取,将图像特征提取与识别分类集为一体,提高了识别精确率,降低了模型训练难度与时间. 相比于卷积神经网络模型VGG16,改进的MobileNet V2模型在保持模型性能的前提下降低了模型训练参数,提高了模型识别速度. 因此与传统机器学习分类模型和卷积神经网络模型相比,改进的MobileNet V2模型,同时采用模型迁移学习进行训练的方法有更高的识别精确率与更快的识别速度.
4 结 论
针对隧道施工过程中岩石岩性的准确、快速识别问题,基于轻量级深度卷积神经网络模型进行改进并采用模型迁移训练方法进行识别分类,得到以下结论:
1) 基于自身搭建的隧道岩石图像数据集,通过改进的轻量级深度卷积神经网络模型分类器,采用模型迁移训练方法能够解决隧道岩石岩性识别问题.
2) 改进轻量级深度卷积神经网络模型,同时采用模型迁移学习进行训练的方法在识别速率与识别精度上比传统卷积神经网络与传统机器学习分类方法效果更优.
3) 模型识别精度与岩石图像数据集自身特征具有关联性,对于特征明显易于分辨的凝灰岩、花岗岩、大理岩等识别效果更好.
致谢:感谢长沙市科技计划重大专项(kq1703022)与中南大学研究生自主创新项目(2018zzts459)的经费支持.
