基于多通道卷积神经网络的中文文本关系抽取
2021-06-03梁艳春房爱莲
梁艳春, 房爱莲
(华东师范大学 计算机科学与技术学院,上海 200062)
0 引 言
在信息爆炸的现代社会, 快速获得准确的信息具有重大意义, 关系抽取则是帮助我们从海量数据中获取关键信息的重要方式之一. 关系抽取也被称为关系分类, 即从自然语言文本中识别出关键实体后, 再判断两个或多个实体间的语义关系, 属于多分类问题. 作为重要的语义处理任务, 关系抽取也在知识库填充、问题回答、自动知识库构建等复杂应用中起着中间作用.
为了抽取出两个实体间的正确关系, 需要解析句子的句法特征和语义特征. 句法特征是指句子的组成部分以及它们的排列顺序, 语义特征是指词语的意义以及在句子中词语意义如何相互结合以形成句子意义. 为了学习这些特征, 早期的关系抽取方法通常需要解析文本并人工构建特征, 这些方法很大程度上依赖于外部自然语言处理工具, 如词性标注、语法分析等. 而卷积神经网络(CNN)建模语句的最短依存路径, 将语法分析融入深度学习框架中. 因此, CNN可以代替句法树提供语法信息. 但中文句法结构比英文更为复杂, 如何自动地从句子中学习特征, 最小化对外部工具包和资源的依赖,实现端到端的中文关系抽取, 是值得研究的问题.
为解决上述难点, 本文在CNN的基础上提出了MCNN_Att_RL模型. 该模型将两种类型的词向量输入卷积层, 每个通道都用分层的网络结构, 使神经网络学习到不同的表示. 为了学习到更多的语义特征, 还加入注意力机制, 获得强调实体的句子表示. 此外, 采用两层池化结构, 先用分段平均池化融入句子的结构特征, 再经过最大池化保留句子的最大信息. 同时, 采用基于边界的排序损失函数, 替代普遍使用的Softmax分类函数和交叉熵函数, 排序损失函数使模型更能区分易于分错的类别. 综上,本文的主要贡献如下.
(1)研究了多通道CNN方法如何用于中文文本关系抽取, 在没有外部信息的情况下, 学习到句子不同的表示.
(2)加入注意力机制获取句子的语义特征, 并通过分段平均池化融入句子结构特征, 在不依赖外部工具包的情况下, 实现了端到端的关系抽取.
(3)用排序损失函数代替交叉熵函数进行训练, 以区分易于分错的类别, 提高了中文文本关系抽取的准确性.
1 相关工作
关系抽取的方法可分为监督学习、半监督学习或无监督学习. 其中监督学习的关系集合通常是确定的, 可以当作分类问题去处理. 半监督学习方法利用少量的标注信息作为种子模板, 从非结构化数据中抽取大量新的实例来构成新的训练数据, 由于这种方法依赖于模板和规则, 会导致数据不太精确,存在大量噪声. 无监督方法一般利用语料中存在的大量冗余信息做聚类, 在聚类结果的基础上给定关系, 但聚类方法本身就存在难以描述关系和低频实例召回率低等问题, 因此无监督学习一般难以得到很好的抽取效果. 下面主要介绍监督学习和半监督学习方法.
早期的方法通常基于正则表达式表示的模式和规则. 模式方法假设同一关系类型的所有句子具有相同的语言环境, 其不能覆盖所有的语言形式, 导致了很低的召回率.
在2013年, Liu等[1]最先提出用CNN方法做关系分类. 他们使用的网络结构很简单, 即是将同义词的嵌入表示作为输入, 之后是卷积层全连接层以及用Softmax分类. 相比于传统方法, 该方法具有一定的提升, 为后续神经网络用于关系抽取提供了启发. 2014年, Zeng等[2]在此基础上进行了改进,使用预处理的词向量, 并设置了实体, 即实体的上位词、实体的上下文环境、词位置等词汇特征, 结果表明, WordNet和位置特征比较重要. 2015年, Zhang等[3]开始尝试用RNN做关系抽取, 在不使用任何词汇特征的情况下, 效果与CNN结合词汇特征相类似. Zhou等[4]在RNN的基础上, 用LSTM(Long Short-Term Memory)替代RNN模型, 并加入注意力机制, 效果取得了提升. 之后, Zhu等[5]也在CNN中采用注意力机制, 并改进损失函数, 在英文数据集SemEval 2010 Task8 中获得了当前最佳结果. Li等[6]则设计了一种双卷积神经网络方法, 结合注意力机制, 并借助知识库提升关系抽取性能.此外, Hong等[7]通过改进图卷积神经网络, 用一种新的感知注意力机制来获取实体间的关系表示, 在多个公共数据集上取得了较好的效果.
上述的全监督方法是在完全正确的标注数据集上做的, 数据量小. 而半监督学习方法则在大数据集上做关系抽取, 需要考虑数据中的噪声问题. 2015年, Zeng等[8]在自己2014年的研究基础上, 使用多示例学习方法解决远程监督自动标注数据产生的大量噪声以及错误标注数据的问题, 并进行了分段池化. 虽然这种方法减弱了噪声的影响, 但也丢失了一部分信息. Lin等[9]在Zeng的基础上引入注意力机制, 这样既可以减弱噪声, 加强正样本, 也可以充分利用信息. 之后, Kim等[10]提出了在文本中附加可确定的显著实体, 帮助识别传统方法无法识别的关系. Sun等[11]则采用多头自注意力网络去噪方法以提取关联, 跟传统模型相比达到了较好效果. Chen等[12]通过融合强化学习, 设计了DQN(Deep Q Network)对句子进行降噪, 减少错误标签的影响, 提高了关系抽取的准确度.
英文关系抽取技术的研究相对比较成熟, 但由于中文数据集的缺乏, 中文关系抽取相应地研究较少. 其中, Wu等[13]采用基于注意力的CNN做中文关系抽取, 并加入了HowNet上位词嵌入信息, 在ACE 2005中文语料中取得了一定的效果提升. 而针对中文文学作品没有明显连词关联, 主语比较隐蔽, 词的用法相对复杂等难点, Wen等[14]利用结构正则化去除句法信息中的噪声, 通过最短依赖路径进行中文文学文本关系的提取. Li等[15]利用外部语义信息, 将字义、词义、同义词等通过Lattice LSTM融入一起, 在多个中文数据集上验证了模型较好的鲁棒性. 张等[16]则针对中文电子病历, 采用双向GRU模型, 并引入注意力机制提升了在特定领域中中文关系抽取的准确性.
2 多通道CNN模型
2.1 多通道机制介绍
多通道机制是图像处理方法的基础, 在图像处理领域, 图像由3个通道(红色、绿色和蓝色)组成.每个通道都使用多层神经网络进行处理, 由于每个通道在循环传播过程中互不影响, 因此它使神经网络能从每个通道学习不同的表示. 基于单通道CNN处理句子的方法与处理图像不同, 它们在不考虑句子结构的情况下对整个句子进行卷积. 整个方法忽略了一个重要问题: 单词可能具有多种含义. 单一词向量只能表征自然语言的一部分语义信息, 这限制了总的信息输入量. 基于此, 本文采用了多通道CNN结构, 每个通道输入不同的预训练词向量, 多个通道表征了输入语句的更多语义信息, 从而使模型学习出区分度更强的语义特征, 对自然语言具有更强的表征能力.
2.2 基于多通道机制的模型MCNN_Att_RL
本文提出的MCNN_Att_RL模型如图1所示. 该模型主要由向量映射层、注意力层、卷积层、分段平均池化层、最大池化层和全连接层组成. 由图1可以看到, 本文模型不同于普通CNN模型的地方在于, 这里使用了两种词向量将输入映射到两条通道, 并在通道2中加入了注意力机制以获得面向实体的向量表示. 此外, 在经过双通道CNN获得多个通道信息后, 按实体位置将其分成5段通过平均池化层, 以融入句子的结构信息. 最后经过最大池化层, 学习到句子的最终表示. 这样, 网络可以自动学习到更丰富的特征.
2.2.1 向量映射层
经典的one-hot编码方法将词与词间视为相互独立, 具有高稀疏性的缺点. 2013年, Mikolov等[17]提出了Word2vec模型. Word2vec模型分为Skip-gram模型和CBOW模型, 它可通过学习文本的方式将每个字映射成低维的实值向量, 从而得到字的语义表征. 使用Word2vec模型训练好的词向量直接输入下一个网络结构进行使用. 自然语言处理领域使用词向量的方式一般分为两种: 一种是使用大型数据预训练的词向量; 另一种是针对特定任务或特定数据集训练词向量, 这两种方式都只能使用一种词向量, 获取的是句子的单一表示. 在本文的MCNN_Att_RL模型中, 采用了两个通道融合两种词向量, 获得的是词的不同语义特征, 其中通道1使用在Gigaword[14]中预训练的中文词向量, 通道2则使用特定于中文文学作品的词向量.

图 1 MCNN_Att_RL模型结构Fig. 1 MCNN_Att_RL model structure


2.2.2 注意力层

其中, 函数f表示web和wi的内积和. 之后, 计算相关性矩阵ab, 矩阵ab的元素为

其中,b=1,2;i=1,2,···,n. 令

得到面向实体对的向量

其中,i=1,2,···,n. 最终融入语义信息的句子S表示为E={e1,e2,···,en}.
2.2.3 卷积层

2.2.4 平均池化层
为了获取句子的结构信息, 根据实体1跟实体2的位置, 将c分成5段. 假设实体1的起始与终止位置为a、b, 实体2的起始位置与终止位置为c、d, 则c被划分为 [c1,···,ca−1] 、 [ca,···,cb] 、 [cb+1,···,cc−1] 、[cc,···,cd] 、 [cd+1,···,cn] 5部分, 将c表示为

将每段输入分别通过平均池化层, 得到
对于库里南,用文字去仔细形容它的座椅舒适程度其实是相当乏味的,只有亲身体验才能明白其中的奥妙。不过遗憾的是,在官方重点宣传的“览景坐席”并没有出现在我体验的那辆库里南上。要不然,在后备厢开启“览景坐席”的两个座椅,让自己沐浴在三亚冬天温暖的阳光下,也算是一种很容易就忘记烦恼的愉快。

其中,j=1,2,3,4,5 . 这样, 每段输入都在平均池化层的作用下得到一个值, 组合在一起就得到了融入了句子结构信息的特征向量.
2.2.5 最大池化层
为了保留最大的信息特征, 再加入最大池化层对平均池化后的结果进行最大化操作, 得到最后的特征信息, 即

其中,j=1,2,3,4,5 .
2.2.6 全连接层
最后采用全连接层进行全局调节, 得到最终的输出

其中,wf为模型的参数, 在反向传播时进行训练.
2.2.7 分数计算
不同于用Softmax分类函数计算关系概率, 这里用句子最终表示与关系类别c的相关性作为得分. 即

其中,wc为关系c的嵌入向量, 通过关系嵌入查找表得到.sscore,c为句子中的实体预测为关系c的分数, 因此, 最终预测的关系类别为

2.2.8 损失函数
不再使用交叉熵函数作为损失函数, 而是采用基于边界的排序损失函数. 在获得关系分数后, 损失函数定义为

3 实 验
3.1 数据集介绍
由于中文关系抽取语料库的缺乏, 2017年, Xu等[18]爬取了1 000多篇中文文章, 去掉太短和噪声太多的文章, 历时3个月从837篇中文文学作品中获得语料, 定义了7种实体类型和9种关系类型用于中文文本命名实体识别和关系抽取. 本文选取这个中文文学文本数据集进行关系抽取实验, 其中关系类别定义如表1所示.
对该语料进行预处理, 共获得21 240个句子. 其中17 227个句子作为训练集, 4 013个句子用作测试集. 每一句都有标记好的两个实体, 预处理后的部分数据示例如图2所示.
这些句子均从中文文学作品中得到, 中文关系抽取任务为抽取两个实体之间的语义关系. 例如,幽兰、山谷, “幽兰在山谷, 本自无人识”. 这里, 标记的两个实体为“幽兰”和“山谷”. 模型的输入为句子的嵌入向量表示, 输出为关系类别5, 对应表1中的Located关系.
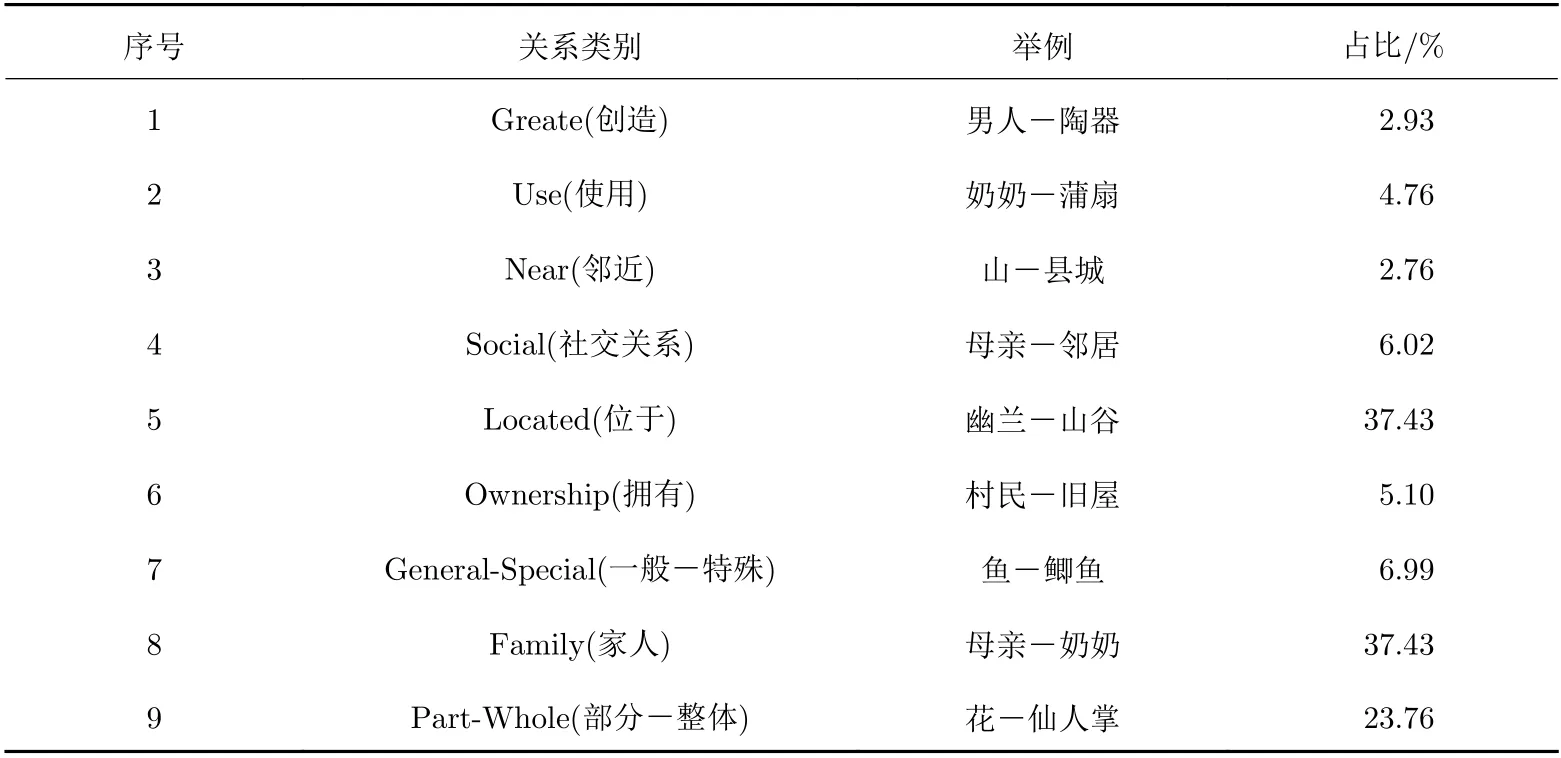
表 1 关系类别Tab. 1 Relationship category

图 2 预处理数据Fig. 2 Pre-processed data
3.2 评价指标
对于给定样本集, 评估机器学习算法预测结果的方式有: 查准率P, 即分为正例的实例中实际值为正例的比例; 查全率R, 又叫召回率, 即正例被分到正例的比例. 由于查准率P和查全率R会出现矛盾, 需要综合考虑, 所以用P和R的加权调和平均地去评估是最好的方式. 在多分类问题中, 查准率和召回率的调和平均F1值的计算为[19]

其中,n是指关系类别的数量, 在本文所用数据集中,n为9.
3.3 实验设置
本文中模型超参数设置如表2所示. 表2中, batch、epoch、Dropout、学习速率、隐藏层个数、词向量维度等均为其他文献中的经验所得; 而缩放系数z, 边界系数a、b, 卷积核大小等通过五折交叉验证确定, 验证集从测试集中随机选择.
3.4 实验结果与分析
为了评估MCNN_Att_RL模型的有效性, 本文选取了CNN[3]模型、BiLSTM[4]模型、加入注意力机制的BiLSTM[5]模型这3种基线模型, 并增加了3组对比实验模型, 即双通道CNN模型MCNN、在MCNN模型中加入注意力机制的MCNN_Att模型、在MCNN_Att模型中加入了分段平均池化的MCNN_Att_P模型. 实验结果如表3所示.
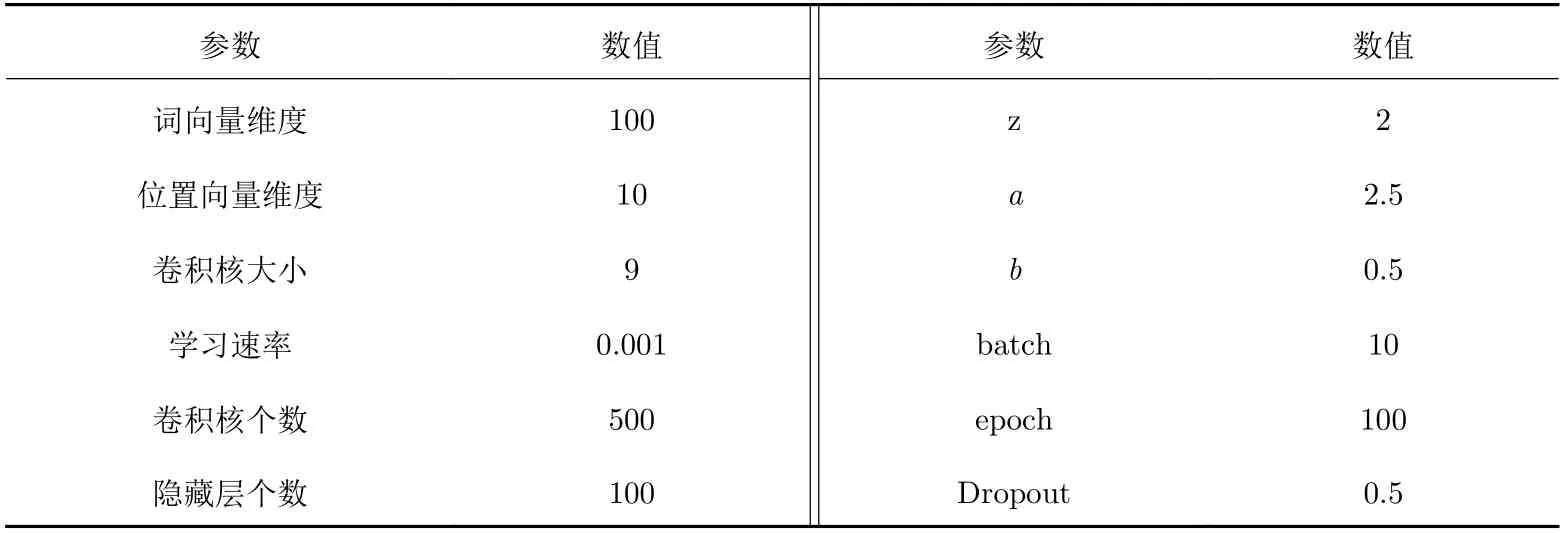
表 2 实验的参数Tab. 2 Experimental parameters
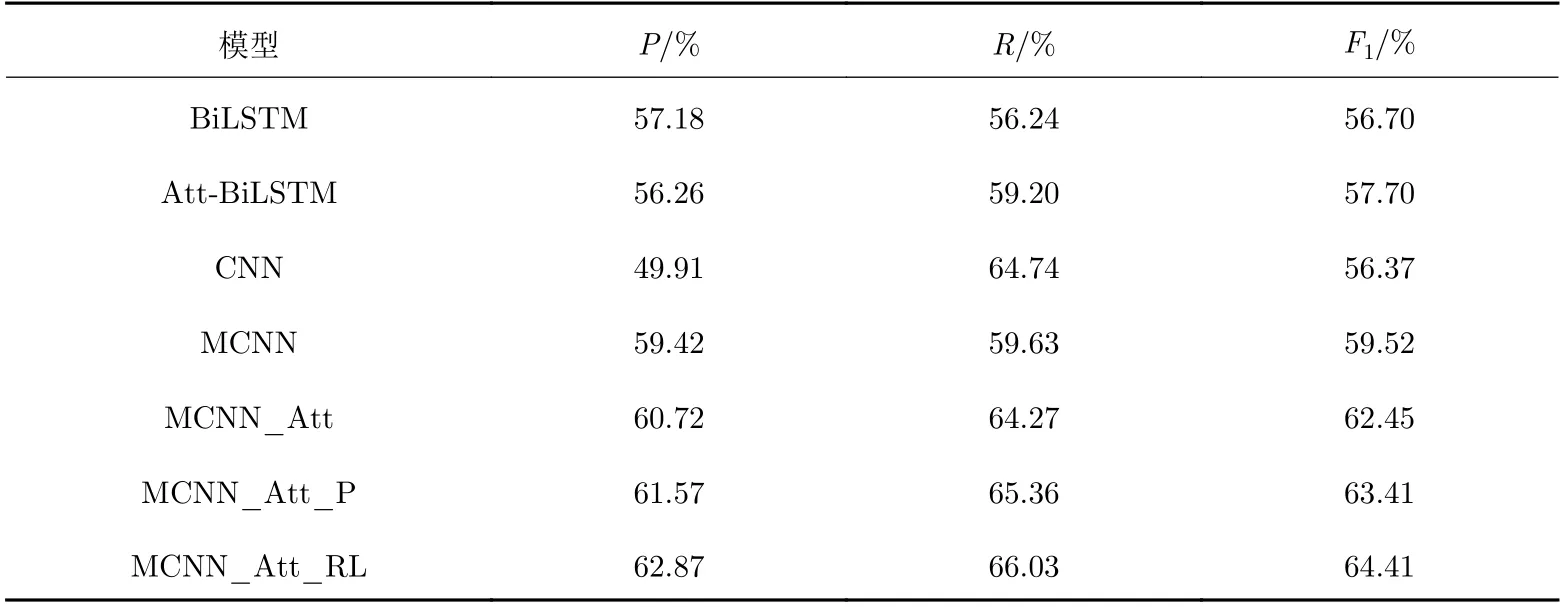
表 3 实验结果Tab. 3 Experimental results
从实验结果可以看出: ①相比于只使用预处理词向量的CNN模型, 融合两种词向量的MCNN模型的分类性能有很大提升, 说明词向量中确实包含自然语句的丰富表示, 多通道网络结构能学习到句子更多的语义特征; ②加入注意力机制的MCNN_Att模型比MCNN模型F1值提高了2.78%, 也证实了融入更多语义信息的重要性; ③加入分段平均池化的MCNN_Att_P模型比直接进行最大池化的MCNN_Att模型提升了1%左右的F1值, 说明虽然之前已经突出了实体位置, 并且双通道卷积层也在一定程度上提供了句子的语法信息, 但融入句子的结构特征还是提供了更多的有效信息; ④采用排序损失函数替代交叉熵函数,F1值也提升了1%左右, 证实了排序损失函数也适用多分类问题;⑤MCNN_Att_RL模型在无须任何外部语言信息的情况下得到了最佳的效果. 相比于使用语义分析工具或资源(如依存句法[14]、同义词信息[15]等)使关系抽取效果得到提升的方式, 该模型仅改进网络结构就学习到了更多的语义和结构特征, 也给其他自然语言处理任务提供启发; ⑥相比于其他模型, 本文模型用来实现融合两种词向量的双通道结构是并行计算的, 在提高抽取效果的同时仍不降低计算效率.
4 结 论
本文提出了一种双通道CNN模型, 其中加入了注意力机制, 采用两层池化, 并用排序损失函数代替交叉熵函数. 在不依赖外部信息源和工具的情况下, 实现了中文文学文本上端到端的关系抽取. 该模型中的双通道结构, 使用两种词向量作为输入, 以得到不同的语义信息. 而注意力机制又关注了每个字对句子的贡献, 得到了面向实体对的向量表示. 最后为了学习句子的结构特征, 采用分段平均池化和最大池化. 实验结果表明, MCNN_Att_RL模型的关系抽取效果优于其他神经网络模型. 未来的工作包括以下两个方面: ①尝试将模型应用在其他语言的关系抽取上, 特别是藏语等一些小众语言,可用的外部工具包较少, 需要这种端到端的关系抽取方式; ②尝试引入更多的特征, 如同义字向量表示等作为第三个通道, 进一步提升模型的性能.
