CNN-LSTM深度神经网络在滚动轴承故障诊断中的应用
2021-06-04陈保家陈学力沈保明陈法法李公法肖文荣肖能齐
陈保家,陈学力,沈保明,陈法法,李公法,肖文荣,肖能齐
(1.三峡大学水电机械设备设计与维护湖北省重点试验室,443002,宜昌;2.武汉科技大学冶金装备及其控制教育部重点试验室,430081,武汉)
滚动轴承故障响应信号往往表现为非平稳性、非线性、强耦合的特点,常规轴承故障诊断技术主要采用时频信号处理方法[1-3],如傅里叶变换,小波变换,经验模式分解(EMD)等,对故障信号进行故障特征提取,再利用分类模型对故障类型进行模式识别。郑近德等提出了一种改进的EMD故障诊断方法,通过广义经验模态分解定义多种均值曲线,采用改进的经验调幅调频分解和直接正交解调方法对最优本征模式分量(IMF)信号进行解调,抑制端点效应的产生[4]。Chen等提出融合遗传算法品质因子参数优化、子带重构共振稀疏分解和小波变换的故障诊断方法,深度挖掘轴承故障信息,凸显早期微弱故障[5]。常规的故障诊断研究多禁锢于先提取特征,后分类评估的固有模式,割裂了二者之间的联系,而特征提取往往需要依靠人工经验,缺乏科学指导,其诊断的准确率还有待进一步提高[6]。现代机械装备在长期服役过程中,其状态监测数据呈现出典型的体量浩大、多源异构、生成快速、价值稀疏的大数据4V特征[7]。面对工业大数据背景下的特征信息提取,依赖人工经验的诊断方法则力有未逮,亟需研发能从大数据自适应提取故障特征信息的技术方法。
深度学习理论以其强大的建模与数据处理能力,在数据处理方面具有独特的优势[8-9]。Chen等采用深度玻尔兹曼机(DBM)、深度置信网络(DBN)和堆栈自动编码器(SAE)3种神经网络讨论使用原始信号,时域和频域特征,时频域特征,结合时域、频域与时频域特征信息的4种不同预处理方法下的滚动轴承故障研究[10]。虽然这种人工特征提取加深度学习的方法在故障诊断领域应用中取得了不错的诊断效果,但仍需要人工提前做相关的预处理工作,没有真正发挥深度学习的自我学习这一优势。随着现代工业的发展,机械系统日趋复杂,利用深度学习方法自适应提取信号特征,减少人工参与,可以减小故障诊断过程中的不确定性对结果的影响,提高诊断精度[11]。
卷积神经网络(CNN)通过卷积运算代替一般神经网络的乘法运算,使用多个卷积核分别进行卷积处理,从而提取不同类型的特征[12]。Hoang等将滚动轴承一维振动信号转换成二维灰度图,作为振动图像CNN(VI-CNN)模型的输入应用于滚动轴承故障模式的自动识别[13]。长短时记忆网络(LSTM)可以短暂存储前一时刻的相关信息[14],Lei等利用LSTM网络有记忆时序数据信号的优势,提出一种基于LSTM的故障诊断模型,并在风力涡轮机数据集上验证了该模型的有效性[15]。
为了避免人工参与的影响,并实现各网络的优势互补,同时完成特征提取与分类评估的自底至顶的端到端健康诊断,本文提出一种结合CNN和LSTM的滚动轴承故障诊断模型,以原始振动信号作为模型输入,CNN层进行故障特征信息提取,LSTM网络层学习故障特征,最终实现故障分类,并与其他3类网络模型进行对比,在不同工况下验证该方法的故障诊断准确性与鲁棒性。
1 深度学习理论
1.1 CNN特征提取基本原理
CNN卷积层将输入信号局部区域与滤波器内核进行卷积,在激活函数的作用下生成输出特征。每个滤波器使用相同的内核来提取输入信号的局部特征。一个滤波器对应于下一层中的一个帧,并且帧的数量称为该层的深度。为了自动提取故障特征,参考第一层宽卷积核深度卷积神经网络(WDCNN)模型参数[16],卷积层采用宽卷积核,卷积过程描述如下
yl+1,m(n)=wl,mxl(n)+bl,m
(1)
式中:wl,m和bl,m分别代表第l层中第m个滤波器内核的权重矩阵和偏置项;xl(n)表示第l层第n个区域;yl+1,m(n)第l+1层中第n个区域的第m个滤波器的卷积后的输出。
卷积之后,通过激活函数以获得非线性特征,增强模型的特征表达能力。ReLU激活函数用以加速CNN的收敛过程,表达式如下
al+1,m(n)=f(yl+1,m(n))=max{0,yl+1,m(n)}
(2)
式中:al+1,m(n)是yl+1,m(n)激活后的输出值。
池化可以有效地减少CNN卷积后的特征空间和网络参数。最常用的池化层有平均池化和最大池化,本文采用最大池化层,对特征信息执行最大池化操作,以减少参数同时降低数据维度。最大池化操作如下
(3)
式中:ql,m(t)表示第l层在第m帧中第t个神经元的值,t∈[(n-1)H+1,nH],H是池化区域的宽度;pl+1,m(n)表示池化操作后第l+1层中神经元对应的值。
1.2 LSTM的基本原理
LSTM是递归神经网络(RNN)的变体,用以缓解RNN在训练时存在的梯度问题[17]。LSTM单元模型主要包括遗忘门、输入门和输出门。输入门可以短暂存储相关信息,是LSTM不同于RNN的最大特点。特征信息经过CNN层后传递到LSTM细胞单元,遗忘门决定信息的通过量,计算如下
ft=σ(wL1[ht-1,xt]+bL1)
(4)
式中:σ是sigmoid函数;wL1和bL1分别是权重和偏置;ht-1是前一个单元的输出;xt是当前输入。
输入门决定了新信息能否被细胞单元记忆,其计算如下
it=σ(wL2[ht-1,xt]+bL2)
(5)
(6)
(7)
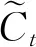
LSTM单元的最终输出ht由输出门的输出ot与记忆单元输出Ct决定,具体计算如下
ot=σ(wL4[ht-1,xt]+bL4)
(8)
ht=ottanh(Ct)
(9)
式中:wL4、bL4分别是输出门的权重和偏置。
2 基于CNN-LSTM的故障诊断方法
2.1 基本流程
诊断模型结构如图1所示,主要由信号输入层,CNN卷积层、池化层、LSTM层及分类输出层组成。基于CNN-LSTM的滚动轴承故障诊断过程如下:①将一维振动信号标准化,输入CNN卷积层,利用宽卷积核自适应提取故障特征;②提取后的特征经过最大池化层的池化操作,降低数据维度,并保留主要的特征信息;③再将降维后的特征数据作为LSTM层的特征输入,用以训练神经网络并自动学习故障特征;④利用BPTT(back-propagation through time)算法将训练误差反向传播,逐层逐步更新模型参数;⑤使用Softmax激活函数,将故障特征进行分类,完成故障诊断。详细过程如下:

图1 一维CNN-LSTM网络结构图Fig.1 1D CNN-LSTM network structure
(1)获取振动信号,整理、标准化并分割成固定段,构建数据样本;
(2)划分训练集、验证集和测试集使用独热编码(one-hot encoding)技术进行标签化处理;
(3)使用网格搜索算法寻找最优初始模型参数,根据结果设置批大小(B),学习率(rL),迭代次数(N)等参数;
(4)训练集对神经网络进行训练,模型提取特征信息并学习故障特征,并利用BPTT算法更新模型参数;
(5)验证集验证模型训练效果,根据验证结果微调模型参数;
(6)判断网络训练次数m是否达到预先设定的迭代次数N,如果是,进行下一步,否则重复第4步;
(7)测试集测试已训练好的模型性能,计算评价指标,输出计算结果,结束计算。
基于CNN-LSTM的滚动轴承故障诊断流程如图2所示。
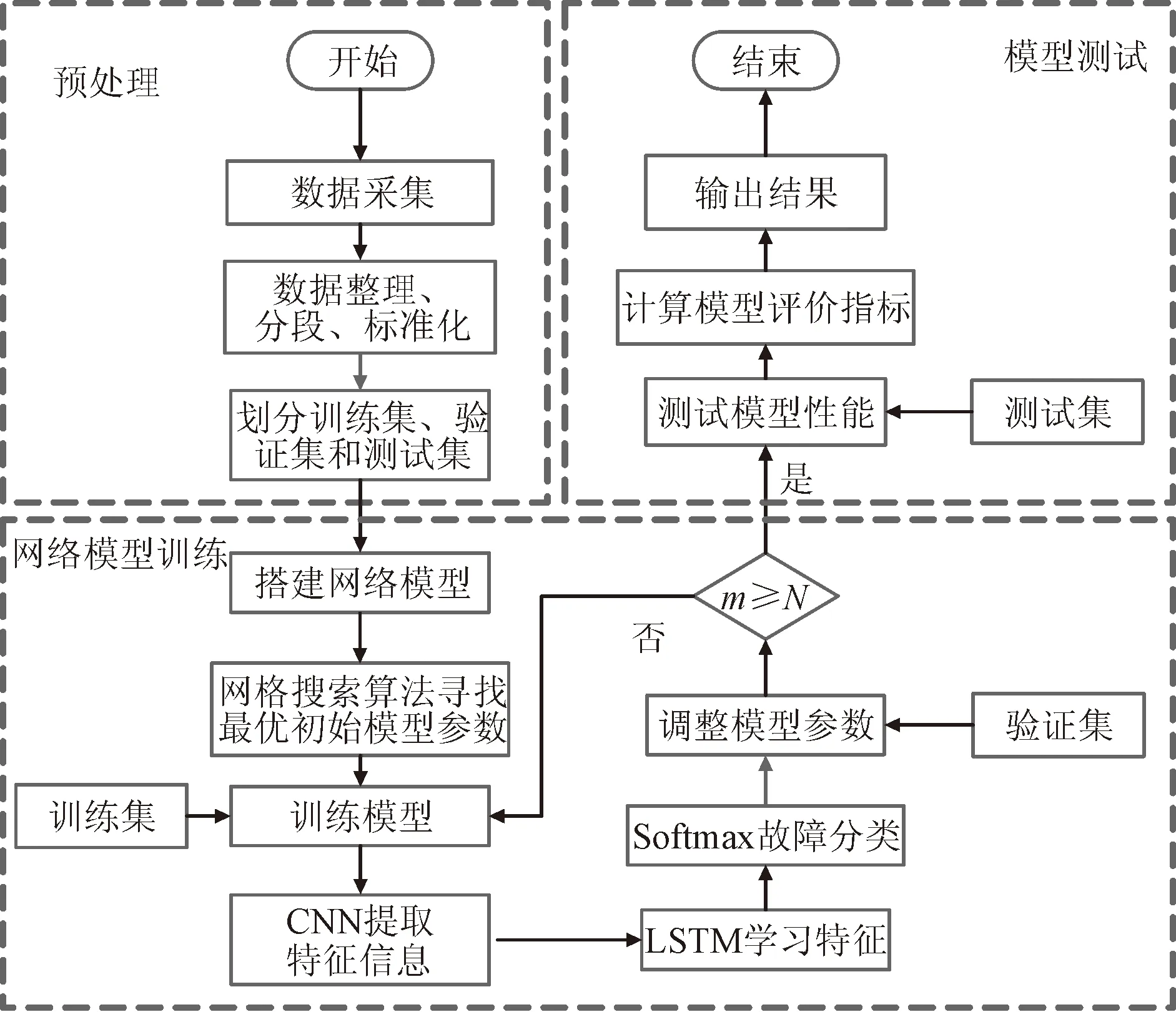
图2 基于CNN-LSTM的滚动轴承故障诊断流程图Fig.2 Flow chart of rolling bearing fault diagnosis based on CNN-LSTM
2.2 评价指标
以准确率作为模型分类故障诊断的量化指标,以损失函数函数值作为目标函数评价指标,评价模型预测值与真实值的接近程度。本文选用交叉熵损失函数来刻画模型实际输出(概率)与期望输出(概率)的距离,计算值越小,表明两者越接近。
3 试验与分析
3.1 试验说明
试验计算使用Google公司的Tensorflow框架,使用Python语言编程,计算机配置为Intel(R)Core(TM)i7-7700CPU@3.60GHz,4 GB运行内存。
为了验证提出模型在实际滚动轴承故障诊断中的有效性,本文使用Spectra Quest公司设计的机械故障综合模拟试验台,如图3所示,主要由驱动电机、转速表、转子基座、载荷和试验轴承等组成。

图3 机械故障综合模拟试验台Fig.3 Mechanical fault comprehensive simulation test bench
传感器采用PCB352C33单轴振动加速度传感器,分别安装在试验轴承的水平方向和垂直方向进行同步数据采集。试验轴承型号为ER12KCL,包括正常,外圈故障,内圈故障和滚动体故障共4种轴承状态类型,其中滚动体故障在轴承内部,故障点不可见,具体如图4所示。试验轴承运行转速为1 600 r/min,采样频率20.48 kHz,分别采集不同故障类型轴承运行状态下的振动加速度数据。

(a)正常
3.2 数据说明
将各运行状态下采集到的轴承数据进行归一化处理并分段,每段样本振动信号包含1 024个数据点,轴承每类运行状态包含1 000个样本,数据集总计4 000个样本,轴承4种运行状态的时域波形图如图5所示。使用独热编码技术对样本数据进行标签化处理,同一标签下随机选择样本并划分训练集、验证集和测试集,构成最终数据集,具体描述如表1所示。
(a)正常
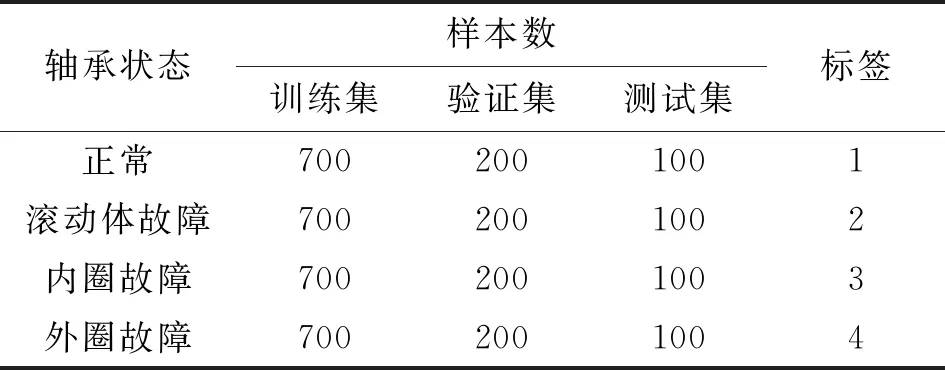
表1 4种轴承状态数据集描述Table 1 Description of four kinds of bearing state dataset
3.3 CNN-LSTM模型参数设计
参考文献[16]和[18]中的深度卷积神经网络结构参数选取方法,并经过反复验算测试后调整模型参数,最终得到的CNN-LSTM模型结构参数如表2所示。CNN卷积层采用宽卷积核,以便获得较大的感受野,从而提取更多的特征信息并有效抑制噪声干扰[16];池化层采用最大池化方式,保留最主要特征信息,同时对边界部分进行全0填充,保证输出尺寸不发生变化;采用双层LSTM网络,学习特征序列信息;最后采用adam优化算法优化交叉熵损失函数,提高计算效率,减少训练时间。

表2 模型结构设置Table 2 Model structure setting
深度神经网络模型超参数众多,参数的设计与选择直接影响网络模型最终计算结果。本文选用网格搜索算法为故障诊断模型选择最佳的初始学习率和批大小,以提高模型计算准确率。网格搜索算法的基本原理是将自变量c和g设定在一个区间内,按照一定步长将区间划分为网格,逐一计算每个网格点上的约束函数值并计算在此网格点下的目标函数值,依次计算完所有网格点的目标函数值,从中选择目标函数值最优解下的自变量c和g作为此区间下的最优参数值[19]。对于非线性规划问题,网格搜索算法可描述为
minf(x)
Xc≤X≤Xg
(10)
式中:Xc和Xg分别是网格区域内未知参数的边界;X为计算时的未知参数;f(x)表示目标函数。
现为测试数据集配置不同的学习率和批大小,批大小B分别取32、64、128和256,学习率分别取0.000 5、0.001、0.002、0.004、0.006,划分网格,计算网格节点上目标函数值,根据计算结果选择最优的参数组合,并依次作为模型初始参数。其中所有训练集和验证集样本全部计算完一次算作完成一次迭代,每次计算迭代次数N取30,计算5次取平均值,降低偶然误差影响。网格搜索算法的计算结果如图6所示。从图6可以看出,当模型的批大小为32,学习率为0.001时计算结果最优,测试集平均准确率达到99.45%。原因在于批大小控制模型的准确度和收敛性,取值越小,模型的训练和计算时间越高,相应的准确率会提高。学习率控制模型参数更新速度,学习率过小,模型训练速度降低,过大则可能导致参数振荡而造成精确度下降。

图6 学习率与批大小对模型计算准确率的影响Fig.6 The influence of learning rate and batch size (B) on the accuracy of model calculation
3.4 结果及分析
为了测试提出模型的性能,在相同的数据集上使用多层感知器(MLP)、LSTM模型(单层LSTM、双层LSTM以及3层LSTM)以及经典CNN模型(LeNet5、AlexNet、VGG)进行轴承故障诊断,计算结果如表3所示。所有模型输入均为原始滚动轴承一维振动信号,模型初始学习率和批大小均分别设置为0.001和32,每次计算30 epochs,计算5次取均值作为计算结果。验证集验证模型训练效果,同时根据验证结果微调模型参数。不同模型的验证集平均准确率对比计算如图7所示,模型验证集的平均损失函数值随着网络训练的变化如图8所示。测试集测试已训练完成模型的性能。

表3 不同模型的测试集平均计算结果Table 3 Average calculation results of test sets for different models

图7 不同模型验证集的平均准确率对比Fig.7 Comparison of average accuracy of different model verification sets
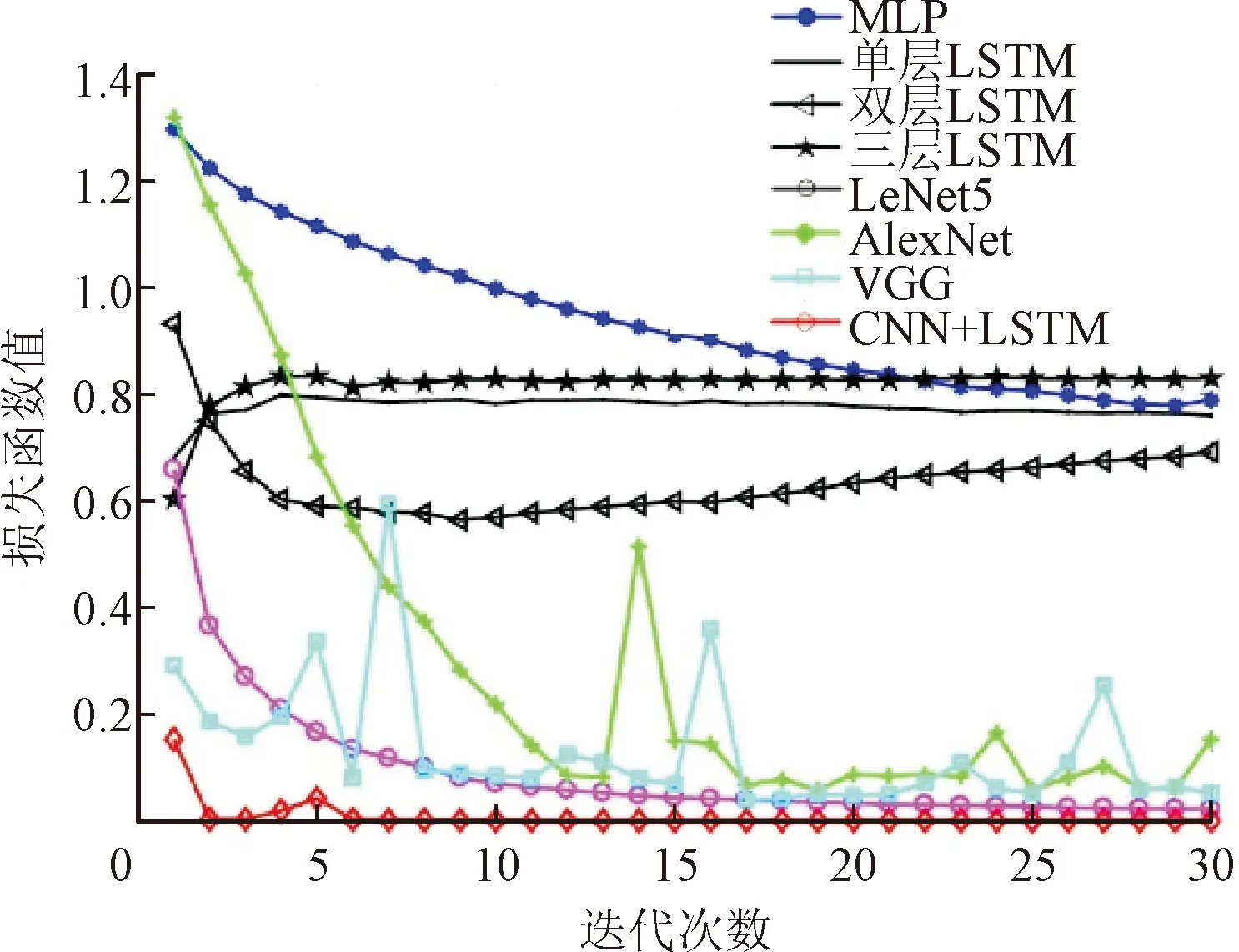
图8 不同模型验证集的平均损失函数值对比Fig.8 Comparison of average loss function values of different model verification sets
可以看出,本文提出的CNN-LSTM模型测试集平均准确率达到99.45%,高于其他模型计算的平均准确率,且损失函数值最低,说明模型的实际输出与预测值之间差异较小。与其他模型相比,本文模型的总参数较低,仅高于MLP模型参数,但MLP模型诊断准确率效果很差,仅65.90%。与准确率达到98.75%的LeNet5模型相比,本文CNN-LSTM模型参数更少,表明了本文模型的结构简单且故障诊断率更高的优越性。
3.5 变工况下模型鲁棒性试验及结果分析
为了进一步试验提出模型在变工况数据集中的鲁棒性,改变第3.1节中的试验载荷(载荷标记为1),减少试验载荷模拟空载工况(载荷标记为0),更改后的试验台如图9所示。试验操作不变,分别采集不同运行状态轴承在1 600 r/min、1 200 r/min转速下的振动信号,组合第3.2节中样本数据共同构成变工况下的滚动轴承故障样本数据集,并标签化处理,总共10种类别,共10 000个样本。每个类别随机选择样本数据划分训练集、验证集和测试集,具体样本描述如表4所示。选用表3中模型故障诊断准确率超过80%的双层LSTM、三层LSTM以及经典CNN模型(LeNet5、AlexNet、VGG)作为与本文CNN-LSTM模型的对比,参数设置与前述相同。表5总结了不同模型在变工况下的滚动轴承故障诊断结果。模型的验证集平均准确率和平均损失函数值分别如图10和图11所示。可以看出,本文模型不仅平均准确率最高,达到99.10%,并且损失函数值最低,同时模型易训练且较稳定。具体表现在迭代次数N大于10时,模型计算平均准确率基本不发生变化,能较好地应对变工况下的工作环境,鲁棒性优于单独的LSTM网络和经典的几种CNN网络。
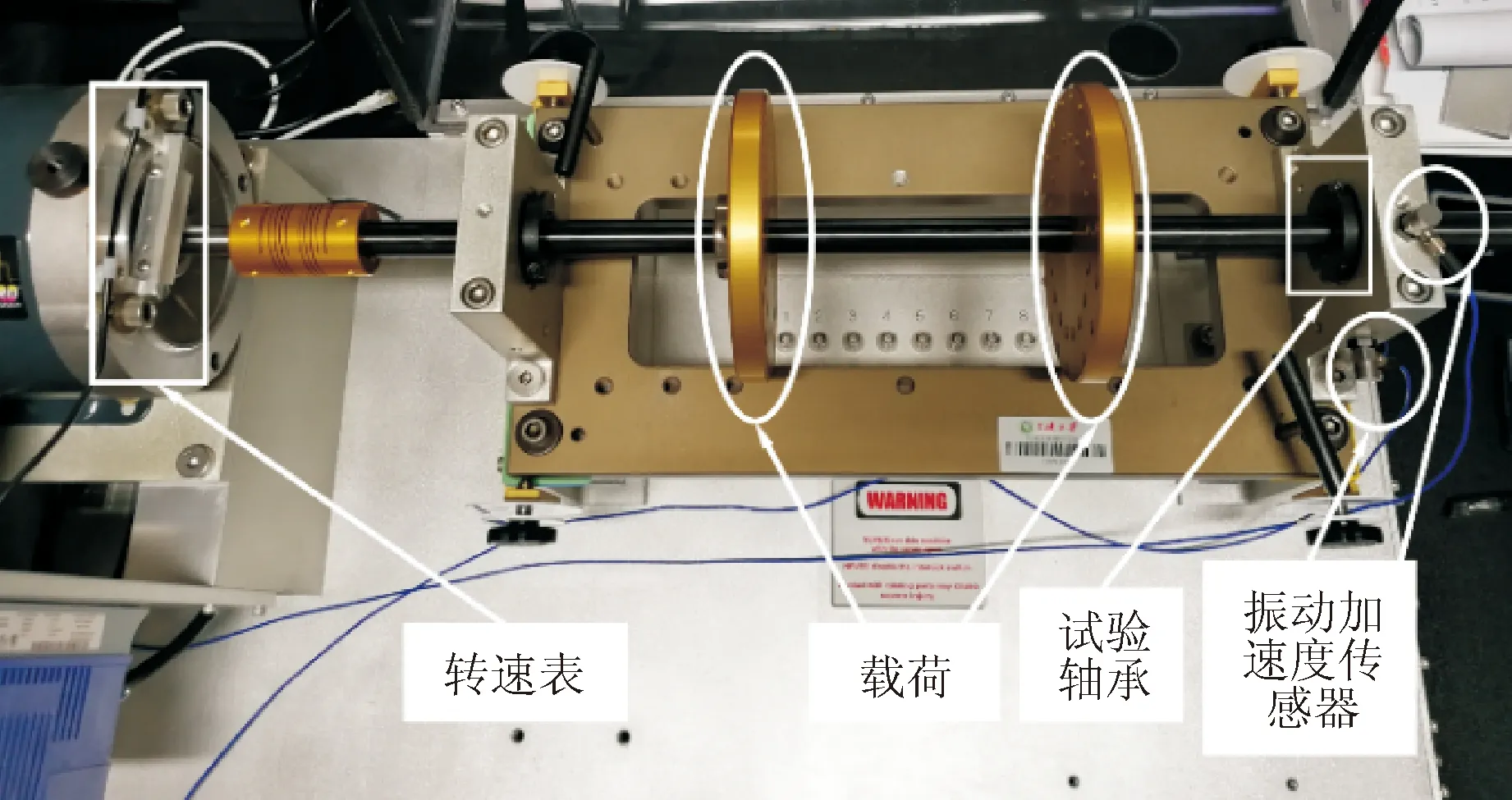
图9 机械故障综合模拟试验台(空载)Fig.9 Mechanical fault comprehensive simulation test bench (no load)
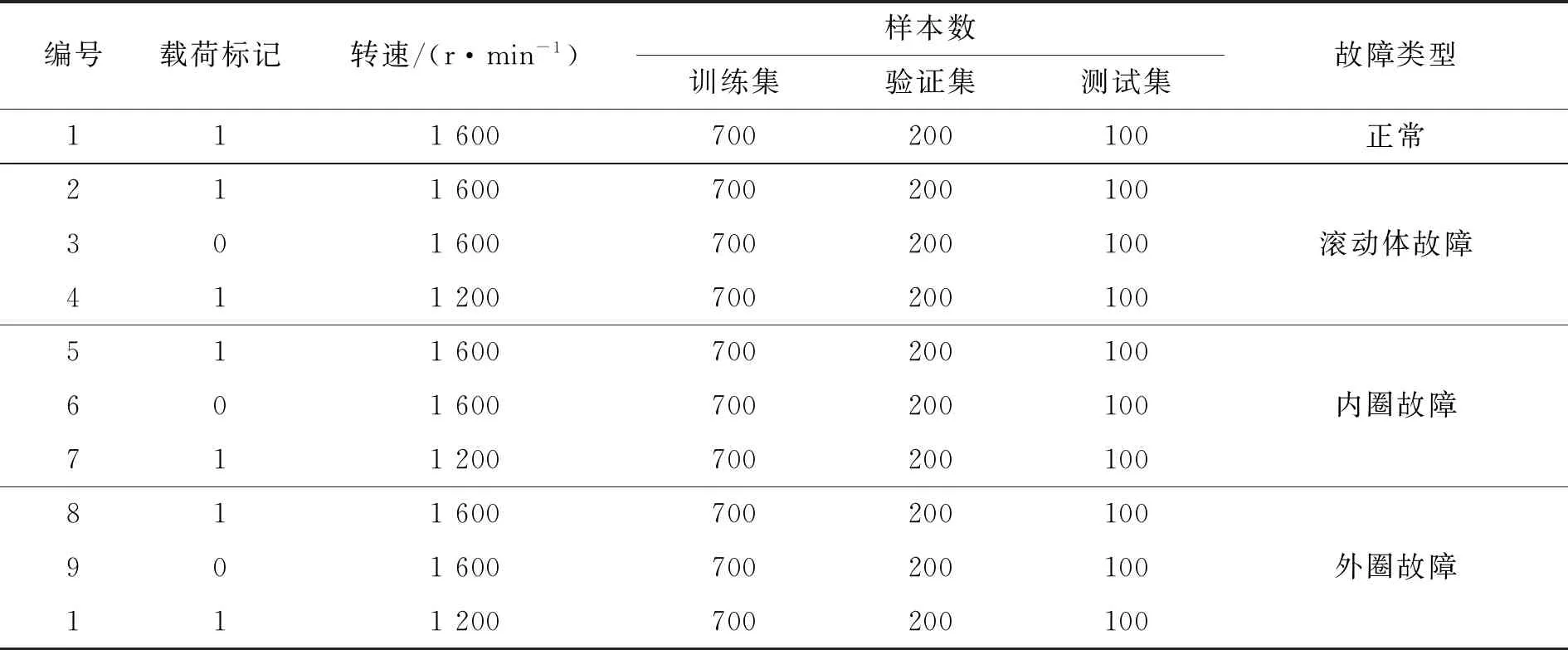
表4 变工况下的滚动轴承故障样本组合Table 4 Fault sample combination of rolling bearing under variable working condition

表5 变工况下的不同模型测试集计算结果Table 5 Calculation results of different model test sets under variable working conditions
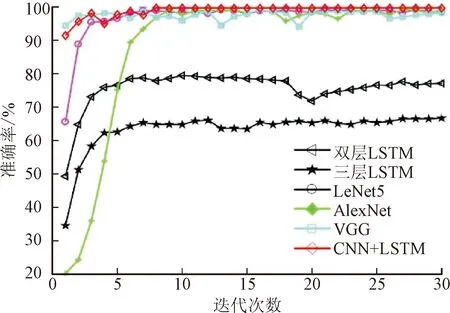
图10 变工况下不同模型验证集的平均准确率对比Fig.10 Comparison of average accuracy of different model verification sets under variable working conditions

图11 变工况下不同模型验证集的平均损失函数值对比Fig.11 Comparison of average loss values of different model verification sets under variable working conditions
3.6 模型评价
K折叠交叉验证算法(K-FCV)[20]是机器学习中用于验证模型参数和评价模型分类器的评价算法。K折叠交叉验证算法的基本思想是将给定数据进行切分训练子集、验证子集和测试子集,重复利用,反复验证、测试,从多次折叠计算中选择较优模型参数,有效避免过拟合现象的出现,最终得到模型的性能评价指标。因此,通过交叉验证可以更好地选择模型参数和评价模型的性能。
选用K折叠交叉验证算法对模型计算结果进行评价,具体计算结果如表6所示。选用10次交叉验证平均结果作为模型最终结果,详细交叉验证结果如图12所示。可以看出,计算准确率达到99%以上的模型包括CNN-LSTM模型和AlexNet模型,其中CNN-LSTM模型计算准确率略高,达到了99.41%,模型误差仅0.21%左右,且相比AlexNet模型,模型总参数少90%左右,训练时间更短。试验结果表明,本文提出的CNN-LSTM模型具有结构简单、计算准确率高的优势,且神经网络训练充分、计算结果稳定、误差较小,未出现过拟合或欠拟合的情况。
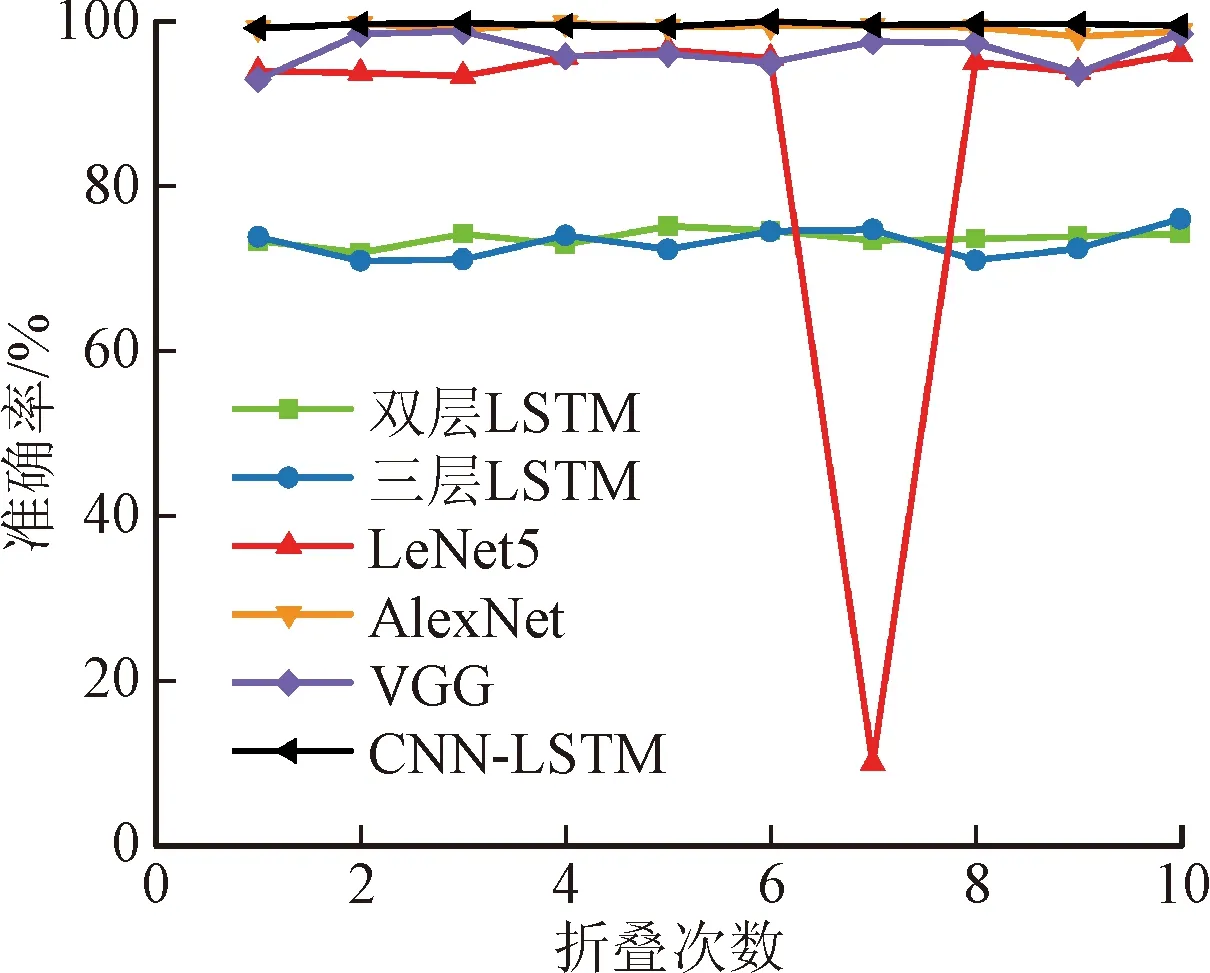
图12 K折叠交叉验证计算过程Fig.12 K-folding cross-validation calculation process
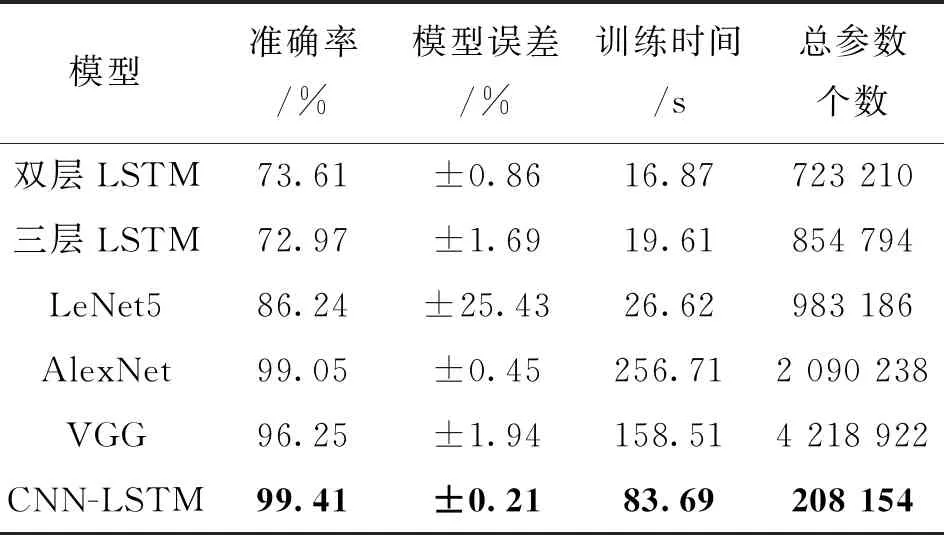
表6 不同模型的评价结果Table 6 Evaluation results of different models
4 总 结
本文提出了基于CNN-LSTM混合神经网络的滚动轴承故障智能诊断方法,结合CNN和LSTM网络的优势,可以直接从原始振动信号中自适应提取特征信息,减少人工特征提取过程中带来的不确定性,实现了端到端的滚动轴承故障分类模式。通过试验测试数据得出如下结论:
(1)本文提出的CNN-LSTM方法在同工况下的滚动轴承故障模式分类准确率达99%以上,且比同等准确率下的其他模型结构更简单,训练时间更少,优于其他几种网络;
(2)通过网格搜索算法计算得到在一定步长设置下初始批大小和学习率的较优取值分别为32和0.001,并通过不同转速,不同载荷的变工况下的滚动轴承试验表明,CNN-LSTM方法的平均准确率达99%以上,损失函数值比其他分类模型更低,模型能较好适应变工况下的工作环境;
(3)通过K折叠交叉验证算法表明提出的CNN -LSTM模型平均计算准确率达到99.41%,模型误差仅0.21%左右,且模型训练较充分,未出现过拟合和欠拟合情况。
